
MySQL 性能优化——B+Tree 索引
0 / 6 / 创建于 7年前 /
 GameTo 的个人博客
GameTo 的个人博客
什么是索引
索引是为了实现mysql高性能查询的数据结构。
为了快速查询数据,MySql在查询算法上进行了许多优化。但是就如二叉树查找算法只能应用于二叉树数据结构一样,需要有满足这种查找算法的数据结构,而数据本身的结构可能并不能满足查找算法所需要的数据结构,所以MySql在数据之外维护了一个能应用于高效的查找算法的数据结构,这种数据结构,就是索引。
接下来将介绍使用最多的索引类型——B-Tree索引
B-Tree
B-Tree索引通常用的是B-Tree的变种B+Tree数据结构
B-Tree的节点是一个二元数组[key,data],key是记录的键,data是键对应的数据,每个节点的每个key左右各有一个指针,非叶子节点的指针分别指向下一层的节点,叶子节点的指针为null,如下图: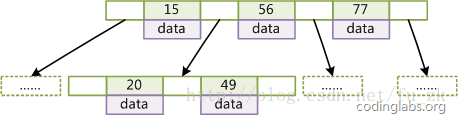
要查找值的时候,会先从根节点开始查找,根节点的每个key有左右两个指针,可以通过这两个指针访问下一层节点。每次查找都会将查找值与key值进行比较,根据比较结果找到合适的指针进入下一层节点,最终,如此重复,最终找到对应的值或者值不存在
B+Tree
B+Tree节点是B-Tree的变种,相对于B-Tree而言B+Tree有如下不同:
在每个非叶子节点只会存储key而不会存储data,data将统一存储到叶子节点中,叶子节点页不需存储指针,但是增加了指向相邻叶子节点的指针
如下图
可以使用B-Tree(B+Tree)索引的查询类型
1.全键值查找,如whre key=val的查询条件
2.键值范围查找,如where key>0此类型的范围查找
3.键前缀查找(只适合于最左前缀查找),如where key like 'abc%'有效,where key like '%abc'或where key like '%abc%'等方式都无效
B-Tree(B+Tree)索引的限制
1.只能按照最左列开始查找,否则无法使用
2.不能跳过索引中的列,例如有key(a,b,c),不能直接跳过a列使用b列索引,所以在创建索引的时候,顺序也很重要
3.如果查询中有一个列使用了范围查询,则右边所有列都不能使用索引
本作品采用《CC 协议》,转载必须注明作者和本文链接







 关于 LearnKu
关于 LearnKu




推荐文章: