
由浅入深 docker 系列: (5) 资源隔离
3 / 0 / 创建于 7年前 /
 lixiang9194 的个人博客
lixiang9194 的个人博客
上篇文章说了容器只是宿主机中的一个用户进程,和虚拟机完全不同,那么,为什么在容器内看不到宿主机进程,容器又是如何实现进程、文件、网络等资源的隔离呢?
这就牵涉到今天要介绍的linux内核的Namespace和Cgroups特性了。
1.Namespace
Linux 内核从版本 2.4.19 开始陆续引入了 Namespace 的概念。其目的是将某个特定的全局系统资源通过抽象方法使得namespace 中的进程看起来拥有它们自己的隔离的全局系统资源实例。Linux 内核中实现了六种 Namespace,按照引入的先后顺序,列表如下: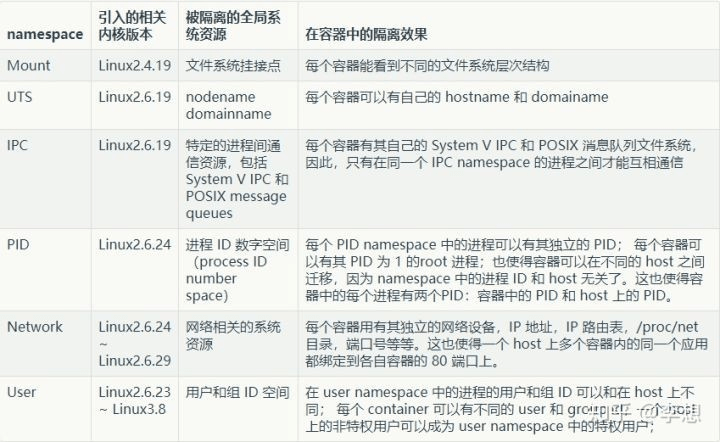
例如,容器进程启动时,只要启用了Mount Namespace,并将自己打包的文件系统挂载好,就可以实现每个容器仅看到自己的文件,实现文件资源的隔离。总之,Docker 守护进程创建容器实例时都启用了相应的Namespace,使得容器中的进程都处于一种隔离的运行环境之中。
那么如何启用相应Namespace呢?
通过系统调用clone()来创建一个具有独立Namespace的进程是最常见的做法,它可以通过flags参数传入相应标志位来控制进程的各种状态,如以下示意代码:
pid = clone(fun,stack,flags,clone_arg);
(flags:CLONE_NEWPID | CLONE_NEWNS |
CLONE_NEWUSER | CLONE_NEWNUT |
CLONE_NEWIPC | CLONE_NEWUTS |
...)
docker run中namespace相关参数
- --ipc string IPC namespace to use
- --pid string PID namespace to use
- --userns string User namespace to use
- --uts string UTS namespace to use
你可以在容器启动的时候,指定这些参数,从而强制容器运行在特定namespace之中。例如,你可以指定 --pid host,从而让容器进程使用宿主机进程空间,此时容器可以看到host上所有的进程(想象这样一个场景,你把常用的性能诊断工具都打包到一个镜像中,然后必要的时候在服务器上使用此镜像进行问题分析,此时加上该参数会很方便)。
2.Cgroups
通过Namespace,容器实现了资源的隔离,从而每个容器看起来都像是拥有自己独立的运行环境。注意,只是看起来。因为容器使用cpu、内存等并不受限制,假如某个容器占用这些资源过高,就可能会造成其它容器运行迟缓甚至异常,这就需要Cgroups了。
cgroups 的全称是control groups,是Linux内核提供的一种可以限制单个进程或者多个进程所使用资源的机制,可以对 cpu,内存等资源实现精细化的控制。
其典型的子系统如下:
- cpu 子系统,主要限制进程的 cpu 使用率。
- cpuacct 子系统,可以统计 cgroups 中的进程的 cpu 使用报告。
- cpuset 子系统,可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点。
- memory 子系统,可以限制进程的 memory 使用量。
- blkio 子系统,可以限制进程的块设备 io。
- devices 子系统,可以控制进程能够访问某些设备。
- net_cls 子系统,可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。
- freezer 子系统,可以挂起或者恢复 cgroups 中的进程。
- ns 子系统,可以使不同 cgroups 下面的进程使用不同的 namespace。
而Cgroups的实现也很有意思,它并不是一组系统调用,linux将其实现为了文件系统,这很符合Unix一切皆文件的哲学,因此我们可以直接查看。
例如,我在ubuntu18.04系统中,直接执行mount -t cgroup即可看到,系统已经自动在sys/fs/cgroup目录下挂载好了相应文件,每个文夹件代表了上面所讲的某种资源类型。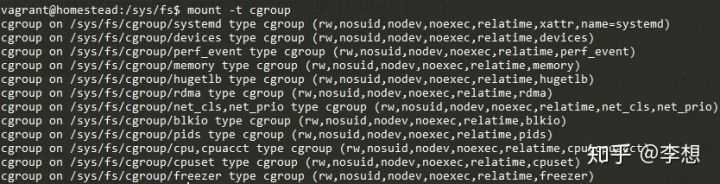
我们可以查看sys/fs/cgroup/cpu文件夹下的文件,它代表对cpu资源的控制,其中tasks文件中是我们系统的进程pid,表示对这些进程进行资源控制,其它文件如cpu.cfs_quota_us表示cpu的利用率,默认值为-1,表示不做限制。
如何使用Cgroups呢
很简单,我们可以直接在相应资源控制组目录下创建文件夹,系统会自动创建需要的文件,例如,在上述cpu目录下创建hello目录,然后看到相应文件已自动创建。
然后我们写一个死循环,代码如下,然后编译执行
//deadLoop.c
int main(void)
{
int i = 0;
for(;;) i++;
return 0;
}
//编译 gcc deadLoop.c -o deadLoop
//执行 ./deadLoop执行top命令,很容易发现,cpu使用率达到了100%左右,怎么办呢?
进入刚才创建的hello目录,将cpu.cfs_quota_us的值改为20000(此参数表示1秒周期内进程使用cpu的最大微秒数,因此20000表示20%),然后将deadLoop进程的Pid写入tasks文件中去,再次执行top命令,你将看到cpu使用率只有20%了!
命令如下:
top
cd /sys/fs/cgroup/cpu/hello
echo 20000 > cpu.cfs_quota_us
ps aux | grep deadLoop
echo pid > tasks
top很直观吧,其它资源的控制也与此类似。
docker对Cgroups的使用
默认情况下,docker 启动一个容器后,就会在 /sys/fs/cgroup 目录下的各个资源目录下生成以容器 ID 为名字的目录,在容器被 stopped 后,该目录被删除。那么,对容器资源进行控制的方式,就同上边的例子一样,显而易见了。
至于docker run提供的Cgroups相关参数,就请你自己查阅文档吧。
3.其它
本篇简单介绍了下Linux内核的Namespace和Cgroups功能,从而理解容器中资源的隔离和控制技术的实现原理,主要是帮助你建立基本的概念,而关于这些功能的使用细节以及内核中的实现原理,还很复杂,想了解的话还需要你投入大量精力。
另外,我们也可以看到,docker并不是全新的技术,它是对很多已有技术的封装、抽象,只要深入的学习下去,你就会看到很多熟悉的东西,你对容器的理解也会越来越深刻,加油!
参考资料:
Docker背后的内核知识——Namespace资源隔离 - InfoQ
理解Docker(4):Docker 容器使用 cgroups 限制资源使用
本作品采用《CC 协议》,转载必须注明作者和本文链接










 关于 LearnKu
关于 LearnKu




推荐文章: