
Pytext 简介——Facebook 基于 PyTorch 的自然语言处理 (NLP) 框架
0 / 0 / 创建于 7年前
 geeker 的个人博客
geeker 的个人博客
自然语言处理(NLP)在现代深度学习生态中越来越常见。从流行的深度学习框架到云端API的支持,例如Google云、Azure、AWS或Bluemix,NLP是深度学习平台不可或缺的部分。尽管已经取得了令人难以置信的进步,但构建大规模的NLP应用依然还有极大的挑战,在学习研究和生产部署之间还存在很多摩擦。作为当前市场上最大的会话环境之一,Facebook已经面对构建大规模NLP应用的挑战有一些年头了,最近,Facebook的工程团队开源了第一个版本的Pytext,一个基于PyTorch的NLP框架,可以用来构建高效的NLP解决方案。
PyText的最终目标是简化端对端的NLP工作流实现。为了实现这一目标,PyText需要解决当前NLP流程中的一些问题,其中最令人头疼的就是NLP应用在实验环境和生产环境的不匹配问题。
更好地平衡NLP实验和生产部署
现代NLP解决方案通常包含非常重的实验环节,在这个阶段数据科学家们将借鉴研究文件快速测试新的想法和模型,以便达成一定的性能指标。在实验阶段,数据科学家倾向于使用容易上手、界面简单的框架,以便快速实现高级、动态的模型,例如PyTorch或TensorFlow Eager。当需要部署到生产环境时,动态图模型的固有局限性就带了新的挑战,这一阶段的深度学习技术需要使用静态计算图,并且需要为大规模计算进行优化。TensorFlow、Caffe2或MxNet都属于这一类型的技术栈。结果是大型数据科学团队不得不为实验和生产部署使用不同的技术栈。
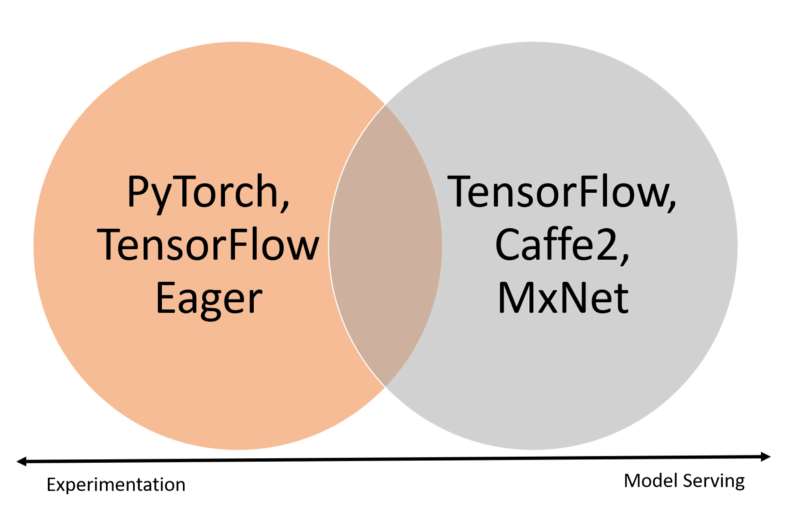
PyTorch是最早解决了快速实验与规模化部署之间冲突的深度学习框架之一。基于PyTorch构建的PyText为NLP领域应用了这些解决实验环境与生产部署之间冲突的优化原则。
理解PyText
从概念角度触发,PyText被设计为实现以下四个基本目标:
-
尽可能简单、快速的实现新模型
-
简化将预构建模型应用于新数据的工作量
-
同时为研究者和工程师定义清晰的工作流,以便构建和评估模型,并以最小的代价上线模型
-
确保部署的模型在推理时具有高性能:低延迟、高吞吐量
PyText的处理容量最终打造的建模框架,可供研究者和工程师构建端到端的训练或推理流水线。当前的PyText实现涵盖了NLP工作流声明周期中的基本环节,为快速实验、原始数据处理、指标统计、训练和模型推理提供了必要的接口。一个高层级的PyText架构图可以清晰地展示这些环节如何封装了框架的原生组件:
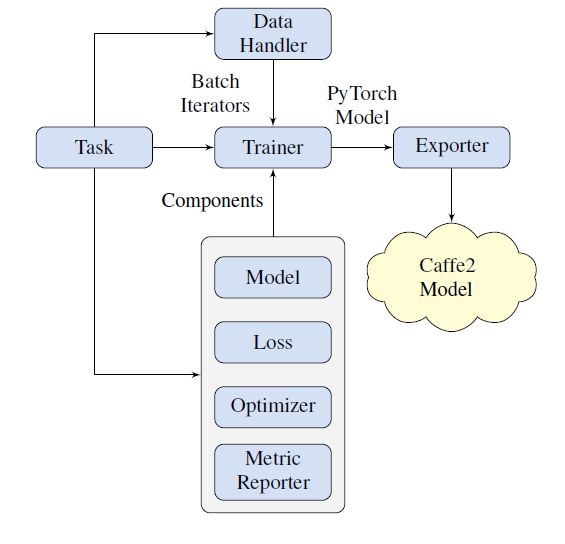
如上图所示,PyText的架构包含以下组成部分:
- Task:将多个用于训练或推理的组件拼装为一个流水线
- Data Handler:处理原始输入数据,贮备张量批数据,以便送入模型
- Model:定义神经网络的架构
- Optimizer:封装模型参数优化过程,基于模型的前馈损失进行优化
- Metric Reporter:实现模型相关指标的计算和报表提供
- Trainer: 使用数据处理器、模型、损失和优化器来训练和筛选模型
- Predictor:使用数据处理器和模型对给定的数据集进行推理
- Exporter: ONNX8导出训练好的PyTorch模型到Caffe2图
你可以看到,PyText利用ONNX(Open Neural Network Exchange Format)将模型从实验环境的PyTorch格式转换为生产环境的Caffe2运行模型。
PyText预置了众多NLP任务组件,例如文本分类、单词标注、语义分析和语言模型等,可以快速实现NLP工作流。类似的,PyText使用上下文模型介入语言理解领域,例如使用SeqNN模型用于意图标注任务,或者使用一个上下文相关的意图槽模型用于多个任务的联合训练。
从NLP工作流的角度来说,PyText可以快速将一个思路从实验阶段转换为生产阶段。一个PyText应用的典型工作流包含如下的步骤:
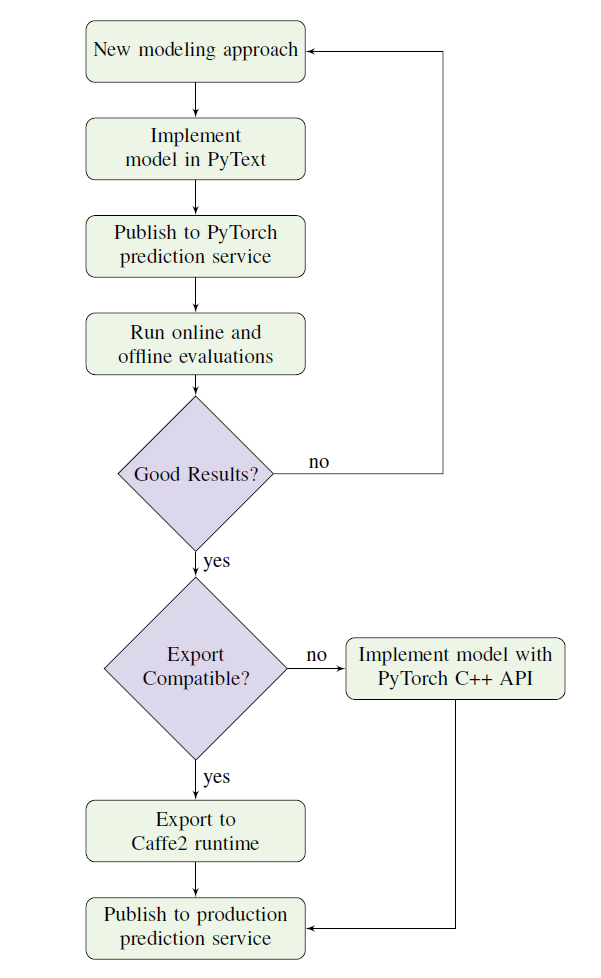
- 用PyText实现模型,确保测试集上的离线指标正确
- 将模型发布到打包的基于PyTorch的推理服务,在实时样本上执行小规模评估
- 自动导出到Caffe2网络,不过在有些情况下,例如当使用复杂的流程控制逻辑时,或者使用自定义数据结构式,PyTorch 1.0还不支持
- 如果第3步不支持,那么使用Py-Torch C++ API9重写模型,并封装为一个Caffe2操作符
- 将模型发布为生产就绪的Caffe2预测服务并启动
使用PyText
上手PyText非常简单,按标准python包的方法安装框架:
$ pip install pytext-nlp然后,我们就可以使用一个任务配置来训练NLP模型了:
(pytext) $ cat demo/configs/docnn.json
{
"task": {
"DocClassificationTask": {
"data_handler": {
"train_path": "tests/data/train_data_tiny.tsv",
"eval_path": "tests/data/test_data_tiny.tsv",
"test_path": "tests/data/test_data_tiny.tsv"
}
}
}
}
$ pytext train < demo/configs/docnn.jsonTask是PyText应用中的用来定义模型的核心部件。每一个任务都有一个嵌入的配置,它定义了不同组件之间的关系,如下面代码所示:
from word_tagging import ModelInputConfig, TargetConfig
class WordTaggingTask(Task):
class Config(Task.Config):
features: ModelInputConfig = ModelInputConfig()
targets: TargetConfig = TargetConfig()
data_handler: WordTaggingDataHandler.Config = WordTaggingDataHandler.Config()
model: WordTaggingModel.Config = WordTaggingModel.Config()
trainer: Trainer.Config = Trainer.Config()
optimizer: OptimizerParams = OptimizerParams()
scheduler: Optional[SchedulerParams] = SchedulerParams()
metric_reporter: WordTaggingMetricReporter.Config = WordTaggingMetricReporter.Config()
exporter: Optional[TextModelExporter.Config] = TextModelExporter.Config()一旦模型训练完毕,我们就可以对模型进行评估,也可以导出为Caffe2格式:
(pytext) $ pytext test < "$CONFIG"
(pytext) $ pytext export --output-path exported_model.c2 < "$CONFIG"需要指出的是,PyText提供了可扩展的架构,可以定制、扩展其中任何一个构建模块。
PyText代表了NLP开发的一个重要里程碑,它是最早解决实验与生产匹配问题的框架之一。基于Facebook和PyTorch社区的支持,PyText可能有机会称为深度学习生态中最重要的NLP技术栈之一。
汇智网翻译整理,转载请标明出处。Pytext简介
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: