
Redis In Action 笔记(四):数据安全和性能优化
0 / 2 / 创建于 6年前 /
 tsin 的个人博客
tsin 的个人博客
文中的例子均使用python编写
持久化数据到磁盘
- RDB 快照(snapshotting)
-
AOF(append-only file)
作用:用于恢复数据,保存计算属性等
快照持久化
选项
save 60 1000 # 60秒有1000次写入触发 stop-writes-on-bgsave-error no rdbcompression yes dbfilename dump.rdb # 保存的文件名 dir ./ # 文件路径创建快照方法
- 客户端发送BGSAVE命令(不支持windows)
- 使用SAVE命令
- 配置save选项:比如 save 60 10000,表示从最近一次创建快照之后算起,60秒内有10000次写入,Redis就会触发BGSAVE命令
- Redis接到SHUTDOWN/TERM命令时,会执行一个SAVE命令
-
Redis之间复制的时候(参考4.2节)
系统崩溃后,会丢失最近一次快照生成之后的数据,因此适用于丢失一部分数据也无所谓的情况。(不能接受数据丢失,则使用AOF)
每GB的数据,大概耗时10-20ms,数据较大时会造成Redis停顿,可以考虑关闭自动保存,手动发送BGSAVE或SAVE来持久化
SAVE命令不需要创建子进程,效率比BGSAVE高,可以写一个脚本在空闲时候生成快照(如果较长时间的数据丢失可以接受)
AOF 持久化
将被执行的命令写到AOF文件末尾,因此AOF文件记录了数据发生的变化,只要重新执行一次AOF文件中的命令,就可以重建数据
选项
appendonly no # 是否打开AOF # 同步频率选项: # 1. no(由操作系统决定), # 2. everysec(每秒,默认,和不开启持久化性能相差无几), # 3. always(每个命令,产生大量写操作,固态硬盘慎用,会大大降低硬盘寿命) appendfsync everysec # 重写AOF的时候是否阻塞append操作 no-appendfsync-on-rewrite no # 自动执行配置:文件大于64mb且比上一次重写之后至少大了一倍时执行 auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb重写/压缩AOF文件
- 手动执行:发送BGREWRITEAOF来移除冗余命令,与BGSAVE原理相似,会创建一个子进程来处理
- 自动执行:配置auto-aof-rewrite-percentage和auto-aof-rewrite-min-size来自动执行
总结:通过持久化,保证系统重启或者系统崩溃的情况下仍然能保留数据。当系统负载量上升,数据完整性变得越来越重要,这时可考虑Redis的复制特性。
复制
选项配置
- 确保主服务器正确设置了dir和dbfilename选项,并且对Redis可写
- 设置主服务器的选项:slaveof,比如slaveof host port
- 可以手动发送slaveof no one来终止复制操作,或者slaveof host port来开始从主服务器复制
新版redis(2.8以后),当主从服务器中途断开时,采用增量复制,效率更高,参考:http://copyfuture.com/blogs-details/365aec...
主从链(略)
检验磁盘写入
- 检验是否同步成功:通过主服务器构造一个唯一标识,检验是否同步到从服务器
- 从服务器检验是否成功持久化到磁盘:对于每秒同步一次的AOF文件,可以通过等待一秒或者检验aof_pending_bio_fsync等于0来判断写入成功
实现代码和详解:
import redis
import time
mconn = redis.Redis(host='127.0.0.1', port=6379)
sconn = redis.Redis(host='127.0.0.1', port=6380)
# mconn 主服务器连接对象
# sconn 从服务器连接对象
def wait_for_sync(mconn, sconn):
# 生成一个唯一标识
identifier = str(uuid.uuid4())
# 将这个唯一标识(令牌)添加到主服务器
mconn.zadd('sync:wait', identifier, time.time())
# 等待主从复制成功
# master_link_status = up 代表复制成功
# 等同于 while sconn.info()['master_link_status'] = 'down'
# 即同步为完成时,继续等待,每隔1ms判断一次
while not sconn.info()['master_link_status'] != 'up':
time.sleep(.001)
# 从服务器还没有接收到主服务器的同步时(无identifier),继续等待
while not sconn.zscore('sync:wait', identifier):
time.sleep(.001)
dealine = time.time() + 1.01 # 最多只等待1s
while time.time() < dealine:
# 注意AOF开启时,才有aof_pending_bio_fsync选项
# 等于0说明没有fsync挂起的任务,即写入磁盘已完成
if sconn.info()['aof_pending_bio_fsync'] == 0:
break
time.sleep(.001)
# 从服务器同步到磁盘后完成后,主服务器删除该唯一标识
mconn.zrem('sync:wait', identifier)
# 删除15分钟前可能没有删除的标识
mconn.zremrangebyscore('sync.wait', time.time() - 900)处理系统故障
检验快照文件和AOF文件
- redis-check-aof [--fix] ,会删除出错命令及其之后的命令
- redis-check-dump 出错无法修复,最好多备份
更换故障服务器
假设有A、B两台Redis服务器,A为主,B为从,A机器出现故障,使用C作为新的服务器。更换方法:向B发送一个SAVE命令创建快照文件,发送给C,最后让B成为C的从服务器。此外,还要更新客户端配置,让程序读写正确的服务器。
Redis事务
Redis处理事务的命令:MULTI、EXEC、DISCARD、WATCH、UNWATCH。
与传统关系型数据库的事务之区别:传统关系型数据库事务:BEGIN-->执行操作-->COMMIT确认操作-->出错时可以ROLLBACK;Redis事务:MULTI开始事务-->添加多个命令-->EXEC执行,EXEC之前不会有任何实际操作。
例子
游戏网站的商品买卖市场,玩家可以在市场里销售和购买商品。
数据结构
-
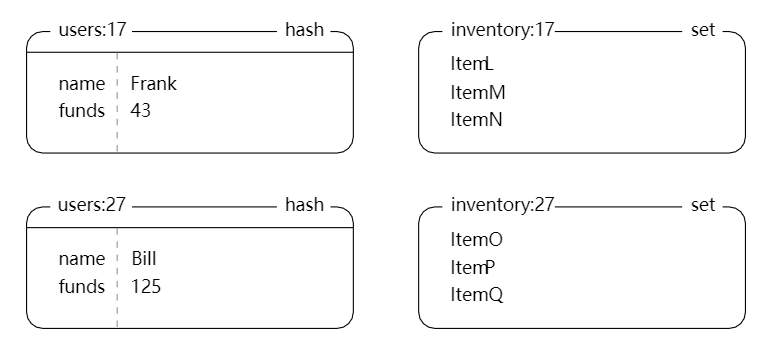
用户信息
hash,记录用户名和余额 -
存量
set,记录包含的商品编号 -
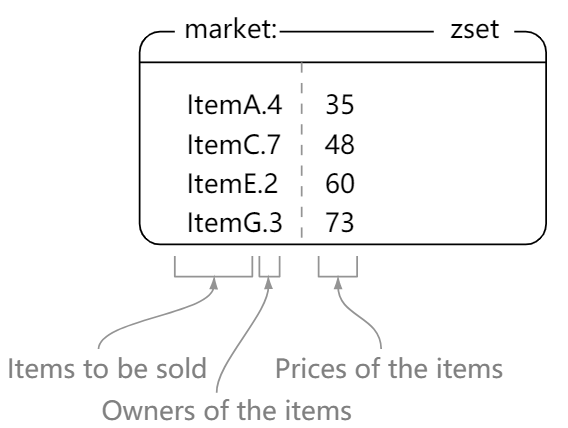
市场
zset,商品名.拥有者-->价格
实现逻辑
不同于传统关系型数据库,事务操作的时候会对数据进行加锁,Redis事务操作只会在数据被其他客户端抢先修改的情况下,通知执行了WATCH命令的客户端,这时事务操作失败,客户端可以选择重试或者中断操作——这种做法称之为乐观锁。
-
连接
import redis import time conn = redis.Redis(host='127.0.0.1', port=6379) -
将商品放到市场上销售
def list_item(conn, itemid, sellerid, price): inventory = "inventory:%s"%sellerid # inventory key item = "%s.%s"%(itemid, sellerid) # item key end = time.time() + 5 pipe = conn.pipeline() while time.time() < end: try: pipe.watch(inventory) # 监视库存变化 if not pipe.sismember(inventory, itemid): # 如果库存中没有该商品 pipe.unwatch() # 取消监控 return None pipe.multi() # 开启事务 pipe.zadd("market:", item, price) # 添加商品到市场 pipe.srem(inventory, itemid) # 从库存中删除商品 pipe.execute() # 执行事务 return True // WATCH和EXEC之间所监控的inventory已经发生变化 // 这时事务执行失败,抛出WatchError // 这里不做任何处理,5s内会继续while循环 except redis.exceptions.WatchError: pass return False -
购买商品
def purchase_item(conn, buyerid, itemid, sellerid, lprice): buyer = "users:%s"%buyerid # 当前买家 seller = "users:%s"%sellerid # 当前卖家 item = "%s.%s"%(itemid, sellerid) # 市场market上商品的key inventory = "inventory:%s"%buyerid # 买家用户商品库存 end = time.time() + 10 pipe = conn.pipeline() while time.time() < end: try: pipe.watch("market:", buyer) # 监控当前市场和当前买家 price = pipe.zscore("market:", item) # 商品价格 funds = int(pipe.hget(buyer, "funds")) # 当前买家余额 if price != lprice or price > funds: # 当前价格是否发生变化或买家余额不足 pipe.unwatch() # 取消监控 return None # 购买失败 pipe.multi() # 开启事务 pipe.hincrby(seller, "funds", int(price)) # 卖家余额增加 pipe.hincrby(buyer, "funds", int(-price)) # 买家余额减少 pipe.sadd(inventory, itemid) # 将添加该商品到买家库存 pipe.zrem("market:", item) # 删除市场中的该商品 pipe.execute() # 执行事务 return True # 成功完成一次买卖过程 // WATCH失败,即在WATCH和EXEC之间监控的KEY发生了改变 // 10s内会继续while循环重试 except redis.exceptions.WatchError: pass return False # 购买失败
非事务型流水线(pipeline)
需要执行大量操作且不需要事务的时候(事务会消耗资源)
pipe = conn.pipeline()传入True或者不传入参数,表示事务型操作
将2.5节的update_token改造为非事务型流水线操作
-
改造前
# 需要2-5次通信往返 # 假如每次通讯耗时2毫秒,则执行一次update_token要4-10毫秒 # 那么每秒可以处理的请求数为100-250次 def update_token(conn, token, user, item=None): timestamp = time.time() conn.hset('login:', token, user) # 1 conn.zadd('recent:', token, timestamp) # 2 if item: conn.zadd('viewed:' + token, item, timestamp) # 3 conn.zremrangebyrank('viewed:' + token, 0, -26) # 4 conn.zincrby('viewed:', item, -1) # 5 -
改造后
# 只要一次通信 # 通信往返次数减少到原来的1/2-1/5 # 每秒处理请求数可以到500次 def update_token_pipeline(conn, token, user, item=None): timestamp = time.time() pipe = conn.pipeline(False) # 非事务型流水线操作 pipe.hset('login:', token, user) pipe.zadd('recent:', token, timestamp) if item: pipe.zadd('viewed:' + token, item, timestamp) pipe.zremrangebyrank('viewed:' + token, 0, -26) pipe.zincrby('viewed:', item, -1) pipe.execute() # 执行添加的所有命令
性能测试及注意事项
- 测试命令:redis-benchmark -c 1 -q
-q 表示简化输出结果
-c 1 表示使用一个客户端
结果大概如下所示:
.
.
.
PING (inline): 34246.57 requests per second
PING: 34843.21 requests per second
MSET (10 keys): 24213.08 requests per second
SET: 32467.53 requests per second
.
.
.
LRANGE (first 100 elements): 22988.51 requests per second
LRANGE (first 300 elements): 13888.89 requests per second
.
.
.- 结果分析及解决方法:
| 性能或错误 | 可能原因 | 解决方法 |
|---|---|---|
| 单个客户端性能达到redis-benchmark的50%-60% | 不使用pipeline时预期性能 | 无 |
| 单个客户端性能达到redis-benchmark的25%-30% | 对每个/每组命令都创建了新的连接 | 重用已有的Redis连接 |
| 客户端错误:Cannot assign requested address | 对每个/每组命令都创建了新的连接 | 重用已有的Redis连接 |
参考资料:
本作品采用《CC 协议》,转载必须注明作者和本文链接




 关于 LearnKu
关于 LearnKu




推荐文章: