
[最近面试整理] PHP 面试详解之技术篇
257 / 39 / 创建于 7年前 /
 Shine-x 的个人博客
Shine-x 的个人博客
最近在面试,总结总结遇到的面试题.
基础问题
LRU算法
[内存管理]的一种页面置换算法,对于在内存中但又不用的[数据块](内存块)叫做LRU,操作系统会根据哪些数据属于LRU而将其移出内存而腾出空间来加载另外的数据,常用于页面置换算法,是为虚拟页式存储管理服务的。
设计原则
如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。也就是说,当限定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。
实现LRU
- 1.用一个数组来存储数据,给每一个数据项标记一个访问时间戳,每次插入新数据项的时候,先把数组中存在的数据项的时间戳自增,并将新数据项的时间戳置为0并插入到数组中。每次访问数组中的数据项的时候,将被访问的数据项的时间戳置为0。当数组空间已满时,将时间戳最大的数据项淘汰。
- 2.利用一个链表来实现,每次新插入数据的时候将新数据插到链表的头部;每次缓存命中(即数据被访问),则将数据移到链表头部;那么当链表满的时候,就将链表尾部的数据丢弃。
- 3.利用链表和hashmap。当需要插入新的数据项的时候,如果新数据项在链表中存在(一般称为命中),则把该节点移到链表头部,如果不存在,则新建一个节点,放到链表头部,若缓存满了,则把链表最后一个节点删除即可。在访问数据的时候,如果数据项在链表中存在,则把该节点移到链表头部,否则返回-1。这样一来在链表尾部的节点就是最近最久未访问的数据项。
- 对于第一种方法,需要不停地维护数据项的访问时间戳,另外,在插入数据、删除数据以及访问数据时,时间复杂度都是O(n)。对于第二种方法,链表在定位数据的时候时间复杂度为O(n)。所以在一般使用第三种方式来是实现LRU算法。
http协议
一个HTTP请求报文由请求行(request line)、请求头部(header)、空行和请求数据4个部分组成
请求行
请求行由请求方法字段、URL字段和HTTP协议版本字段3个字段组成,它们用空格分隔。
GET
常见的一种请求方式,当客户端要从服务器中读取文档时,当点击网页上的链接或者通过在浏览器的地址栏输入网址来浏览网页 的,使用的都是GET方式。GET方法要求服务器将URL定位的资源放在响应报文的数据部分,回送给客户端。使用GET方法时,请 求参数和对应的值附加在URL后面,利用一个问号(“?”)代表URL的结尾与请求参数的开始,传递参数长度受限制。例 如,/index.jsp?id=100&op=bind,这样通过GET方式传递的数据直接表示在地址中,所以我们可以把请求结果以链接的形式发 送给好友
POST
使用POST方法可以允许客户端给服务器提供信息较 多。POST方法将请求参数封装在HTTP请求数据中,以名称/值的形式出现,可以传输大量数据,这样POST方式对传送的数据大 小没有限制,而且也不会显示在URL中,POST方式请求行中不包含数据字符串,这些数据保存在”请求内容”部分,各数据之间也是使用”&”符号隔开。POST方 式大多用于页面的表单中。因为POST也能完成GET的功能,因此多数人在设计表单的时候一律都使用POST方式,其实这是一个 误区。
HEAD
HEAD就像GET,只不过服务端接受到HEAD请求后只返回响应头,而不会发送响应内容。当我们只需要查看某个页面的状态的时 候,使用HEAD是非常高效的,因为在传输的过程中省去了页面内容。
请求头部
- 请求头部由关键字/值对组成,每行一对,关键字和值用英文冒号“:”分隔。
- 请求头部通知服务器有关于客户端请求的信息,典型的 请求头有:
- UserAgent:产生请求的浏览器类型。
- Accept:客户端可识别的内容类型列表。
- Host:请求的主机名,允许多个域名同处一个IP地址,即虚拟主机。
空行
后一个请求头之后是一个空行,发送回车符和换行符,通知服务器以下不再有请求头。
请求数据
请求数据不在GET方法中使用,而是在POST方法中使用。POST方法适用于需要客户填写表单的场合。与请求数据相关的常使 用的请求头是ContentType和ContentLength。
HTTP相应报文
HTTP响应也由三个部分组成,分别是:状态行、消息响应头、响应正文。
状态码
- 1xx:指示信息表示请求已接收,继续处理。
- 2xx:成功表示请求已被成功接收、理解、接受。
- 3xx:重定向要完成请求必须进行更进一步的操作。
- 4xx:客户端错误请求有语法错误或请求无法实现。
- 5xx:服务器端错误服务器未能实现合法的请求。
常见状态代码、状态描述的说明如下
- 200 OK:客户端请求成功。
- 400 Bad Request:客户端请求有语法错误,不能被服务器所理解。
- 401 Unauthorized:请求未经授权,这个状态代码必须和WWWAuthenticate报头域一起使用。
- 403 Forbidden:服务器收到请求,但是拒绝提供服务。
- 404 Not Found:请求资源不存在,举个例子:输入了错误的URL。 500 Internal Server Error:服务器发生不可预期的错误。
- 503 Server Unavailable:服务器当前不能处理客户端的请求,一段时间后可能恢复正常,举个例子:HTTP/1.1 200 OK(CRLF)。
GET和POST
- GET提交,请求的数据会附在URL之后(就是把数据放置在HTTP协议头<requestline>中),以?分割URL和传输数据,多个 参数用&连接;如果数 据是英文字母/数字,原样发送,如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64加密,,GET提交的数据会在地址栏中显示出来,而POST提交,地址栏不会改变, POST提交:把提交的数据放置在是HTTP包的包体<request body>中。
- HTTP协议没有对传输的数据大小进行限制,HTTP协议规范也没有对URL长度进行限制。 而在实际开发中存在的限制 主要有:
- GET:特定浏览器和服务器对URL长度有限制,例如IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如 Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持。
- 因此对于GET提交时,传输数据就会受到URL长度的限制。
- POST:由于不是通过URL传值,理论上数据不受限。但实际各个WEB服务器会规定对post提交数据大小进行限制,Apache、 IIS6都有各自的配置。
- POST的安全性要比GET的安全性高。注意:这里所说的安全性和上面GET提到的“安全”不是同个概念。上面“安全”的含义仅仅 是不作数据修改,而这里安全的含义是真正的Security的含义,比如:通过GET提交数据,用户名和密码将明文出现在URL上,因 为(1)登录页面有可能被浏览器缓存, (2)其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了,
数据类型
- 标量 :boolean (布尔型)integer (整型)float (浮点型, 也称作 double) string (字符串)
- 复合 :数组 对象
- 特殊 :NULL resource(资源)
常见的header头
- // 信息型状态码,提示目前为止一切正常,客户端应该继续请求, 如果已完成请求则忽略.
- header(‘HTTP/1.1 100 OK’);
- //通知浏览器 页面不存在
- header(‘HTTP/1.1 404 Not Found’);
- //资源被永久的重定向 301 ;302:临时重定向(该资源临时被改变位置)
- header(‘HTTP/1.1 301 Moved Permanently’);
- //跳转到一个新的地址
- header(‘Location: php.itcast.cn/');
- //延迟转向也就是隔几秒跳转
- header(‘Refresh:10;url=php.itcast.cn/');
内容类型
- //网页编码
- header(‘Content-Type: text/html;charset=utf-8’);
- //纯文本格式
- header(‘Content-Type:text/plain’);
- //JPG、JPEG
- header(‘Content-Type:image/jpeg’);
- //ZIP文件
- header(‘Content-Type:application/zip’);
- //PDF文件
- header(‘Content-Type:application/pdf’);
- //音频文件
- header(‘Content-Type: ‘);
- //css文件
- header(‘Content-type:text/css’);
- ###声明一个下载的文件###
- header(‘Content-Type:application/octet-stream’);
- header(‘Content-Disposition:attachment;filename=”ITblog.zip”‘);
- ###显示一个需要验证的登陆对话框###
- header(‘HTTP/1.1 401Unauthorized’);
- header(‘WWW-Authenticate:Basic realm=”TopSecret”‘);
魔术方法
- __autoload() 类文件自动加载函数
- __construct() 构造函数,PHP将在对象创建时调用这个方法
- __destruct() 析构函数,PHP将在对象被销毁前(即从内存中清除前)调用这个方法
- __call() 当所调用的成员方法不存在(或者没有权限)该类时调用,用于对错误后做一些操作或者提示信息
- __clone() 该函数在对象克隆时自动调用,其作用是对克隆的副本做一些初始化操作
- __get() 当所对象所调用的成员属性未声明或者级别为private或者protected等时,我们可以在这个函数里进行自己的一些操作
- __set() 当所对未声明或者级别为private或者protected等进行赋值时调用此函数,我们可以在这个函数里进行自己的一些操作
- __isset() 当对一个未声明或者访问级别受限的成员属性调用isset函数时调用此函数,共用户做一些操作
- __unset() 当对一个未声明或者访问级别受限的成员属性调用unset函数时调用此函数,共用户做一些操作
- __toString()函数 该函数在将对象引用作为字符串操作时自动调用,返回一个字符串
- __sleep()函数 该函数是在序列化时自动调用的,序列化这里可以理解成将信息写如文件中更长久保存
- __wakeup()函数 该魔术方法在反序列化的时候自动调用,为反序列化生成的对象做一些初始化操作
- invoke()函数,当尝试以调用函数的方式调用一个对象时,invoke 方法会被自动调用。
- _callStatic()函数,它的工作方式类似于 call() 魔术方法,callStatic() 是为了处理静态方法调用,
超全局变量
- $GLOBALS是PHP的一个超级全局变量组,在一个PHP脚本的全部作用域中都可以访问。是一个包含了全部变量的全局组合数组。变量的名字就是数组的键。
- $_SERVER是一个包含了诸如头信息(header)、路径(path)、以及脚本位置(script locations)等等信息的数组。这个数组中的项目由 Web 服务器创建。不能保证每个服务器都提供全部项目;服务器可能会忽略一些,或者提供一些没有在这里列举出来的项目。
- $_REQUEST 用于收集HTML表单提交的数据。
- $_POST 被广泛应用于收集表单数据,在HTML form标签的指定该属性:”method=”post”。
- $_GET 同样被广泛应用于收集表单数据,在HTML form标签的指定该属性:”method=”get”。
- $_COOKIE 经由 HTTP Cookies 方法提交至脚本的变量
- $_SESSION 当前注册给脚本会话的变量。类似于旧数组 $HTTP_SESSION_VARS 数组。
- $_FILES 经由 HTTP POST 文件上传而提交至脚本的变量。类似于旧数组 $HTTP_POST_FILES 数组。
- $_ENV 执行环境提交至脚本的变量。类似于旧数组 $HTTP_ENV_VARS 数组。
http 和 https 区别
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
hash取模算法
hash算法
分布式cahce系统中的一致性hash算法应该满足以下几个方面
平衡性(Balance)
哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
单调性(Monotonicity)
如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区。简单的哈希算法往往不能满足单调性的要求,如最简单的线性哈希:x = (ax + b) mod (P),在上式中,P表示全部缓冲的大小。不难看出,当缓冲大小发生变化时(从P1到P2),原来所有的哈希结果均会发生变化,从而不满足单调性的要求。哈希结果的变化意味着当缓冲空间发生变化时,所有的映射关系需要在系统内全部更新。而在P2P系统内,缓冲的变化等价于Peer加入或退出系统,这一情况在P2P系统中会频繁发生,因此会带来极大计算和传输负荷。单调性就是要求哈希算法能够应对这种情况。
分散性(Spread)
在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
负载(Load)
负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
平滑性(Smoothness)
平滑性是指缓存服务器的数目平滑改变和缓存对象的平滑改变是一致的。
hash取模算法
常用的算法是对hash结果取余数 (hash() mod N):对机器编号从0到N-1,按照自定义的hash()算法,对每个请求的hash()值按N取模,得到余数i,然后将请求分发到编号为i的机器。但这样的算法方法存在致命问题,如果某一台机器宕机,那么应该落在该机器的请求就无法得到正确的处理,这时需要将当掉的服务器从算法从去除,此时候会有(N-1)/N的服务器的缓存数据需要重新进行计算;
为何是 (N-1)/N 呢
- 比如有 3 台机器,hash值 1-6 在这3台上的分布就是:
- host 1: 1 4
- host 2: 2 5
- host 3: 3 6
- 如果挂掉一台,只剩两台,模数取 2 ,那么分布情况就变成:
- host 1: 1 3 5
- host 2: 2 4 6
- 可以看到,还在数据位置不变的只有2个: 1,2,位置发生改变的有4个,占共6个数据的比率是 4/6 = 2/3。
虚拟节点
- 对于hash取模算法,当某个节点的服务器坏了,算有压力将转到下个节点的服务器。那我们考虑是否能够将压力转到其他节点。
- 虚拟节点即:N个真实节点,把每个真实节点映射成M个虚拟节点, 再把M* N个虚拟节点,
- 散列在圆环上. 各真实节点对应的虚拟节点相互交错分布,这样,某真实节点down后,则把其影响平均分担到其他所有节点上。
访问方法:
如果有一个写入缓存的请求,其中Key值为K,计算器hash值Hash(K), Hash(K) 对应于环中的某一个点,如果该点对应没有映射到具体的某一个机器节点,那么顺时针查找,直到第一次找到有映射机器的节点,该节点就是确定的目标节点,如果超过了2^32仍然找不到节点,则命中第一个机器节点。
一致性哈希算法
一种特殊的哈希算法,目前主要应用于分布式缓存当中,可以有效地解决分布式存储结构下动态增加和删除节点所带来的问题。
- 一致性Hash算法是对2^32取模,2^32个点组成的圆环称为Hash环。根据服务节点的IP或者机器名称进行哈希,就能确定每台机器就能确定其在哈希环上的位置;
- 将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
- 添加、删除节点的时候,只影响相邻一个节点的数据,其他节点的数据不影响。具有较好的扩展性和容错性。
- 为了防止数据分布不均匀,可以应用虚拟节点来映射物理节点。
hash槽
Redis准备了16384个hash槽,类似于Memcached Hash环上的一个个位置。 这16384个hash槽被分配给不同节点,存放数据时,根据数据的key计算出所在的槽,再根据槽找到对应的机器。hash函数为:CRC16(key) % 16384。
为什么是16384?
我们需要维护节点和槽之间的映射关系,每个节点需要知道自己有哪些槽,并且需要在结点之间传递这个消息。为了节省存储空间,每个节点用一个Bitmap来存放其对应的槽: 2k = 210248 = 16384,也就是说,每个结点用2k的内存空间,总共16384个比特位,就可以存储该结点对应了哪些槽。然后这2k的信息,通过Gossip协议,在结点之间传递。
php远程获取文件
第一种:file_get_contents
$url = 'http://www.xxx.com/';
$contents = file_get_contents($url)curl
** 第二种使用 curl **
$url = “http://www.xxx.com/”;
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);\
$contents = curl_exec($ch);第三种
3.fopen->fread->fclose
$handle = fopen (“http://www.xxx.com/”, “rb”);
$data = fread($handle, 8192)一般我们使用 curl 来进行 文章的抓取 他可以设置 超时时间 比较方便
怎么解决请求被劫持的问题
推荐用https,充分测试无问题以后在服务器端配置HSTS头,但即使这样也还不能解决首次访问时的劫持问题,不过已经能解决绝大部分的问题了。如果是个人网站,建议直接用sha2的证书,sha1的证书已经不安全了,双证书费用和维护成本都不低,何况第三方浏览器现在是流量的大头
用户输入url到页面显示经历了哪些
*通过DNS找对应的IP *
- 找浏览器缓存,浏览器会保存一段时间你之前访问过的一些网址的DNS信息
- 通过dns 找 域 名对应ip 本地的 host 通过dns 找 域名对应ip
- 接着会发送一个请求到路由器上,然后路由器在自己的路由器缓存上查找记录,路由器一 般也存有DNS信息。
- 通过dns 找 域名对应ip 你的ISP的DNS服务器会将请求发向根域名服务器进行搜通过dns 找 域名对应ip
*通过IP 向对应的web服务器发送请求 *
浏览器终于得到了IP以后,浏览器接着给这个IP的服务器发送了一个http请求,方式为get,例如访问nbut.cn
*服务器接受到请求后,如果是nginx 通过nginx的location匹配 后缀是.php的文件, 然后如果是,则将这个请求转发到127.0.0.1:9000的个服务,而9000 这个服务是PHP, 把请求交给php来进行处理,php处理完毕,把处理的数据发送给nginx ,nginx把数据再 相应,并发送给浏览器 *
服务器收到浏览器的请求以后(其实是WEB服务器接收到了这个请求,WEB服务器有iis、 apache等 会解析这个请求(读请求头),然后生成一个响应头和具体响应内容 如果是个静态页面,那么基本上到这一步就没了
页面还有其他资源(css img js ) 继续重复执行
主页(index)页面框架传送过来以后,浏览器还要继续向服务器发送请求,请求的内容是 主页里面包含的一些资源,如图片,视频,css样式等等
mysql
建表,修改字段,字段类型
事务
事务(transaction)是作为一个单元的一组有序的数据库操作。如果组中的所有操作都成功,则认为事务成功,即使只有一个操作失败,事务也不成功。如果所有操作完成,事务则提交,其修改将作用于所有其他数据库进程。如果一个操作失败,则事务将回滚,该事务所有操作的影响都将取消。
事务控制语句
- BEGIN 或 START TRANSACTION 显式地开启一个事务;
- COMMIT 也可以使用 COMMIT WORK,不过二者是等价的。COMMIT 会提交事务,并使已对数据库进行的所有修改成为永久性的;
- ROLLBACK 也可以使用 ROLLBACK WORK,不过二者是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改;
- SAVEPOINT identifier,SAVEPOINT 允许在事务中创建一个保存点,一个事务中可以有多个 SAVEPOINT;
- RELEASE SAVEPOINT identifier 删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常;
- ROLLBACK TO identifier 把事务回滚到标记点;
- SET TRANSACTION 用来设置事务的隔离级别。
- InnoDB 存储引擎提供事务的隔离级别有READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ 和 SERIALIZABLE。
事务的处理方法
- 用 BEGIN, ROLLBACK, COMMIT来实现
- BEGIN 开始一个事务
- ROLLBACK 事务回滚
- COMMIT 事务确认
- 直接用 SET 来改变 MySQL 的自动提交模式:
- SET AUTOCOMMIT=0 禁止自动提交
- SET AUTOCOMMIT=1 开启自动提交
例
php实现事务
mysql_query("COMMIT");//提交事务mysql_query("ROLLBACK");//至少有一条sql语句执行错误,事务回滚mysql_query("END");//事务结束mysqli
$conn = mysqli_connect('127.0.0.1', 'root', 'root') or die(mysqli_error()); //连接数据库 mysqli_query($conn, 'BEGIN'); //开启事务mysqli_query($conn, 'COMMIT'); //提交事务mysqli_query($conn, 'rollBack'); //回滚事务php的PDO的实现方式 $pdo为实例化PDO对象
//1.开启事务 $pdo->beginTransaction();//提交事务 $pdo->commit();//回滚事务 $pdo->rollBack();//结束事务 $pdo->end();TP实现事务
无model
// 启动事务 Db::startTrans();// 提交事务 Db::commit(); // 回滚事务 Db::rollback();有model
$model=M('myself_audio');//事务开启 $model->startTrans();//事务提交 $model->commit(); // 事务回滚 $model->rollback();laravel框架实现事务
想要在一个数据库事务中运行一连串操作,可以使用DB门面的transaction方法,如果事务闭包中抛出异常,事务将会自动回滚。如果闭包执行成功,事务将会自动提交。
DB::transaction(function () {
DB::table('users')->update(['votes' => 1]);
DB::table('posts')->delete();
});手动使用事务
DB::beginTransaction(); //开启事务DB::commit(); //事务提交DB::rollBack(); // 事务回滚 四大特性
- 原子性(Autmic):事务在执行性,要做到“要么不做,要么全做!”,就是说不允许事务部分得执行。即使因为故障而使事务不能完成,在rollback时也要消除对数据库得影响!
- 一致性(Consistency):事务得操作应该使使数据库从一个一致状态转变倒另一个一致得状态!就拿网上购物来说吧,你只有即让商品出库,又让商品进入顾客得购物篮才能构成事务!
- 隔离性(Isolation):如果多个事务并发执行,应象各个事务独立执行一样!
- 持久性(Durability):一个成功执行得事务对数据库得作用是持久得,即使数据库应故障出错,也应该能够恢复!
四种隔离级别
- 读未提交(read-uncommitted)所有事务都可以看到其他未提交事务的执行结果。很少用于实际应用,因为它的性能也不比其他级别好多少。会产生脏读,不可重复读以及幻读
- 不可重复读(read-committed)这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。会产生不可重复读,幻读
- 可重复读(repeatable-read)这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
- 串行化(serializable)这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
操作
- 查看当前会话隔离级别
select @@tx_isolation; - 查看系统当前隔离级别
select @@global.tx_isolation; - 设置当前会话隔离级别
set session transaction isolatin level repeatable read; - 设置系统当前隔离级别
set global transaction isolation level repeatable read; - 命令行,开始事务时
set autocommit=off 或者 start transaction
锁机制
锁是计算机协调多个进程或纯线程并发访问某一资源的机制。在数据库中,除传统的计算资源(CPU、RAM、I/O)的争用以外,数据也是一种供许多用户共享的资源。如何保证数据并发访问的一致性、有效性是所在有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。从这个角度来说,锁对数据库而言显得尤其重要,也更加复杂。
mysql的三种锁
- 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
- 行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
表级锁的锁模式(MyISAM)
- MySQL表级锁有两种模式:表共享锁(Table Read Lock)和表独占写锁(Table Write Lock)。
- 对MyISAM的读操作,不会阻塞其他用户对同一表请求,但会阻塞对同一表的写请求;
- 对MyISAM的写操作,则会阻塞其他用户对同一表的读和写操作;
- MyISAM表的读操作和写操作之间,以及写操作之间是串行的。
- 当一个线程获得对一个表的写锁后,只有持有锁线程可以对表进行更新操作。其他线程的读、写操作都会等待,直到锁被释放为止。
对MyISAM表的读操作,不会阻塞其他用户对同一表的读请求,但会阻塞对同一表的写请求;对MyISAM表的写操作,则会阻塞其他用户对同一表的读和写请求;MyISAM表的读和写操作之间,以及写和写操作之间是串行的!(当一线程获得对一个表的写锁后,只有持有锁的线程可以对表进行更新操作。其他线程的读、写操作都会等待,直到锁被释放为止。)
如何加表锁
MyISAM在执行查询语句(SELECT)前,会自动给涉及的所有表加读锁,在执行更新操作(UPDATE、DELETE、INSERT等)前,会自动给涉及的表加写锁,这个过程并不需要用户干预,因此用户一般不需要直接用LOCK TABLE命令给MyISAM表显式加锁。
一些命令
查询表级锁争用情况
show status like 'table%';如何加表锁
加读锁/表共享锁(Table Read Lock):
lock table tbl_name read;加写锁/表独占写锁(Table Write Lock):
lock table tbl_name write;释放锁:
unlock tables;并发锁
- 在一定条件下,MyISAM也支持查询和操作的并发进行。
- MyISAM存储引擎有一个系统变量concurrent_insert,专门用以控制其并发插入的行为,其值分别可以为0、1或2。
- 当concurrent_insert设置为0时,不允许并发插入。
- 当concurrent_insert设置为1时,如果MyISAM允许在一个读表的同时,另一个进程从表尾插入记录。这也是MySQL的默认设置。
- 当concurrent_insert设置为2时,无论MyISAM表中有没有空洞,都允许在表尾插入记录,都允许在表尾并发插入记录。
- 可以利用MyISAM存储引擎的并发插入特性,来解决应用中对同一表查询和插入锁争用。例如,将concurrent_insert系统变量为2,总是允许并发插入;同时,通过定期在系统空闲时段执行OPTIMIZE TABLE语句来整理空间碎片,收到因删除记录而产生的中间空洞。
MyISAM的锁调度
- 大量的更新操作会造成查询操作很难获得读锁,从而可能永远阻塞。我们可以通过一些设置来调节MyISAM的调度行为。
- 通过指定启动参数low-priority-updates,使MyISAM引擎默认给予读请求以优先的权利。
- 通过执行命令SET LOW_PRIORITY_UPDATES=1,使该连接发出的更新请求优先级降低。
- 通过指定INSERT、UPDATE、DELETE语句的LOW_PRIORITY属性,降低该语句的优先级。
- 虽然上面3种方法都是要么更新优先,要么查询优先的方法,但还是可以用其来解决查询相对重要的应用(如用户登录系统)中,读锁等待严重的问题。
- 另外,MySQL也提供了一种折中的办法来调节读写冲突,即给系统参数max_write_lock_count设置一个合适的值,当一个表的读锁达到这个值后,MySQL变暂时将写请求的优先级降低,给读进程一定获得锁的机会。
- 注意:一些需要长时间运行的查询操作,也会使写进程“饿死”!因此,应用中应尽量避免出现长时间运行的查询操作,不要总想用一条SELECT语句来解决问题。因为这种看似巧妙的SQL语句,往往比较复杂,执行时间较长,在可能的情况下可以通过使用中间表等措施对SQL语句做一定的“分解”,使每一步查询都能在较短时间完成,从而减少锁冲突。如果复杂查询不可避免,应尽量安排在数据库空闲时段执行,比如一些定期统计可以安排在夜间执行。
INNODB锁
并发问题
1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
3、幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
4、更新丢失(Lost Update):当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,由于每个事务都不知道其他事务的存在,就会发生丢失更新问题--最后的更 新覆盖了由其他事务所做的更新。例如,两个编辑人员制作了同一文档的电子副本。每个编辑人员独立地更改其副本,然后保存更改后的副本,这样就覆盖了原始文 档。最后保存其更改副本的编辑人员覆盖另一个编辑人员所做的更改。如果在一个编辑人员完成并提交事务之前,另一个编辑人员不能访问同一文件,则可避免此问题。
不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
查看InonoD行锁争用情况
show status like 'innodb_row_lock%';打开监视器
CREATE TABLE innodb_monitor(a INT) ENGINE=INNODB;
Show innodb status\G;停止监视器
DROP TABLE innodb_monitor;打开监视器以后,默认情况下每15 秒会向日志中记录监控的内容,如果长时间打开会导致.err 文件变得非常的巨大,所以用户在确认问题原因之后,要记得删除监控表以关闭监视器,或者通过使用“–console”选项来启动服务器以关闭写日志文件。
锁机制
共享锁和排它锁
- InnoDB实现了标准的行级锁,有两种类型:共享锁(S锁)允许事务持有锁并读取一行记录和排它锁(X锁)允许事务持有并更新或者删除一行记录。
- 如果事务T1持有行记录r的上一个共享(S)锁,接着另一个事务T2请求行记录r上的锁
- 如果事务T1持有r上的排它(X)锁,事务T2请求任意一个锁都不立刻获得。此时,T2必须等待T1释放r上的锁。
上共享锁的写法:lock in share mode
例如:
select math from zje where math>60 lock in share mode;上排它锁的写法:for update
例如:
select math from zje where math >60 for update;注意
- 行锁必须有索引才能实现,否则会自动锁全表,那么就不是行锁了。
- 两个事务不能锁同一个索引,例如:
- 事务A先执行:
select math from zje where math>60 for update; - 事务B再执行:
select math from zje where math<60 for update; - 这样的话,事务B是会阻塞的。如果事务B把 math索引换成其他索引就不会阻塞,
- 但注意,换成其他索引锁住的行不能和math索引锁住的行有重复。
- 事务A先执行:
- insert ,delete , update在事务中都会自动默认加上排它锁。
意向锁
- InnoDB支持多粒度的锁,多粒度的锁允许行锁和表锁共存。为了在实际中实现多粒度的锁,使用了另外一种类型的锁:意向锁。在InnoDB中,意向锁是表级锁,它标明了一个事务在将在表中行记录上使用锁的类型(共享锁和排它锁)。在InnoDB中使用了两种意向锁(假设事务T请求了表t上的锁)
- 意向共享锁(IS):事务T打算在表t的某些行设置S共享锁。
- 意向排它锁(IX)::事务T打算在表t的某些行设置T排他锁。
- 意向锁的协议如下:
- 一个事务获得表t中某行的共享锁之前,必须先获得t表上的IS意向共享锁或者更强类型的锁。
- 一个事务获得表t中某行的排他锁之前, 必须先获得t表上的IX意向排它锁。
- IX意向共享锁和IS意向排它锁的主要目的是显示有人锁定了一行记录或者准备锁定一行记录。
记录锁
- 记录锁是索引记录上的锁。SELECT c1 FOR UPDATE FROM t WHERE c1 = 10;可以防止任何其它事务插入、 更新或删除t.c1等于10的行。
- 记录锁锁定的是索引,即使表没有定义索引。这种情况下,InnoDB会创建一个隐式的聚簇索引并将此索引用作记录锁。
间隙锁
- 间隙锁会锁定一个范围内的索引,或者是某索引记录之前或者之后的索引。例如,SELECT c1 FOR UPDATE FROM t WHERE c1 BETWEEN 10 and 20;可以防止其他事务将一个t.c1等于15的值插入到表中,无论列中是否有该记录,因为该范围内所有可能存在的值都被锁定。
- 间隙有可能跨越单索引值,多个索引值,甚至空值。
- 在InnoDB中,间隙锁是“完全被抑制”的,意思是它只阻止其它事务给往间隙中插入。它们不阻止其他事务在同一个间隙上获得间隙锁。因此,一个间隙X锁和一个间隙S锁效果一样
Next-Key锁
- Next-Key锁是索引记录上的记录锁与此索引记录之前间隙上的间隙锁两者的结合。InnoDB在查找或扫描索引时使用行级锁,给遇到的索引记录上设置共享锁或者排它锁。因此,行级锁就是索引记录锁。一个索引记录上的next-key锁也影响在该索引之间的“间隙”。也就是说,next-key是一个索引记录锁加上在该索引记录之前间隙上的间隙锁。如果一个会话在记录R的索引上持有一个共享锁或者排它锁,另一个会话无法在在R的索引之前立刻插入一个新的索引记录。
- InnoDB使用next-key锁查找和扫描索引,阻止了幻行。
插入意向锁
插入意向锁时在插入行前设置的一种间隙锁。这个锁示意如果多个事务感兴趣的不是索引区间中的同一个位置,则事务在同一个索引区间插入不需要相互等待。假设有索引记录值为4和7的行。两个事务分别尝试插入5和6,分别用插入意向锁锁住4和7之间的间隙,然后再取得插入行的排它锁,但是锁相互不会冲突,因为插入行没有冲突。
自动增长锁
- 自动增长锁是一个特殊的表级锁,事务持有它用于给带有auto_increment列的表插入数据。在最简单的情况下,如果一个事务正在给表中插入数据,其他的事务想要插入数据,必须等待,这样第一个事务才能插入具有连续主键的值。
- innodb_autoinc_lock_mode配置选项控制用于自动增长锁的算法。它允许你选择如何权衡可预测的自动增长值序列和最大的插入操作并发性
空间索引的预测锁
- 在MySQL 5.7.5,InnoDB支持包含空间数据列的空间索引
- 为了使得空间索引支持隔离级别,InoDB使用预测锁。一个空间索引包含最小边界矩形 (MBR)值,所以InnoDB通过在MBR上设置预测锁来查询数据,强制一致性读。其它事务不能插入或修改与查询条件匹配的行。
InnoDB的行锁模式及加锁方法
InnoDB的行锁有两种:共享锁(S)和排他锁(X)。为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB还有两种内部使用的意向锁:意向共享锁和意向排他锁,这两种意向锁都是表锁。一个事务在给数据行加锁之前必须先取得对应表对应的意向锁。
- 两种类型的行锁。
- 共享锁(s):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
- 排他锁(X):允许获取排他锁的事务更新数据,阻止其他事务取得相同的数据集共享读锁和排他写锁。
- 另外,为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB还有两种内部使用的意向锁(Intention Locks),这两种意向锁都是表锁。
- 意向共享锁(IS):事务打算给数据行共享锁,事务在给一个数据行加共享锁前必须先取得该表的IS锁。
- 意向排他锁(IX):事务打算给数据行加排他锁,事务在给一个数据行加排他锁前必须先取得该表的IX锁。
- 如果一个事务请求的锁模式与当前的锁兼容,InnoDB就请求的锁授予该事务;反之,如果两者两者不兼容,该事务就要等待锁释放。
- 意向锁是InnoDB自动加的,不需用户干预。对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及及数据集加排他锁(X);对于普通SELECT语句,InnoDB会自动给涉及数据集加排他锁(X);对于普通SELECT语句,InnoDB不会任何锁;事务可以通过以下语句显示给记录集加共享锁或排锁。
- 共享锁(S):SELECT * FROM table_name WHERE … LOCK IN SHARE MODE
- 排他锁(X):SELECT * FROM table_name WHERE … FOR UPDATE
- 释放锁:unlock tables;(会隐含提交事务)
- 用SELECT .. IN SHARE MODE获得共享锁,主要用在需要数据依存关系时确认某行记录是否存在,并确保没有人对这个记录进行UPDATE或者DELETE操作。但是如果当前事务也需要对该记录进行更新操作,则很有可能造成死锁,对于锁定行记录后需要进行更新操作的应用,应该使用SELECT … FOR UPDATE方式获取排他锁。
InnoDB行锁实现方式
- InnoDB行锁是通过给索引上的索引项加锁来实现的,InnoDB 这种行锁实现特点意味着:
- 只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB 将使用表锁。
- 由于MySQL的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行的记录,但是如果是使用相同的索引键,是会出现锁冲突的。
- 当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行,另外,不论是使用主键索引、唯一索引或普通索引,InnoDB 都会使用行锁来对数据加锁。(虽然使用的是不同的索引,但是如果记录已经被其他session锁定的话也是需要等待的。)
- 即便在条件中使用了索引字段,但是否使用索引来检索数据是由MySQL 通过判断不同执行计划的代价来决定的,如果MySQL 认为全表扫描效率更高,比如对一些很小的表,它就不会使用索引,这种情况下InnoDB将使用表锁,而不是行锁。
什么时候使用表锁
- 第一种情况是:事务需要更新大部分或全部数据,表又比较大,如果使用默认的行锁,不仅这个事务执行效率低,而且可能造成其他事务长时间锁等待和锁冲突,这种情况下可以考虑使用表锁来提高该事务的执行速度。
- 第二种情况是:事务涉及多个表,比较复杂,很可能引起死锁,造成大量事务回滚。这种情况也可以考虑一次性锁定事务涉及的表,从而避免死锁、减少数据库因事务回滚带来的开销。
- 当然,应用中这两种事务不能太多,否则,就应该考虑使用MyISAM表。
- 在InnoDB下 ,使用表锁要注意以下两点。
- 使用LOCK TALBES虽然可以给InnoDB加表级锁,但必须说明的是,表锁不是由InnoDB存储引擎层管理的,而是由其上一层MySQL Server负责的,仅当autocommit=0、innodb_table_lock=1(默认设置)时,InnoDB层才能知道MySQL加的表锁,MySQL Server才能感知InnoDB加的行锁,这种情况下,InnoDB才能自动识别涉及表级锁的死锁;否则,InnoDB将无法自动检测并处理这种死锁。
- 在用LOCAK TABLES对InnoDB锁时要注意,要将AUTOCOMMIT设为0,否则MySQL不会给表加锁;事务结束前,不要用UNLOCAK TABLES释放表锁,因为UNLOCK TABLES会隐含地提交事务;COMMIT或ROLLBACK产不能释放用LOCAK TABLES加的表级锁,必须用UNLOCK TABLES释放表锁,正确的方式见如下语句。
总结
MyISAM表锁
(1)共享读锁(S)之间是兼容的,但共享读锁(S)和排他写锁(X)之间,以及排他写锁之间(X)是互斥的,也就是说读和写是串行的。
(2)在一定条件下,MyISAM允许查询和插入并发执行,我们可以利用这一点来解决应用中对同一表和插入的锁争用问题。
(3)MyISAM默认的锁调度机制是写优先,这并不一定适合所有应用,用户可以通过设置LOW_PRIPORITY_UPDATES参数,或在INSERT、UPDATE、DELETE语句中指定LOW_PRIORITY选项来调节读写锁的争用。
(4)由于表锁的锁定粒度大,读写之间又是串行的,因此,如果更新操作较多,MyISAM表可能会出现严重的锁等待,可以考虑采用InnoDB表来减少锁冲突。
InnoDB表
(1)InnoDB的行销是基于索引实现的,如果不通过索引访问数据,InnoDB会使用表锁。
(2)InnoDB间隙锁机制,以及InnoDB使用间隙锁的原因。
(3)在不同的隔离级别下,InnoDB的锁机制和一致性读策略不同。
(4)MySQL的恢复和复制对InnoDB锁机制和一致性读策略也有较大影响。
(5)锁冲突甚至死锁很难完全避免。
减少锁冲突和死锁
- 尽量使用较低的隔离级别
- 精心设计索引,并尽量使用索引访问数据,使加锁更精确,从而减少锁冲突的机会。
- 选择合理的事务大小,小事务发生锁冲突的几率也更小。
- 给记录集显示加锁时,最好一次性请求足够级别的锁。比如要修改数据的话,最好直接申请排他锁,而不是先申请共享锁,修改时再请求排他锁,这样容易产生死锁。
- 不同的程序访问一组表时,应尽量约定以相同的顺序访问各表,对一个表而言,尽可能以固定的顺序存取表中的行。这样可以大减少死锁的机会。
- 尽量用相等条件访问数据,这样可以避免间隙锁对并发插入的影响。
- 不要申请超过实际需要的锁级别;除非必须,查询时不要显示加锁。
- 对于一些特定的事务,可以使用表锁来提高处理速度或减少死锁的可能。
INNODB MVCC
- MVCC (Multiversion Concurrency Control),即多版本并发控制技术,它使得大部分支持行锁的事务引擎,不再单纯的使用行锁来进行数据库的并发控制,取而代之的是把数据库的行锁与行的多个版本结合起来,只需要很小的开销,就可以实现非锁定读,从而大大提高数据库系统的并发性能
- innodb MVCC主要是为Repeatable-Read(可重复读)事务隔离级别做的。在此隔离级别下,A、B客户端所示的数据相互隔离,互相更新不可见
- 具体的执行拿select,insert,update和delete来说,
- Select Innodb检查每行数据,确保他们符合两个标准:
- 1、InnoDB只查找版本早于当前事务版本的数据行(也就是数据行的版本必须小于等于事务的版本),这确保当前事务读取的行都是事务之前已经存在的,或者是由当前事务创建或修改的行
- 2、行的删除操作的版本一定是未定义的或者大于当前事务的版本号,确定了当前事务开始之前,行没有被删除
- 符合了以上两点则返回查询结果。
- INSERT InnoDB为每个新增行记录当前系统版本号作为创建ID。
- DELETE InnoDB为每个删除行的记录当前系统版本号作为行的删除ID。
- UPDATE InnoDB复制了一行。这个新行的版本号使用了系统版本号。它也把系统版本号作为了删除行的版本。
MYSQL死锁
产生的原因
竞争资源
- 产生死锁中的竞争资源之一指的是竞争不可剥夺资源 [当系统把这类资源分配给某进程后,再不能强行收回,只能在进程用完后自行释放,如磁带机、打印机等](例如:系统中只有一台打印机,可供进程P1使用,假定P1已占用了打印机,若P2继续要求打印机打印将阻塞)
- 产生死锁中的竞争资源另外一种资源指的是竞争临时资源 [指某进程在获得这类资源后,该资源可以再被其他进程或系统剥夺,CPU和主存均属于可剥夺性资源] (临时资源包括硬件中断、信号、消息、缓冲区内的消息等),通常消息通信顺序进行不当,则会产生死锁
进程间推进顺序非法
若P1保持了资源R1,P2保持了资源R2,系统处于不安全状态,因为这两个进程再向前推进,便可能发生死锁
产生的必要条件
- 互斥条件:进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用。
- 请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
- 环路等待条件:在发生死锁时,必然存在一个进程–资源的环形链。
预防死锁
- 资源一次性分配:一次性分配所有资源,这样就不会再有请求了:(破坏请求条件)
- 只要有一个资源得不到分配,也不给这个进程分配其他的资源:(破坏请保持条件)
- 可剥夺资源:即当某进程获得了部分资源,但得不到其它资源,则释放已占有的资源(破坏不可剥夺条件)
- 资源有序分配法:系统给每类资源赋予一个编号,每一个进程按编号递增的顺序请求资源,释放则相反(破坏环路等待条件)
避免死锁
- 预防死锁的几种策略,会严重地损害系统性能。因此在避免死锁时,要施加较弱的限制,从而获得 较满意的系统性能。由于在避免死锁的策略中,允许进程动态地申请资源。因而,系统在进行资源分配之前预先计算资源分配的安全性。若此次分配不会导致系统进入不安全的状态,则将资源分配给进程;否则,进程等待。其中最具有代表性的避免死锁算法是银行家算法。
- 银行家算法:首先需要定义状态和安全状态的概念。系统的状态是当前给进程分配的资源情况。因此,状态包含两个向量Resource(系统中每种资源的总量)和Available(未分配给进程的每种资源的总量)及两个矩阵Claim(表示进程对资源的需求)和Allocation(表示当前分配给进程的资源)。安全状态是指至少有一个资源分配序列不会导致死锁。当进程请求一组资源时,假设同意该请求,从而改变了系统的状态,然后确定其结果是否还处于安全状态。如果是,同意这个请求;如果不是,阻塞该进程知道同意该请求后系统状态仍然是安全的。
检测死锁
- 首先为每个进程和每个资源指定一个唯一的号码;
- 然后建立资源分配表和进程等待表。
解除死锁
- 剥夺资源:从其它进程剥夺足够数量的资源给死锁进程,以解除死锁状态;
- 撤消进程:可以直接撤消死锁进程或撤消代价最小的进程,直至有足够的资源可用,死锁状态.消除为止;所谓代价是指优先级、运行代价、进程的重要性和价值等。
索引
是什么
官方对索引的定义
索引(Index)是帮助MySQL高效获取数据的数据结构。我们可以简单理解为:快速查找排好序的一种数据结构。Mysql索引主要有两种结构:B+Tree索引和Hash索引。我们平常所说的索引,如果没有特别指明,一般都是指B树结构组织的索引(B+Tree索引)。
存储引擎
MyISAM存储引擎
- .frm后缀的文件存储的是表结构。
- .myd后缀的文件存储的是表数据。
- .myi后缀的文件存储的就是索引文件。
InnoDB存储引擎
- .frm后缀的文件存储的是表结构。
- .ibd后缀的文件存放索引文件和数据(需要开启innodb_file_per_table参数)
总结
- 索引是按照特定的数据结构把数据表中的数据放在索引文件中,以便于快速查找;
- 索引存在于磁盘中,会占据物理空间。
索引的类型
B-Tree 索引
以 B-Tree 为结构的索引是最常见的索引类型,比如 InnoDB 和 MyISAM 都是以 B-Tree 为索引结构的索引,事实上是以 B+ Tree 为索引结构,B-Tree 和 B+Tree 区别在于,B+ Tree 在叶子节点上增加了顺序访问指针,方便叶子节点的范围遍历.
InnoDB
- InnoDB 支持聚簇索引,聚簇索引和非聚簇索引严格来说不是一种索引,而是一种数据存储方式,这个名字跟它本身的存储方式有关系,“聚簇“表示数据行和相邻的键值存储在一起,简单的说,就是叶子节点中存储的实际是真实的数据。InnoDB 通过主键聚集数据,所以一个表只能有一个聚簇索引,且必须有主键,如果没有定义主键,且不存在非空索引可以代替,InnoDB 会隐式定义一个主键作为聚簇索引。
- 聚簇索引的二级索引存储的不是指向行的物理位置的指针,而是行的主键值,所以如果通过二级索引查找行,需要找到二级索引的叶子结点获得对应的主键值,然后再去查找对应的行。对于 InnoDB,自适应哈希索引可以减少这样的重复工作。
锁
- InnoDB 使用的是行锁,所以支持事务,而 MyISAM 使用的是表锁,不支持事务。
- 适用范围
- B-Tree 索引适用于区间查询,因为 B-Tree 存储后的叶子节点本身就是有序的,并且 B+ Tree 结构还增加了叶子节点的连续顺序指针,对于区间查询来说就更加方便了。
哈希索引
哈希索引是基于哈希表实现的,只有精确匹配索引所有列的查询才有效。方法是,对所有的索引列计算一个 hash code,hash code 作为索引,在哈希表中保存指向每个数据行的指针。
优点
索引本身只存储 hash code,所以结构很紧凑,并且查找速度很快
限制
- 索引中的 hash code 是顺序存储的,但是 hash code 对应的数据并不是顺序的,所以无法用于排序
- 不支持部分索引列匹配查找,因为哈希索引是使用索引列的全部内容来计算 hash code
- 只支持等值比较,不支持范围查询
- 如果哈希冲突严重时,必须遍历链表中所有行指针
- 哈希冲突严重的话,索引维护操作的代价也很高
InnoDB 的自适应哈希索引
- 自适应哈希索引对于用户来说是无感知的,这是一个完全自动、内部的行为,用户无法控制或者配置,但是可以关闭。
- 当 InnoDB 注意到某个索引值被使用的非常频繁时,它会在内存中基于 B-Tree 索引之上再创建一个哈希索引,这样 B-Tree 也可以具有哈希索引的一些优点,比如快速的哈希查找。
- 当然如果存储引擎不支持哈希索引,用户也可以自定义哈希索引,这样性能会比较高,缺陷是需要自己维护哈希值,如果采用这种方法,不要使用 SHA1() 和 MD5() 作为哈希函数,因为这两个是强加密函数,设计目标是最大限度消除冲突,生成的 hash code 是一个非常长的字符串,浪费大量的空间,哈希索引中对于索引的冲突要求没有那么高。
索引的存储结构
- MySQL支持在所有关系数据库表中创建主键、唯一键、不唯一的非主码索引等多种类型的索引。此外MySQL还支持纯文本和空间索引类型。
- MySQL内置的存储引擎对各种索引技术有不同的实现方式,包括:B-树,B+树,R-树以及散列类型。
B-树
- B-树中有两种节点类型:索引节点和叶子节点。叶子节点是用来存储数据的,而索引节点则用来告诉用户存储在叶子节点中的数据顺序,并帮助用户找到相应的数据。
- B-树的搜索,从根节点开始,对节点内的关键字有序进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子节点,重复。直到所对应的儿子指针为空,或已经是叶子节点。
- B-树是一种多路搜索树:
- 定义任意非叶子节点最多有M个儿子,且M>2;
- 根节点的儿子数为[2,M];
- 除根节点以外的非叶子节点的儿子数为[M/2,M];
- 每个节点存放至少M/2-1(取上整)和至多M-1个关键字;
- 非叶子节点的关键字个数=指向儿子节点的指针的个数-1;
- 非叶子节点的关键字:k[i]<k[i+1];
- 非叶子节点的指针:p[1],p[2],·····,p[M];其中p[1]指向的关键字小于k[1]的子树,p[M]指向的关键字大于K[m-1]的子树;
- 所有的叶子节点位于同一层;
B+树
- B+树数据结构是B-树实现的增强版本。尽管B+树支持B-树索引的所有特性,它们之间最显著的不同点在于B+树中底层数据是根据被提及的索引列进行排序的。B+树还通过叶子节点之间的附加引用来优化扫描性能。
- B+搜索和B-搜索不同,区别是B+树只有达到叶子节点才命中(B-树可以在非叶子节点命中),其性能等价于关键字全集做一次二分搜索。
- B+树的特性:
- 所有关键字都出现在叶子节点的链表中,叶子节点相当于存储数据的数据层。
- 不可能在非叶子节点上命中。
- 非叶子节点相当于是叶子节点的索引,叶子节点相当于数据层。
散列
散列表数据结构是一种很简单的概念,它将一种算法应用到给定值中以在底层数据存储系统中返回一个唯一的指针或位置。散列表的优点是始终以线性时间复杂度找到需要读取的行的位置,而不像B-树那样需要横跨多层节点来确定位置。
通信R-树
R-树数据结构支持基于数据类型对几何数据进行管理。目前只有MyISAM使用R-树实现支持空间索引,使用空间索引也有很多限制,比如只支持唯一的NOT NULL列等。
全文本
全文本结构也是一种MySQL采用的基本数据结构。这种数据结构目前只有当前版本MySQL中的MyISAM存储引擎支持。5.6版本将要在InnoDB存储引擎中加入全文本功能。全文本索引在大型系统中并没有什么实用的价值,因为大规模系统有很多专门的文件检索产品
为什么快
- 不加索引,会比较整个数据库,因为他不知道数据是不是规律的。添加了索引,相当于加了一个目录,给索引字段排序,比较的时候只用几次就可以查找到你需要的数据。数据越多,索引约有用。也可以说拿空间换时间。
- 索引对性能的影响:
- 大大减少服务器需要扫描的数据量。
- 帮助服务器避免排序和临时表。将随机I/O变顺序I/O。
- 大大提高查询速度,降低写的速度、占用磁盘。
主键与唯一索引
- 主键是一种约束,唯一索引是一种索引,两者在本质上是不同的。
- 主键一定是唯一性索引,唯一性索引并不一定就是主键。主键列在创建时,已经默认为空值 + 唯一索引了。
- 一个表中可以有多个唯一性索引,但只能有一个主键。
- 主键可以被其他表引用为外键,而唯一索引不能。
- 主键列不允许空值,而唯一性索引列允许空值。
- 索引可以提高查询的速度,而主键不能。
- 主键和索引都是键,不过主键是逻辑键,索引是物理键,意思就是主键不实际存在,而索引实际存在在数据库中,会占用磁盘。
- 主键一般都要建,主要是用来避免一张表中有相同的记录,索引一般可以不建,但如果需要对该表进行查询操作,则最好建,这样可以加快检索的速度。
使用
创建索引
添加PRIMARY KEY(主键索引)
mysql>ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` ) 添加UNIQUE(唯一索引)
mysql>ALTER TABLE `table_name` ADD UNIQUE ( `column` ) 添加INDEX(普通索引)
mysql>ALTER TABLE `table_name` ADD INDEX index_name ( `column` ) 添加FULLTEXT(全文索引)
mysql>ALTER TABLE `table_name` ADD FULLTEXT ( `column`) 添加多列索引
mysql>ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )修改索引
ALTER TABLE 表名 CHANGE 原字段名 新字段名 字段类型 约束条件
alter table table_name change id user_id int not null //把字段 id 换成 user_id删除索引
DROP INDEX index_name ON talbe_name
ALTER TABLE table_name DROP INDEX index_name
ALTER TABLE table_name DROP PRIMARY KEY查看索引
mysql> show index from tblname;
mysql> show keys from tblname;优点
- 使用索引可以减少服务器需要扫描的数据量
- 使用索引可以帮助服务器避免排序和临时表
- 使用索引可以将随机 I/O 变为顺序 I/O
- 但是不是所有情况下,索引都是最好的解决方案,对于非常小的表来说,大部分情况下简单的全表扫描更高效,对于中到大型表,索引就比较有效,对于特大型的表来说,分区会更加有效。
索引的优化
联合索引最左前缀原则
- 复合索引遵守「最左前缀」原则,查询条件中,使用了复合索引前面的字段,索引才会被使用,如果不是按照索引的最左列开始查找,则无法使用索引。
- 比如在(a,b,c)三个字段上建立联合索引,那么它能够加快a|(a,b)|(a,b,c)三组查询的速度,而不能加快b|(b,a)这种查询顺序。
- 另外,建联合索引的时候,区分度最高的字段在最左边。
不要在列上使用函数和进行运算
不要在列上使用函数,这将导致索引失效而进行全表扫描。
例如下面的 SQL 语句:
select * from artile where YEAR(create_time) <= '2018';即使 date 上建立了索引,也会全表扫描,可以把计算放到业务层,这样做不仅可以节省数据库的 CPU,还可以起到查询缓存优化效果。
负向条件查询不能使用索引
负向条件有:!=、<>、not in、not exists、not like 等。
select * from artile where status != 1 and status != 2;
可以使用in进行优化:
select * from artile where status in (0,3) 使用覆盖索引
- 所谓覆盖索引,是指被查询的列,数据能从索引中取得,而不用通过行定位符再到数据表上获取,能够极大的提高性能。
- 可以定义一个让索引包含的额外的列,即使这个列对于索引而言是无用的。
避免强制类型转换
- 当查询条件左右两侧类型不匹配的时候会发生强制转换,强制转换可能导致索引失效而进行全表扫描。
- 如果phone字段是varchar类型,则下面的SQL不能命中索引:
select * from user where phone=12345678901; 可以优化为:
select * from user where phone='12345678901'; 范围列可以用到索引
- 范围条件有:<、<=、>、>=、between等。
- 范围列可以用到索引,但是范围列后面的列无法用到索引,索引最多用于一个范围列,如果查询条件中有两个范围列则无法全用到索引。
更新频繁、数据区分度不高的字段上不宜建立索引
- 更新会变更B+树,更新频繁的字段建立索引会大大降低数据库性能。
- 「性别」这种区分度不大的属性,建立索引没有意义,不能有效过滤数据,性能与全表扫描类似。
- 区分度可以使用 count(distinct(列名))/count(*) 来计算,在80%以上的时候就可以建立索引。
索引列不允许为null
单列索引不存null值,复合索引不存全为null的值,如果列允许为 null,可能会得到不符合预期的结果集。
避免使用or来连接条件
应该尽量避免在 where 子句中使用 or 来连接条件,因为这会导致索引失效而进行全表扫描,虽然新版的MySQL能够命中索引,但查询优化耗费的 CPU比in多。
模糊查询
前导模糊查询不能使用索引,非前导查询可以。
MySQL实现
MyISAM的B-树
- MyISAM存储引擎使用B-树数据结构来实现主码索引、唯一索引以及非主码索引。在MyISAM实现数据目录和数据库模式子目录中,用户可以找到和每个MySQL表对应的.MYD和.MYI文件。数据库表上定义的索引信息就存储在MYI文件中,该文件的块大小是1024字节。这个大小是可以通过myisam-block-size系统变量分配。
- 在MyISAM中,非主码索引的B-树结构存储索引值和一个指向主码数据的指针,这是MyISAM和InnoDB的一个显著区别。这一点导致了两个存储引擎的索引的不同工作方式。
- MyISAM索引是在内存的一个公共缓存中管理的,这个缓存的大小可以通过key_buffer_size或者其他命名键缓存来定义。这是根据统计和规划的表索引的大小来设定缓存大小时主要的考虑因素。
InnoDB的B+树聚簇主码
- InnoDB存储引擎在它的主码索引(也被称为聚簇主码)中使用了B+树,这种结构把所有数据都和对应的主码组织在一起,并且在叶子节点这一层上添加额外的向前和向后的指针,这样就可以更方便地进行范围扫描。
- 在文件系统层面,所有InnoDB数据和索引信息都默认在公共InnoDB表空间中管理,否则管理员就通过innodb_data_file_path这个变量指定文件路径。这是一个叫ibdatal文件。
- 由于InnoDB用聚簇主码存储数据,底层信息占用的磁盘空间的大小很大程度上取决于页面的填充因子。对于按序排列的主码,InnoDB会用16K页面的15/16作为填充因子。对于不是按序排列的主码,默认情况下InnoDB会插入初始数据的时候为每一个页面分配50%作为填充因子。
- 在改索引的实现方式中B+树的叶子节点上是data就是数据本身,key为主键,如果是一般索引的话,data便会指向对应的主索引。在B+树的每一个叶子节点上面增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+树。其目的是提高区间访问的性能。
InnoDB的B-树非主码
InnoDB中的非主码索引使用了B-树数据结构,但InnoDB中的B-树结构实现和MyISAM中并不一样。在InnoDB中,非主码索引存储的是主码的实际值。而MyISAM中,非主码索引存储的包含主码值的数据指针。这一点很重要。首先,当定义很大的主码的时候,InnoDB的非主码索引可能回更大,随着非主码索引数量的增加,索引之间大小差别可能会变得很大。另一个不同点在于非主码索引当前可以包含主键的值,并且可以不是索引必须有的部分。
内存散列索引
在默认MySQL的引擎索引中,只有MEMORY引擎支持散列数据结构,散列结构的强度可以表示为直接键查找的简单性,散列索引的相似度模式匹配查询比直接查询慢。也可以为MEMORY引擎指定一个B-树索引实现。
内存B-树索引
对于大型MEMORY表来说,使用散列索引进行索引范围搜索的效率很低,B-树索引在执行直接键查询时确实比使用默认的散列索引快。根据B-树的不同深度,B-树索引在个别操作中的确可能比散列算法快。
InnoDB内部散列索引
InnoDB存储引擎在聚簇B+树索引中存储主码:但在InnoDB内部还是使用内存中的散列表来更高效地进行主码查询。这个机制有InnoDB存储引擎来管理,用户只能通过innodb_adaptive_hash_index配置项来选择是否启用这个唯一的配置选项。
服务器配置优化
系统参数调整
Linux系统内核参数优化
vim /etc/sysctl.conf
net.ipv4.ip_local_port_range = 1024 65535 # 用户端口范围
net.ipv4.tcp_max_syn_backlog = 4096
net.ipv4.tcp_fin_timeout = 30
fs.file-max=65535 # 系统最大文件句柄,控制的是能打开文件最大数量数据库参数优化
实例整体
thread_concurrency #并发线程数量个数
sort_buffer_size #排序缓存
read_buffer_size #顺序读取缓存
read_rnd_buffer_size #随机读取缓存
key_buffer_size #索引缓存
thread_cache_size #线程缓存(1G—>8, 2G—>16, 3G—>32, >3G—>64)连接层(基础优化)
设置合理的连接客户和连接方式
max_connections #最大连接数,看交易笔数设置
max_connect_errors #最大错误连接数,能大则大
connect_timeout #连接超时
max_user_connections #最大用户连接数
skip-name-resolve #跳过域名解析
wait_timeout #等待超时
back_log #可以在堆栈中的连接数量SQL层(基础优化)
query_cache_size: 查询缓存
OLAP类型数据库,需要重点加大此内存缓存.
但是一般不会超过GB.
对于经常被修改的数据,缓存会立马失效。
我们可以实用内存数据库(redis、memecache),替代他的功能。
存储引擎层
innodb基础优化参数
default-storage-engine
innodb_buffer_pool_size # 没有固定大小,50%测试值,看看情况再微调。但是尽量设置不要超过物理内存70% innodb_file_per_table=(1,0)
innodb_flush_log_at_trx_commit=(0,1,2) #1是最安全的,0是性能最高,2折中
binlog_sync
Innodb_flush_method=(O_DIRECT, fdatasync)
innodb_log_buffer_size #100M以下
innodb_log_file_size #100M 以下
innodb_log_files_in_group #5个成员以下,一般2-3个够用(iblogfile0-N)
innodb_max_dirty_pages_pct #达到百分之75的时候刷写 内存脏页到磁盘。 log_bin
max_binlog_cache_size #可以不设置
max_binlog_size #可以不设置
innodb_additional_mem_pool_size #小于2G内存的机器,推荐值是20M。32G内存以上100M大数据的一些操作
大数据的分页
直接用limit start, count分页语句
当起始页较小时,查询没有性能问题,随着起始记录的增加,时间也随着增大
发现
1)limit语句的查询时间与起始记录的位置成正比
2)mysql的limit语句是很方便,但是对记录很多的表并不适合直接使用
对limit分页问题的性能优化方法
- 利用表的覆盖索引来加速分页查询
- 我们都知道,利用了索引查询的语句中如果只包含了那个索引列(覆盖索引),那么这种情况会查询很快。
- 因为利用索引查找有优化算法,且数据就在查询索引上面,不用再去找相关的数据地址了,这样节省了很多时间。另外Mysql中也有相关的索引缓存,在并发高的时候利用缓存就效果更好了。
- id字段是主键,自然就包含了默认的主键索引。
覆盖索引
如果一个索引包含(或覆盖)所有需要查询的字段的值,称为‘覆盖索引’。即只需扫描索引而无须回表。
覆盖索引优点
1.索引条目通常远小于数据行大小,只需要读取索引,则mysql会极大地减少数据访问量。 2.因为索引是按照列值顺序存储的,所以对于IO密集的范围查找会比随机从磁盘读取每一行数据的IO少很多。 3.一些存储引擎如myisam在内存中只缓存索引,数据则依赖于操作系统来缓存,因此要访问数据需要一次系统调用 4.innodb的聚簇索引,覆盖索引对innodb表特别有用。
覆盖索引必须要存储索引列的值,而哈希索引、空间索引和全文索引不存储索引列的值,所以mysql只能用B-tree索引做覆盖索引。
例子
select id from product limit 866613, 20
SELECT * FROM product WHERE ID > =(select id from product limit 866613, 1) limit 20
SELECT * FROM product a JOIN (select id from product limit 866613, 20) b ON a.ID = b.id百万级的数据的导出
一. 对于数据超过了65535行的问题,很自然的就会想到将整个数据分块,利用excel的多sheet页的功能,将超出65535行后的数据写入到下一个sheet页中,即通过多sheet页的方式,突破了最高65535行数据的限定, 具体做法就是,单独做一个链接,使用JSP导出,在JSP上通过程序判断报表行数,超过65535行后分SHEET写入。这样这个问题就得以解决了
二. 在这种大数据量的报表生成和导出中,要占用大量的内存,尤其是在使用TOMCAT的情况下,JVM最高只能支持到2G内存,则会发生内存溢出的情况。此时的内存开销主要是两部分,一部分是该报表生成时的开销,另一部分是该报表生成后写入一个EXCEL时的开销。由于JVM的GC机制是不能强制回收的,因此,对于此种情形,我们要改变一种方式:
- 将该报表设置起始行和结束行参数,在API生成报表的过程中,分步计算报表,比如一张20万行数据的报表,在生成过程中,可通过起始行和结束行分4-5次进行。这样,就降低了报表生成时的内存占用,在后面报表生成的过程中,如果发现内存不够,即可自动启动JVM的GC机制,回收前面报表的缓存
- 导出EXCEL的过程,放在每段生成报表之后立即进行,改多个SHEET页为多个EXCEL,即在分步生成报表的同时分步生成EXCEL,则通过 POI包生成EXCEL的内存消耗也得以降低。通过
多次生成,同样可以在后面EXCEL生成所需要的内存不足时,有效回收前面生成EXCEL时占用的内存- 再使用文件操作,对每个客户端的导出请求在服务器端根据SESSIONID和登陆时间生成唯一的临时目录,用来放置所生成的多个EXCEL,然后调用系统控制台,打包多个EXCEL为RAR
或者JAR方式,最终反馈给用户一个RAR包或者JAR包,响应客户请求后,再次调用控制台删除该临时目录。- 通过分段运算和生成,有效降低了报表从生成结果到生成EXCEL的内存开销。其次是通过使用压缩包,响应给用户的生成文件体积大大缩小,降低了多用户并
发访问时服务器下载文件的负担,有效减少多个用户导出下载时服务器端的流量,从而达到进一步减轻服务器负载的效果
php 相关
cgi ,fastcgi,php-fpm 区别
cgi
- CGI的英文是(COMMON GATEWAY INTERFACE)公共网关接口,它的作用就是帮助服务器与语言通信,这里就是nginx和php进行通信,因为nginx和php的语言不通,因此需要一个沟通转换的过程,而CGI就是这个沟通的协议。
- nginx服务器在接受到浏览器传递过来的数据后,如果请求的是静态的页面或者图片等无需动态处理的则会直接根据请求的url找到其位置然后返回给浏览器,这里无需php参与,但是如果是一个动态的页面请求,这个时候nginx就必须与php通信,这个时候就会需要用到cgi协议,将请求数据转换成php能理解的信息,然后php根据这些信息返回的信息也要通过cgi协议转换成nginx可以理解的信息,最后nginx接到这些信息再返回给浏览器。
fast-cgi
- 传统的cgi协议在每次连接请求时,会开启一个进程进行处理,处理完毕会关闭该进程,因此下次连接,又要再次开启一个进程进行处理,因此有多少个连接就有多少个cgi进程,这也就是为什么传统的cgi会显得缓慢的原因,因此过多的进程会消耗资源和内存。
- 而fast-cgi每次处理完请求后,不会kill掉这个进程,而是保留这个进程,使这个进程可以一次处理多个请求。这样每次就不用重新fork一个进程了,大大提高效率。
php-cgi
php-cgi是php提供给web serve也就是http前端服务器的cgi协议接口程序,当每次接到http前端服务器的请求都会开启一个php-cgi进程进行处理,而且开启的php-cgi的过程中会先要重载配置,数据结构以及初始化运行环境,如果更新了php配置,那么就需要重启php-cgi才能生效,例如phpstudy就是这种情况。
php-fpm
- php-fpm是php提供给web serve也就是http前端服务器的fastcgi协议接口程序,它不会像php-cgi一样每次连接都会重新开启一个进程,处理完请求又关闭这个进程,而是允许一个进程对多个连接进行处理,而不会立即关闭这个进程,而是会接着处理下一个连接。它可以说是php-cgi的一个管理程序,是对php-cgi的改进。
- php-fpm会开启多个php-cgi程序,并且php-fpm常驻内存,每次web serve服务器发送连接过来的时候,php-fpm将连接信息分配给下面其中的一个子程序php-cgi进行处理,处理完毕这个php-cgi并不会关闭,而是继续等待下一个连接,这也是fast-cgi加速的原理,但是由于php-fpm是多进程的,而一个php-cgi基本消耗7-25M内存,因此如果连接过多就会导致内存消耗过大,引发一些问题,例如nginx里的502错误。
- 同时php-fpm还附带一些其他的功能:
- 例如平滑过渡配置更改,普通的php-cgi在每次更改配置后,需要重新启动才能初始化新的配置,而php-fpm是不需要,php-fpm分将新的连接发送给新的子程序php-cgi,这个时候加载的是新的配置,而原先正在运行的php-cgi还是使用的原先的配置,等到这个连接后下一次连接的时候会使用新的配置初始化,这就是平滑过渡。
参考链接:blog.csdn.net/belen_xue/article/de...
PHP5 跟php7的区别
PHP7.0 号称是性能提升上革命性的一个版本。面对 Facebook 家的 HHVM 引擎带来的压力,开发团队重写了底层的 Zend Engine,名为 Zend Engine 2。
底层内核解析
PHP7 中最重要的改变就是 zval 不再单独从堆上分配内存并且不自己存储引用计数。需要使用 zval 指针的复杂类型(比如字符串、数组和对象)会自己存储引用计数。这样就可以有更少的内存分配操作、更少的间接指针使用以及更少的内存分配。在PHP7中的zval, 已经变成了一个值指针, 它要么保存着原始值, 要么保存着指向一个保存原始值的指针. 也就是说现在的zval相当于PHP5的时候的zval * . 只不过相比于zval * , 直接存储zval, 我们可以省掉一次指针解引用, 从而提高缓存友好性.
参考链接:www.jb51.net/article/76732.htm
PHP7 为什么比 PHP5 性能提升了
1、变量存储字节减小,减少内存占用,提升变量操作速度
2、改善数组结构,数组元素和hash映射表被分配在同一块内存里,降低了内存占用、提升了 cpu 缓存命中率
3、改进了函数的调用机制,通过优化参数传递的环节,减少了一些指令,提高执行效率
安全
函数修改
- preg_replace()不再支持/e修饰符,,同时官方给了我们一个新的函数preg_replace_callback
- create_function()被废弃,实际上它是通过执行eval实现的。
- mysql_* 系列全员移除,如果你要在PHP7上面用老版本的mysql_* 系列函数需要你自己去额外装了,官方不在自带,现在官方推荐的是mysqli或者pdo_mysql。
- unserialize()增加一个可选白名单参数,其实就是一个白名单,如果反序列数据里面的类名不在这个白名单内,就会报错。
- assert() 默认不在可以执行代码
语法修改
- foreach不再改变内部数组指针
- 8进制字符容错率降低,在php5版本,如果一个八进制字符如果含有无效数字,该无效数字将被静默删节。在php7里面会触发一个解析错误。
- 十六进制字符串不再被认为是数字
- 移除了 ASP 和 script PHP 标签
- 超大浮点数类型转换截断,将浮点数转换为整数的时候,如果浮点数值太大,导致无法以整数表达的情况下, 在PHP5的版本中,转换会直接将整数截断,并不会引发错误。 在PHP7中,会报错。
参考链接:www.freebuf.com/articles/web/19701...
总体
- 性能提升:PHP7比PHP5.0性能提升了两倍。
- 全面一致的64位支持。
- 以前的许多致命错误,现在改成[抛出异常]。
- PHP 7.0比PHP5.0移除了一些老的不在支持的SAPI([服务器端]应用编程端口)和扩展。
- .PHP 7.0比PHP5.0新增了空接合操作符。
- PHP 7.0比PHP5.0新增加了结合比较运算符。
- PHP 7.0比PHP5.0新增加了函数的返回类型声明。
- PHP 7.0比PHP5.0新增加了标量类型声明。
- PHP 7.0比PHP5.0新增加匿名类。
多进程同时读写一个文件
- PHP是支持进程的而不支持多线程(这个先搞清楚了),如果是对于文件操作,其实你只需要给文件加锁就能解决,不需要其它操作,PHP的flock已经帮你搞定了。
- 用flock在写文件前先锁上,等写完后解锁,这样就实现了多线程同时读写一个文件避免冲突。
流程
- flock参数说明:file 必需,规定要锁定或释放的已打开的文件,lock 必需。规定要使用哪种锁定类型。block 可选。若设置为 1 或 true,则当进行锁定时阻挡其他进程。
- LOCK_SH 要取得共享锁定(读取的程序)
- LOCK_EX 要取得独占锁定(写入的程序)
- LOCK_UN 要释放锁定(无论共享或独占)
- LOCK_NB 如果不希望 flock() 在锁定时堵塞
在PHP中,flock似乎工作的不是那么好!在多并发情况下,似乎是经常独占资源,不即时释放,或者是根本不释放,造成死锁,从而使服务器的cpu占用很高,甚至有时候会让服务器彻底死掉。好所以使用flock之前,一定要慎重考虑。
解决方案
- 对文件进行加锁时,设置一个超时时间,超时设置为1ms,如果这里时间内没有获得锁,就反复获得,直接获得到对文件操作权为止,当然。如果超时限制已到,就必需马上退出,让出锁让其它进程来进行操作。
- 不使用flock函数,借用临时文件来解决读写冲突的问题
- 将需要更新的文件考虑一份到我们的临时文件目录,将文件最后修改时间保存到一个变量,并为这个临时文件取一个随机的,不容易重复的文件名。
- 当对这个临时文件进行更新后,再检测原文件的最后更新时间和先前所保存的时间是否一致。
- 如果最后一次修改时间一致,就将所修改的临时文件重命名到原文件,为了确保文件状态同步更新,所以需要清除一下文件状态。
- 但是,如果最后一次修改时间和先前所保存的一致,这说明在这期间,原文件已经被修改过,这时,需要把临时文件删除,然后返回false,说明文件这时有其它进程在进行操作。
- 对操作的文件进行随机读写,以降低并发的可能性。
- 先前需要定义一个随机空间,空间越大,并发的的可能性就越小,这里假设随机读写空间为[1-500],那么我们的日志文件的分布就为log1
到log500不等。每一次用户访问,都将数据随机写到log1log500之间的任一文件。在同一时刻,有2个进程进行记录日志,A进程可能是更新的log32文件,而B进程呢?则此时更新的可能就为log399.要知道,如果要让B进程也操作log32,概率基本上为1/500,差不多约等于零。在需要对访问日志进行分析时,这里我们只需要先将这些日志合并,再进行分析即可。使用这种方案来记录日志的一个好处时,进程操作排队的可能性比较小,可以使进程很迅速的完成每一次操作。- 将所有要操作的进程放入一个队列中。
- 队列中的每一个排除的进程相当于第一个具体的操作,所以第一次我们的服务只需要从队列中取得相当于具体操作事项就可以了,如果这里还有大量的文件操作进程,没关系,排到我们的队列后面即可,只要愿意排,队列的多长都没关系。
框架方面
tp框架
优点
TP框架是我们中国人自己开发的框架,各种资料比较齐全,国内用的比较多,比较简单
和方便,而且是免费开源的
特性
- 多表查询非常方便,在 model 中几句代码就可以完成对多表的关联操作
- 融合了 smarty 模板,使前后台分离
- 支持多种缓存技术,尤其对 memcache 技术支持非常好
- 命名规范,模型,视图,控制器严格遵循命名规则,通过命名一一对应
- 支持多种 url 模式
- 内置 ajax 返回方法,包括 xml,json,html 等
- 支持应用扩展,类库扩展,驱动扩展
大写字母
U:对 url 的组装 A:内部实例化控制器 S:缓存处理 R:调用某个控制器的操作方法 D:实例化
自定义模型类 M:实例化基础模型类 I:获取参数 L:设置或者获取当前语言 C:设置或获取,
保存配置
laravel框架
简介
laravel框架的设计思想比较先进,非常适合应用各种开发模式,作为一个框架,它为你
准备好了一切,composer是php的未来,没有 composer,php肯定要走向没落
laravel框架最大的特点和优秀之处就是集合了php比较新的特点,以及各种各样的设计
模式,Ioc模式,依赖注入等.
特点
1.强大的rest router:用简单的回调函数就可以调用,快速绑定controller和router
2.artisan:命令行工具,很多手动的工作都自动化
3.可继承的模板,简化 view的开发和管理
4.blade模板:渲染速度更快
5.ORM操作数据库
6.migration:管理数据库和版本控制
7.测试功能也很强大
8.composer也是亮点
laravel框架引入了门面,依赖注入,Ioc模式,以及各种各样的设计模式等
composer
简介
composer依赖管理工具,且实现了自动加载。开发人员只需要几个命令行,就能获取其他开发者的包,PHP开发工作因此变得如同堆积木,可以根据业务的需求,快速方便地拆解组合代码。它不是一个包管理器。是的,它涉及 “packages” 和 “libraries”,但它在每个项目的基础上进行管理,在你项目的某个目录中(例如 vendor)进行安装。默认情况下它不会在全局安装任何东西。因此,这仅仅是一个依赖管理。
命令
- composer install 依据当前目录下的 composer.lock(锁文件) 或 composer.json 文件,所定义的依赖关系,安装依赖包。
- composer update 更新依赖版本,如果你修改了 composer.json 中的依赖关系,想让 composer 按照composer.json 文件中的定义执行更新操作,就用 update 命令。
- composer require require 命令一般用来安装新的依赖包,并将依赖写入当前目录的 composer.json 文件中。如果 composer.json 文件中,添加或改变了依赖,修改后的依赖关系将被安装或者更新。
- create-project 你可以使用 create-project 从现有的包中创建一个新的项目。它相当于执行了 git clone 命令后,将这个包的依赖安装到它自己的 vendor 目录。
设计模式
创建型
在软件工程中,创建型设计模式是处理对象创建机制的设计模式,试图以适当的方式来创建对象。对象创建的基本形式可能会带来设计问题,亦或增加了设计的复杂度。创建型设计模式通过控制这个对象的创建方式来解决此问题。
抽象工厂模式
在不指定具体类的情况下创建一系列相关或依赖对象。 通常创建的类都实现相同的接口。 抽象工厂的客户并不关心这些对象是如何创建的,它只是知道它们是如何一起运行的。
建造者模式
- 建造者是创建一个复杂对象的一部分接口。
- 有时候,如果建造者对他所创建的东西拥有较好的知识储备,这个接口就可能成为一个有默认方法的抽象类(又称为适配器)。
- 如果对象有复杂的继承树,那么对于建造者来说,有一个复杂继承树也是符合逻辑的。
- 注意:建造者通常有一个「流式接口」,例如 PHPUnit 模拟生成器。
工厂方法模式
- 对比简单工厂模式的优点是,您可以将其子类用不同的方法来创建一个对象。
- 举一个简单的例子,这个抽象类可能只是一个接口。
- 这种模式是「真正」的设计模式, 因为他实现了 S.O.L.I.D 原则中「D」的 「依赖倒置」。
- 这意味着工厂方法模式取决于抽象类,而不是具体的类。 这是与简单工厂模式和静态工厂模式相比的优势。
多例模式
对象池模式
- 对象池模式是一种提前准备了一组已经初始化了的对象『池』而不是按需创建或者销毁的创建型设计模式。对象池的客户端会向对象池中请求一个对象,然后使用这个返回的对象执行相关操作。当客户端使用完毕,它将把这个特定类型的工厂对象返回给对象池,而不是销毁掉这个对象。
- 在初始化实例成本高,实例化率高,可用实例不足的情况下,对象池可以极大地提升性能。在创建对象(尤其是通过网络)时间花销不确定的情况下,通过对象池在可期时间内就可以获得所需的对象。
- 无论如何,对象池模式在需要耗时创建对象方面,例如创建数据库连接,套接字连接,线程和大型图形对象(比方字体或位图等),使用起来都是大有裨益的。在某些情况下,简单的对象池(无外部资源,只占内存)可能效率不高,甚至会有损性能。
原型模式
相比正常创建一个对象 (new Foo () ),首先创建一个原型,然后克隆它会更节省开销。
简单工厂模式
- 简单工厂模式是一个精简版的工厂模式。
- 它与静态工厂模式最大的区别是它不是『静态』的。因为非静态,所以你可以拥有多个不同参数的工厂,你可以为其创建子类。甚至可以模拟(Mock)他,这对编写可测试的代码来讲至关重要。
单例模式
单例模式被公认为是 反面模式,为了获得更好的可测试性和可维护性,请使用『依赖注入模式』。主要为了在应用程序调用的时候,只能获得一个对象实例。主要包括:数据库的连接,日志的使用等。
静态工厂模式
与抽象工厂模式类似,此模式用于创建一系列相关或相互依赖的对象。 『静态工厂模式』与『抽象工厂模式』的区别在于,只使用一个静态方法来创建所有类型对象, 此方法通常被命名为
factory或build。
结构型
在软件工程中,结构型设计模式是通过识别实体之间关系来简化设计的设计模式。
行为型
在软件工程中,行为设计模式是识别对象之间的通用通信模式并实现这些模式的设计模式。 通过这样做,这些模式增加了执行此通信的灵活性。
生命周期
php的生命周期
- 模块初始化阶段(Module init):即调用每个拓展源码中的的PHP_MINIT_FUNCTION中的方法初始化模块,进行一些模块所需变量的申请,内存分配等。
- 请求初始化阶段(Request init):即接受到客户端的请求后调用每个拓展的PHP_RINIT_FUNCTION中的方法,初始化PHP脚本的执行环境。
- 执行该PHP脚本。
- 请求结束(Request Shutdown):这时候调用每个拓展的PHP_RSHUTDOWN_FUNCTION方法清理请求现场,并且ZE开始回收变量和内存
- 关闭模块(Module shutdown):Web服务器退出或者命令行脚本执行完毕退出会调用拓展源码中的PHP_MSHUTDOWN_FUNCTION 方法
laravel的生命周期
- 加载项目依赖,注册加载composer自动生成的class loader,也就是加载初始化第三方依赖。
- 创建应用实例,生成容器 Container,并向容器注册核心组件,是从 bootstrap/app.php 脚本获取 Laravel 应用实例,并且绑定内核服务容器,它是HTTP 请求的运行环境的不同,将请求发送至相应的内核: HTTP 内核 或 Console 内核。
- 接收请求并响应,请求被发送到 HTTP 内核或 Console 内核,这取决于进入应用的请求类型。HTTP 内核继承自 Illuminate\Foundation\Http\Kernel 类,该类定义了一个 bootstrappers 数组,这个数组中的类在请求被执行前运行,这些 bootstrappers 配置了错误处理、日志、检测应用环境以及其它在请求被处理前需要执行的任务。HTTP 内核还定义了一系列所有请求在处理前需要经过的 HTTP 中间件,这些中间件处理 HTTP 会话的读写、判断应用是否处于维护模式、验证 CSRF 令牌等等。
- 发送请求,在Laravel基础的服务启动之后,把请求传递给路由了。路由器将会分发请求到路由或控制器,同时运行所有路由指定的中间件。传递给路由是通过 Pipeline(管道)来传递的,在传递给路由之前所有请求都要经过app\Http\Kernel.php中的$middleware数组,也就是中间件,默认只有一个全局中间件,用来检测你的网站是否暂时关闭。所有请求都要经过,你也可以添加自己的全局中间件。然后遍历所有注册的路由,找到最先符合的第一个路由,经过它的路由中间件,进入到控制器或者闭包函数,执行你的具体逻辑代码,把那些不符合或者恶意的的请求已被Laravel隔离在外。
基础组件 - 日志
- Laravel 提供了强大的日志服务来记录日志信息到文件、系统错误日志、甚至是 Slack 以便通知整个团队。在日志引擎之下,Laravel 集成了 Monolog 日志库以便提供各种功能强大的日志处理器,从而允许你通过它们来定制自己应用的日志处理。
- 应用日志系统的所有配置都存放在配置文件
config/logging.php中,该文件允许你配置应用的日志通道,因此需要查看每个可用通道及其配置项,默认情况下,Laravel 使用 stack 通道来记录日志信息,stack 通道被用于聚合多个日志通道到单个通道
配置通道名称
默认情况下,Monolog 通过与当前环境匹配的「通道名称」实例化,例如
production或local,要改变这个值,添加name项到通道配置
有效通道驱动列表
stack用于创建「多通道」通道的聚合器single基于单文件/路径的日志通道(StreamHandler)daily基于RotatingFileHandler的 Monolog 驱动,以天为维度对日志进行分隔slack基于SlackWebhookHandler的 Monolog 驱动syslog基于SyslogHandler的 Monolog 驱动errorlog基于ErrorLogHandler的 Monolog 驱动monologMonolog 改成驱动,可以使用所有支持的 Monolog 处理器custom调用指定改成创建通道的驱动
配置 Single 和 Daily 通道
single和daily通道有三个可选配置项:bubble、permission和locking。bubble表示消息在被处理后是否冒泡到其它通道 ,默认为truepermission日志文件权限,默认为644locking在日志文件写入前尝试锁定它,默认为false
配置 Slack 通道slack 通道需要一个 url 配置项,这个 URL 需要和你配置的 Slack 团队[请求 URL]相匹配。
构建日志堆栈
stack驱动允许你将多个通道合并到单个日志通道,stack 通道通过 channels 项将聚合了其他两个通道:syslog 和 slack。因此,记录日志信息时,这两个通道都有机会记录信息。
参考链接:laravelacademy.org/post/19467.html
面向对象oop
是什么
oop是面向对象编程,面向对象编程是一种计算机编程架构,OOP 的一条基本原则是
计算机程序是由单个能够起到子程序作用的单元或对象组合而成。
*三大特点 *
1、封装性:也称为信息隐藏,就是将一个类的使用和实现分开,只保留部分接口和方
法与外部联系,或者说只公开了一些供开发人员使用的方法。于是开发人员只 需要关
注这个类如何使用,而不用去关心其具体的实现过程,这样就能实现MVC分工合作,
也能有效避免程序间相互依赖,实现代码模块间松藕合。
2、继承性:就是子类自动继承其父级类中的属性和方法,并可以添加新的属性和方法
或者对部分属性和方法进行重写。继承增加了代码的可重用性。PHP只支持单继承,也
就是说一个子类只能有一个父类。
3、多态性:子类继承了来自父级类中的属性和方法,并对其中部分方法进行重写。于
是多个子类中虽然都具有同一个方法,但是这些子类实例化的对象调用这些相同的方法
后却可以获得完全不同的结果,这种技术就是多态性。多态性增强了软件的灵活性。
设计模式的五大原则
- 单一职责原则 单一职责原则可以看做是低耦合、高内聚在面向对象原则上的引申,将职责定义为引起变化的原因,以提高内聚性来减少引起变化的原因
- 开发封闭原则 开放-封闭原则是面向对象设计的核心所在。遵循这个原则可以带来面向对象技术所声称的巨大好处,也就是可维护,可扩展,可复用,灵活性好。
- 接口隔离原则 通俗点说,不要强迫客户使用它们不用的方法,如果强迫用户使用它们不使用的方法,那么这些客户就会面临由于这些不使用的方法的改变所带来的改变。
- 依赖倒置原则 依赖倒置原则其实可以说是面向对象设计的标志,用哪种语言来编写程序不重要,如果编写时考虑的都是如何针对抽象编程而不是针对细节编程,即程序中所有的依赖关系都是终止于抽象类或者接口,那就是面向对象的设计,反之那就是过程化的设计了。
- 里氏替换原则 任何基类可以出现的地方,子类一定可以出现。 LSP是继承复用的基石,只有当衍生类可以替换掉基类,软件单位的功能不受到影响时,基类才能真正被复用,而衍生类也能够在基类的基础上增加新的行为。里氏代换原则是对“开-闭”原则的补充。实现“开-闭”原则的关键步骤就是抽象化。而基类与子类的继承关系就是抽象化的具体实现,所以里氏代换原则是对实现抽象化的具体步骤的规范。
好处
1、易维护 采用面向对象思想设计的结构,可读性高,由于继承的存在,即使改变需求,那么维护
也只是在局部模块,所以维护起来是非常方便和较低成本的。
2、质量高 在设计时,可重用现有的,在以前的项目的领域中已被测试过的类使系统满足业务需求
并具有较高的质量。
3、效率高 在软件开发时,根据设计的需要对现实世界的事物进行抽象,产生类。使用这样的方法
解决问题,接近于日常生活和自然的思考方式,势必提高软件开发的效率和质量。
4、易扩展 由于继承、封装、多态的特性,自然设计出高内聚、低耦合的系统结构,使得系统更灵
活、更容易扩展,而且成本较低。
smarty
- smarty是用php写出来的模板引擎,也是目前业界最著名的php模板引擎之一 ,它分离了逻辑代码和外在的显示,提供了一种易于管理和使用的方法,用来将混杂的php
- 逻辑代码与html代码进行分离,smarty是php中最著名的引擎框架之一,我们公司使用的是TP框架,已经封装好了smarty模板,所以没有单独使用过
- smarty是个模板引擎,最显著的地方就是有可以把模板缓存起来。一般模板来说,都是做一个静态页面,然后在里面把一些动态的部分用一切分隔符切开,然后在PHP里打开这个模板文件,把分隔符里面的值替换掉,然后输出来,你可以看下PHPLib里面的template部分。
而smarty设定了缓存参数以后,第一次运行时候会把模板打开,在php替换里面值的
时候把读取的html和php部分重新生成一个临时的php文件,这样就省去了每次打
开都重新读取html了。如果修改了模板,只要重新刷下就行了。
数据库的优化
结构层
负载均衡
Nginx负载均衡服务器 在nginx里面配置一个upstream,然后把相关的服务器ip都配置进去。然后采用轮询的方案,然后在nginx里面的配置项里,proxy-pass指向这个upst;eam,这样就能实现负载均衡。
nginx的负载均衡有4种模式:
- 轮询(默认)每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
- Weight 指定轮询几率,weight和访问比率成正比, 用于后端服务器性能不均的情况。
- ip_hash 每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session共享的问题。
- fair(第三方)按后端服务器的响应时间来分配请求,响应时间短的优先分配。
- url_hash(第三方)
使用nginx与apache相比
最核心的区别在于apache是同步多进程模型,一个连接对应一个进程;nginx是异步的,多个连接(万级别)可以对应一个进程 (nginx 处理请求是异步非阻塞的,而apache 则是阻塞型的)
在高并发下nginx 能保持低资源低消耗高性能。
apache 相对于nginx 的优点: rewrite ,比nginx 的rewrite 强大 模块超多,基本想到的都可以找到 少bug 。
主从复制
支持的复制类型 :
1) 基于语句的复制。在服务器上执行sql语句,在从服务器上执行同样的语句,mysql默认采用基于语句的复制,执行效率高。
2) 基于行的复制。把改变的内容复制过去,而不是把命令在从服务器上执行一遍。
3) 混合类型的复制。默认采用基于语句的复制,一旦发现基于语句无法精确复制时,就会采用基于行的复制。
主从形式:
1.一主一从
2.一主多从,提高系统的读性能
注:一主一从和一主多从是最常见的主从架构,实施起来简单并且有效,不仅可以实现HA,而且还能读写分离,进而提升集群的并发能力。
3.多主一从(5.7以后支持) 多主一从可以将多个mysql数据库备份到一台存储性能比较好的服务器上。
4.双主复制,也就是互做主从复制,每个master既是master,又是另外一台服务器的slave。这样任何一方所做的变更,都会通过复制应用到另外一方的数据库中。
5.级联复制,级联复制模式下,部分slave的数据同步不连接主节点,而是连接从节点。因为如果主节点有太多的从节点,就会损耗一部分性能用于replication,那么我们可以让3~5个从节点连接主节点,其它从节点作为二级或者三级与从节点连接,这样不仅可以缓解主节点的压力,并且对数据一致性没有负面影响。
*原理: *
MySQL主从复制涉及到三个线程,一个运行在主节点(log dump thread),其余两个(I/O thread, SQL thread)运行在从节点
主节点binary log dump 线程
当从节点连接主节点时,主节点会创建一个log dump 线程,用于发送bin-log的内容。在读取bin-log中的操作时,此线程会对主节点上的bin-log加锁,当读取完成,甚至在发动给从节点之前,锁会被释放。
从节点I/O线程
当从节点上执行 start slave 命令之后,从节点会创建一个I/O线程用来连接主节点,请求主库中更新的bin-log。I/O线程接收到主节点 binlog dump 进程发来的更新之后,保存在本地relay-log中。
从节点SQL线程
SQL线程负责读取relay log中的内容,解析成具体的操作并执行,最终保证主从数据的一致性。
主从复制模式
- 主从复制默认是异步模式
- 异步模式,主节点不会主动push bin log到从节点,这样有可能导致failover的情况下,也许从节点没有即时地将最新的bin log同步到本地。
- 半同步模式主节点只需要接收到其中一台从节点的返回信息,就会commit;否则需要等待直到超时时间然后切换成异步模式再提交;这样做的目的可以使主从数据库的数据延迟缩小,可以提高数据安全性,确保了事务提交后,binlog至少传输到了一个从节点上,不能保证从节点将此事务更新到db中。性能上会有一定的降低,响应时间会变长。
- 全同步模式是指主节点和从节点全部执行了commit并确认才会向客户端返回成功
解决的问题
- 数据分布:随意停止或开始复制,并在不同地理位置分布数据备份
- 负载均衡:降低单个服务器的压力
- 高可用和故障切换:帮助应用程序避免单点失败
- 升级测试:可以使用更高版本的 MYSQL作为从库
读写分离
什么是读写分离
读写分离就是在主服务器上修改,数据会同步到从服务器,从服务器只能提供读取数据,不能写入,实现备份的同时也实现了数据库性能的优化,以及提升了服务器安全。
为什么要读写分离
因为数据库的“写”(写10000条数据到oracle可能要3分钟)操作是比较耗时的。但是数据库的“读”(从oracle读10000条数据可能只要5秒钟)。所以读写分离,解决的是,数据库的写入,影响了查询的效率。
常见的Mysql读写分离分为以下两种:
基于程序代码内部实现
在代码中根据select 、insert进行路由分类,这类方法也是目前生产环境下应用最广泛的。优点是性能较好,因为程序在代码中实现,不需要增加额外的硬件开支。
基于中间代理层实现
代理一般介于应用服务器和数据库服务器之间,代理数据库服务器接收到应用服务器的请求后根据判断后转发到,后端数据库,有以下代表性的程序。
储存层
存储引擎
从储存层: 采用合适的存储引擎,采用三范式 目前广泛使用的是MyISAM和InnoDB两种引擎
核心区别
- MyISAM是非事务安全型的,而InnoDB是事务安全型的。
- MyISAM锁的粒度是表级,而InnoDB支持行级锁定。
- MyISAM支持全文类型索引,而InnoDB不支持全文索引。
- MyISAM相对简单,所以在效率上要优于InnoDB,小型应用可以考虑使用MyISAM。
- MyISAM表是保存成文件的形式,在跨平台的数据转移中使用MyISAM存储会省去不少的麻烦。
- InnoDB表比MyISAM表更安全,可以在保证数据不会丢失的情况下,切换非事务表到事务表(alter table tablename type=innodb)。
应用场景
- MyISAM管理非事务表。它提供高速存储和检索,以及全文搜索能力。如果应用中需要执行大量的SELECT查询,那么MyISAM是更好的选择。做很多count 的计算;
- 插入不频繁,查询非常频繁;
- 没有事务。
- InnoDB用于事务处理应用程序,具有众多特性,包括ACID事务支持。如果应用中需要执行大量的INSERT或UPDATE操作,则应该使用InnoDB,这样可以提高多用户并发操作的性能。
- 可靠性要求比较高,或者要求事务;
- 表更新和查询都相当的频繁,并且行锁定的机会比较大的情况。
Mysql的存储引擎和索引
- InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用”where id = 14”这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。
- MyISM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检i索无需访问主键的索引树。;
三范式
- 第一范式:若关系模式 R 的每一个属性是不可再分解的,且有主键,则属于第一范式。
- 第二范式:若 R 属于第一范式,且所有的非主键属性都完全函数依赖于主键属性,则满足第二范式。
- 第三范式:若 R 属于第二范式,且所有的非主键属性没有一个是传递函数依赖于候选主键属性,则满足第三范式。
在实际使用中,可以根据需求适当的逆范式。
设计层
从设计层: 采用分区分表,索引,表字段合适的字段属性,适当采用逆范式,开启 mysql 缓存
分库分表
表分区
分区工作原理
- 对用户而言,分区表是一个独立的逻辑表,但是底层 MYSQL将其分成了多个物理子表,这对用户来说是透明的,每一个分区表都会使用一个独立的表文件。
- 创建表时使用 partition by子句定义每个分区存放的数据,执行查询时,优化器会根据分区定义过滤那些没有我们需要数据的分区,这样查询只需要查询所需数据在的分区。
- 分区的主要目的是将数据按照一个较粗的粒度分在不同的表中,这样可以将相关的数据存放在一起,而且如果想一次性删除整个分区的数据也很方便
分区的好处
- 可以让单表存储更多的数据
- 分区表的数据更容易维护,可以通过清楚整个分区批量删除大量数据,也可以增加新的分区来支持新插入的数据。另外,还可以对一个独立分区进行优化、检查、修复等操作
- 部分查询能够从查询条件确定只落在少数分区上,速度会很快
- 分区表的数据还可以分布在不同的物理设备上,从而高效利用多个硬件设备
- 可以使用分区表赖避免某些特殊瓶颈,例如InnoDB单个索引的互斥访问、ext3文件系统的inode锁竞争
分区的限制和缺点:
- 一个表最多只能有1024个分区
- 如果分区字段中有主键或者唯一索引的列,那么所有主键列和唯一索引列都必须包含进来
- 分区表无法使用外键约束
- NULL值会使分区过滤无效
- 所有分区必须使用相同的存储引擎
分区的类型
- RANGE分区:基于属于一个给定连续区间的列值,把多行分配给分区
- LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择
- HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算这个函数可以包含MySQL中有效的、产生非负整数值的任何表达式
- KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值
分区适合的场景
- 表非常大,无法全部存在内存,或者只在表的最后有热点数据其他都是历史数据
- 分区表的数据更易维护,可以对独立的分区进行独立的操作
- 分区表的数据可以分布在不同的机器上,从而高效使用资源
- 可以使用分区表来避免某些特殊的瓶颈
- 备份和恢复独立的分区
垂直拆分
垂直分库是根据数据库里面的数据表的相关性进行拆分,比如:一个数据库里面既存在用户数据,又存在订单数据,那么垂直拆分可以把用户数据放到用户库、把订单数据放到订单库。垂直分表是对数据表进行垂直拆分的一种方式,常见的是把一个多字段的大表按常用字段和非常用字段进行拆分,每个表里面的数据记录数一般情况下是相同的,只是字段不一样,使用主键关联[比如将users分成了users和usersExtra两个表
优点:
- 可以使得行数据变小,一个数据块(Block)就能存放更多的数据,在查询时就会减少I/O次数(每次查询时读取的Block 就少)
- 可以达到最大化利用Cache的目的,具体在垂直拆分的时候可以将不常变的字段放一起,将经常改变的放一起
- 数据维护简单
缺点是:
- 主键出现冗余,需要管理冗余列
- 会引起表连接JOIN操作(增加CPU开销)可以通过在业务服务器上进行join来减少数据库压力
- 依然存在单表数据量过大的问题(需要水平拆分)
- 事务处理复杂
水平拆分
- 水平拆分,是通过某种策略将数据分片来存储,分库内分表和分库两部分,每片数据会分散到不同的MySQL表或库,达到分布式的效果,能够支持非常大的数据量。前面的表分区本质上也是一种特殊的库内分表
- 库内分表,仅仅是单纯的解决了单一表数据过大的问题,由于没有把表的数据分布到不同的机器上,因此对于减轻MySQL服务器的压力来说,并没有太大的作用,大家还是竞争同一个物理机上的IO、CPU、网络,这个就要通过分库来解决
- 前面垂直拆分的用户表如果进行水平拆分,分为Users_A_M Users_N_Z两张表
- 实际情况中往往会是垂直拆分和水平拆分的结合,即将
Users_A_M和Users_N_Z再拆成Users和UserExtras,这样一共四张表
优点是:
- 不存在单库大数据和高并发的性能瓶颈
- 应用端改造较少
- 提高了系统的稳定性和负载能力
缺点是:
- 分片事务一致性难以解决
- 跨节点Join性能差,逻辑复杂
- 数据多次扩展难度跟维护量极大
分片原则
- 能不分就不分
- 分片数量尽量少,分片尽量均匀分布在多个数据结点上,因为一个查询SQL跨分片越多,则总体性能越差,虽然要好于所有数据在一个分片的结果,只在必要的时候进行扩容,增加分片数量
- 分片规则需要慎重选择做好提前规划,分片规则的选择,需要考虑数据的增长模式,数据的访问模式,分片关联性问题,以及分片扩容问题,最近的分片策略为范围分片,枚举分片,一致性Hash分片,这几种分片都有利于扩容
- 尽量不要在一个事务中的SQL跨越多个分片,分布式事务一直是个不好处理的问题
- 查询条件尽量优化,尽量避免Select * 的方式,大量数据结果集下,会消耗大量带宽和CPU资源,查询尽量避免返回大量结果集,并且尽量为频繁使用的查询语句建立索引。
- 通过数据冗余和表分区赖降低跨库Join的可能
- 这里特别强调一下分片规则的选择问题,如果某个表的数据有明显的时间特征,比如订单、交易记录等,则他们通常比较合适用时间范围分片,因为具有时效性的数据,我们往往关注其近期的数据,查询条件中往往带有时间字段进行过滤,比较好的方案是,当前活跃的数据,采用跨度比较短的时间段进行分片,而历史性的数据,则采用比较长的跨度存储。
- 总体上来说,分片的选择是取决于最频繁的查询SQL的条件,因为不带任何Where语句的查询SQL,会遍历所有的分片,性能相对最差,因此这种SQL越多,对系统的影响越大,所以我们要尽量避免这种SQL的产生。
索引
是什么
帮助MySQL高效获取数据的数据结构,也可以称为快速查找排序的一种数据结构。Mysql索引主要有两种结构:B+Tree索引和Hash索引。我们平常所说的索引,如果没有特别指明,一般都是指B树结构组织的索引(B+Tree索引)。
Mysql索引为什么选择B+树
- mysql 主要是由 server 层和存储层两部分构成的。server 层主要包括连接器、查询缓存,分析器、优化器、执行器。存储层主要是用来存储和查询数据的,常用的存储引擎有 InnoDB、MyISAM,MySQL 5.5.5版本后使用 InnoDB 作为默认存储引擎。
- 几种常见的数据类型哈希表适合等值查询,由于是无序的,区间查询会很慢有序数组适合等值和区间查询,但是数组具有连续性,插入和删除操作都可能需要移动其他元素。二叉搜索树由于树的高度,区间查询需要中序遍历,都会导致查询效率很慢。 B+ 树就是通过二叉搜索树推演改进的
- B+ 树就是一种多叉树,是由二叉搜索树不断演变过来的,为了满足区间快速查询,B+ 树的叶子节点通过双向链表串联起来。
- 这里使用双向链表是为了支持顺序和倒序查询,虽然双向链表相对于单向链表虽然会浪费一倍的指针空间,但是在硬盘中这点空间几乎微乎其微,用这点空间换时间是一件很值得的事情。
- B+ 树的子节点数不超过 m 个,同时也不能少于 m/2 个,一旦超过就需要分裂,一旦少于就需要合并。
- 而InnoDB 在底层是采用 B+ 树这种数据结构来存储数据的。
Mysql为什么加索引就快
不加索引,会比较整个数据库,因为他不知道数据是不是规律的。添加了索引,相当于加了一个目录,给索引字段排序,比较的时候只用几次就可以查找到你需要的数据。数据越多,索引约有用。也可以说拿空间换时间。
索引对性能的影响:
- 大大减少服务器需要扫描的数据量。
- 帮助服务器避免排序和临时表。将随机I/O变顺序I/O。
- 大大提高查询速度,降低写的速度、占用磁盘。
索引的使用场景:
- 对非常小的表,大部分情况下全表扫描效率更高。
- 对中大型表,索引非常有效
- 特大型的表,建立和使用索引的代价随着增长,可以使用分区技术来解决。
索引的类型
- 索引都是实现在存储引擎层的。
- 普通索引:最基本的索引,没有任何约束
- 唯一索引:与普通索引类似,但具有唯一性约束
- 主键索引:特殊的唯一索引,不允许有空值
- 组合索引:将多个列组合在一起创建索引,可以覆盖多个列
- 外键索引:只有InnoDB类型的表才可以使用外键索引,保证数据的一致性、完整性和实现级联操作
- 全文索引:MySQL自带的全文索引只能用于MyISAM,并且只能对英文进行全文检索,一般使用全文索引引擎
** 主键索引和唯一索引的区别 **
- 一个表只能有一个主键索引,可以有多个唯一索引
- 主键索引一定是唯一索引,唯一索引不是主键索引
- 主键和外键构成参照完整性约束,防止数据不一致
MySQL索引的创建原则
- 索引并不是越多越好,要根据查询有针对性的创建,考虑在
WHERE和ORDER BY命令上涉及的列建立索引,可根据EXPLAIN来查看是否用了索引还是全表扫描- 应尽量避免在
WHERE子句中对字段进行NULL值判断,否则将导致引擎放弃使用索引而进行全表扫描- 使用多列索引必须满足最左匹配,注意顺序和查询条件保持一致,同时删除不必要的单列索引
- OR关键字的两个字段必须都是用了索引,该查询才会使用索引.
- LIKE关键字匹配’%’开头的字符串,不会使用索引.
- 值分布很稀少的字段不适合建索引,例如”性别”这种只有两三个值的字段
- 字符字段只建前缀索引,最好不要做主键
- 不用外键,由程序保证约束
- 尽量不用
UNIQUE,由程序保证约束;
选择合适的索引列
- 1)查询频繁的列,在where,group by,order by,on从句中出现的列
- 2)where条件中<,<=,=,>,>=,between,in,以及like 字符串+通配符(%)出现的列
- 3)长度小的列,索引字段越小越好,因为数据库的存储单位是页,一页中能存下的数据越多越好
- 4)离散度大(不同的值多)的列,放在联合索引前面。查看离散度,通过统计不同的列值来实现,count越大,离散程度越高
COMMIT语句和ROLLBACK语句
- [COMMIT]是表示【提交】,就是提交事务的所有操作。具体地说,就是将事务中的所有对数据库的更新写回到磁盘上的物理数据库中去,事务正常结束。
- ROLLBACK指的是【回滚】,即是在事务的运行过程中,发生了某种故障,事务不能继续执行,系统将事务中对数据库的所有的已完成的操作全部撤销,回滚到事务开始之前的状态。
表字段的选择,Sql语句编写规范
创建表时表字段设计
- 1.表字段避免null值出现,null值很难查询优化且占用额外的索引空间,推荐默认数字0代替null。
- 2.尽量使用INT而非BIGINT,如果非负则加上UNSIGNED(这样数值容量会扩大一倍),当然能使用TINYINT、SMALLINT、MEDIUM_INT更好。
- 3.使用枚举或整数代替字符串类型
- 4.尽量使用TIMESTAMP而非DATETIME
- 5.单表不要有太多字段,建议在20以内
- 6.用整型来存IP
Sql语句编写规范
- 1.使用limit对查询结果的记录进行限定
- 2.避免select * ,将需要查找的字段列出来
- 3.使用连接(join)来代替子查询
- 4.拆分大的delete或insert语句
- 5.可通过开启慢查询日志来找出较慢的SQL
- 6.不做列运算:SELECT id WHERE age + 1 = 10,任何对列的操作都将导致表扫描,它包括数据库教程函数、计算表达式等等,查询时要尽可能将操作移至等号右边
- 7.sql语句尽可能简单:一条sql只能在一个cpu运算;大语句拆小语句,减少锁时间;一条大sql可以堵死整个库
- 9.不用函数和触发器,在应用程序实现
- 10.避免%xxx式查询
- 12.使用同类型进行比较,比如用’123’和’123’比,123和123比
- 15.列表数据不要拿全表,要使用LIMIT来分页,.每页数量也不要太大
逆范式
逆范式化指的是通过增加冗余或重复的数据来提高数据库的读性能。
缓存和缓存集群
缓存
mysql开启默认缓存
- 修改配置文件:windows下是my.ini,linux下是my.cnf,最后加上query_cache_type = 1和query_cache_size = 600000
- 命令方式:使用mysql命令:set global query_cache_type = 1; set global query_cache_size = 600000;
其他的一些mysql设置缓存命令
- set query_cache_type 设置使用查询缓存的方式,默认情况下应该是ON
- show have_query_cache 设置查询缓存是否可用
- select query_cache_size查看缓存大小
- select query_cache_limit 控制缓存查询结果的最大值
缓存发生的层次
- MySQL内部:在系统调优参数介绍了相关设置]\
- 数据访问层:比如MyBatis针对SQL语句做缓存,而Hibernate可以精确到单个记录,这里缓存的对象主要是持久化对象
Persistence Object- 应用服务层:这里可以通过编程手段对缓存做到更精准的控制和更多的实现策略,这里缓存的对象是数据传输对象
Data Transfer Object- Web层:针对web页面做缓存
- 浏览器客户端:用户端的缓存
实现缓存的两种方式
- 直写式(Write Through):在数据写入数据库后,同时更新缓存,维持数据库与缓存的一致性。这也是当前大多数应用缓存框架如Spring Cache的工作方式。这种实现非常简单,同步好,但效率一般。
- 回写式(Write Back):当有数据要写入数据库时,只会更新缓存,然后异步批量的将缓存数据同步到数据库上。这种实现比较复杂,需要较多的应用逻辑,同时可能会产生数据库与缓存的不同步,但效率非常高。
缓存集群
高可用分布式集群
** 高可用(High Availability),是当一台服务器停止服务后,对于业务及用户毫无影响。 停止服务的原因可能由于网卡、路由器、机房、CPU负载过高、内存溢出、自然灾害等不可预期的原因导致,在很多时候也称单点问题。**
解决单点问题主要有2种方式:
- 主备方式: Redis HA中使用比较多的是keepalived,它使主机备机对外提供同一个虚拟IP,客户端通过虚拟IP进行数据操作,正常期间主机一直对外提供服务,宕机后VIP自动漂移到备机上。对客户端毫无影响,仍然通过VIP操作。但是在绝大多数时间内备机是一直没使用,被浪费着的。
- 主从方式:这种采取一主多从的办法,主从之间进行数据同步。 当Master宕机后,通过选举算法(Paxos、Raft)从slave中选举出新Master继续对外提供服务,主机恢复后以slave的身份重新加入。
- 主从另一个目的是进行读写分离,这是当单机读写压力过高的一种通用型解决方案。 其主机的角色只提供写操作或少量的读,把多余读请求通过负载均衡算法分流到单个或多个slave服务器上。
- 缺点是主机宕机后,Slave虽然被选举成新Master了,但对外提供的IP服务地址却发生变化了,意味着会影响到客户端。 解决这种情况需要一些额外的工作,在当主机地址发生变化后及时通知到客户端,客户端收到新地址后,使用新地址继续发送新请求。
数据同步
- 同步方式:当主机收到客户端写操作后,以同步方式把数据同步到从机上,当从机也成功写入后,主机才返回给客户端成功,也称数据强一致性。 很显然这种方式性能会降低不少,当从机很多时,可以不用每台都同步,主机同步某一台从机后,从机再把数据分发同步到其他从机上,这样提高主机性能分担同步压力。 在redis中是支持这杨配置的,一台master,一台slave,同时这台salve又作为其他slave的master。
- 异步方式:主机接收到写操作后,直接返回成功,然后在后台用异步方式把数据同步到从机上。 这种同步性能比较好,但无法保证数据的完整性,比如在异步同步过程中主机突然宕机了,也称这种方式为数据弱一致性。
- Redis主从同步采用的是异步方式,因此会有少量丢数据的危险。还有种弱一致性的特例叫最终一致性
方案选择
keepalived方案配置简单、人力成本小,在数据量少、压力小的情况下推荐使用。 如果数据量比较大,不希望过多浪费机器,还希望在宕机后,做一些自定义的措施,比如报警、记日志、数据迁移等操作,推荐使用主从方式,因为和主从搭配的一般还有个管理监控中心。
分布式(distributed), 是当业务量、数据量增加时,可以通过任意增加减少服务器数量来解决问题。
集群时代
- 至少部署两台Redis服务器构成一个小的集群,主要有2个目的:
- 高可用性:在主机挂掉后,自动故障转移,使前端服务对用户无影响。
- 读写分离:将主机读压力分流到从机上。
- 可在客户端组件上实现负载均衡,根据不同服务器的运行情况,分担不同比例的读请求压力。
Redis集群方案应该怎么做
- codis:目前用的最多的集群方案,基本和twemproxy一致的效果,但它支持在 节点数量改变情况下,旧节点数据可恢复到新hash节点。
- redis cluster3.0自带的集群,特点在于他的分布式算法不是一致性hash,而是hash槽的概念,以及自身支持节点设置从节点。具体看官方文档介绍。
- 在业务代码层实现,起几个毫无关联的redis实例,在代码层,对key 进行hash计算,然后去对应的redis实例操作数据。 这种方式对hash层代码要求比较高,考虑部分包括,节点失效后的替代算法方案,数据震荡后的自动脚本恢复,实例的监控,等等
Redis集群方案什么情况下会导致整个集群不可用
有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用。
Redis集群的主从复制模型是怎样的
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有N-1个复制品.
Redis的注意事项
- Redis并不能保证数据的强一致性,这意味这在实际中集群在特定的条件下可能会丢失写操作。
- Redis集群最大节点个数16384个。
- Redis集群目前无法做数据库选择,默认在0数据库。
sql 语句层
sql 语句层:结果一样的情况下,采用效率高,速度快节省资源的 sql 语句执行
查找查询慢的原因
导致SQL执行慢的原因
- 1.硬件问题。如网络速度慢,内存不足,I/O吞吐量小,磁盘空间满了等
- 2.没有索引或者索引失效。(一般在互联网公司,DBA会在半夜把表锁了,重新建立一遍索引,因为当你删除某个数据的时候,索引的树结构;就不完整了。所以互联网公司的数据做的是假删除.一是为了做数据分析,二是为了不破坏索引 )
- 3.数据过多(分库分表)
- 4.服务器调优及各个参数设置(调整my.cnf)
找切入点
- 1.先观察,开启慢查询日志,设置相应的阈值(比如超过3秒就是慢SQL)。
- mysql的配置文件里( windows系统是my.ini,linux系统是 my.cnf )的 [mysqld] 中加入log-slow-queries=/var/lib/mysql/slowquery.log 和long_query_time=2
- log-slow-queries : 代表MYSQL慢查询的日志存储目录, 此目录文件一定要有写权限。long_query_time: sql最长执行时间。
- 2.Explain显示mysql如何使用索引和慢SQL分析。比如SQL语句写的烂,索引没有或失效,关联查询太多(有时候是设计缺陷或者不得以的需求)等等。
- Explain返回参数说明
- table 显示这一行的数据是关于哪张表的
- type 这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg,ref、range、indexhe和ALL
- possible_keys 显示可能应用在这张表中的索引。如果为空,没有可能的索引。
- key 实际使用的索引。如果为NULL,则没有使用索引。
- key_len 使用的索引的长度。在不损失精确性的情况下,长度越短越好
- ref 显示索引的哪一列被使用了,如果可能的话,是一个常数
- rows MYSQL认为必须检查的用来返回请求数据的行数
- 3.Show Profile是比Explain更近一步的执行细节,可以查询到执行每一个SQL都干了什么事,这些事分别花了多少秒
- 限制版本:Show profiles是5.0.37之后添加的,要想使用此功能,要确保版本在5.0.37之后。
- 用来干什么:SHOW PROFILE 是MySQL提供可以用来分析当前会话语句执行的资源消耗情况,可以用于SQL 的调优测评依据。在默认的情况下,参数处于关闭状态,并保存着最近15 次的运行结果。
- 命令:
- 通过 SHOW VARIABLES LIKE ‘PROFILING’; 命令查看参数的开关情况;
- 通过 SET PROFILING = ON; 命令设置开启状态。
- 通过 Show profiles 执行
- 查询结果参数说明
- Query_ID表示从连接上数据库到现在执行的SQL 语句序号,Duration 表示执行该SQL 所耗费的时间(S),Query 表示执行的操作。
- 如果我们想要具体的知道执行SQL 时CPU 与 I/O 的消耗,可以使用 SHOW PROFILE CPU ,BLOCK IO FOR QUERY Query_ID; 命令
- 也可以可以通过Status 属性清楚的知道MySQL在执行SQL 语句时每个阶段所消耗的时间,CPU 内存 与 I/O 资源。
- Status一些参数说明
- converting HEAP to MyISAM 查询结果集太大,内存不够借用磁盘空间
- Creating tmp table 拷贝数据到临时表(先创建,然后拷贝数据,用完后会自动删除),很消耗资源
- Coping to tmp table on disk 把内存中的临时表复制到磁盘,很危险
- Locked 加锁
socket,tcp,http三者之间的区别和原理
不同的TCP/IP和其他的协议在最初OSI模型中的位置
- | 7 | 应用层 :HTTP、SMTP、SNMP、FTP、Telnet、SIP、SSH、NFS、RTSP、XMPP、Whois、ENRP
- | 6 | 表示层:XDR、ASN.1、SMB、AFP、NCP
- | 5 | 会话层 :ASAP、TLS、SSH、ISO 8327 / CCITT X.225、RPC、NetBIOS、ASP、Winsock、BSD sockets
- | 4 | 传输层 :TCP、UDP、RTP、SCTP、SPX、ATP、IL
- | 3 | 网络层 : IP、ICMP、IGMP、IPX、BGP、OSPF、RIP、IGRP、EIGRP、ARP、RARP、 X.25
- | 2 | 数据链路层 :以太网、令牌环、HDLC、帧中继、ISDN、ATM、IEEE 802.11、FDDI、PPP
- | 1 | 物理层 :线路、无线电、光纤、信鸽
1、TCP/IP连接
TCP协议可以对上层网络提供接口,使上层网络数据的传输建立在“无差别”的网络之上。
- 建立起一个TCP连接需要经过三次握手
- 第一次握手:客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;
- 第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
- 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手
- 握手过程中传送的包里不包含数据,三次握手完毕后,客户端与服务器才正式开始传送数据。理想状态下,TCP连接一旦建立,在通信双方中的任何一方主动关闭连接之前,TCP连接都将被一直保持下去。断开连接时服务器和客户端均可以主动发起断开TCP连接的请求,断开过程需要经过“四次握手”(过程就不细写了,就是服务器和客户端交互,最终确定断开).
2、HTTP连接
HTTP协议即超文本传送协议(Hypertext Transfer Protocol ),是Web联网的基础,也是手机联网常用的协议之一,HTTP协议是建立在TCP协议之上的一种应用。
- HTTP连接最显著的特点是客户端发送的每次请求都需要服务器回送响应,在请求结束后,会主动释放连接。从建立连接到关闭连接的过程称为“一次连接”。
- 1)在HTTP 1.0中,客户端的每次请求都要求建立一次单独的连接,在处理完本次请求后,就自动释放连接。
- 2)在HTTP 1.1中则可以在一次连接中处理多个请求,并且多个请求可以重叠进行,不需要等待一个请求结束后再发送下一个请求。
- 由于HTTP在每次请求结束后都会主动释放连接,因此HTTP连接是一种“短连接”,要保持客户端程序的在线状态,需要不断地向服务器发起连接请求。通常的做法是即时不需要获得任何数据,客户端也保持每隔一段固定的时间向服务器发送一次“保持连接”的请求,服务器在收到该请求后对客户端进行回复,表明知道客户端“在线”。若服务器长时间无法收到客户端的请求,则认为客户端“下线”,若客户端长时间无法收到服务器的回复,则认为网络已经断开。
3、SOCKET原理
套接字(socket)概念
- 套接字(socket)是通信的基石,是支持TCP/IP协议的网络通信的基本操作单元。它是网络通信过程中端点的抽象表示,包含进行网络通信必须的五种信息:连接使用的协议,本地主机的IP地址,本地进程的协议端口,远地主机的IP地址,远地进程的协议端口。
- 应用层通过传输层进行数据通信时,TCP会遇到同时为多个应用程序进程提供并发服务的问题。多个TCP连接或多个应用程序进程可能需要通过同一个TCP协议端口传输数据。为了区别不同的应用程序进程和连接,许多计算机操作系统为应用程序与TCP/IP协议交互提供了套接字(Socket)接口。应用层可以和传输层通过Socket接口,区分来自不同应用程序进程或网络连接的通信,实现数据传输的并发服务。
建立socket连接
- 建立Socket连接至少需要一对套接字,其中一个运行于客户端,称为ClientSocket ,另一个运行于服务器端,称为ServerSocket 。
- 套接字之间的连接过程分为三个步骤:服务器监听,客户端请求,连接确认。
- 服务器监听:服务器端套接字并不定位具体的客户端套接字,而是处于等待连接的状态,实时监控网络状态,等待客户端的连接请求。
- 客户端请求:指客户端的套接字提出连接请求,要连接的目标是服务器端的套接字。为此,客户端的套接字必须首先描述它要连接的服务器的套接字,指出服务器端套接字的地址和端口号,然后就向服务器端套接字提出连接请求。
- 连接确认:当服务器端套接字监听到或者说接收到客户端套接字的连接请求时,就响应客户端套接字的请求,建立一个新的线程,把服务器端套接字的描述发给客户端,一旦客户端确认了此描述,双方就正式建立连接。而服务器端套接字继续处于监听状态,继续接收其他客户端套接字的连接请求。
4、SOCKET连接与TCP/IP连接
- 建Socket连接时,可以指定使用的传输层协议,Socket可以支持不同的传输层协议(TCP或UDP),当使用TCP协议进行连接时,该Socket连接就是一个TCP连接。
- socket则是对TCP/IP协议的封装和应用(程序员层面上)。也可以说,TPC/IP协议是传输层协议,主要解决数据 如何在网络中传输,而HTTP是应用层协议,主要解决如何包装数据。关于TCP/IP和HTTP协议的关系,网络有一段比较容易理解的介绍:
- “我们在传输数据时,可以只使用(传输层)TCP/IP协议,但是那样的话,如果没有应用层,便无法识别数据内容,如果想要使传输的数据有意义,则必须使用到应用层协议有很多,比如HTTP、FTP、TELNET等,也可以自己定义应用层协议。WEB使用HTTP协议作应用层协议,以封装HTTP文本信息,然后使用TCP/IP做传输层协议将它发到网络上。”
- 我们平时说的最多的socket是什么呢,实际上socket是对TCP/IP协议的封装,Socket本身并不是协议,而是一个调用接口(API),通过Socket,我们才能使用TCP/IP协议。 实际上,Socket跟TCP/IP协议没有必然的联系。Socket编程接口在设计的时候,就希望也能适应其他的网络协议。所以说,Socket的出现,只是使得程序员更方便地使用而已,是对TCP/IP协议的抽象,从而形成了我们知道的一些最基本的函数接口,比如create、listen、connect、accept、send、read和write等等。
- “TCP/IP只是一个协议栈,就像操作系统的运行机制一样,必须要具体实现,同时还要提供对外的操作接口。这个就像操作系统会提供标准的编程接口,比如win32编程接口一样,TCP/IP也要提供可供程序员做网络开发所用的接口,这就是Socket编程接口。”
- 实际上,传输层的TCP是基于网络层的IP协议的,而应用层的HTTP协议又是基于传输层的TCP协议的,而Socket本身不算是协议,就像上面所说,它只是提供了一个针对TCP或者UDP编程的接口。socket是对端口通信开发的工具,它要更底层一些
5、Socket连接与HTTP连接
- 由于通常情况下Socket连接就是TCP连接,因此Socket连接一旦建立,通信双方即可开始相互发送数据内容,直到双方连接断开。但在实际网络应用中,客户端到服务器之间的通信往往需要穿越多个中间节点,例如路由器、网关、防火墙等,大部分防火墙默认会关闭长时间处于非活跃状态的连接而导致 Socket 连接断连,因此需要通过轮询告诉网络,该连接处于活跃状态。
- 而HTTP连接使用的是“请求—响应”的方式,不仅在请求时需要先建立连接,而且需要客户端向服务器发出请求后,服务器端才能回复数据。
- 很多情况下,需要服务器端主动向客户端推送数据,保持客户端与服务器数据的实时与同步。此时若双方建立的是Socket连接,服务器就可以直接将数据传送给客户端;若双方建立的是HTTP连接,则服务器需要等到客户端发送一次请求后才能将数据传回给客户端,因此,客户端定时向服务器端发送连接请求,不仅可以保持在线,同时也是在“询问”服务器是否有新的数据,如果有就将数据传给客户端。
- http协议是应用层的协义
- 有个比较形象的描述:HTTP是轿车,提供了封装或者显示数据的具体形式;Socket是发动机,提供了网络通信的能力。
- 两个计算机之间的交流无非是两个端口之间的数据通信,具体的数据会以什么样的形式展现是以不同的应用层协议来定义的如HTTP,FTP…
vue
Vue单页网页路由
什么是单页Web应用
单页Web应用(single page web application,SPA),就是只有一张Web页面的应用。单页应用程序 (SPA) 是加载单个HTML 页面并在用户与应用程序交互时动态更新该页面的Web应用程序。^ [1]^ 浏览器一开始会加载必需的HTML、CSS和JavaScript,所有的操作都在这张页面上完成,都由JavaScript来控制。因此,对单页应用来说模块化的开发和设计显得相当重要。
通常spa前端路由实现有两种方式
window.history
- window.history 对象包含浏览器的历史,window.history 对象在编写时可不使用 window 这个前缀。history是实现SPA前端路由是一种主流方法,它有几个原始方法
- history.back() - 与在浏览器点击后退按钮相同
- history.forward() - 与在浏览器中点击按钮向前相同
- history.go(n) - 接受一个整数作为参数,移动到该整数指定的页面,比如go(1)相当于forward(),go(-1)相当于back(),go(0)相当于刷新当前页面
- 注意:如果移动的位置超出了访问历史的边界,以上三个方法并不报错,而是静默失败
- 在HTML5,history对象提出了 pushState() 方法和 replaceState() 方法,这两个方法可以用来向历史栈中添加数据,就好像 url 变化了一样,这样就可以很好的模拟浏览历史和前进后退了,现在的前端路由也是基于这个原理实现的
- history.pushState(stateObj, title, url) 方法向历史栈中写入数据,其第一个参数是要写入的数据对象(不大于640kB),第二个参数是页面的 title, 第三个参数是 url (相对路径)。pushState方法不会触发页面刷新,只是导致history对象发生变化,地址栏会有反应,只有当触发前进后退等事件(back()和forward()等)时浏览器才会刷新
- history.replaceState(stateObj, title, url) 和pushState的区别就在于它不是写入而是替换修改浏览历史中当前纪录,其余和 pushState一模一样
location.hash
- hash模式:在浏览器中符号“#”,#以及#后面的字符称之为hash,用window.location.hash读取;
- 特点:hash虽然在URL中,但不被包括在HTTP请求中;用来指导浏览器动作,对服务端安全无用,hash不会重加载页面。
- hash 模式下,仅 hash 符号之前的内容会被包含在请求中,如 [http://www.xxx.com],因此对于后端来说,即使没有做到对路由的全覆盖,也不会返回 404 错误。
Vue的MVVM模式
- MVVM是Model-View-ViewModel的简写。即模型-视图-视图模型。【模型】指的是后端传递的数据。【视图】指的是所看到的页面。【视图模型】mvvm模式的核心,它是连接view和model的桥梁。
- 它有两个方向:
- 一是将【模型】转化成【视图】,即将后端传递的数据转化成所看到的页面。实现的方式是:数据绑定。
- 二是将【视图】转化成【模型】,即将所看到的页面转化成后端的数据。实现的方式是:DOM 事件监听。这两个方向都实现的,我们称之为数据的双向绑定。
- Vue就是基于MVVM模式实现的一套框架,在vue中:Model:指的是js中的数据,如对象,数组等等。View:指的是页面视图viewModel:指的是vue实例化对象
渐进式的javascript框架
渐进式是什么意思?
- 1.如果你已经有一个现成的服务端应用,你可以将vue 作为该应用的一部分嵌入其中,带来更加丰富的交互体验;
- 2.如果你希望将更多业务逻辑放到前端来实现,那么VUE的核心库及其生态系统也可以满足你的各式需求(core+vuex+vue-route)。和其它前端框架一样,VUE允许你将一个网页分割成可复用的组件,每个组件都包含属于自己的HTML、CSS、JAVASCRIPT以用来渲染网页中相应的地方。
- 3.如果我们构建一个大型的应用,在这一点上,我们可能需要将东西分割成为各自的组件和文件,vue有一个命令行工具,使快速初始化一个真实的工程变得非常简单(vue init webpack my-project)。
我们可以使用VUE的单文件组件,它包含了各自的HTML、JAVASCRIPT以及带作用域的CSS或SCSS。以上这三个例子,是一步步递进的,也就是说对VUE的使用可大可小,它都会有相应的方式来整合到你的项目中。所以说它是一个渐进式的框架。VUE最独特的特性:响应式系统VUE是响应式的(reactive),也就是说当我们的数据变更时,VUE会帮你更新所有网页中用到它的地方。
Vue双向绑定
- vue实现数据双向绑定主要是:采用数据劫持结合发布者订阅者模式的方式,通过Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应监听回调。当把一个普通 Javascript 对象传给 Vue 实例来作为它的 data 选项时,Vue 将遍历它的属性,用 Object.defineProperty 将它们转为 getter/setter。用户看不到 getter/setter,但是在内部它们让 Vue 追踪依赖,在属性被访问和修改时通知变化。
- vue的数据双向绑定 将MVVM作为数据绑定的入口,整合Observer,Compile和Watcher三者,通过Observer来监听自己的model的数据变化,通过Compile来解析编译模板指令(vue中是用来解析 {{}}),最终利用watcher搭起observer和Compile之间的通信桥梁,达到数据变化 —>视图更新;视图交互变化(input)—>数据model变更双向绑定效果。
Vue生命周期
什么是vue生命周期?
Vue 实例从创建到销毁的过程,就是生命周期。从开始创建、初始化数据、编译模板、挂载Dom→渲染、更新→渲染、销毁等一系列过程,称之为 Vue 的生命周期。
Vue生命周期的作用
它的生命周期中有多个事件钩子,让我们在控制整个Vue实例的过程时更容易形成好的逻辑。
Vue生命周期的过程
它可以总共分为8个阶段:创建前/后, 载入前/后,更新前/后,销毁前/销毁后。
beforeCreate(创建前) 在数据观测和初始化事件还未开始
created(创建后) 完成数据观测,属性和方法的运算,初始化事件,$el属性还没有显示出来
beforeMount(载入前) 在挂载开始之前被调用,相关的render函数首次被调用。实例已完成以下的配置:编译模板,把data里面的数据和模板生成html。注意此时还没有挂载html到页面上。
mounted(载入后) 在el 被新创建的 vm.$el 替换,并挂载到实例上去之后调用。实例已完成以下的配置:用上面编译好的html内容替换el属性指向的DOM对象。完成模板中的html渲染到html页面中。此过程中进行ajax交互。
beforeUpdate(更新前) 在数据更新之前调用,发生在虚拟DOM重新渲染和打补丁之前。可以在该钩子中进一步地更改状态,不会触发附加的重渲染过程。
updated(更新后) 在由于数据更改导致的虚拟DOM重新渲染和打补丁之后调用。调用时,组件DOM已经更新,所以可以执行依赖于DOM的操作。然而在大多数情况下,应该避免在此期间更改状态,因为这可能会导致更新无限循环。该钩子在服务器端渲染期间不被调用。
beforeDestroy(销毁前) 在实例销毁之前调用。实例仍然完全可用。
destroyed(销毁后) 在实例销毁之后调用。调用后,所有的事件监听器会被移除,所有的子实例也会被销毁。该钩子在服务器端渲染期间不被调用。
.第一次页面加载会触发哪几个钩子?
会触发 下面这几个beforeCreate, created, beforeMount, mounted 。
DOM 渲染在 哪个周期中就已经完成?
DOM 渲染在 mounted 中就已经完成了。
Vue三种常用传值方式
父组件向子组件传值
- 使用props建立数据通道的渠道
- 在子组件中通过props传递过来的数据
子组件向父组件传值
- 子组件中需要一个点击事件触发一个自定义事件
- 在父组件中的子标签监听该自定义事件得到传递的值
非父子组件传值
- 1他们之间有一个共同的容器,假设A和B之间传值,我们可以用localstoage和SessionStorage把A的数据传给共同的容器,然后B从这个容器中再把A的数据取出来。
- 2.可以先定义一个bus的空对象,首先A通过‘emit发送数据到bus这个空对象中,然后B通过emit发送数据到bus这个空对象中,然后B通过on来接收这个空对象的数据。
- 3.vuex集中管理的方式传值也是和上面一样的办法,只是在数据较多且复杂的情况下才用,具体操作都是通过一个中间人来传递数据。
Vuex
Vuex是什么
Vuex是一个专门为Vue.js应用程序开发的状态管理模式, 它采用集中式存储管理所有组件的公共状态, 并以相应的规则保证状态以一种可预测的方式发生变化.
vuex的核心概念
- vuex五大核心属性:state,getter,mutation,action,module
- getter:可以认为是 store 的计算属性,它的返回值会根据它的依赖被缓存起来,且只有当它的依赖值发生了改变才会被重新计算。
- mutation:更改 Vuex 的 store 中的状态的唯一方法是提交 mutation。
- action:包含任意异步操作,通过提交 mutation 间接更变状态。
- module:将 store 分割成模块,每个模块都具有state、mutation、action、getter、甚至是嵌套子模块。
vuex的数据传递流程
当组件进行数据修改的时候我们需要调用dispatch来触发actions里面的方法。actions里面的每个方法中都会有一个commit方法,当方法执行的时候会通过commit来触发mutations里面的方法进行数据的修改。mutations里面的每个函数都会有一个state参数,这样就可以在mutations里面进行state的数据修改,当数据修改完毕后,会传导给页面。页面的数据也会发生改变。
为什么要用vuex
由于传参的方法对于多层嵌套的组件将会非常繁琐,并且对于兄弟组件间的状态传递无能为力。我们经常会采用父子组件直接引用或者通过事件来变更和同步状态的多份拷贝。以上的这些模式非常脆弱,通常会导致代码无法维护。所以我们需要把组件的共享状态抽取出来,以一个全局单例模式管理。在这种模式下,我们的组件树构成了一个巨大的“视图”,不管在树的哪个位置,任何组件都能获取状态或者触发行为!另外,通过定义和隔离状态管理中的各种概念并强制遵守一定的规则,我们的代码将会变得更结构化且易维护。
mysql各字段的区别
char,varchar和text
- char是采用固定长度存储数据,也就是数据初始化为该类型的字段分配固定长度的存储空间,即使没有达到存储空间的长度,实际占用的存储空间也是定义时的长度。当存储的字符串没有达到char的最大长度时,字符串后面是不会以空格来填充的,而且char会过滤字符串末端的空格然后存储,而在比较字符串的时候又会自动空格填充到字符串的末端。虽然浪费存储空间,但是它固定长度,索引效率极高,不存在碎片。最多能存放的字符个数 255。
- varchar是存储可变长度的字符串,我们可以指定的字段长度的最大长度,当字符串没有达到最大长度的时候以字符串的实际长度来存储的,不占用多余的存储空间。varchar不定长,索引速度没有char快。理论上可以添加全部索引,但是数据长度太大时索引也会截取数据前面的一部分。但是如果字段的长度越大,在字段不完全填充的情况下,varchar的性能优势就越明显。最多能存放 65532 个字符。
int、tinyint、float与decimal
- TINYINT一个很小的整数。有符号的范围是-128到127,无符号的范围是0到255。一个字符
- SMALLINT一个小整数。有符号的范围是-32768到32767,无符号的范围是0到65535。两个字符
- MEDIUMINT一个中等大小整数。有符号的范围是-8388608到8388607,无符号的范围是0到16777215。三个字符
- INT一个正常大小整数。有符号的范围是-2147483648到2147483647,无符号的范围是0到4294967295。四个字符
- BIGINT一个大整数。有符号的范围是-9223372036854775808到9223372036854775807,无符号的范围是0到18446744073709551615。八个字符。注意,所有算术运算用有符号的BIGINT或DOUBLE值完成,因此你不应该使用大于9223372036854775807(63位)的有符号大整数,除了位函数!
- FLOAT一个小(单精密)浮点数字。不能无符号。允许的值是-3.402823466E+38-1.175494351E-38,0 和1.175494351E-38到3.402823466E+38。没有参数的FLOAT或有<24 的一个参数表示一个单精密浮点数字。
- DOUBLE一个正常大小(双精密)浮点数字。不能无符号。允许的值是-1.7976931348623157E+308到-2.2250738585072014E-308、 0和2.2250738585072014E-308到1.7976931348623157E+308。
- decimal表示数值的精度,即实际保存到数据库的有效数字的总个数; 第二个参数代表小数点后的位数
DATE,DATETIME,TIME,TIMESTAMP,YEAR;
- DATE 为年月日的日期格式,标准格式为YYYY-MM-DD,但是mysql中还支持一些不严谨的格式:比如YYYY/MM/DD等其他的符号来分割,在插入数据的数据的也可以使用YY-MM-DD 年份的转换,可以使用CURRENT_DATE() 函数获取当前的DATE值,占三个字节
- DATETIME 为年月日时分秒的混合时间格式,DATE和TIME类型的结合体,占八个字节
- YEAR 为年份的时间的格式,占一个字节
- TIME 为时分秒的时间格式时间范围为0~23,但是为了表示某些特殊的时间,mysql将小时的范围扩大了,并且支持负值。对于TIME类型复制,标准的格式为HH
SS,但不一定要这个格式,在mysql中,系统可以自动识别HHMMSS转化为标准格式.我们可以通过CURRENT_TIME()获取当前的TIME值,三个字节
- TIMESTAMP 为年月份时分秒的混合时间格式,以时间戳的格式存储。取值范围比DATETIME小,因此输入时一定要注意输入值的范围,超过范围会当作零值处理。占四个字节
PSR0~4
psr0(官方已废弃)
自动加载标准
- 一个完全合格的namespace和class必须符合这样的结构:“< Vendor Name>(< Namespace>)*< Class Name>”
- 每个namespace必须有一个顶层的namespace(”Vendor Name”提供者名字)
- 每个namespace可以有多个子namespace
- 当从文件系统中加载时,每个namespace的分隔符(/)要转换成DIRECTORY_SEPARATOR(操作系统路径分隔符)
- 在类名中,每个下划线要转换成DIRECTORY_SEPARATOR(操作系统路径分隔符)。在namespace中,下划线是没有(特殊)意义的。
- 当从文件系统中载入时,合格的namespace和class一定是以 .php 结尾的verdor name,namespaces,class名可以由大小写字母组合而成(大小写敏感的)
psr1
基本代码规范
PHP源文件必须只使用 <?php 和 <?= 这两种标签。(php标记有多种方式)
源文件中php代码的编码格式必须是不带字节顺序标记(BOM)的UTF-8。(注:PHP在设计时就没有考虑BOM的问题,也就是说他不会忽略UTF-8编码的文件开头BOM的那三个字节导致出现奇怪的错误。)
一个源文件建议只用来做声明(类(class),函数(function),常量(constant)等)或者只用来做一些引起从属效应的操作(例如:输出信息,包含文件,修改.ini配置等),但不能同时使用两者。
注:“从属效应”(side effects)一词的意思是,仅仅通过包含文件,不直接声明类、函数和常量等,而执行的逻辑操作。 “从属效应”包含却不仅限于:生成输出、直接的 require 或 include、连接外部服务、修改 ini 配置、抛出错误或异常、修改全局或静态变量、读或写文件等。 这个很多人都不遵守,但是基本上所有框架里都不会把修改.ini配置和声明类或函数放到一起,比如框架index.php入口文件只定义宏常量和修改.ini等命名空间(namespace)和类(class) 必须遵守PSR0或psr4标准。
类名(class name) 必须使用骆驼式(StudlyCaps)写法(注:StudlyCaps即首字母大写驼峰式)。
类(class)中的常量必须只由大写字母和下划线组成。
方法名(method name) 必须使用驼峰式(cameCase)写法。
psr2
代码风格
- 代码必须遵循PSR-1中的编码规范
- 代码必须使用四个空格符而不是tab键进行缩进。
- 每行的字符数应该软性保持在80个内,理论上不可多于120个,但一定不能硬性限制
- 每个namespace命名空间声明语句和use语句块后面,必须插入一个空白行
- 类的开始花括号必须在类声明后自成一行,结束花名号也必须在类主体后自成一行
- 函数的开始花括号必须在函数声明后自成一行,结束花名号也必须在函数主体后自成一行
- 类的属性和方法必须添加访问修饰符(private protected以及public),abstract以及final必须声明在访问修饰符之前,而static必须声明在访问修饰符之后。
- 控制结构的关键字后必须要有一个空格符,而调用方法或函数时则一定不能有。
- 控制结构的开始花括号必须写在声明的同一行,而结束花括号必须写在主体后自成一行。
- 控制结构的开始左括号后和结束右括号前,都一定不能有空格符。
注意
对于php文件:
- 所有的php文件都必须以Unix LF(换行)作为结束符
- 所有的php文件都必须以一个单独的空行结尾
- 纯PHP代码源文件的关闭标签?>必须省略。
关键字和 True/False/Null
- php的关键字,必须小写
- php产量 true ,false,null也必须小写
命名空间
- 命名空间(namespace)的声明后面必须有一行空行。
- 所有的导入(use)声明必须放在命名空间(namespace)声明的下面。
- 一句声明中,必须只有一个导入(use)关键字。
- 在导入(use)声明代码块后面必须有一行空行。
控制结构
if ,else ,elseif ,while ,do while ,switch case ,for, foreach,try catch等。这一类的写法规范也是经常容易出现问题的,也要规范一下。在关键字和后面的判断条件中间应该加空格,在判断条件和左大括号之间也要加空格。
psr3
日志接口规范
- 它的主要目的,是为了让类库以简单通用的方式接收一个Psr\Log\LoggerInterface对象,来记录日志信息。框架以及CMS内容管理系统如有需要,可以扩展接口以用于它们自己的目的,但须遵循本规范,才能在使用第三方的类库文件时,保证日志接口仍能正常对接。
- LoggerInterface 接口对外定义了八个方法,分别用来记录RFC 5424中定义的八个级别:debug、info、notice、warning、error、critical、alert,emergency。
- 第九个方法-log,其第一个参数为日志的等级,可使用一个预定义好的等级常量作为参数来调用此方法,必须与直接调用以上八个方法具有相同的效果。如果传入的等级常量参数没有预先定义,就必须抛出Psr\Log\InvalidArgumentException类型的异常,在不确定的情况下,使用者不该使用未支持的等级常量来调用此方法。如果有用过monolog就应该对这里有较深的理解。
psr4
升级版的PSR-0自动加载规范
PSR4是关于由文件路径自动载入对应的类的相关规范,本规范是可互操作的。可以作为任一自动(包括PSR-0)载入规范的补充,此外,PSR4还包括自动载入的类对应的文件存放路径规范。此处的“类”泛指所有的class类、接口、traits可复用代码块以及其他类似结构。
一个完整的类名需要具有以下结构<命名空间>(<子命名空间>)*<类名>
- 完整的类名必须要有一个顶级命名空间,被称为“Vendor namespace”
- 完整的类名可以有一个或多个子命名空间
- 完整的类名必须有一个最终的类名
- 完整的类名中任意一部分中的下划线都是没有特殊意义的
- 完整的类名可以由任意大小写字母组成
- 所有类名都必须是大小写敏感的
当根据完整的类名载入相应的文件
- 完整的类名中,去掉最前面的命名空间分隔符,前面连续的一个或多个命名空间和子命名空间,作为“命名空间前缀”,其必须至少对应一个基础目录。
- 紧接命名空间前缀后的子命名空间必须与相对应的“基础目录”的子目录相匹配,其中的命名空间分隔符作为目录分割符
- 末尾的类名必须与对应的.php为后缀的文件同名
- 自动加载器(autoloader)的实现一定不能抛出异常,一定不能触发任一级别的错误信息以及不应该有返回值。
PSR-4和PSR-0最大的区别是对下划线(underscore)的定义不同。PSR-4中,在类名中使用下划线没有任何特殊含义。而PSR-0则规定类名中的下划线_会被转化成目录分隔符。
ES
简介
- 一个高扩展、开源的全文检索和分析引擎,它可以准实时地快速存储、搜索、分析海量的数据。
- 全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。全文搜索搜索引擎数据库中的数据
ES为什么比mysql快
Mysql只有term dictionary这一层,是以b-tree排序的方式存储在磁盘上的。检索一个term需要若干次的random access的磁盘操作。而Lucene在term dictionary的基础上添加了term index来加速检索,term index以树的形式缓存在内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘的random access次数。另外:term index在内存中是以FST(finite state transducers)的形式保存的,其特点是非常节省内存。Term dictionary在磁盘上是以分block的方式保存的,一个block内部利用公共前缀压缩,比如都是Ab开头的单词就可以把Ab省去。这样term dictionary可以比b-tree更节约磁盘空间。
同步数据库
我们采取MySQL的数据存储,利用MySQL的事务特性维护数据一致性,使用ElasticSearch进行数据汇集和查询,此时es与数据库的同步方案就尤为重要。
流程
首先添加商品入数据库,添加商品成功后,商品入ES,若入ES失败,将失败的商品ID放入redis的缓存队列,且失败的商品ID入log文件(若出现redis挂掉,可从日志中取异常商品ID然后再入ES),task任务每秒刷新一下redis缓存队列,若是从缓存队列中取到商品ID,则根据商品ID从数据库中获取商品数据然后入ES。
使用
logstash-input-jdbc插件同步数据库,安装,配置:创建一个 .conf文件,配置了要同步的数据库和.sql用于执行的sql语句,最后把一个jdbc驱动放到这个文件夹下,用来连接mysql数据库
可能遇到的问题
elasticsearch数据重复以及增量同步
在默认配置下,tracking_column这个值是@timestamp,存在elasticsearch就是_id值,是logstash存入elasticsearch的时间,这个值的主要作用类似mysql的主键,是唯一的,但是我们的时间戳其实是一直在变的,所以我们每次使用select语句查询的数据都会存入elasticsearch中,导致数据重复。
解决方法
在要查询的表中,找主键或者自增值的字段,将它设置为_id的值,因为_id值是唯一的,所以,当有重复的_id的时候,数据就不会重复
数据同步频繁,影响mysql数据库性能
我们写入jdbc.sql文件的mysql语句是写死的,所以每次查询的数据库有很多是已经不需要去查询的,尤其是每次select * from table;的时候,对mysql数据库造成了非常大的压力
解决:
(1)根据业务需求,可以适当修改定时同步时间,我这里对实时性相对要求较高,因此设置了10分钟
schedule => "*/10 * * * *"
(2)设置mysql查询范围,防止大量的查询拖死数据库,在sql语句这里设置select * from WHERE autoid > :sql_last_value;
elasticsearch存储容量不断上升
elasticsearch为了数据安全,接收到数据后,先将数据写入内存和translog,然后再建立索引写入到磁盘,这样即使突然断电,重启后,还可以通过translog恢复,不过这里由于我们每次查询都有很多重复的数据,而这些重复的数据又没有写入到elasticsearch的索引中,所以就囤积了下来,导致elasticsearch容量就不断上升
解决:
查询官网说会定期refresh,会自动清理掉老的日志,因此可不做处理
增量同步和mysql范围查询导致mysql数据库有修改时无法同步到以前的数据。
解决了mysql每次都小范围查询,解决了数据库压力的问题,不过却导致无法同步老数据的修改问题
解决:
可根据业务状态来做,如果你数据库是修改频繁类型,那只能做全量更新了,但是高频率大范围扫描数据库来做的索引还不如不做索引了(因为建立索引也是有成本的),我们做索引主要是针对一些数据量大,不常修改,很消耗数据库性能的情况。我这里是数据修改较少,而且修改也一般是近期数据,因为同步时,我在mysql范围上面稍微调整一下
php使用ES
- php composer安装composer require elasticsearch/elasticsearch
- 引入es文件autoload.php文件,设置IP地址
- 创建index,index 对应关系型数据(以下简称MySQL)里面的数据库,而不是对应MySQL里面的索引
- 有了数据库还不行,还需要建立表,ES也是一样的,ES中的type对应MySQL里面的表。type不是单独定义的,而是和字段一起定义,字段定义在body中;当然可以在body字段中也能使用ik分词;
- 使用EsClient->search()实现搜索;
同义词和近义词的使用
- 配置分词器:配置IK
- 下载es的ik版本包
- 在es目录下的plugins在创建
ik目录,把下载ik的zip包所有文件解压进去。- 进去es的config目录,编辑
elasticsearch.yml,在空白地方加上index.analysis.analyzer.default.type : "ik"即可。- 拼音分词器配置:使用已经编译好的:elasticsearch-analysis-pinyin-1.3.0
- 在elasticsearch的plugins目录下,新建analysis-pinyin文件夹,解压压缩包,将里面的jar包放到analysis-pinyin文件夹。
- 在elasticsearch.yml里面配置拼音分词器的过滤器
- 同义词分词器配置
- 在elasticsearch.yml里面配置好同义词分词器的过滤器
- 配置同义词词库,在elasticsearch的config目录下新建sysnonym.txt。
- 配置ik+pinying+同义词的分词器,主要有分词器的名称,类型,分割词元的组件,对分割的次元做处理:这里使用的是拼音和同义词
ES 关键字高亮显示
ES 通过在查询的时候可以在查询之后的字段数据加上html 标签字段,使文档在在web 界面上显示的时候是由颜色或者字体格式的,是在highlight修饰高亮字段, 这个部分包含了 name 属性匹配的文本片段,并以 HTML 标签 封装
ES查询分页
Elasticsearch中数据都存储在分片中,当执行搜索时每个分片独立搜索后,数据再经过整合返回。
一般查询流程为
- 1)客户端请求发给某个节点
- 2)节点转发给个个分片,查询每个分片上的前10条
- 3)结果返回给节点,整合数据,提取前10条
- 4)返回给请求客户端
当我们查询第10条到第20条的数据时,有两种方式,包括深度分页(from-size)和快照分页(scroll);
深度分页(from-size)
from定义了目标数据的偏移值,size定义当前返回的事件数目。默认from为0,size为10,也就是说所有的查询默认仅仅返回前10条数据。查询前20条数据,然后截断前10条,只返回10-20的数据。浪费了前10条的查询。越往后的分页,执行的效率越低。分页的偏移值越大,执行分页查询时间就会越长
快照分页(scroll)
相对于from和size的分页来说,使用scroll可以模拟一个传统数据的游标,记录当前读取的文档信息位置。这个分页的用法,不是为了实时查询数据,而是为了一次性查询大量的数据(甚至是全部的数据)。因为这个scroll相当于维护了一份当前索引段的快照信息,这个快照信息是你执行这个scroll查询时的快照。在这个查询后的任何新索引进来的数据,都不会在这个快照中查询到。但是它相对于from和size,不是查询所有数据然后剔除不要的部分,而是记录一个读取的位置,保证下一次快速继续读取。
流程:
* 调用:index/type/_search?pretty&scroll=2m,返回一个scroll值
* 直接用scroll_id进行查询。
* 清除scroll,我们在设置开启scroll时,设置了一个scroll的存活时间,但是如果能够在使用完顺手关闭,可以提早释放资源,降低ES的负担
redis
简介
- 它支持多种类型的数据结构,如字符串(String),散列(Hash),列表(List),集合 (Set),有序集合(Sorted Set或者是ZSet)与范围查询,Bitmaps,Hyperloglogs 和 地理空间(Geospatial)索引半径查询。其中常见的数据结构类型有:String、List、Set、 Hash、ZSet这5种。
Redis 的对象系统中包括字符串对象(String)、列表对象(List)、哈希对象(Hash)、集合对象(Set)和有序集合对象(ZSet)- Redis 内置了复制(Replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(Transactions) 和不同级别的磁盘持久化(Persistence),并通过 Redis哨兵(Sentinel)和自动分区(Cluster)提供高可用性(High Availability)。
- Redis也提供了持久化的选项,这些选项可以让用户将自己的数据保存到磁盘上面进行存 储。根据实际情况,可以每隔一定时间将数据集导出到磁盘(快照),或者追加到命令日志 中(AOF只追加文件),他会在执行写命令时,将被执行的写命令复制到硬盘里面。您也可 以关闭持久化功能,将Redis作为一个高效的网络的缓存数据功能使用。
- Redis不使用表,他的数据库不会预定义或者强制去要求用户对Redis存储的不同数据进行 关联。
数据库的工作模式按存储方式可分为:硬盘数据库和内存数据库。Redis 将数据储存在内存 里面,读写数据的时候都不会受到硬盘 I/O 速度的限制,所以速度极快。
redis,memcache
- 数据结构:Memcache仅能支持简单的K-V形式,Redis支持的数据更多
- 多线程:Memcached是多线程,非阻塞IO复用的网络模型;Redis使用单线程的IO复用模型。
- 持久化:Redis支持持久化,Memcache不支持持久化
- 分布式:Redis做主从结构,而Memcache服务器需要通过hash一致化来支撑主从结构
- 虚拟内存:Redis当物理内存使用完时,会将一些很久没有用的内存交换到磁盘,而Memcache采取的LUR策略,将一部分数据刷新叼
- 事务:redis支持事务
保持 redis和mysql 数据库的数据一致性
MySQL持久化数据,Redis只读数据
redis在启动之后,从数据库加载数据。
读请求:
不要求强一致性的读请求,走redis,要求强一致性的直接从mysql读取
写请求:
数据首先都写到数据库,之后更新redis(先写redis再写mysql,如果写入失败事务回滚会造成redis中存在脏数据)
MySQL和Redis处理不同的数据类型
- MySQL处理实时性数据,例如金融数据、交易数据
- Redis处理实时性要求不高的数据,例如网站最热贴排行榜,好友列表等
- 在并发不高的情况下,读操作优先读取redis,不存在的话就去访问MySQL,并把读到的数据写回Redis中;写操作的话,直接写MySQL,成功后再写入Redis(可以在MySQL端定义CRUD触发器,在触发CRUD操作后写数据到Redis,也可以在Redis端解析binlog,再做相应的操作)
- 在并发高的情况下,读操作和上面一样,写操作是异步写,写入Redis后直接返回,然后定期写入MySQL
例子
当更新数据时,如更新某商品的库存,当前商品的库存是100,现在要更新为99,先更新数据库更改成99,然后删除缓存,发现删除缓存失败了,这意味着数据库存的是99,而缓存是100,这导致数据库和缓存不一致。
解决方法
这种情况应该是先删除缓存,然后在更新数据库,如果删除缓存失败,那就不要更新数据库,如果说删除缓存成功,而更新数据库失败,那查询的时候只是从数据库里查了旧的数据而已,这样就能保持数据库与缓存的一致性。
问题
在高并发的情况下,如果当删除完缓存的时候,这时去更新数据库,但还没有更新完,另外一个请求来查询数据,发现缓存里没有,就去数据库里查,还是以上面商品库存为例,如果数据库中产品的库存是100,那么查询到的库存是100,然后插入缓存,插入完缓存后,原来那个更新数据库的线程把数据库更新为了99,导致数据库与缓存不一致的情况
解决方法
- 可以用队列的去解决这个问,创建几个队列,如20个,根据商品的ID去做hash值,然后对队列个数取模,当有数据更新请求时,先把它丢到队列里去,当更新完后在从队列里去除,如果在更新的过程中,遇到以上场景,先去缓存里看下有没有数据,如果没有,可以先去队列里看是否有相同商品ID在做更新,如果有也把查询的请求发送到队列里去,然后同步等待缓存更新完成。
- 这里有一个优化点,如果发现队列里有一个查询请求了,那么就不要放新的查询操作进去了,用一个while(true)循环去查询缓存,循环个200MS左右,如果缓存里还没有则直接取数据库的旧数据,一般情况下是可以取到的。
为什么Redis是单线程的
- 官方FAQ表示, 因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的 大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单 线程的方案
- 我们已经可以很清楚的解释了为什么Redis这么快,并且正是由于在单 线程模式的情况下已经很快了,就没有必要在使用多线程了! 但是,我们使用单线程的方式是无法发挥多核CPU 性能,不过我们可以通过在单机开多个 Redis 实例来完善!
注意:
- 这里我们一直在强调的单线程,只是在处理我们的网络请求的时候只有一个线程来 处理,一个正式的Redis Server运行的时候肯定是不止一个线程的,例如Redis进行持久化的时候会以子进程或者子线程的方式执
- 我们知道Redis是用”单线程-多路复用IO模型”来实现高性能的内存数据服务的,这种 机制避免了使用锁,但是同时这种机制在进行sunion之类的比较耗时的命令时会使redis的 并发下降。因为是单一线程,所以同一时刻只有一个操作在进行,所以,耗时的命令会导致 并发的下降,不只是读并发,写并发也会下降。而单一线程也只能用到一个CPU核心,所以 可以在同一个多核的服务器中,可以启动多个实例,组成master-master或者master-slave 的形式,耗时的读命令可以完全在slave进行。
- “我们不能任由操作系统负载均衡,因为我们自己更了解自己的程序,所以,我们可以 手动地为其分配CPU核,而不会过多地占用CPU,或是让我们关键进程和一堆别的进程挤在 一起。CPU 是一个重要的影响因素,由于是单线程模型,Redis 更喜欢大缓存快速 CPU, 而不是 多核 在多核 CPU 服务器上面,Redis 的性能还依赖NUMA 配置和处理器绑定位置。最明显的影 响是 redis-benchmark 会随机使用CPU内核。为了获得精准的结果,需要使用固定处理器 工具(在 Linux 上可以使用 taskset)。最有效的办法是将客户端和服务端分离到两个不同 的 CPU 来高校使用三级缓存。
redis为什么快
Redis采用的是基于内存的采用的是单进程单线程模型的 KV 数据库, 由C语言编写,官方提供的数据是可以达到100000+的QPS(每秒内查询次数)。这个数据 不比采用单进程多线程的同样基于内存的 KV 数据库 Memcached 差!
- 完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于 HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
- 数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
- 采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致 的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出 现死锁而导致的性能消耗;
- 使用多路I/O复用模型,非阻塞IO;
- 多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在 空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤 醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只 依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
- 这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用 技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈, 主要由以上几点造就了 Redis 具有很高的吞吐量。
- 使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样, Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去 移动和请求;
多路 I/O 复用模型
多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在 空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤 醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只 依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。 这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用 技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈, 主要由以上几点造就了 Redis 具有很高的吞吐量。
数据结构
简单动态字符串
- Redis 使用动态字符串 SDS 来表示字符串值。
- SDS 的结构可以减少修改字符串时带来的内存重分配的次数,这依赖于内存预分配和惰性空间释放两大机制。
- 当 SDS 需要被修改,并且要对 SDS 进行空间扩展时,Redis 不仅会为 SDS 分配修改所必须要的空间,还会为 SDS 分配额外的未使用的空间。
- 如果修改后, SDS 的长度(也就是len属性的值)将小于 1MB ,那么 Redis 预分配和 len 属性相同大小的未使用空间。
- 如果修改后, SDS 的长度将大于 1MB ,那么 Redis 会分配 1MB 的未使用空间。
- 比如说,进行修改后 SDS 的 len 长度为20字节,小于 1MB,那么 Redis 会预先再分配 20 字节的空间, SDS 的 buf数组的实际长度(除去最后一字节)变为 20 + 20 = 40 字节。当 SDS的 len 长度大于 1MB时,则只会再多分配 1MB的空间。
- 类似的,当 SDS 缩短其保存的字符串长度时,并不会立即释放多出来的字节,而是等待之后使用。
链表
- 链表在 Redis 中的应用非常广泛,比如列表对象的底层实现之一就是链表。除了链表对象外,发布和订阅、慢查询、监视器等功能也用到了链表。
- Redis 的链表结构的dup 、 free 和 match 成员属性是用于实现多态链表所需的类型特定函数:
- dup 函数用于复制链表节点所保存的值,用于深度拷贝。
- free 函数用于释放链表节点所保存的值。
- match 函数则用于对比链表节点所保存的值和另一个输入值是否相等。
字典
- 字典被广泛用于实现 Redis 的各种功能,包括键空间和哈希对象
- Redis 使用 MurmurHash2 算法来计算键的哈希值,并且使用链地址法来解决键冲突,被分配到同一个索引的多个键值对会连接成一个单向链表。
跳跃表
Redis 使用跳跃表作为有序集合对象的底层实现之一。它以有序的方式在层次化的链表中保存元素, 效率和平衡树媲美 —— 查找、删除、添加等操作都可以在对数期望时间下完成, 并且比起平衡树来说, 跳跃表的实现要简单直观得多。
整数集合
整数集合 intset 是集合对象的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时, Redis 就会使用整数集合作为集合对象的底层实现。
压缩列表
- 压缩队列 ziplist 是列表对象和哈希对象的底层实现之一。当满足一定条件时,列表对象和哈希对象都会以压缩队列为底层实现。
- 压缩队列是 Redis 为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构。它的属性值有:
- zlbytes : 长度为 4 字节,记录整个压缩数组的内存字节数。
- zltail : 长度为 4 字节,记录压缩队列表尾节点距离压缩队列的起始地址有多少字节,通过该属性可以直接确定尾节点的地址。
- zllen : 长度为 2 字节,包含的节点数。当属性值小于 INT16_MAX时,该值就是节点总数,否则需要遍历整个队列才能确定总数。
- zlend : 长度为 1 字节,特殊值,用于标记压缩队列的末端。
- 中间每个节点 entry 由三部分组成:
- previousentrylength : 压缩列表中前一个节点的长度,和当前的地址进行指针运算,计算出前一个节点的起始地址。
- encoding: 节点保存数据的类型和长度
- content :节点值,可以为一个字节数组或者整数。
对象
字符串对象
- 如果一个字符串对象保存的是一个字符串值,并且长度大于32字节,那么该字符串对象将使用 SDS 进行保存,并将对象的编码设置为 raw。如果字符串的长度小于32字节,那么字符串对象将使用embstr 编码方式来保存。
- embstr 编码是专门用于保存短字符串的一种优化编码方式,这个编码的组成和 raw 编码一致,都使用 redisObject 结构和 sdshdr 结构来保存字符串。
- 但是 raw 编码会调用两次内存分配来分别创建上述两个结构,而embstr则通过一次内存分配来分配一块连续的空间,空间中一次包含两个结构。
- embstr 只需一次内存分配,而且在同一块连续的内存中,更好的利用缓存带来的优势,但是 embstr 是只读的,不能进行修改,当一个 embstr 编码的字符串对象进行 append 操作时, redis 会现将其转变为 raw 编码再进行操作。
列表对象
- 列表对象的编码可以是 ziplist 或 linkedlist。
- 当列表对象可以同时满足以下两个条件时,列表对象使用 ziplist 编码:
- 列表对象保存的所有字符串元素的长度都小于 64 字节。
- 列表对象保存的元素数量数量小于 512 个。
- 不能满足这两个条件的列表对象需要使用 linkedlist 编码或者转换为 linkedlist 编码。
哈希对象
- 哈希对象的编码可以使用 ziplist 或 dict
- 当哈希对象使用压缩队列作为底层实现时,程序将键值对紧挨着插入到压缩队列中,保存键的节点在前,保存值的节点在后。
- 当哈希对象可以同时满足以下两个条件时,哈希对象使用 ziplist 编码:
- 哈希对象保存的所有键值对的键和值的字符串长度都小于64字节。
- 哈希对象保存的键值对数量小于512个。
- 不能满足这两个条件的哈希对象需要使用 dict 编码或者转换为 dict 编码。
集合对象
- 集合对象的编码可以使用 intset 或者 dict。
- intset 编码的集合对象使用整数集合最为底层实现,所有元素都被保存在整数集合里边。
- 而使用 dict 进行编码时,字典的每一个键都是一个字符串对象,每个字符串对象就是一个集合元素,而字典的值全部都被设置为NULL。
- 当集合对象可以同时满足以下两个条件时,对象使用 intset 编码:
- 集合对象保存的所有元素都是整数值。
- 集合对象保存的元素数量不超过512个。
- 否则使用 dict 进行编码。
有序集合对象
- 有序集合的编码可以为 ziplist 或者 skiplist。
- 有序集合使用 ziplist 编码时,每个集合元素使用两个紧挨在一起的压缩列表节点表示,前一个节点是元素的值,第二个节点是元素的分值,也就是排序比较的数值。
- 压缩列表内的集合元素按照分值从小到大进行排序
- 有序集合使用 skiplist 编码时使用 zset 结构作为底层实现,一个 zet 结构同时包含一个字典和一个跳跃表。
- 其中,跳跃表按照分值从小到大保存所有元素,每个跳跃表节点保存一个元素,其score值是元素的分值。而字典则创建一个一个从成员到分值的映射,字典的键是集合成员的值,字典的值是集合成员的分值。通过字典可以在O(1)复杂度查找给定成员的分值。
- 跳跃表和字典中的集合元素值对象都是共享的,所以不会额外消耗内存。
- 当有序集合对象可以同时满足以下两个条件时,对象使用 ziplist 编码:
- 有序集合保存的元素数量少于128个;
- 有序集合保存的所有元素的长度都小于64字节。
- 否则使用 skiplist 编码。
数据库键空间
- Redis 服务器都有多个 Redis 数据库,每个Redis 数据都有自己独立的键值空间。每个 Redis 数据库使用 dict 保存数据库中所有的键值对。
- 键空间的键也就是数据库的键,每个键都是一个字符串对象,而值对象可能为字符串对象、列表对象、哈希表对象、集合对象和有序集合对象中的一种对象。
- 除了键空间,Redis 也使用 dict 结构来保存键的过期时间,其键是键空间中的键值,而值是过期时间。
- 通过过期字典,Redis 可以直接判断一个键是否过期,首先查看该键是否存在于过期字典,如果存在,则比较该键的过期时间和当前服务器时间戳,如果大于,则该键过期,否则未过期。
五种数据类型
string
这个其实没啥好说的,常规的set/get操作,value可以是String也可以是数 字。一般做一些复杂的计数功能的缓存。
hash
这里value存放的是结构化的对象,比较方便的就是操作其中的某个字段。博主 在做单点登录的时候,就是用这种数据结构存储用户信息,以cookieId作为 key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。
list
使用List的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以 利用lrange命令,做基于redis的分页功能,性能极佳,用户体验好。本人还用 一个场景,很合适—取行情信息。就也是个生产者和消费者的场景。LIST可以 很好的完成排队,先进先出的原则。
set
因为set堆放的是一堆不重复值的集合。所以可以做全局去重的功能。另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自 己独有的喜好等功能。
sorted set
sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以 做排行榜应用,取TOP N操作。
redis事务
众多其它数据库一样,Redis作为NoSQL数据库也同样提供了事务机制。在Redis中,MULTI/EXEC/DISCARD/WATCH这四个命令是我们实现事务的基石。相信对有关系型数据库开发经验的开发者而言
Redis中事务的实现特征:
1). 在事务中的所有命令都将会被串行化的顺序执行,事务执行期间,Redis不会再为其它客户端的请求提供任何服务,从而保证了事物中的所有命令被原子的执行。
2). 和关系型数据库中的事务相比,在Redis事务中如果有某一条命令执行失败,其后的命令仍然会被继续执行。
3). 我们可以通过MULTI命令开启一个事务,有关系型数据库开发经验的人可以将其理解为”BEGIN TRANSACTION”语句。在该语句之后执行的命令都将被视为事务之内的操作,最后我们可以通过执行EXEC/DISCARD命令来提交/回滚该事务内的所有操作。这两个Redis命令可被视为等同于关系型数据库中的COMMIT/ROLLBACK语句。
4). 在事务开启之前,如果客户端与服务器之间出现通讯故障并导致网络断开,其后所有待执行的语句都将不会被服务器执行。然而如果网络中断事件是发生在客户端执行EXEC命令之后,那么该事务中的所有命令都会被服务器执行。
5). 当使用Append-Only模式时,Redis会通过调用系统函数write将该事务内的所有写操作在本次调用中全部写入磁盘。然而如果在写入的过程中出现系统崩溃,如电源故障导致的宕机,那么此时也许只有部分数据被写入到磁盘,而另外一部分数据却已经丢失。
Redis服务器会在重新启动时执行一系列必要的一致性检测,一旦发现类似问题,就会立即退出并给出相应的错误提示。此时,我们就要充分利用Redis工具包中提供的redis-check-aof工具,该工具可以帮助我们定位到数据不一致的错误,并将已经写入的部分数据进行回滚。修复之后我们就可以再次重新启动Redis服务器了。
redis主从
通过配置两台(或多台)数据库的主从关系,可以将一台数据库服务器的数据更新同步到另一台服务器上。redis 支持 master-slave(主从)模式,redisserver 可以设置为另一个 redis server 的主机(从机),从机定期从主机拿数据。特殊的,一个从机同样可以设置为一个 redis server 的主机,master以写为主,slaver以读为主。
流程
* 准备好设置主从的redis服务器
* 修改配置文件
* 修改redis-master的配置文件 redis.windows.confport 6379 bind 127.0.0.1 2.2
* 修改redis-slave1 和redis-slave2的配置文件
* redis-slave1的配置文件 port 6380 bind 127.0.0.1 slaveof 127.0.0.1 6379
* redis-slave2的配置文件 port 6381 bind 127.0.0.1 slaveof 127.0.0.1 6379
* 检查
redis 哨兵
有了主从复制的实现以后,如果我们想对主从服务器进行监控,那么在redis2.6以后提供了一个”哨兵”的机制。在2.6版本中的哨兵为1.0版本,并不稳定,会出现各种各样的问题,在2.8版本以后的哨兵功能才稳定起来。顾名思义,哨兵的含义就是监控Redis系统的运行状态。可以启动多个哨兵,去监控Redis数据库的运行状态。
其主要功能有两点
- 监控主数据库和从数据库是否正常运行。
- 主数据库出现故障时,可以自动将从数据库转换为主数据库,实现自动切换。
配置
1. port :当前Sentinel服务运行的端口 2.sentinel monitor mymaster 127.0.0.1 6379 2:Sentinel去监视一个名为mymaster的 主redis实例,这个主实例的IP地址为本机地址127.0.0.1,端口号为6379,而将这个主实例 判断为失效至少需要2个 Sentinel进程的同意,只要同意Sentinel的数量不达标,自动 failover就不会执行 3.sentinel down-after-milliseconds mymaster 5000:指定了Sentinel认为Redis实例已 经失效所需的毫秒数。当 实例超过该时间没有返回PING,或者直接返回错误,那么 Sentinel将这个实例标记为主观下线。只有一个 Sentinel进程将实例标记为主观下线并不一 定会引起实例的自动故障迁移:只有在足够数量的Sentinel都将一个实例标记为主观下线之 后,实例才会被标记为客观下线,这时自动故障迁移才会执行 4.sentinel parallel-syncs mymaster 1:指定了在执行故障转移时,最多可以有多少个 从Redis实例在同步新的主实例,在从Redis实例较多的情况下这个数字越小,同步的时间 越长,完成故障转移所需的时间就越长 5.sentinel failover-timeout mymaster 15000:如果在该时间(ms)内未能完成 failover操作,则认为该failover失败
作用
1.当启动哨兵模式之后,如果你的master服务器宕机之后,哨兵自动会在从redis服务器里面 投票选举一个master主服务器出来;这个主服务器也可以进行读写操作!
2.如果之前宕机的主服务器已经修好,可以正式运行了。那么这个服务器只能进行读的操作,会自动跟随由哨兵选举出来的新服务器!
特点
- master可以有多台slave
- 除了多个slave连到相同master外,slave也可以连接到其它slave形成图状结构
- 主从复制不会阻塞master,也就是说当一个或多个slave与master连接进行复制时,master可以继续处理客户端发来的请求
- 主从复制可以用来提高系统的伸缩性,我们可以用多个slave专门负责客户端的读请求,可以做数据冗余
redis持久化
redis持久化的几种方式
1、快照(snapshots)
缺省情况情况下,Redis把数据快照存放在磁盘上的二进制文件中,文件名为dump.rdb。你可以配置Redis的持久化策略,例如数据集中每N秒钟有超过M次更新,就将数据写入磁盘;或者你可以手工调用命令SAVE或BGSAVE。
工作原理
- Redis forks.
- 子进程开始将数据写到临时RDB文件中。
- 当子进程完成写RDB文件,用新文件替换老文件。
- 这种方式可以使Redis使用copy-on-write技术。
2、AOF
- 快照模式并不十分健壮,当系统停止,或者无意中Redis被kill掉,最后写入Redis的数据就会丢失。这对某些应用也许不是大问题,但对于要求高可靠性的应用来说,
- Redis就不是一个合适的选择。
- Append-only文件模式是另一种选择。
- 你可以在配置文件中打开AOF模式
3、虚拟内存方式
- 当你的key很小而value很大时,使用VM的效果会比较好.因为这样节约的内存比较大.
- 当你的key不小时,可以考虑使用一些非常方法将很大的key变成很大的value,比如你可以考虑将key,value组合成一个新的value.
- vm-max-threads这个参数,可以设置访问swap文件的线程数,设置最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的.可能会造成比较长时间的延迟,但是对数据完整性有很好的保证.
RDB机制
RDB机制的优势和劣势
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。 也是默认的持久化方式,这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。可以通过配置设置自动做快照持久化的方式
RDB文件保存过程
- redis调用fork,现在有了子进程和父进程。
- 父进程继续处理client请求,子进程负责将内存内容写入到临时文件。由于os的写时复制机制(copy on write)父子进程会共享相同的物理页面,当父进程处理写请求时os会为父进程要修改的页面创建副本,而不是写共享的页面。所以子进程的地址空间内的数 据是fork时刻整个数据库的一个快照。
- 当子进程将快照写入临时文件完毕后,用临时文件替换原来的快照文件,然后子进程退出。
- client 也可以使用save或者bgsave命令通知redis做一次快照持久化。save操作是在主线程中保存快照的,由于redis是用一个主线程来处理所有 client的请求,这种方式会阻塞所有client请求。所以不推荐使用。
- 另一点需要注意的是,每次快照持久化都是将内存数据完整写入到磁盘一次,并不 是增量的只同步脏数据。如果数据量大的话,而且写操作比较多,必然会引起大量的磁盘io操作,可能会严重影响性能。
优势
- 一旦采用该方式,那么你的整个Redis数据库将只包含一个文件,这样非常方便进行备份。比如你可能打算没1天归档一些数据。
- 方便备份,我们可以很容易的将一个一个RDB文件移动到其他的存储介质
- RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
- RDB 可以最大化 Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。
劣势
- 如果你需要尽量避免在服务器故障时丢失数据,那么 RDB 不适合你。 虽然 Redis 允许你设置不同的保存点(save point)来控制保存 RDB 文件的频率, 但是, 因为RDB 文件需要保存整个数据集的状态, 所以它并不是一个轻松的操作。 因此你可能会至少 5 分钟才保存一次 RDB 文件。 在这种情况下, 一旦发生故障停机, 你就可能会丢失好几分钟的数据。
- 每次保存 RDB 的时候,Redis 都要 fork() 出一个子进程,并由子进程来进行实际的持久化工作。 在数据集比较庞大时, fork() 可能会非常耗时,造成服务器在某某毫秒内停止处理客户端; 如果数据集非常巨大,并且 CPU 时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒。 虽然 AOF 重写也需要进行 fork() ,但无论 AOF 重写的执行间隔有多长,数据的耐久性都不会有任何损失。
AOF机制
redis会将每一个收到的写命令都通过write函数追加到文件中(默认是 appendonly.aof)。
当redis重启时会通过重新执行文件中保存的写命令来在内存中重建整个数据库的内容。当然由于os会在内核中缓存 write做的修改,所以可能不是立即写到磁盘上。这样aof方式的持久化也还是有可能会丢失部分修改。不过我们可以通过配置文件告诉redis我们想要 通过fsync函数强制os写入到磁盘的时机。
aof 的方式也同时带来了另一个问题。持久化文件会变的越来越大。例如我们调用incr test命令100次,文件中必须保存全部的100条命令,其实有99条都是多余的。因为要恢复数据库的状态其实文件中保存一条set test 100就够了。
为了压缩aof的持久化文件。redis提供了bgrewriteaof命令。收到此命令redis将使用与快照类似的方式将内存中的数据 以命令的方式保存到临时文件中,最后替换原来的文件。具体过程如下
- redis调用fork ,现在有父子两个进程
- 子进程根据内存中的数据库快照,往临时文件中写入重建数据库状态的命令
- 父进程继续处理client请求,除了把写命令写入到原来的aof文件中。同时把收到的写命令缓存起来。这样就能保证如果子进程重写失败的话并不会出问题。
- 当子进程把快照内容写入已命令方式写到临时文件中后,子进程发信号通知父进程。然后父进程把缓存的写命令也写入到临时文件。
- 现在父进程可以使用临时文件替换老的aof文件,并重命名,后面收到的写命令也开始往新的aof文件中追加。
需要注意到是重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
优势
- 使用 AOF 持久化会让 Redis 变得非常耐久(much more durable):你可以设置不同的 fsync 策略,比如无 fsync ,每秒钟一次 fsync ,或者每次执行写入命令时 fsync 。 AOF 的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync 会在后台线程执行,所以主线程可以继续努力地处理命令请求)。
- AOF 文件是一个只进行追加操作的日志文件(append only log), 因此对 AOF 文件的写入不需要进行 seek , 即使日志因为某些原因而包含了未写入完整的命令(比如写入时磁盘已满,写入中途停机,等等), redis-check-aof 工具也可以轻易地修复这种问题。
- Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。
- AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
劣势
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
- 根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。
- AOF 在过去曾经发生过这样的 bug : 因为个别命令的原因,导致 AOF 文件在重新载入时,无法将数据集恢复成保存时的原样。 (举个例子,阻塞命令 BRPOPLPUSH 就曾经引起过这样的 bug 。) 测试套件里为这种情况添加了测试: 它们会自动生成随机的、复杂的数据集, 并通过重新载入这些数据来确保一切正常。 虽然这种 bug 在 AOF 文件中并不常见, 但是对比来说, RDB 几乎是不可能出现这种 bug 的。
对比
一般来说, 如果想达到足以媲美 PostgreSQL 的数据安全性, 你应该同时使用两种持久化功能。如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化。其余情况我个人喜好选择AOF
Sentinel
Sentinel的作用:
* Master 状态监测 * 如果Master 异常,则会进行Master-slave 转换,将其中一个Slave作为Master,将之前的Master作为Slave * Master-Slave切换后,master_redis.conf、slave_redis.conf和sentinel.conf的内容都会发生改变,即master_redis.conf中会多一行slaveof的配置,sentinel.conf的监控目标会随之调换
2、Sentinel的工作方式:
1):每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个 PING 命令。
2):如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel 标记为主观下线。 3):如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
4):当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线 。
5):在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有Master,Slave发送 INFO 命令 。
6):当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次 。
7):若没有足够数量的 Sentinel 同意 Master 已经下线, Master 的客观下线状态就会被移除。
若 Master 重新向 Sentinel 的 PING 命令返回有效回复, Master 的主观下线状态就会被移除。
Redis集群方案
集群过程
1:当一个从数据库启动时,会向主数据库发送sync命令,
2:主数据库接收到sync命令后会开始在后台保存快照(执行rdb操作),并将保存期间接收到的命令缓存起来
3:当快照完成后,redis会将快照文件和所有缓存的命令发送给从数据库。
4:从数据库收到后,会载入快照文件并执行收到的缓存的命令
集群方案应该怎么做?都有哪些方案?
Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接
1、所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
2、节点的fail是通过集群中超过半数的节点检测失效时才生效。
3、客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
4、redis-cluster把所有的物理节点映射到[0-16383]slot上(不一定是平均分配),cluster 负责维护node<->slot<->value。
5、Redis集群预分好16384个桶,当需要在 Redis 集群中放置一个 key-value 时,根据 CRC16(key) mod 16384的值,决定将一个key放到哪个桶中。
Redis集群方案什么情况下会导致整个集群不可用?
有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用
Redis集群最大节点个数是多少?
一个redis集群的搭建,最少需要6个节点,构成3组服务节点;每组服务节点包括两个节点(Master-Slave)
redis的过期策略以及内存淘汰机制
假如你redis只能存5G数据,可是你写了10G,那会删5G的数据。怎么删的,这 个问题思考过么?还有,你的数据已经设置了过期时间,但是时间到了,内存占 用率还是比较高,有思考过原因么?
redis采用的是定期删除+惰性删除策略。
为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放, 但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不 是删除key,因此没有采用这一策略.
定期删除+惰性删除是如何工作的呢?
- 定期删除,redis默认每个100ms检查,是否有过期的key,有过期key则删除。需 要说明的是,redis不是每个100ms将所有的key检查一次,而是随机抽取进行 检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用 定期删除策略,会导致很多key到时间没有删除。
- 于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一 下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。
采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性 删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机 制。
在redis.conf中有一行配置# maxmemory-policy volatile-lru该配置就是配内存淘汰策略的
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除近少 使用的key。推荐使用,目前项目在用这种。
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除 某个key。
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间 中,移除近少使用的key。这种情况一般是把redis既当缓存,又做持久化存 储的时候才用。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的 键空间中,随机移除某个key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间 中,有更早过期时间的key优先移除。
如果没有设置 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatile-random 和 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。
redis和数据库双写一致性问题
一致性问题是分布式常见问题,还可以再分为终一致性和强一致性。数 据库和缓存双写,就必然会存在不一致的问题。答这个问题,先明白一个前提。 就是如果对数据有强一致性要求,不能放缓存。我们所做的一切,只能保证终 一致性。另外,我们所做的方案其实从根本上来说,只能说降低不一致发生的概 率,无法完全避免。因此,有强一致性要求的数据,不能放缓存。
首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除 缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
并发竞争key问题
同时有多个子系统去set一个key。因为我们的生产环 境,基本都是redis集群环境,做了数据分片操作。你一个事务中有涉及到多个 key操作的时候,这多个key不一定都存储在同一个redis-server上。所以, redis的事务机制,并不好。
(1)如果对这个key操作,不要求顺序,这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可,比较 简单。
(2)如果对这个key操作,要求顺序,假设有一个key1,系统A需要将key1设置为valueA,系统B需要将key1设置为 valueB,系统C需要将key1设置为valueC.。期望按照key1的value值按照 valueA–>valueB–>valueC的顺序变化。这种时 候我们在数据写入数据库的时候,需要保存一个时间戳。假设时间戳如下
- 系统A key 1 {valueA 3:00}
- 系统B key 1 {valueB 3:05}
- 系统C key 1 {valueC 3:10}
那么,假设这会系统B先抢到锁,将key1设置为{valueB 3:05}。接下来系统A抢 到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做set操作了。
其他方法,比如利用队列,将set方法变成串行访问也可以。
Redis内存满了的几种解决方法
1,增加内存;
2,使用内存淘汰策略。
3,Redis集群。
缓存穿透,雪崩,预热,更新,降级
缓存雪崩
由于原有缓存失效,新缓存未到期间(例如:我们设置缓 存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期),所有原本应该访问缓存 的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕 机。从而形成一系列连锁反应,造成整个系统崩溃。
缓存失效时的雪崩效应对底层系统的冲击非常可怕!大多数系统设计者考虑用加锁或者队列 的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发 请求落到底层存储系统上。还有一个简单方案就时讲缓存失效时间分散开,比如我们可以在 原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的 重复率就会降低,就很难引发集体失效的事件。
加锁排队
加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。假设在高并发下,缓存重建 期间key是锁着的,这是过来1000个请求999个都在阻塞的。同样会导致用户等待超时,这 是个治标不治本的方法!
注意:加锁排队的解决方式分布式环境的并发问题,有可能还要解决分布式锁的问题;线程 还会被阻塞,用户体验很差!因此,在真正的高并发场景下很少使用!
缓存标记
缓存标记记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去更新实际 key的缓存,给每一个缓存数据增加相应的缓存标记,记录缓存的 是否失效,如果缓存标记失效,则更新数据缓存
缓存标记:记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去更新实际 key的缓存;
缓存数据:它的过期时间比缓存标记的时间延长1倍,例:标记缓存时间30分钟,数据 缓存设置为60分钟。 这样,当缓存标记key过期后,实际缓存还能把旧数据返回给调用 端,直到另外的线程在后台更新完成后,才会返回新缓存。
做二级缓存
做二级缓存,或者双缓存策略: A1 为原始缓存,A2 为拷贝缓存,A1 失效时,可以访问 A2,A1 缓存失效时间设置为短期,A2 设置为长期
缓存穿透
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询 的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次 无用的查询)。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
布隆过滤器
将所有可能存 在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉, 从而避免了对底层存储系统的查询压力。
对空结果缓存
另外也有一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还 是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分 钟。通过这个直接设置的默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继 续访问数据库,这种办法最简单粗暴!把空结果,也给缓存起来,这样下次同样的请求就可以直接返回空了,即可以避免当查询的 值为空时引起的缓存穿透。同时也可以单独设置个缓存区域存储空值,对要查询的key进行 预先校验,然后再放行给后面的正常缓存处理逻辑。
缓存预热
缓存 预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求 的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
解决思路:
1、直接写个缓存刷新页面,上线时手工操作下;
2、数据量不大,可以在项目启动的时候自动进行加载;
3、定时刷新缓存;
缓存更新
除了缓存服务器自带的缓存失效策略之外(Redis默认的有6中策略可供选择),我们还可 以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:
- 定时去清理过期的缓存;
- 当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系 统得到新数据并更新缓存。
两者各有优劣,第一种的缺点是维护大量缓存的key是比较麻烦的,第二种的缺点就是每次 用户请求过来都要判断缓存失效,逻辑相对比较复杂!根据应用场景来权衡。
缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性 能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自 动降级,也可以配置开关实现人工降级。
目的
降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入 购物车、结算)。在进行降级之前要对系统进行梳理,看看系统是不是可以丢卒保帅;从而梳理出哪些必须誓 死保护,哪些可降级;比如可以参考日志级别设置预案:
(1)一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
(2)警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级 或人工降级,并发送告警;
(3)错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系 统能承受的最大阀值,此时可以根据情况自动降级或者人工降级;
(4)严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
过期键删除策略
- 如果一个键过期了,那么他什么时候会被删除
- 定时删除:在设置键的过期时间的同时,创建一个定时器,让定时器在键的过期时间来 临时,立即执行对键的删除操作。
- 惰性删除:放任键过期不管,但是每次从键空间获取键时,都检测获取得的键是否过 期,如果过期的话,就删除该键,如果没有过期,就返回该键。
- 定期删除:每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键。
- 至于要 删除多少过期键,以及要检查多少数据库,由程序算法决定。 这三种策略中,第一种和第三种为主动删除策略,而第二种则为被动删除策略。
Redis的过期键删除策略
Redis服务器实际使用的是惰 性删除和定期删除两种策略,通过配合使用者两种策略,服务器可以很好的合理的使用CPU 和避免浪费内存空间之间取得平衡。
惰性删除策略的实现
- 过期键的惰性删除策略由db.c/expireIfNeeded函数实现,所有的读写数据库的Redis命 令在执行之前都会调用expireIfNeeded函数对输入键进行检查:
- 如果输入键已经过期,那么expireIfNeeded函数将做输入键从数据库中删除。
- 如果键未过期,那么expiredNeeded函数不做任何操作。
AOF,RDB和复制功能对过期键的处理
生成RDB文件
- 在执行Save命令或者bgsave命令创建一个新的RDB文件时,程序会对数据库中的键进行检 查,已过期的键不会被保存到新创建的RDB文件中。
- 例如:如果数据库中包含三个键,k1,k2,k3.并且k2已经过期,那么当执行Save命令或者 bgsave命令时,程序只将k1,k3的数据保存到RDB文件中,而K2则会被忽略。
- 因此,数据库中包含过期键不会对生成新的RDB文件造成影响。
载入RDB文件
- 在启动Redis服务器时,如果服务器开启了RDB功能,那么服务器对RDB文件进行载入 如果服务器以主服务器模式运行,那么载入RDB文件时,程序会对文件中保存的键进行检 查,未过期的键会被载入到数据库中,而过期键则会被忽略,所以过期键对载入RDB文件的 主服务器不会造成影响。
- 如果服务器以从服务器模式运行,那么在载入RDB文件时,文件中保存的所有键,不乱是否 过期,都会被载入到数据库中,不过因为主从服务器在同步数据的时候,从服务器的数据库 就会被清空。所以一般来讲,过期键对载入RDB文件的从服务器也不会造成影响。
AOF文件写入
- 当服务器以AOF持久化模式运行时,如果数据库中的某个键已经过期,但它还没有被惰性删 除或者定期删除,那么AOF文件不会因为这个过期键而产生任何影响。
- 当过期键被惰性删除或者定期删除之后,程序会向AOF文件追加一条DEL命令,来显式地记 录该键已被删除。
- 和生成RDB文件类似,在执行AOF重写的过程中,程序会对数据库中的键进行检查,已过 期的键不会被保存到重写的AOF文件中。
git
git和svn
- 核心区别:
- SVN 是集中式版本控制系统,版本库是集中放在中央服务器的,而干活的时候,用的都是自己的电脑,所以首先要从中央服务器哪里得到最新的版本,然后干活,干完后,需要把自己做完的活推送到中央服务器。集中式版本控制系统是必须联网才能工作,如果在局域网还可以,带宽够大,速度够快,如果在互联网下,如果网速慢的话,就纳闷了。
- Git 是分布式版本控制系统,那么它就没有中央服务器的,每个人的电脑就是一个完整的版本库,这样,工作的时候就不需要联网了,因为版本都是在自己的电脑上。既然每个人的电脑都有一个完整的版本库,那多个人如何协作呢?比如说自己在电脑上改了文件 A,其他人也在电脑上改了文件 A,这时,你们两之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
- Git把内容按元数据方式存储,而SVN是按文件:因为,.git目录是处于你的机器上的一个克隆版的版本库,它拥有中心版本库上所有的东西,例如标签,分支,版本记录等。.git目录的体积大小跟.svn比较,你会发现它们差距很大。
- Git没有一个全局版本号,而SVN有:目前为止这是跟SVN相比Git缺少的最大的一个特征。
- Git的内容的完整性要优于SVN: GIT的内容存储使用的是SHA-1哈希算法。这能确保代码内容的完整性,确保在遇到磁盘故障和网络问题时降低对版本库的破坏。
- Git下载下来后,在OffLine状态下可以看到所有的Log,SVN不可以。
- 刚开始用时,SVN必须先Update才能Commit,忘记了合并时就会出现一些错误,git还是比较少的出现这种情况。
- 克隆一份全新的目录以同样拥有五个分支来说,SVN是同时复製5个版本的文件,也就是说重复五次同样的动作。而Git只是获取文件的每个版本的 元素,然后只载入主要的分支(master)在我的经验,克隆一个拥有将近一万个提交(commit),五个分支,每个分支有大约1500个文件的 SVN,耗了将近一个小时!而Git只用了区区的1分钟!
- 版本库(repository):SVN只能有一个指定中央版本库。当这个中央版本库有问题时,所有工作成员都一起瘫痪直到版本库维修完毕或者新的版本库设立完成。而 Git可以有无限个版本库。或者,更正确的说法,每一个Git都是一个版本库,区别是它们是否拥有活跃目录(Git Working Tree)。如果主要版本库(例如:置於GitHub的版本库)发生了什麼事,工作成员仍然可以在自己的本地版本库(local repository)提交,等待主要版本库恢复即可。工作成员也可以提交到其他的版本库
- 分支(Branch)在SVN,分支是一个完整的目录。且这个目录拥有完整的实际文件。如果工作成员想要开啟新的分支,那将会影响“全世界”!每个人都会拥有和你一样的分支。如果你的分支是用来进行破坏工作(安检测试),那将会像传染病一样,你改一个分支,还得让其他人重新切分支重新下载,十分狗血。而 Git,每个工作成员可以任意在自己的本地版本库开啟无限个分支。举例:当我想尝试破坏自己的程序(安检测试),并且想保留这些被修改的文件供日后使用, 我可以开一个分支,做我喜欢的事。完全不需担心妨碍其他工作成员。只要我不合并及提交到主要版本库,没有一个工作成员会被影响。等到我不需要这个分支时, 我只要把它从我的本地版本库删除即可。
- 提交(Commit)在SVN,当你提交你的完成品时,它将直接记录到中央版本库。当你发现你的完成品存在严重问题时,你已经无法阻止事情的发生了。如果网路中断,你根本没办法提交!而Git的提交完全属於本地版本库的活动。而你只需“推”(git push)到主要版本库即可。Git的“推”其实是在执行“同步”(Sync)
git乘用命令
新建代码库
- $ git init 在当前目录新建一个Git代码库
- $ git init [project-name] 新建一个目录,将其初始化为Git代码库
- $ git clone [url] 下载一个项目和它的整个代码历史
配置
- 显示当前的Git配置 $ git config –list
- 编辑Git配置文件 $ git config -e [–global]
- 设置提交代码时的用户信息
- $ git config [–global] user.name “[name]”
- $ git config [–global] user.email “[email address]”
增加/删除文件
- 添加指定文件到暂存区 $ git add [file1] [file2] …
- 添加指定目录到暂存区,包括子目录 $ git add [dir]
- 添加当前目录的所有文件到暂存区 $ git add .
- 添加每个变化前,都会要求确认
- 对于同一个文件的多处变化,可以实现分次提交 $ git add-p
- 删除工作区文件,并且将这次删除放入暂存区 $ git rm [file1] [file2] …
- 停止追踪指定文件,但该文件会保留在工作区 $ git rm –cached [file]
- 改名文件,并且将这个改名放入暂存区 $ git mv [file-original] [file-renamed]
代码提交
- 提交暂存区到仓库区 $ git commit -m [message]
- 提交暂存区的指定文件到仓库区 $ git commit [file1] [file2] … -m [message]
- 提交工作区自上次commit之后的变化,直接到仓库区 $ git commit -a
- 提交时显示所有diff信息 $ git commit -v
- 使用一次新的commit,替代上一次提交
- 如果代码没有任何新变化,则用来改写上一次commit的提交信息 $ git commit –amend -m [message]
- 重做上一次commit,并包括指定文件的新变化 $ git commit –amend [file1] [file2] …
分支
- 列出所有本地分支 $ git branch
- 列出所有远程分支 $ git branch -r
- 列出所有本地分支和远程分支 $ git branch -a
- 新建一个分支,但依然停留在当前分支 $ git branch [branch-name]
- 新建一个分支,并切换到该分支 $ git checkout-b [branch]
- 新建一个分支,指向指定commit $ git branch [branch] [commit]
- 新建一个分支,与指定的远程分支建立追踪关系 $ git branch –track [branch] [remote-branch]
- 切换到指定分支,并更新工作区 $ git checkout[branch-name]
- 切换到上一个分支 $ git checkout -
- 建立追踪关系,在现有分支与指定的远程分支之间 $ git branch–set-upstream [branch] [remote-branch]
- 合并指定分支到当前分支 $ git merge[branch]
- 选择一个commit,合并进当前分支 $ git cherry-pick [commit]
- 删除分支 $ git branch -d [branch-name]
- 删除远程分支
- $ git push origin –delete [branch-name]
- $ git branch -dr [remote/branch]
标签
- 列出所有tag $ git tag
- 新建一个tag在当前commit $ git tag [tag]
- 新建一个tag在指定commit $ git tag [tag] [commit]
- 删除本地tag $ git tag -d [tag]
- 删除远程tag $ git push origin :refs/tags/[tagName]
- 查看tag信息 $ git show [tag]
- 提交指定tag $ git push [remote] [tag]
- 提交所有tag $ git push [remote] –tags
- 新建一个分支,指向某个tag $ git checkout -b [branch] [tag]
查看信息
- 显示有变更的文件 $ git status
- 显示当前分支的版本历史 $ git log
- 显示commit历史,以及每次commit发生变更的件$ git log –stat
- 搜索提交历史,根据关键词 $ git log-S [keyword]
- 显示某个commit之后的所有变动,每个commi占据一行 $ git log[tag] HEAD –pretty=format:%s
- 显示某个commit之后的所有变动,其”提交说明”必须符合搜索条件 $ git log[tag] HEAD –grep feature
- 显示某个文件的版本历史,包括文件改名
- $ git log–follow [file]
- $ git whatchanged [file]
- 显示指定文件相关的每一次diff $ git log -p [file]
- 显示过去5次提交 $ git log-5 –pretty –oneline
- 显示所有提交过的用户,按提交次数排序 $ git shortlog-sn
- 显示指定文件是什么人在什么时间修改过 $ git blame[file]
- 显示暂存区和工作区的差异 $ git diff
- 显示暂存区和上一个commit的差异 $ git diff–cached [file]
- 显示工作区与当前分支最新commit之间的差异 $ git diff HEAD
- 显示两次提交之间的差异 $ git diff[first-branch]…[second-branch]
- 显示今天你写了多少行代码 $ git diff–shortstat “@{0 day ago}”
- 显示某次提交的元数据和内容变化 $ git show[commit]
- 显示某次提交发生变化的文件 $ git show–name-only [commit]
- 显示某次提交时,某个文件的内容 $ git show[commit]:[filename]
- 显示当前分支的最近几次提交 $ git reflog
远程同步
- 下载远程仓库的所有变动 $ git fetch[remote]
- 显示所有远程仓库 $ git remote-v
- 显示某个远程仓库的信息 $ git remote show[remote]
- 增加一个新的远程仓库,并命名 $ git remote add[shortname] [url]
- 取回远程仓库的变化,并与本地分支合并 $ git pull[remote] [branch]
- 上传本地指定分支到远程仓库 $ git push [remote] [branch]
- 强行推送当前分支到远程仓库,即使有冲突 $ git push[remote] –force
- 推送所有分支到远程仓库 $ git push[remote] –all
撤销
- 恢复暂存区的指定文件到工作区 $ git checkout[file]
- 恢复某个commit的指定文件到暂存区和工作区 $ git checkout[commit] [file]
- 恢复暂存区的所有文件到工作区 $ git checkout .
- 重置暂存区的指定文件,与上一次commit保持一致,但工作区不变 $ git reset [file]
- 重置暂存区与工作区,与上一次commit保持一致 $ git reset –hard
- 重置当前分支的指针为指定commit,同时重置暂存区,但工作区不变 $ git reset[commit]
- 重置当前分支的HEAD为指定commit,同时重置暂存区和工作区,与指定commit一致 $ git reset –hard [commit]
- 重置当前HEAD为指定commit,但保持暂存区和工作区不变 $ git reset –keep [commit]
- 新建一个commit,用来撤销指定commit
- 后者的所有变化都将被前者抵消,并且应用到当前分支 $ git revert[commit]
- 暂时将未提交的变化移除,稍后再移入 $ git stash $ git stash pop
常见的攻击
xss
Xss 跨站脚本攻击,例如攻击者向form表单输入了恶意的html代码,当用户访问列表页面时,这段html代码会自动执行,达到攻击效果,我们也遇到过一次,他在form中input输入了js代码,创建了html节点,创建了一个超链接标签,使网页跳转到恶意的菠菜网站. 防止:使用正则过滤,使用htmlentites函数实现html标签的实体化
sql注入
Sql注入没有过滤传入的参数,篡改sql语句,达到攻击效果,比如账号输入完成后使用单引号加井号完成了免密码登录,通过#吧#后面的数据过滤 防止 通过pdo防止首先将 sql 语句模板发送给Mysql Server,随后将绑定的字符变量再发送给Mysql server,这里的转义是在Mysql Server做的,它是根据你在连接PDO的时候,在charset里指定的编码格式来转换的。
csrf
Csrf跨站请求攻击, 全称是“跨站请求伪造”,而 XSS 的全称是“跨站脚本”。看起来有点相似,它们都是属于跨站攻击——不攻击服务器端而攻击正常访问网站的用户 防止:通过存储在cookie中token来防止;
Mysql
B树、B+树、B* 树
链接: blog.csdn.net/v_JULY_v/article/det...
平衡查找树之B树
链接: www.cnblogs.com/yangecnu/p/Introdu...
异步复制,半同步复制和并行复制
复制对于mysql的重要性不言而喻,mysql集群的负载均衡,读写分离和高可用都是基于复制实现。
异步复制
- 异步复制是mysql自带的最原始的复制方式,主库和备库成功建立起复制关系后,在备库上会有一个IO线程去主库拉取binlog,并将binlog写到本地,就是下图中的Relay log,然后备库会开启另外一个SQL线程去读取回放Relay log,通过这种方式达到Master-Slave数据同步的目的。
- 通常情况下,Slave是只读的,可以承担一部分读流量,而且可以根据实际需要,添加一个或多个Slave,这样在一定程度上可以缓解主库的读压力;
- 另一方面,若Master出现异常(crash,硬件故障等),无法对外提供服务,此时Slave可以承担起Master的重任,避免了单点的产生,所以复制就是为容灾和提高性能而生。
半同步复制
概念
- 一般情况下,异步复制就已经足够应付了,但由于是异步复制,备库极有可能是落后于主库,特别是极端情况下,我们无法保证主备数据是严格一致的(即使我们观察到Seconds Behind Master 这个值为0)。
- 比如,当用户发起commit命令时,Master并不关心Slave的执行状态,执行成功后,立即返回给用户。试想下,若一个事务提交后,Master成功返回给用户后crash,这个事务的binlog还没来得及传递到Slave,那么Slave相对于Master而言就少了一个事务,此时主备就不一致了。对于要求强一致的业务是不可以接受的,半同步复制就是为了解决数据一致性而产生的。
为什么叫半同步复制?
- 先说说同步复制,所谓同步复制就是一个事务在Master和Slave都执行后,才返回给用户执行成功。这里核心是说Master和Slave要么都执行,要么都不执行,涉及到2PC(2 Phrase Commit)。而MySQL只实现了本地redo-log和binlog的2PC,但并没有实现Master和Slave的2PC,所以不是严格意义上的同步复制。而MySQL半同步复制不要求Slave执行,而仅仅是接收到日志后,就通知Master可以返回了。
- 这里关键点是Slave接受日志后是否执行,若执行后才通知Master则是同步复制,若仅仅是接受日志成功,则是半同步复制。
半同步复制如何实现?
- 半同步复制实现的关键点是Master对于事务提交过程特殊处理。目前实现半同步复制主要有两种模式,AFTER_SYNC模式和AFTER_COMMIT模式。两种方式的主要区别在于是否在存储引擎提交后等待Slave的ACK。
AFTER_COMMIT模式
- 先来看看AFTER_COMMIT模式,Start和End分别表示用户发起Commit命令和Master返回给用户的时间点,中间部分就是整个Commit过程Master和Slave做的事情。
- Master提交时,会首先将该事务的redo log刷入磁盘,然后将事务的binlog刷入磁盘(这里其实还涉及到两阶段提交的问题),然后进入innodb commit流程,这个步骤主要是释放锁,标记事务为提交状态(其他用户可以看到该事务的更新),这个过程完成后,等待Slave发送的ACK消息,等到Slave的响应后,Master才成功返回给用户。
AFTER_SYNC模式
- 与AFTER_COMMIT相比,master在AFTER_SYNC模式下,Fsync binlog后,就开始等待SLAVE同步。那么在进行第5步innodbcommit后,即其它事务能看到该事务的更新时,Slave已经成功接收到binlog,即使发生切换,Slave拥有与Master同样的数据,不会发生“幻读”现象。但是对于上面描述的第一种情况,结果是一样的。
- 所以,在极端情况下,半同步复制的Master-Slave会有一个事务不一致,但是对于用户而言,由于这个事务并没有成功返回给用户,所以无论事务提交与否都是可以接受的,用户有必要进行查询或重试,判读是否更新成功。或者我们想想,对于单机而言,若事务执行成功后,返回给用户时,网络断了,用户也是面临一样的问题,所以,这不是半同步复制的问题。对于提交返回成功的事务,半同步复制保证Master-Slave一定是一致的,从这个角度来看,半同步复制不会丢数据,可以保证Master-Slave的强一致性。
并行复制
半同步复制解决了Master-Slave的强一致问题,那么性能问题呢?从图1中可以看到参与复制的主要有两个线程:IO线程和SQL线程,分别用于拉取和回放binlog。对于Slave而言,所有拉取和解析binlog的动作都是串行的,相对于Master并发处理用户请求,在高负载下, 若Master产生binlog的速度超过Slave消费binlog的速度,导致Slave出现延迟。
那么如何并行化,并行IO线程,还是并行SQL线程?
其实两方面都可以并行,但是并行SQL线程的收益更大,因为SQL线程做的事情更多(解析,执行)。并行IO线程,可以将从Master拉取和写Relay log分为两个线程;并行SQL线程则可以根据需要做到库级并行,表级并行,事务级并行。库级并行在mysql官方版本5.6已经实现。并行复制框架实际包含了一个协调线程和若干个工作线程,协调线程负责分发和解决冲突,工作线程只负责执行。
并行复制如何处理冲突?
并发的世界是美好的,但不能乱并发,否则数据就乱了。Master上面通过锁机制来保证并发的事务有序进行,那么并行复制呢?Slave必需保证回放的顺序与Master上事务执行顺序一致,因此只要做到顺序读取binlog,将不冲突的事务并发执行即可。对于库级并发而言,协调线程要保证执行同一个库的事务放在一个工作线程串行执行;对于表级并发而言,协调线程要保证同一个表的事务串行执行;对于事务级而言,则是保证操作同一行的事务串行执行。
是否粒度越细,性能越好?
这个并不是一定的。相对于串行复制而言,并行复制多了一个协调线程。协调线程一个重要作用是解决冲突,粒度越细的并发,可能会有更多的冲突,最终可能也是串行执行的,但消耗了大量的冲突检测代价。
查询用了组合索引哪些字段
结合explain的key_len(索引长度字节数)和组合索引索引的字段长度来判断。
找出所有的下载任务:
explain select * from my_task where task_type = 'download';- 使用了key_task_type索引,该索引建立在
task_type varchar(32)字段上。 - varchar(32)表示32个字符,utf8编码下一个字符有3个字节,另外varchar还需要两个字节作为长度标示,所以explain的key_len为
32*3 + 2 = 98。
找出本地执行的任务:
explain select * from my_task where server_id = '127.0.0.1';- 使用了key_server_id 索引,对应于
server_id char(16)字段,另外,server_id允许为null,所以还需要一个字节表示是否为null,所以explain的key_len为16*3+1=49
找出待执行的任务:
explain select * from my_task where process_status = 1;- 使用了key_process_status索引,对应的
process_status int为4个字节。
找出2018-08-09后执行的任务:
explain select * from my_task where process_time >= '2018-08-09';- 使用了key_process_time 索引,对应
process_time timestamp字段也是4个字节。 - 找出2018-08-09后本机执行的下载任务:*
explain select * from my_task force index(key_multiple) where task_type = 'download' and server_id = '127.0.0.1' and process_time >= '2018-08-09'; - 这里使用了force index强制使用
key_multiple(task_type,server_id, process_status, process_time)索引。 - key_len为147,等于
(32*3+2) + (16*3+1),而32*3+2为task_type字段长度,16*3+1为server_id字段长度,可以看出,查询条件process_time 无法使用索引,这也是符合最左匹配原则的。
找出2018-08-09后本机执行成功或者失败的下载任务:
explain select * from my_task force index(key_multiple) where task_type = 'download' and server_id = '127.0.0.1' and process_status in (3,4) and process_time >= '2018-08-09';- key_len为155,等于
(32*3+2) + (16*3+1) + 4 + 4,可以看到该查询使用了key_multiple的所有字段。 - 看来索引中间字段(process_status)使用了in条件,也不妨碍后面字段(process_time)使用索引。
找出2018-08-09后被本机执行的下载任务:
explain select * from my_task force index(key_multiple) where task_type = 'download' and server_id = '127.0.0.1' and process_status > 1 and process_time >= '2018-08-09';- key_len为151,等于
(32*3+2) + (16*3+1) + 4,这里process_status > 1使用了范围查询,所以后面的字段process_time不能使用索引了。但process_status是可以使用索引的。
找出2018-08-09后处理节点不为null的待处理下载任务(这种是异常任务):
explain select * from my_task force index(key_multiple) where task_type = 'download' and server_id is null and process_status = 1 and process_time >= '2018-08-09';key_len为155,就是key_multiple所有字段都使用了索引,看来,查询为null的server_id字段不会影响后面字段使用索引,只是索引需要使用一个额外字节标示字段是否为null。
Rabbitmq
参考链接
简介
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ服务器是用[Erlang]语言编写的,而群集和故障转移是构建在[开放电信平台]框架上的。所有主要的编程语言均有与代理接口通讯的客户端[库]。用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
注:
- AMQP,即Advanced Message Queuing Protocol,高级消息队列协议,是应用层协议的一个开放标准,为面向消息的[中间件]设计。消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在,反之亦然。\
- AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。
- Erlang是一种通用的面向[并发]的编程语言, 在[编程范型]上,Erlang属于多重范型编程语言,涵盖函数式、并发式及[分布式]。顺序执行的Erlang是一个及早求值, 单次赋值和动态类型的函数式编程语言。Erlang是一个结构化,动态类型编程语言,内建并行计算支持。
- 消息队列是“”消费-生产者模型“”的一个典型的代表,一端往消息队列中不断写入消息,而另一端则可以读取或者订阅队列中的消息。
项目的使用
Rabbitmq 的队列容量可以认为是无限的,根据内存有关。 可以设置队列最大长度,当达到长度的时候,最先入队的消息将被丢弃。
流量削峰一般在秒杀活动中应用广泛
场景
秒杀活动,一般会因为流量过大,导致应用挂掉,为了解决这个问题,一般在应用前端加入消息队列。
作用:
- 可以控制活动人数,超过此一定阀值的订单直接丢弃,先显示一个排队中,后端在处理,可能成功可能失败。
- 可以缓解短时间的高流量压垮应用(应用程序按自己的最大处理能力获取订单)
为什么选择rabbitmq
- Rabbit mq 是一个高级消息队列,在分布式的场景下,拥有高性能。,对负载均衡也有很好的支持。
- 拥有持久化的机制,进程消息,队列中的信息也可以保存下来。
- 实现消费者和生产者之间的解耦。
- 对于高并发场景下,利用消息队列可以使得同步访问变为串行访问达到一定量的限流,利于数据库的操作。
- 可以使用消息队列达到异步下单的效果,排队中,后台进行逻辑下单。
AMQP,即Advanced Message Queuing Protocol,高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在
rabbitMQ的优点(适用范围)
- 基于erlang语言开发具有高可用高并发的优点,适合集群服务器。
- 健壮、稳定、易用、跨平台、支持多种语言、文档齐全。
- 有消息确认机制和持久化机制,可靠性高。
- 开源
使用场景
- 跨系统的异步通信,所有需要异步交互的地方都可以使用消息队列。就像我们除了打电话(同步)以外,还需要发短信,发电子邮件(异步)的通讯方式。
- 多个应用之间的耦合,由于消息是平台无关和语言无关的,而且语义上也不再是函数调用,因此更适合作为多个应用之间的松耦合的接口。基于消息队列的耦合,不需要发送方和接收方同时在线。在企业应用集成(EAI)中,文件传输,共享数据库,消息队列,远程过程调用都可以作为集成的方法。
- 应用内的同步变异步,比如订单处理,就可以由前端应用将订单信息放到队列,后端应用从队列里依次获得消息处理,高峰时的大量订单可以积压在队列里慢慢处理掉。由于同步通常意味着阻塞,而大量线程的阻塞会降低计算机的性能。
- 消息驱动的架构(EDA),系统分解为消息队列,和消息制造者和消息消费者,一个处理流程可以根据需要拆成多个阶段(Stage),阶段之间用队列连接起来,前一个阶段处理的结果放入队列,后一个阶段从队列中获取消息继续处理。
- 应用需要更灵活的耦合方式,如发布订阅,比如可以指定路由规则。
- 跨局域网,甚至跨城市的通讯(CDN行业),比如北京机房与广州机房的应用程序的通信。
rabbitmq 三个主要角色
- 生产者:消息的创建者,负责创建和推送数据到消息服务器;
- 消费者:消息的接收方,用于处理数据和确认消息;
- 代理:就是 RabbitMQ 本身,用于扮演“快递”的角色,本身不生产消息,只是扮演“快递”的角色。
消息发送流程
- 首先客户端必须连接到 RabbitMQ 服务器才能发布和消费消息,客户端和 rabbit server 之间会创建一个 tcp 连接,一旦 tcp 打开并通过了认证(认证就是你发送给 rabbit 服务器的用户名和密码),你的客户端和 RabbitMQ 就创建了一条 amqp 信道(channel),信道是创建在“真实” tcp 上的虚拟连接,amqp 命令都是通过信道发送出去的,每个信道都会有一个唯一的 id,不论是发布消息,订阅队列都是通过这个信道完成的。
- 生产者通过网络将消息发送给消费者,在中间会有一个应用RabbitMQ(转发和存储的功能),这时RabbitMQ收到消息后,根据消息指定的exchange(交换机)来查找绑定然后根据规则分发到不同的Queue(队列),queue将消息转发到具体的消费者。
- 消费者收到消息后,会根据自己对消息的处理对RabbitMQ进行返回,如果返回ack,就表示已经确认这条消息,RabbitMQ会对这条消息进行处理(一般是删除)。
- 如果消费者接收到消息后处理不了,就可能不对RabbitMQ进行处理,或者拒绝对消息处理,返回reject。
ACK消息确认机制
- ACK消息确认机制, 保证数据能被正确处理而不仅仅是被Consumer(接收端)收到,我们就不能采用no-ack或者auto-ack,我们需要手动ack(manual-ack)。在数据处理完成后手动发送ack,这个时候Server才将Message删除。
- ACK机制可以起到限流的作用,比如在消费者处理后,sleep一段时间,然后再ACK,这可以帮助消费者负载均衡。
- 当然,除了ACK,有两个比较重要的参数也在控制着consumer(接收端)的load-balance,即prefetch和concurrency
Broker(消息队列服务器实体)
接收和分发消息的应用,RabbitMQ Server就是Message Broker。
Virtual host(虚拟消息服务器)
出于多租户和安全因素设计的,把AMQP的基本组件划分到一个虚拟的分组中,类似于网络中的namespace概念。当多个不同的用户使用同一个RabbitMQ server提供的服务时,可以划分出多个vhost,每个用户在自己的vhost创建exchange/queue等
Connection(TCP连接)
publisher(发送端)/consumer(接收端)和broker(消息队列服务器实体)之间的TCP连接。断开连接的操作只会在client端进行,Broker(消息队列服务器实体)不会断开连接,除非出现网络故障或broker(消息队列服务器实体)服务出现问题。
Channel(connection内部建立的逻辑连接)
如果每一次访问RabbitMQ都建立一个Connection,在消息量大的时候建立TCP Connection的开销将是巨大的,效率也较低。Channel是在connection内部建立的逻辑连接,如果应用程序支持多线程,通常每个thread创建单独的channel进行通讯,AMQP method包含了channel id帮助客户端和message broker识别channel,所以channel之间是完全隔离的。Channel作为轻量级的Connection极大减少了操作系统建立TCP connection的开销。
Exchange(交换机)
message到达broker(消息队列服务器实体)的第一站,根据分发规则,匹配查询表中的routing key,分发消息到queue中去。
Queue(队列)
消息最终被送到这里等待consumer(接收端)取走。一个message可以被同时拷贝到多个queue中。
Binding(交换机和队列之间的虚拟连接)
exchange和queue之间的虚拟连接,binding中可以包含routing key。Binding信息被保存到exchange中的查询表中,用于message的分发依据。
发送/接收信息
Send.py(发送信息)
- 权限验证
- 链接参数: virtual_host, 在多租户系统中隔离exchange, queue
- 建立链接
- 从链接中获得信道
- 声明交换机
- consumer(接收端)创建队列, 如果没有就创建
- 队列一旦被创建, 再进行的重复创建会简单的失效, 所以建议在producer(发送端)和consumer同时创建队列, 避免队列创建失败
- 创建队列回调函数, callback.
- auto_delete=True, 如果queue失去了最后一个subscriber会自动删除, 队列中的message也会失效.
- 默认auto_delete=False, 没有subscriber的队列会cache message, subscriber出现后将缓存的message发送.
- delivery_mode=2表示让消息持久化, 重启RabbitMQ也不丢失. 考虑成本, 开启此功能, 建议把消息存储到SSD上.
- 发布消息到exchange
- 关闭链接
receive.py(接收信息)
- 权限验证
- 链接参数: virtual_host, 在多租户系统中隔离exchange, queue
- 建立链接
- 从链接中获得信道
- 声明交换机, 直连方式, 后面将会创建binding将exchange和queue绑定在一起
- consumer(接收端)创建队列, 如果没有就创建
- 队列一旦被创建, 再进行的重复创建会简单的失效, 所以建议在producer(发送端)和consumer(接收端)同时创建队列, 避免队列创建失败
- 创建队列回调函数, callback.
- auto_delete=True, 如果queue失去了最后一个subscriber会自动删除, 队列中的message也会失效.
- 默认auto_delete=False, 没有subscriber的队列会cache message, subscriber出现后将缓存的message发送.
- 通过binding将队列queue和交换机exchange绑定
- 处理接收到的消息的回调函数,method_frame携带了投递标记, header_frame表示AMQP信息头的对象
- 订阅队列, 我们设置了不进行ACK, 而把ACK交给了回调函数来完成
- 关闭连接
如何确保消息正确地发送至RabbitMQ
- RabbitMQ使用发送方确认模式,确保消息正确地发送到RabbitMQ。
- 发送方确认模式:将信道设置成confirm模式(发送方确认模式),则所有在信道上发布的消息都会被指派一个唯一的ID。一旦消息被投递到目的队列后,或者消息被写入磁盘后(可持久化的消息),信道会发送一个确认给生产者(包含消息唯一ID)。如果RabbitMQ发生内部错误从而导致消息丢失,会发送一条nack(not acknowledged,未确认)消息。
- 发送方确认模式是异步的,生产者应用程序在等待确认的同时,可以继续发送消息。当确认消息到达生产者应用程序,生产者应用程序的回调方法就会被触发来处理确认消息。
如何确保消息接收方消费了消息
- 接收方消息确认机制:消费者接收每一条消息后都必须进行确认(消息接收和消息确认是两个不同操作)。只有消费者确认了消息,RabbitMQ才能安全地把消息从队列中删除。
- 这里并没有用到超时机制,RabbitMQ仅通过Consumer的连接中断来确认是否需要重新发送消息。也就是说,只要连接不中断,RabbitMQ给了Consumer足够长的时间来处理消息。
下面罗列几种特殊情况:
- 如果消费者接收到消息,在确认之前断开了连接或取消订阅,RabbitMQ会认为消息没有被分发,然后重新分发给下一个订阅的消费者。(可能存在消息重复消费的隐患,需要根据bizId去重)
- 如果消费者接收到消息却没有确认消息,连接也未断开,则RabbitMQ认为该消费者繁忙,将不会给该消费者分发更多的消息。
避免消息重复投递或重复消费
在消息生产时,MQ内部针对每条生产者发送的消息生成一个inner-msg-id,作为去重和幂等的依据(消息投递失败并重传),避免重复的消息进入队列;在消息消费时,要求消息体中必须要有一个bizId(对于同一业务全局唯一,如支付ID、订单ID、帖子ID等)作为去重和幂等的依据,避免同一条消息被重复消费。
消息基于什么传输
由于TCP连接的创建和销毁开销较大,且并发数受系统资源限制,会造成性能瓶颈。RabbitMQ使用信道的方式来传输数据。信道是建立在真实的TCP连接内的虚拟连接,且每条TCP连接上的信道数量没有限制。
消息如何分发
若该队列至少有一个消费者订阅,消息将以循环(round-robin)的方式发送给消费者。每条消息只会分发给一个订阅的消费者(前提是消费者能够正常处理消息并进行确认)。
消息怎么路由
从概念上来说,消息路由必须有三部分:交换器、路由、绑定。生产者把消息发布到交换器上;绑定决定了消息如何从路由器路由到特定的队列;消息最终到达队列,并被消费者接收。
- 消息发布到交换器时,消息将拥有一个路由键(routing key),在消息创建时设定。
- 通过队列路由键,可以把队列绑定到交换器上。
- 消息到达交换器后,RabbitMQ会将消息的路由键与队列的路由键进行匹配(针对不同的交换器有不同的路由规则)。如果能够匹配到队列,则消息会投递到相应队列中;如果不能匹配到任何队列,消息将进入 “黑洞”。
常用的交换器主要分为一下三种:
- direct:如果路由键完全匹配,消息就被投递到相应的队列
- fanout:如果交换器收到消息,将会广播到所有绑定的队列上
- topic:可以使来自不同源头的消息能够到达同一个队列。 使用topic交换器时,可以使用通配符,比如:“ * ” 匹配特定位置的任意文本, “ . ” 把路由键分为了几部分,“#” 匹配所有规则等。特别注意:发往topic交换器的消息不能随意的设置选择键(routing_key),必须是由”.”隔开的一系列的标识符组成。
确保消息不丢失
息持久化的前提是:将交换器/队列的durable属性设置为true,表示交换器/队列是持久交换器/队列,在服务器崩溃或重启之后不需要重新创建交换器/队列(交换器/队列会自动创建)。
如果消息想要从Rabbit崩溃中恢复,那么消息必须:
- 在消息发布前,通过把它的 “投递模式” 选项设置为2(持久)来把消息标记成持久化
- 将消息发送到持久交换器
- 消息到达持久队列
RabbitMQ确保持久性消息能从服务器重启中恢复的方式是,将它们写入磁盘上的一个持久化日志文件,当发布一条持久性消息到持久交换器上时,Rabbit会在消息提交到日志文件后才发送响应(如果消息路由到了非持久队列,它会自动从持久化日志中移除)。一旦消费者从持久队列中消费了一条持久化消息,RabbitMQ会在持久化日志中把这条消息标记为等待垃圾收集。如果持久化消息在被消费之前RabbitMQ重启,那么Rabbit会自动重建交换器和队列(以及绑定),并重播持久化日志文件中的消息到合适的队列或者交换器上。
重要的组件
- ConnectionFactory(连接管理器):应用程序与Rabbit之间建立连接的管理器,程序代码中使用。
- Channel(信道):消息推送使用的通道。
- Exchange(交换器):用于接受、分配消息。
- Queue(队列):用于存储生产者的消息。
- RoutingKey(路由键):用于把生成者的数据分配到交换器上。
- BindingKey(绑定键):用于把交换器的消息绑定到队列上。
vhost
vhost 可以理解为虚拟 broker ,即 mini-RabbitMQ server。其内部均含有独立的 queue、exchange 和 binding 等,但最最重要的是,其拥有独立的权限系统,可以做到 vhost 范围的用户控制。当然,从 RabbitMQ 的全局角度,vhost 可以作为不同权限隔离的手段(一个典型的例子就是不同的应用可以跑在不同的 vhost 中)。
保证消息持久化成功的条件
- 声明队列必须设置持久化 durable 设置为 true.
- 消息推送投递模式必须设置持久化,deliveryMode 设置为 2(持久)。
- 消息已经到达持久化交换器。
- 消息已经到达持久化队列。
rabbitmq 持久化有什么缺点
持久化的缺地就是降低了服务器的吞吐量,因为使用的是磁盘而非内存存储,从而降低了吞吐量。可尽量使用 ssd 硬盘来缓解吞吐量的问题。
几种广播类型
三种广播模式:
- fanout: 所有bind到此exchange的queue都可以接收消息(纯广播,绑定到RabbitMQ的接受者都能收到消息);
- direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息;
- topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息;
延迟消息队列实现
- 通过消息过期后进入死信交换器,再由交换器转发到延迟消费队列,实现延迟功能;
- 使用 RabbitMQ-delayed-message-exchange 插件实现延迟功能。
集群的作用
- 高可用:某个服务器出现问题,整个 RabbitMQ 还可以继续使用;
- 高容量:集群可以承载更多的消息量。
节点的类型
- 磁盘节点:消息会存储到磁盘。
- 内存节点:消息都存储在内存中,重启服务器消息丢失,性能高于磁盘类型。
集群搭建注意问题
- 各节点之间使用“–link”连接,此属性不能忽略。
- 各节点使用的 erlang cookie 值必须相同,此值相当于“秘钥”的功能,用于各节点的认证。
- 整个集群中必须包含一个磁盘节点。
rabbitmq 每个节点是其他节点的完整拷贝吗
不是,原因有以下两个:
- 存储空间的考虑:如果每个节点都拥有所有队列的完全拷贝,这样新增节点不但没有新增存储空间,反而增加了更多的冗余数据;
- 性能的考虑:如果每条消息都需要完整拷贝到每一个集群节点,那新增节点并没有提升处理消息的能力,最多是保持和单节点相同的性能甚至是更糟。
集群中唯一一个磁盘节点崩溃了会发生什么
如果唯一磁盘的磁盘节点崩溃了,不能进行以下操作:
- 不能创建队列
- 不能创建交换器
- 不能创建绑定
- 不能添加用户
- 不能更改权限
- 不能添加和删除集群节点
唯一磁盘节点崩溃了,集群是可以保持运行的,但你不能更改任何东西。
API 接口
接口的规范
接口规范采用rustful接口规范
使用SSL(https)来提供URL
- 首先,使用https可以在数据包被抓取时多一层加密。我们现在的APP使用环境大部分都是在路由器WIFI环境下,一旦路由器被入侵,那么黑客可以非常容易的抓取到用户通过路由器传输的数据,如果使用http未经加密,那么黑客可以很轻松的获取用户的信息,甚至是账户信息。
- 其次,即使使用https,也要在API数据传输设计时,正确的采用加密。例如直接将token信息放在URL中的做法,即使你使用了https,黑客抓不到你具体传输的数据,但是可以抓到你请求的URL啊!因此,使用https进行请求时,要采用POST、PUT或者HEAD的方式传输必要的数据。
使用GET、POST、PUT、DELETE这几种请求模式
请求模式也可以说是动作、数据传输方式,通常我们在web中的form有GET、POST两种,而在HTTP中,存在下发这几种。
GET (选择):从服务器上获取一个具体的资源或者一个资源列表。
POST (创建): 在服务器上创建一个新的资源。
PUT(更新):以整体的方式更新服务器上的一个资源。
PATCH (更新):只更新服务器上一个资源的一个属性。
DELETE(删除):删除服务器上的一个资源。
HEAD : 获取一个资源的元数据,如数据的哈希值或最后的更新时间。
OPTIONS:获取客户端能对资源做什么操作的信息。
在URI中体现资源,而非动作
- 在构建API的URL的时候,URI中应该仅包含资源(对象),而不要加入动作。比如 /user/1/update ,其中update就是一个动作,虽然我们希望通过这个URI来实现用户ID为1的用户进行信息更新,但是按照RESTful的规范,作为动作,应该用上面的PUT来表示,所以请求更新用户信息,应该使用 PUT /user/1 来表示更新用户ID为1的用户信息。
- 如果去对应上面的请求模式,GET表示显示、列出、展示,POST表示提交、创建,PUT表示更新,DELETE表示删除。
版本
- API的开发直接关系了APP是否可以正常使用,如果原本运行正常的API,突然改动,那么之前使用这个API的APP可能无法正常运行。APP是不可能强迫用户主动升级的,因此,通过API版本来解决这个问题。也就是说,API的多个版本是同时运行的,而且都要保证可以正常使用。
- 按照RESTful的规范,不同的版本也应该用相同的API URL,通过header信息来判断版本,再调用不同版本的程序进行处理。但是这明显会给开发带来巨大的成本。解决办法有两种:1.新版本兼容旧版本,所有旧版本的动作、字段、操作,都在新版本中可以被实现,但明显这样的维护成本很大;2.不同的版本,用不同的URL来提供服务,比如再URL中通过v1、v2来区分版本号,我则更喜欢采用子域名的方式,比如v2.api.xxx.com/user的方式。
HTTP响应码
在用户发出请求,服务端对请求进行响应时,给予正确的HTTP响应状态码,有利于让客户端正确区分遇到的情况。
- 200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。
- 201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。
- 202 Accepted - [* ] :表示一个请求已经进入后台排队(异步任务)
- 204 NO CONTENT - [DELETE]:用户删除数据成功。
- 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。
- 401 Unauthorized - [* ]:表示用户没有权限(令牌、用户名、密码错误)。
- 403 Forbidden - [* ] 表示用户得到授权(与401错误相对),但是访问是被禁止的。
- 404 NOT FOUND - [* ]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。
- 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。
- 410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的
- 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。
- 500 INTERNAL SERVER ERROR - [* ]:服务器发生错误,用户将无法判断发出的请求是否成功。
返回值结构
用JSON进行返回,而非xml。
原因:
- JSON可以很好的被很多程序支持,javascript的ajax可以直接将JSON转换为对象。
- JSON的格式在容量上比xml小很多,可以减低宽带占用,提高传输效率。
那么,返回值应该怎么去部署呢?
- 首先,字段的合理返回,数据的包裹。因为返回值中,我们常常要对数据进行区分分组,或者按照从属关系打包,所以,我们再返回时,最好有包裹的思想,把数据存放在不同的包裹中进行返回。可以使用data来作为数据包,将所有数据统一以这个字段进行包裹。除了data,也可以用list等其他形式的包裹,命名都是自己来根据自己的需要确定的。
- 总之,不要不分包,直接把所有数据和一些你想返回的全局数据混在一起进行返回。
- 其次,错误码。错误码的作用是方便查找错误原因,通常情况下,我喜欢用error_code来表示,当error_code=0时,表示没有发生错误,当error_code>0时,发生了错误,并且提供较为详细的文档,告诉客户端对应的error_code值所产生的错误的原因和位置。
- 最后,空白压缩和字符转换。也就是返回的JSON结果不要换行和空格,用一行返回结果,使整个结果文本容量最小。同时,中文等字符或结果中有引号,都进行字符转换,防止结果无法被正确识别。
鉴权
- 其实也就是客户端的权限控制。一般而言,我会采用给客户端分发一个token来确定该客户端的唯一身份。客户端在请求时,通过这个token,判断发出请求的客户端所对应的用户,及其相关信息和权限。
- token信息不是用来进行处理的数据,虽然可以通过POST、PUT等进行数据提交或传输,但是从RESTful规范来讲,它不属于操作数据,在服务端进行处理时,仅是利用token进行鉴权处理,所以,我的建议是通过header来发送token。
- 国内大部分API对PUT、DELETE请求进行了阉割,更不用提HEAD、PACTH、OPTIONS请求。实际上,国内大部分开放API仅支持GET和POST两种,部分API支持将app key信息通过header进行发送。在面对这种情况下,我们不得不抛弃标准的RESTful规范,在url中加入get、add、update、delete等动作词汇,以补充由于请求支持不完善带来的动作区分问题。如果仅支持GET和POST,那么所有需要保密的数据,绝对不可以用GET来进行请求,而必须用POST。
接口的安全
保证接口的可用性
接口的效率
接口的版本控制
算法
时间复杂度
*算法分析 *
- 同一问题可用不同算法解决,而一个算法的质量优劣将影响到算法乃至程序的效率.算法分析的目的在 于选择合适算法和改进算法.一个算法的评价主要从时间复杂度和空间复杂度来考虑.
- 计算机科学中,算法的时间复杂度是一个函数,它定性描述了该算法的运行时间。这是一个关于代 表算法输入值的字符串的长度的函数。时间复杂度常用大O符号表述,不包括这个函数的低阶项和首 项系数。使用这种方式时,时间复杂度可被称为是渐近的,它考察当输入值大小趋近无穷时的情况
*时间复杂度 *
在计算机科学中,算法的时间复杂度是一个函数,它定性描述了该算法的运行时间。这是一个关于 代表算法输入值的字符串的长度的函数。时间复杂度常用大O符号表述,不包括这个函数的低阶项和 首项系数。
*计算方法 *
1.一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅 助函数f(n),使得T(n)/f(n)的极限值(当n趋近于无穷大时)为不等于零的常数,则称f(n)是T(n)的同 数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。 分析:随着模块n的增大,算法执行的时间的增长率和 f(n) 的增长率成正比,所以 f(n) 越小,算法的 时间复杂度越低,算法的效率越高。
- 在计算时间复杂度的时候,先找出算法的基本操作,然后根据相应的各语句确定它的执行次数, 再找出 T(n) 的同数量级(它的同数量级有以下:1,log2n,n,n log2n ,n的平方,n的三次方,2 的n次方,n!),找出后,f(n) = 该数量级,若 T(n)/f(n) 求极限可得到一常数c,则时间复杂度T(n) = O(f(n))
- 在pascal中比较容易理解,容易计算的方法是:看看有几重for循环,只有一重则时间复杂度为 O(n),二重则为O(n^2),依此类推,如果有二分则为O(logn),二分例如快速幂、二分查找,如果一 个for循环套一个二分,那么时间复杂度则为O(nlogn)。
*分类 *
- 按数量级递增排列,常见的时间复杂度有: 常数阶O(1),对数阶O(log 2的n次方 ),线性阶O(n), 线性对数阶O(nlog2n),平方阶O(n^2),立方阶O(n^3),…, k次方阶O(n^k),指数阶O(2^n)。
- 随着问题规模n的不断增大,上述时间复杂度不断增大,算法的执行 效率越低。
理解
- 整个算法的执行时间与基本操 作重复执行的次数成正比。
- 基本操作重复执行的次数是问题规模n的某个函数f(n),于是算法的时间量度可以记为:T(n) = O(f(n)) 如果按照这么推断,T(n)应该表示的是算法的时间量度,也就是算法执行的时间。
- 而该页对“语句频度”也有定义:指的是该语句重复执行的次数。
- 如果是基本操作所在语句重复执行的次数,那么就该是f(n)。 上边的n都表示的问题规模。
总结
时间频度
一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道.但我们不可能也没 有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了.并且 一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多. 一个算法中的语句执行次数称为语句频度或时间频度.记为T(n).
时间复杂度
- 一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数 f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数. 记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度.
- 在各种不同算法中,若算法中语句执行次数为一个常数,则时间复杂度为O(1),另外,在时间频度不相同 时,时间复杂度有可能相同,如T(n)=n^2+3n+4与T(n)=4n^2+2n+1它们的频度不同,但时间复杂度 相同,都为O(n2).
- 按数量级递增排列,常见的时间复杂度有: 常数阶O(1),对数阶O(log2n),线性阶O(n), 线性对数阶O(nlog2n),平方阶O(n2),立方阶O(n3),…,
- k次方阶O(nk),指数阶O(2n).随着问题规模n的不断增大,上述时间复杂度不断增大,算法的执行效率越 低.
空间复杂度
- 与时间复杂度类似,空间复杂度是指算法在计算机内执行时所需存储空间的度量.记作: S(n)=O(f(n)) 我们一般所讨论的是除正常占用内存开销外的辅助存储单元规模.
- O(1): 表示算法的运行时间为常量
- O(n): 表示该算法是线性算法
- O(㏒2n): 二分查找算法
- O(n2): 对数组进行排序的各种简单算法,例如直接插入排序的算法。
- O(n3): 做两个n阶矩阵的乘法运算
- O(2n): 求具有n个元素集合的所有子集的算法
- O(n!): 求具有N个元素的全排列的算法
- O(n²)表示当n很大的时候,复杂度约等于Cn²,C是某个常数,简单说就是当n足够大的 时候,n的线性增长,复杂度将沿平方增长。
- 一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。 但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪 个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句的执行次数成正 比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为 语句频度或时间频度。记为T(n)。
- 一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示, 若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常 数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n))
性能比较
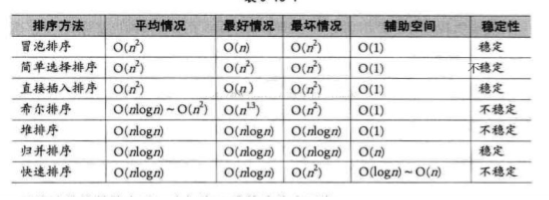
排序 算法
交换排序:交换排序的基本思想是,比较两个记录键值的大小,如果这两个记录键值的大小出现逆 序,则交换这两个记录,这样将键值较小的记录向序列前部移动,键值较大的记录向序列后部移动。
冒泡排序
冒泡排序(Bubble Sort,台湾译为:泡沫排序或气泡排序)是一种简单的排序算法。它重复 地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访 数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的 名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
步骤
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一 点,最后的元素应该会是最大的数。 3. 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比 较。
冒泡排序理解起来是最简单,但是时间复杂度(O(n^2))也是最大的之一
快速排序
快速排序是由东尼∙霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要Ο(n log n) 次比较。在最坏状况下则需要Ο(n2)次比较,但这种状况并不常见。事实上,快速排序通常明 显比其他Ο(n log n) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很 有效率地被实现出来,且在大部分真实世界的数据,可以决定设计的选择,减少所需时间的 二次方项之可能性。
步骤
- 从数列中挑出一个元素,称为 “基准”(pivot)
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大 的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排 序。
快排也是一个高效的排序算法,它的时间复杂度也是O(nlogn)
选择排序
- 选择排序(Selection sort)是一种简单直观的排序算法。首先在未排序序 列中找到最小元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最 小元素,然后放到排序序列末尾。以此类推,直到所有元素均排序完毕。
- 选择排序包括两种,分别是直接选择排序和堆排序,选择排序的基本思想是每一次在ni+1(i=1,2,3,…,n-1)个记录中选取键值最小的记录作为有序序列的第i个记录
堆排序
堆积排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全 二叉树的结构,并同时满足堆性质:即子结点的键值或索引总是小于(或者大于)它的父节 点。
步骤
堆排序是指利用堆积树(堆)这种数据结构所设计的一种排序算法,利用数组的特点快速定位指定 索引的元素。堆分为大根堆和小根堆,是完全二叉树。大根堆的要求是每个节点的值都不大于其父 节点的值,即A[PARENT[i]] >= A[i]。在数组的非降序排序中,需要使用的就是大根堆,因为根据 大根堆的要求可知,最大的值一定在堆顶。
堆排序是一种高效的排序算法,它的时间复杂度是O(nlogn)。原理是:先把数组转为一个最 大堆,然后把第一个元素跟第i元素交换,然后把剩下的i-1个元素转为最大堆,然后再把第一 个元素与第i-1个元素交换,以此类推
插入排序
插入排序(Insertion Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构 建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入 排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向 前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
步骤
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置中
- 重复步骤2
插入排序跟冒泡排序有点相似,时间复杂度也是O(n^2)
希尔排序
- 希尔排序,也称递减增量排序算法,是插入排序的一种高速而稳定的改进版本。 希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 1、插入排序在对几乎已经排好序的数据操作时, 效率高, 即可以达到线性排序的效率
- 2、但插入排序一般来说是低效的, 因为插入排序每次只能将数据移动一位>
- 希尔排序其实可以理解是插入排序的一个优化版,它的效率跟增量有关,增量要取多 少,根据不同的数组是不同的,所以希尔排序是一个不稳定的排序算法,它的时间复杂 度为O(nlogn)到O(n^2)之间
归并排序
归并排序(Merge sort,台湾译作:合并排序)是建立在归并操作上的一种有效的排序算 法。该算法是采用分治法(pide and Conquer)的一个非常典型的应用
步骤
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针 到下一位置
- 重复步骤3直到某一指针达到序列尾
- 将另一序列剩下的所有元素直接复制到合并序列尾
归并排序的时间复杂度也是O(nlogn)。原理是:对于两个排序好的数组,分别遍历这两 个数组,获取较小的元素插入新的数组中,那么,这么新的数组也会是排序好的。
顺序查找
** 说明**
顺序查找适合于存储结构为顺序存储或链接存储的线性表。
基本思想
顺序查找也称为线形查找,属于无序查找算法。从数据结构线形表的一端开始,顺 序扫描,依次将扫描到的结点关键字与给定值k相比较,若相等则表示查找成功;若扫描结束仍没有 找到关键字等于k的结点,表示查找失败。
*复杂度分析 *
查找成功时的平均查找长度为:(假设每个数据元素的概率相等) ASL = 1/n(1+2+3+…+n) = (n+1)/2 ; 当查找不成功时,需要n+1次比较,时间复杂度为O(n);
二分查找
二分搜索(binary search),也称折半搜索(half-interval search)、对数搜索(logarithmic search),是一种在有序数组中查找某一特定元素的搜索算法。搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。
思路
- 查找的k可能在数组下标区间a,b
- 计算区间ab的中间点m
- k < tarr[m] 将区间缩小为a,m继续二分查找
- k >arr[m] 将区间缩小为m,b,继续二分查找
** 复杂度分析**
最坏情况下,关键词比较次数为log2(n+1),且期望时间复杂度为O(log2n);
其他链接
优惠券
优惠券业务设计
链接: www.jianshu.com/p/269a54846a9c
技术架构设计:blog.csdn.net/HUXU981598436/articl...
优惠券表设计:
blog.csdn.net/t_332741160/article/...
优惠券业务设计
blog.csdn.net/egworkspace/article/...
MYSQL 索引
blog.csdn.net/xluren/article/detai...
未完。。。。
本作品采用《CC 协议》,转载必须注明作者和本文链接





















































 谁有岗位推荐的
谁有岗位推荐的




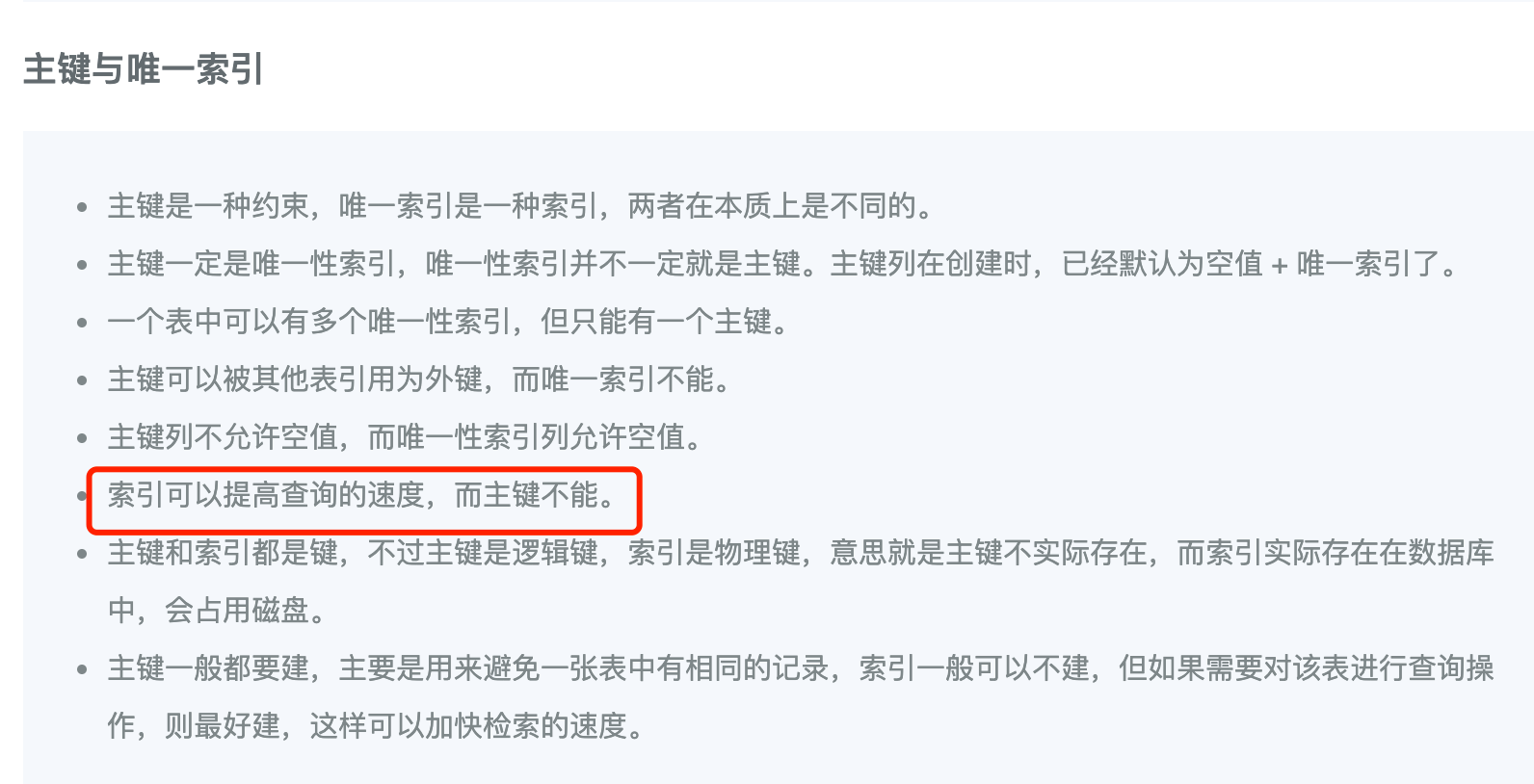 这是神马操作
这是神马操作




 关于 LearnKu
关于 LearnKu




推荐文章: