
Redis In Action 笔记(五):使用 Redis 支持应用程序
0 / 0 / 创建于 7年前 /
 tsin 的个人博客
tsin 的个人博客
记录日志
记录最近日志
# 思路:将日志加入list,然后修剪到规定大小
def log_recent(conn, name, message, severity=logging.INFO, pipe=None):
severity = str(SEVERITY.get(severity, severity)).lower()
# 日志的KEY,构成:recent:日志名称:日志级别
destination = 'recent:%s:%s'%(name, severity)
message = time.asctime() + ' ' + message # 日志信息前面添加时间信息
pipe = pipe or conn.pipeline()
pipe.lpush(destination, message) # 1. 加入list
pipe.ltrim(destination, 0, 99) # 2. 截取最近100条记录
pipe.execute() # 执行以上两步
# 运行:log_recent(conn, 'test', 'test_msg')
# 结果:(key)recent:test:info (value)Sun Jun 23 11:57:38 2019 test_msg 记录常见日志
记录出现频率较高的日志,每小时进行一次轮换
# 思路:消息作为成员记录到有序集合,消息出现频率作为成员的分值(score)
# 记录的时间范围为1小时,记录的时候发现已经过了一小时,
# 则把已有的记录归档到上一小时(通过把KEY重命名来实现)
# 则新的一小时消息频率有从0开始记录
# 用于记录的KEY:[common:日志名称:日志级别]
def log_common(conn, name, message, severity=logging.INFO, timeout=5):
severity = str(SEVERITY.get(severity, severity)).lower()
destination = 'common:%s:%s'%(name, severity)
#当前所处小时数
start_key = destination + ':start' # common:日志名称:日志级别:start
pipe = conn.pipeline()
end = time.time() + timeout
while time.time() < end:
try:
pipe.watch(start_key)
# datetime(*now[:4]).isoformat() --> '2019-06-23T06:00:00'
now = datetime.utcnow().timetuple()
# 简单获取小时数(原书方法行不通,这里加以修改)
hour_start = now.tm_hour
# 获取[common:日志名称:日志级别:start]的值
# 这里返回字符串类型,注意转为整型
existing = pipe.get(start_key)
pipe.multi()
# 如果值存在 且 小于当前小时数
if existing and int(existing) < hour_start:
# 进行归档
# KEY [common:日志名称:日志级别] 重命名为 [common:日志名称:日志级别:last]
pipe.rename(destination, destination + ':last')
# KEY [common:日志名称:日志级别:start] 重命名为 [common:日志名称:日志级别:pstart]
pipe.rename(start_key, destination + ':pstart')
# 之前的KEY已经归档,这里是新的
pipe.set(start_key, hour_start)
# 不存在则添加该日志开始时间记录
elif not existing:
# KEY [common:日志名称:日志级别:start] 的值设置为当前小时数
pipe.set(start_key, hour_start)
# 对有序集合destination的成员message自增1
# 注意:zincrby在redis-py3.0+的用法
pipe.zincrby(destination, 1, message)
# 记录到最新日志
log_recent(pipe, name, message, severity, pipe)
return
# 如果其他客户端刚好有操作,修改了watch的key,进行重试
except redis.exceptions.WatchError:
continue
# 运行
log_common(conn, 'test', 'msg')
#结果
#(zset)common:test:info msg --> 1
# -->1小时后再次记录日志的话,该KEY就会变成common:test:info:last
#(string)common:test:info:start 14(小时数)
# -->1小时后再次记录日志的话,该KEY就会变成common:test:info:pstart
#(list)recent:test:info Wed Jun 26 22:53:17 2019 msg计数器
记录,比如,1秒钟、5秒钟……页面点击数,下图为5秒钟点击计数器,类型为hash,各键值对为 [ 时间戳:点击数 ]。
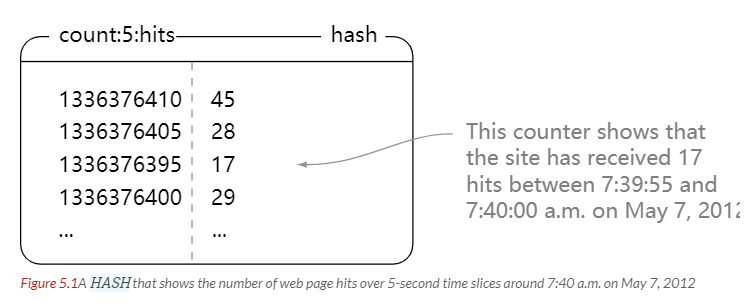
[know:]有序聚合用于清理旧数据时,按精度大小顺序逐个迭代计数器。
更新计数器
# 以秒为单位的计数器精度
PRECISION = [1, 5, 60, 300, 3600, 18000, 86400]
QUIT = False
SAMPLE_COUNT = 100
# 实现:获取每个时间片段的开始时间,将次数统计到每个时间段的开始时间
def update_counter(conn, name, count=1, now=None):
now = now or time.time() # 当前时间
pipe = conn.pipeline()
for prec in PRECISION:
pnow = int(now / prec) * prec # 获取当前时间片的开始时间
hash = '%s:%s'%(prec, name) # 创建存储计数信息的hash
# zadd在redis-py 3.0之后更改了,第二个参数应该传入一个字典 √
# pipe.zadd('known:', hash, 0) ×
# 有序集合,用于后期可以按顺序迭代清理计数器(并不使用expire,因为expire只能对hash整个键过期)
# 这里可以组合使用set和list,但用zset,可以排序,又可以避免重复元素
# **这个zset的score值都是0,所以最后排序的时候按member字符串的二进制来排序**
pipe.zadd('known:', {hash: 0}) # 这个记录在后面的清理程序有用
pipe.hincrby('count:' + hash, pnow, count) # 更新对应精度时间片的计数
pipe.execute()获取计数器
def get_counter(conn, name, precision):
hash = '%s:%s'%(precision, name) # 要获取的hash的key
data = conn.hgetall('count:' + hash)
to_return = []
for key, value in data.items():
to_return.append((int(key), int(value)))
to_return.sort()
return to_return清理计数器
计数器中的元素随着时间的推移越来越多,需要对其定期清理,保持合理的数量,以减少内存消耗。
# 清理规则: 1s,5s计数器,1min清理一次
# 后面的,5min计数器5min清理一次,以此类推
def clean_counters(conn):
pipe = conn.pipeline(True)
passes = 0
# 按时间片段从小到大迭代已知的计数器
while not QUIT:
start = time.time()
index = 0
while index < conn.zcard('known:'):
# 取出有序集合的一个元素(打印hash,发现返回的是一个byte类型)
hash = conn.zrange('known:', index, index)
index += 1
if not hash:
break
hash = hash[0]
# 得到时间精度
prec = int(hash.partition(b':')[0])
# 按上面说明的清理规则计算时间间隔
# 小于60s的计数器至少1min清理一次
bprec = int(prec // 60) or 1 # '//'操作是取整除法
# 实现几分钟清理一次的逻辑
# 不整除的时候continue --> 重新while循环
# 比如,1分钟,每次都整除,所以每次判断后后执行continue下面的语句
# 10分钟,要等10次到passes=10才整除
if passes % bprec: #
continue
# 清理逻辑开始
hkey = 'count:' + hash.decode('utf-8') # 注意将byte转换成str,书中没有转换
# 根据要保留的个数*精度,计算要截取的时间点
cutoff = time.time() - SAMPLE_COUNT * prec
# python3的map返回可迭代对象而不是list,原书的这句需要加上list转换
samples = list(map(int, conn.hkeys(hkey)))
samples.sort()
# 二分法找出cutoff右边的位置(index)
remove = bisect.bisect_right(samples, cutoff)
# 如果有需要移除的
if remove:
# 删除0-remove位置的元素
conn.hdel(hkey, *samples[:remove])
# 判断是否全部被移除
if remove == len(samples):
try:
pipe.watch(hkey)
# 再次确保hash中已经没有元素
if not pipe.hlen(hkey):
pipe.multi()
# 同时将known:中的相应元素移除
pipe.zrem('known:', hash)
pipe.execute()
# 减少了一个计数器
index -= 1
else:
pipe.unwatch()
except redis.exceptions.WatchError:
pass
# 累计次数,直到整除,才开始清理程序
passes += 1
# 以下两句保证一次while循环时间是1min
# 计算程序运行时间,且保证至少1s,最多是1min
duration = min(int(time.time() - start) + 1, 60)
# 休息,时间为:1min减去程序运行时间,也即1min中剩余的时间,且保证至少是1s
time.sleep(max(60 - duration, 1)) 统计数据

# 将所有统计量放在一个有序集合里
def update_stats(conn, context, type, value, timeout=5):
destination = 'stats:%s:%s'%(context, type)
start_key = destination + ':start'
pipe = conn.pipeline(True)
end = time.time() + timeout
while time.time() < end:
try:
pipe.watch(start_key)
now = datetime.utcnow().timetuple()
hour_start = now.tm_hour
existing = pipe.get(start_key)
pipe.multi()
if existing and existing < hour_start:
pipe.rename(destination, destination + ':last')
pipe.rename(start_key, destination + ':pstart')
pipe.set(start_key, hour_start)
# 以上部分跟记录常见日志一样
tkey1 = str(uuid.uuid4())
tkey2 = str(uuid.uuid4())
# 这里比较巧妙地统计到最大值和最小值
# 构造两个有序集合,成员为min、max,score为要统计的值
# 然后跟目标集合求并集,聚合方式为min、max
pipe.zadd(tkey1, {'min': value})
pipe.zadd(tkey2, {'max': value})
pipe.zunionstore(destination,
[destination, tkey1], aggregate='min')
pipe.zunionstore(destination,
[destination, tkey2], aggregate='max')
pipe.delete(tkey1, tkey2)
pipe.zincrby(destination, 1, 'count') # +1
pipe.zincrby(destination, value, 'sum') # 总和
pipe.zincrby(destination, value*value,'sumsq') #平方和
return pipe.execute()[-3:]
except redis.exceptions.WatchError:
continue
# 计算平均值、方差
def get_stats(conn, context, type):
key = 'stats:%s:%s'%(context, type)
data = dict(conn.zrange(key, 0, -1, withscores=True))
data['average'] = data['sum'] / data['count']
numerator = data['sumsq'] - data['sum'] ** 2 / data['count']
data['stddev'] = (numerator / (data['count'] - 1 or 1)) ** .5
return data 完整代码:
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: