
Docker 容器搭建及 Redis 集群原理
0 / 0 / 创建于 7年前 /
 JaneWorld 的个人博客
JaneWorld 的个人博客
Docker 的主要用途,目前有三大类。
(1)提供一次性的环境。比如,本地测试他人的软件、持续集成的时候提供单元测试和构建的环境。
(2)提供弹性的云服务。因为 Docker 容器可以随开随关,很适合动态扩容和缩容。
(3)组建微服务架构。通过多个容器,一台机器可以跑多个服务,因此在本机就可以模拟出微服务架构。
~Centos 安装docker~
1、更新update到最新的版本
yum update
2、卸载老版本docker
yum remove docker docker-common docker-selinux docker-engine
3、安装需要的软件包
yum install -y yum-utils device-mapper-persistent-data lvm2
4、设置yum源
yum-config-manager --add-repo https://download.docker.com/linux/centos/d...
5、查看docker版本
yum list docker-ce --showduplicates|sort -r
6、安装docker
yum install docker-ce-18.03.1.ce -y
7、启动docker
systemctl start docker
8、加入开机自启
systemctl enable docker
9、配置国内镜像
vi /etc/docker/daemon.json
{
"registry-mirrors": ["http://hub-mirror.c.163.com"]
}
Docker 指令
查询docker命令:docker --help
1. 启动
2. 删除
停止所容器
docker stop $(docker ps -aq)
docker rm $(docker ps -aq)
查看当前镜像:docker image
查看当前docker版本:docker -v
创建镜像:docker build -t redis-test . (创建一个名叫redis-test的镜像) .:代表当前上下文路径、必须有
docker build --no-cache -t redis2 .
指定网段:172.10.0.0/16 并命名为mynetwork,指令如下:
docker network create --subnet=172.10.0.0/16 mynetwork
通过docker命令分别进入到redis容器当中,主从复制查看另外一个文档
构建容器:docker run -it --name redis-master --net mynetwork -p 6380:6379 --ip 172.10.0.2 redis
构建容器:docker run -it --name redis-slave --net mynetwork -p 6381:6379 --ip 172.10.0.3 redis
查看所有容器:docker ps -a (一个容器可以创建多个镜像) 或者 docker container
查看网络类型:docker network ls
查看容器IP地址:docker network inspect mynetwork
进入容器:docker exec -it redis(容器名) bash sudo docker exec -it 775c7c9ee1e1 /bin/bash
运行容器:docker run -ti redis-master(容器名) /bin/bash
退出容器:exit
查看docker版本:yum list installed | grep docker
卸载docker安装包:yum remove docker-ce.x86_64 ddocker-ce-cli.x86_64 -y
删除镜像/容器等:rm -rf /var/lib/docker
清除缓存并重新构建yum 源: yum clean all yum makecache
配置DOCKER_HOST:sudo vim /etc/profile.d/docker.sh
https://www.cnblogs.com/SH170706/p/1024250...
容器外面和里面公用一个文件夹:VOLUME /usr/docker/config
构建容器的时候-v创建公用文件夹:docker run -itd --name redis-maser2 -v /usr/docker/config:/config --net mynetwork -p 6383:6379 --ip 172.10.0.4 redis2
在从服务器里,vi /etc/redis.conf
配置bind 0.0.0.0
关闭保护模式proteced model no
slaveof 主节点IP 6379
info replication(在从节点客户端下,查看角色)
报错Could not connect to Redis at 127.0.0.1:6379: Connection refused
主容器里启动redis服务:redis-server ./redis-master.conf &
从容器里启动redis服务:redis-server ./redis-slave.conf &
哨兵容器里启动redis服务:redis-sentinel ./redis-sentinel.conf &
查看服务器日志:vi /var/log/redis/redis.log
vi /var/log/redis/sentinel.log
停止全部容器:docker stop $(docker ps -aq)
RDB快照和AOF快照
查看获取 redis 服务的配置参数:CONFIG GET maxmemory(主从内存数量)
查看服务器运行id(runid):info server
增加延迟5秒同步:tc qdisc add dev eth0 root netem delay 5000ms
删除: del
全量复制:尽量避免主节点给子节点造成全量复制,造成一次发送大量数据。
部分复制:主从复制中因网络闪断原因造成数据丢失场景,从节点再次连上主节点后,如果条件允许,主节点会补发丢失数据给从节点。补发的数据远远小于全量复制,有效避免全量复制的过高开销。特别注意的是,网络中断时间过长,造成主节点没能够完整保存中断期间执行的写命令,则无法进行部分复制,仍使用全量复制。
Redis全量复制的过程如下:
1、Redis 内部会发出一个同步命令,刚开始是 Psync 命令,Psync ? -1表示要求 master 主机同步数据
2、主机会向从机发送 runid 和 offset,因为 slave 并没有对应的 offset,所以是全量复制
3、从机 slave 会保存 主机master 的基本信息 save masterInfo
4、主节点收到全量复制的命令后,执行bgsave(异步执行),在后台生成RDB文件(快照),并使用一个缓冲区(称为复制缓冲区)记录从现在开始执行的所有写命令
5、主机send RDB 发送 RDB 文件给从机
6、发送缓冲区数据
7、刷新旧的数据,从节点在载入主节点的数据之前要先将老数据清除
8、加载 RDB 文件将数据库状态更新至主节点执行bgsave时的数据库状态和缓冲区数据的加载。
全量复制开销,主要有以下几项:
bgsave 时间
RDB 文件网络传输时间
从节点清空数据的时间
从节点加载 RDB 的时间
部分复制
部分复制是 Redis 2.8 以后出现的,之所以要加入部分复制,是因为全量复制会产生很多问题,比如像上面的时间开销大、无法隔离等问题, Redis 希望能够在 master 出现抖动(相当于断开连接)的时候,可以有一些机制将复制的损失降低到最低。
1、如果网络抖动(连接断开 connection lost)
2、主机master 还是会写 replbackbuffer(复制缓冲区)
3、从机slave 会继续尝试连接主机
4、从机slave 会把自己当前 runid 和偏移量传输给主机 master,并且执行 pysnc 命令同步
5、如果 master 发现你的偏移量是在缓冲区的范围内,就会返回 continue 命令
6、同步了 offset 的部分数据,所以部分复制的基础就是偏移量 offset。
注意:
正常情况下redis是如何决定是全量复制还是部分复制
从节点将offset发送给主节点后,主节点根据offset和缓冲区大小决定能否执行部分复制:
如果offset偏移量之后的数据,仍然都在复制积压缓冲区里,则执行部分复制;
如果offset偏移量之后的数据已不在复制积压缓冲区中(数据已被挤出),则执行全量复制。
服务器运行ID(runid)
每个Redis节点(无论主从),在启动时都会自动生成一个随机ID(每次启动都不一样),由40个随机的十六进制字符组成;runid用来唯一识别一个Redis节点。 通过info server命令,可以查看节点的runid:
主从节点初次复制时,主节点将自己的runid发送给从节点,从节点将这个runid保存起来;当断线重连时,从节点会将这个runid发送给主节点;主节点根据runid判断能否进行部分复制:
如果从节点保存的runid与主节点现在的runid相同,说明主从节点之前同步过,主节点会继续尝试使用部分复制(到底能不能部分复制还要看offset和复制积压缓冲区的情况)
如果从节点保存的runid与主节点现在的runid不同,说明从节点在断线前同步的Redis节点并不是当前的主节点,只能进行全量复制。
*主从复制进阶常见问题解决**
1、读写分离
2、主从配置不一致
3、规避全量复制
4、规避复制风暴
设置从节点个数:CONFIG set min-slaves-to-write 2
查看设置内存:CONFIG get relbacklogsize
redis的主节点重启:debug reload(重启后,主节点的runid和offset都不受影响)
Sentinel 的核心配置:
sentinel monitor mymaster 127.0.0.1 7000 2
监控的主节点的名字、IP 和端口,最后一个2的意思是有几台 Sentinel 发现有问题,就会发生故障转移,例如 配置为2,代表至少有2个 Sentinel 节点认为主节点不可达,那么这个不可达的判定才是客观的。对于设置的越小,那么达到下线的条件越宽松,反之越严格。一般建议将其设置为 Sentinel 节点的一半加1
主从树状结构:是哨兵和集群的基础,是高可用的基础。
一主两从三哨兵,客户端访问哨兵集群。
kill掉主节点后,哨兵会帮助,从节点中选举出新的主节点。
docker network create --subnet=172.10.0.0/16 mytest
主节点容器:docker run -itd --name redis-master --net mytest -p 6380:6379 --ip 172.10.0.2 redis2 Master
从节点容器:docker run -itd --name redis-slave2 --net mytest -p 6384:6379 --ip 172.10.0.6 redis2 Slave
从节点容器:docker run -itd --name redis-slave3 --net mytest -p 6385:6379 --ip 172.10.0.7 redis2 Slave
哨兵节点容器:docker run -itd --name redis-sentinel1 --net mytest -p 22530:22530 --ip 172.10.0.9 redis2 Sentinel1
哨兵节点容器:docker run -itd --name redis-sentinel2 --net mytest -p 22531:22531 --ip 172.10.0.10 redis2 Sentinel2
哨兵节点容器:docker run -itd --name redis-sentinel3 --net mytest -p 22532:22532 --ip 172.10.0.11 redis2 Sentinel3
启动主容器: redis-server ./config/redis-master.conf
查看主从节点信息:SENTINEL masters
查看从节点信息:SENTENEL slaves mymaster
查看节点信息:docker inspect mytest
redis-sentinel /etc/redis-sentinel.conf &
查看链接信息:vi /var/log/redis/sentinel.log(可看到哨兵的redis端口号)
切换到哨兵redis的客户端:redis-cli -p 26379(端口号)
哨兵redis的客户端,获取当前主机的连接和master:SENTINEL get-master-addr-by-name mymaster
[WARNING: The file has been changed since reading it!!! Do you really want to write to it (y/n)?]
关掉正在使用该文件的进程
快照的生成,会fork一个子进程出来。
取消主从复制:slaveof no one
重启从服务器的复制:SLAVEOF 172.10.0.2 6379(主节点的IP)
安装网络延迟:yum install iproute -y
安装swoole:pecl install swoole
redis文档:
http://redisdoc.com/
https://blog.csdn.net/q1035331653/article/...
docker文档:
http://www.runoob.com/docker/docker-run-co...
http://www.dockerinfo.net/docker%E5%AE%B9%...
使用Dockerfile定制镜像:
1.FROM 指定基础镜像
2.RUN 执行命令(最新docker最多接受run 127层左右,用&&或\可避免)
FROM centos:latest
RUN groupadd -r redis && useradd -r -g redis redis\
RUN yum -y update && yum -y install epel-release && yum -y install redis && yum -y install net-tools\
EXPOSE 6379(暴露端口)
06.docker-compose命令、redis集群搭建
docker 编排工具搭建集群
docker-composer.yaml
image:公用镜像
container_name:容器名称
working_dir:公共工作目录
environment:环境变量
ports:外部的linux云服务器端口和容器的端口映射
networks:ipv4_address:172.50.0.3
stdin_open:输入
tty:终端
privileged:true 权限的提取
volunums:宿主机跟容器之间的共享目录
entrypoint:容器启动后会启动的命令
08.redis集群原理及常见问题、集群客户端封装
1、docker-compose构建cluster集群
2、Redis-cluster集群伸缩原理redis的Ruby工具快递创建集群(redis-trib.rb是采用Ruby实现Redis的集群管理工具)
启动好6个节点之后,使用 redis-trib.rb create 命令完成节点握手和槽分配过程
redis-trib.rb create --replicas 1 47.98.147.49:6391 47.98.147.49:6392 47.98.147.49:6393 47.98.147.49:6394 47.98.147.49:6395 47.98.147.49:6396
报错:-bash: gem: command not found
解决链接:https://blog.csdn.net/zhaoraolin/article/d...
https://blog.csdn.net/Hello_World_QWP/arti...
在当前Dockerfile的目录下构建:docker build -t redis-cluster .
编排指令:docker-compose -p redis-cluster up -d
env
查看工作目录:echo $PWD
查看端口:echo $PORT
echo /config/nodes-${PWD}.conf
进入节点:redis-cli -p 6394
查看集群状态:cluster info
查看节点信息:cluster nodes
cluster meet 116.255.176.221 6391
通过集群模式设计客户端:redis-cli -c -h 116.255.176.221 -p 6394 set tls 123
~二、Redis-cluster原理~
## **~1、~****~节点通信~**
在分布式存储中需要提供维护节点元数据信息的机制,所谓元数据是指:节点负责哪些数据,是否出现故障等状态信息,Redis 集群采用 Gossip(流言)协议,Gossip 协议工作原理就是节点彼此不断通信交换信息,一段时间后所有的节点都会知道集群完整的信息,这种方式类似流言传播集群中的每个节点都会单独开辟一个 TCP 通道,用于节点之间彼此通信,通信端口号在基础端口上加10000。
2)每个节点在固定周期内通过特定规则选择几个节点发送 ping 消息。
3)接收到 ping 消息的节点用 pong 消息作为响应。
集群中每个节点通过一定规则挑选要通信的节点,每个节点可能知道全部节点,也可能仅知道部分节点,只要这些节点彼此可以正常通信,最终它们会达到一致的状态。当节点出故障、新节点加入、主从角色变化、槽信息变更等事件发生时,通过不断的 ping/pong 消息通信,经过一段时间后所有的节点都会知道整个集群全部节点的最新状态,从而达到集群状态同步的目的
## **~2、集群伸缩~**Redis 集群提供了灵活的节点扩容和收缩方案。在不影响集群对外服务的情况下,可以为集群添加节点进行扩容也可以下线部分节点进行缩容。
#### 2.1、**槽和数据与节点的对应关系**当主节点分别维护自己负责的槽和对应的数据,如果希望加入1个节点实现集群扩容时,需要通过相关命令把一部分槽和数据迁移给新节点。
每个节点负责的槽和数据相比之前变少了从而达到了集群扩容的目的,集群伸缩=槽和数据在节点之间的移动。
### **2.2、扩容操作**扩容是分布式存储最常见的需求,Redis 集群扩容操作可分为如下步骤:
1)准备新节点。
2)加入集群。
3)迁移槽和数据。
2.2.1、准备新节点
需要提前准备好新节点并运行在集群模式下,新节点建议跟集群内的节点配置保持一致,便于管理统一。
### **2.2.2、加入集群**
通过 redis-trib.rb add-node 127.0.0.1:6397 127.0.0.1:6391 实现节点添加
要加入的节点 集群中的节点
docker run -itd --name redis-master4 -v /usr/docker/redis/config:/config --net redis-cluster_redis-master -e PORT=6397 -p 6397:6397 -p 16397:16397 --ip 172.50.0.5 redis-cluster
3. **迁移槽和数据**加入集群后需要为新节点迁移槽和相关数据,槽在迁移过程中集群可以正常提供读写服务,迁移过程是集群扩容最核心的环节,下面详细讲解。
槽是 Redis 集群管理数据的基本单位,首先需要为新节点制定槽的迁移计划,确定原有节点的哪些槽需要迁移到新节点。迁移计划需要确保每个节点负责相似数量的槽,从而保证各节点的数据均匀,比如之前是三个节点,现在是四个节点,把节点槽分布在四个节点上。
数据迁移过程是逐个槽进行的
流程说明:
1)对目标节点发送导入命令,让目标节点准备导入槽的数据。
2)对源节点发送导出命令,让源节点准备迁出槽的数据。
3)源节点循环执行迁移命令,将槽跟数据迁移到目标节点。
redis-trib 提供了槽重分片功能,命令如下:
redis-trib.rb reshard host:port --from --to --slots --yes --timeout --pipeline
### **3.1、迁移操作**redis-trib.rb reshard 127.0.0.1:6379
打印出集群每个节点信息后,reshard 命令需要确认迁移的槽数量,这里我们根据节点个数输入对应的值:
输入某个节点的节点 ID 作为目标节点,目标节点只能指定一个:
What is the receiving node ID xxxx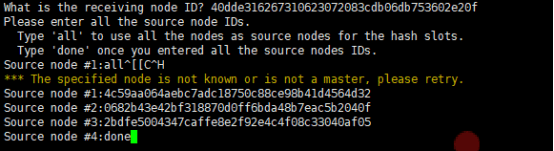
之后输入源节点的 ID,这里分别输入相应的节点 ID 最后用 done 表示结束:
数据迁移之前会打印出所有的槽从源节点到目标节点的计划,确认计划无误后输入 yes 执行迁移工作
redis-trib 工具会打印出每个槽迁移的进度:
查看节点的信息cluster-node
输入 redis-trib.rb rebalance ip:port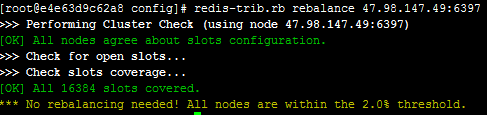
### **3.2、主从节点设置**扩容之初我们把6397、6398节点加入到集群,节点6397迁移了部分槽和数据作为主节点,但相比其他主节点目前还没有从节点,因此该节点不具备故障转移的能力。
这时需要把节点6398作为6397的从节点,从而保证整个集群的高可用。使用 cluster replicate{masterNodeId}命令为主节点添加对应从节点。(进入6398 的客户端,进行添加 redis-cli -h 116.255.176.221 -p 6398)
## **~4、收缩集群~**收缩集群意味着缩减规模,需要从现有集群中安全下线部分节点,下线节点过程如下:
1)首先需要确定下线节点是否有负责的槽,如果是,需要把槽迁移到其他节点,保证节点下线后整个集群槽节点映射的完整性。
2)当下线节点不再负责槽或者本身是从节点时,就可以通知集群内其他节点忘记下线节点,当所有的节点忘记该节点后可以正常关闭。
### 4.1、**下线迁移槽**下线节点需要把自己负责的槽迁移到其他节点,原理与之前节点扩容的迁移槽过程一致,但是过程收缩正好和扩容迁移方向相反,下线节点变为源节点,其他主节点变为目标节点,源节点需要把自身负责的4096个槽均匀地迁移到其他主节点上。
使用 redis-trib.rb reshard 命令完成槽迁移。由于每次执行 reshard 命令只能有一个目标节点,因此需要执行3次 reshard 命令
**删除节点**:redis-trib.rb del-none 116.255.176.223:6397
**节点槽数据迁移**:redis-trib.rb rebalance 116.255.176.223:6379
### **4.2、忘记节点**由于集群内的节点不停地通过 Gossip 消息彼此交换节点状态,因此需要通过一种健壮的机制让集群内所有节点忘记下线的节点。也就是说让其他节点不再与要下线节点进行 Gossip 消息交换。Redis 提供了 cluster forget{downNodeId}命令实现该功能,会把这个节点信息放入黑名单,但是60s之后会恢复。
生产环境当中使用redis-trib.rb del-node {host:port}{downNodeId}命令进行相关操作
注意: redis-trib rebalance 命令选择
适用于节点的槽不平衡的状态,有槽的节点
1、默认节点加入,要先做节点槽的迁移
2、节点已经迁移了所有的槽信息,并且已经从集群删除后,才可以使用平衡
查看当前节点的槽位:cluster slots09.docker-swarm集群部署、docker集群伸缩
Docker Machine 是 Docker 官方编排项目之一,负责在多种平台上快速安装 Docker 环境。
Docker Machine 是一个工具,它允许你在虚拟宿主机上安装 Docker Engine ,并使用 docker-machine 命令管理这些宿主机。你可以使用 Machine 在你本地的 Mac 或 Windows box、公司网络、数据中心、或像 阿里云 或 华为云这样的云提供商上创建 Docker 宿主机。
使用 docker-machine 命令,你可以启动、审查、停止和重新启动托管的宿主机、升级 Docker 客户端和守护程序、并配置 Docker 客户端与你的宿主机通信。
1、为什么要使用它?
在没有Docker Machine之前,你可能会遇到以下问题:
1、你需要登录主机,按照主机及操作系统特有的安装以及配置步骤安装Docker,使其能运行Docker容器。
2、你需要研发一套工具管理多个Docker主机并监控其状态。
Docker Machine的出现解决了以上问题。
1、Docker Machine简化了部署的复杂度,无论是在本机的虚拟机上还是在公有云平台,只需要一条命令便可搭建好Docker主机
2、Docker Machine提供了多平台多Docker主机的集中管理部署
3、Docker Machine 使应用由本地迁移到云端变得简单,只需要修改一下环境变量即可和任意Docker主机通信部署应用。
Docker的组成:
1、Docker daemon
2、一套与 Docker daemon 交互的 REST API
3、一个命令行客户端
哨兵监控redis主从,当主redis挂掉,在哨兵选举主服务器时,数据无法写入进去。写进去数据可能丢失了,客户端根据错误做有限次数的重试。
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: