
python 爬虫 mc 皮肤站 little skin 的简单爬取
0 / 3 / 创建于 6年前 /
 Coolest 的个人博客
Coolest 的个人博客
首先,找到一个皮肤网站,其中一个著名的皮肤网站就是https://littleskin.cn 。进入网站,我们就会见到一堆皮肤,这就是今天我们要爬的皮肤。给各位分享一下代码。
import requests
import re
import time
import json
download_sucess = True
time.sleep(1.5)
pictures = input('你想下载多少张皮肤:')
while pictures.isdigit() == False:
print("请输入数字!")
pictures = input('你想下载多少张皮肤:')
Path = input('请输入保存的路径:')
print("请稍等......")
pictures = int(pictures)
for i in range(1,pictures+1):
url = 'https://littleskin.cn/skinlib/data?filter=skin&uploader=0&sort=likes&keyword=&page=' + str(i)
response = requests.get(url).json()
ids = re.findall("'tid': (.*?),",str(response))
for id in ids:
picture_url = 'https://littleskin.cn/preview/' + id + '.png'
picture_name = picture_url.strip('https://littleskin.cn/preview/')
picture = requests.get(picture_url).content
try:
with open(Path + '//%s'%picture_name,'wb') as file:
file.write(picture)
except FileNotFoundError:
download_sucess = False
print('路径不存在!')
break
if download_sucess == False:
print("下载失败!")
elif download_sucess == True:
print('下载完成!')最终效果: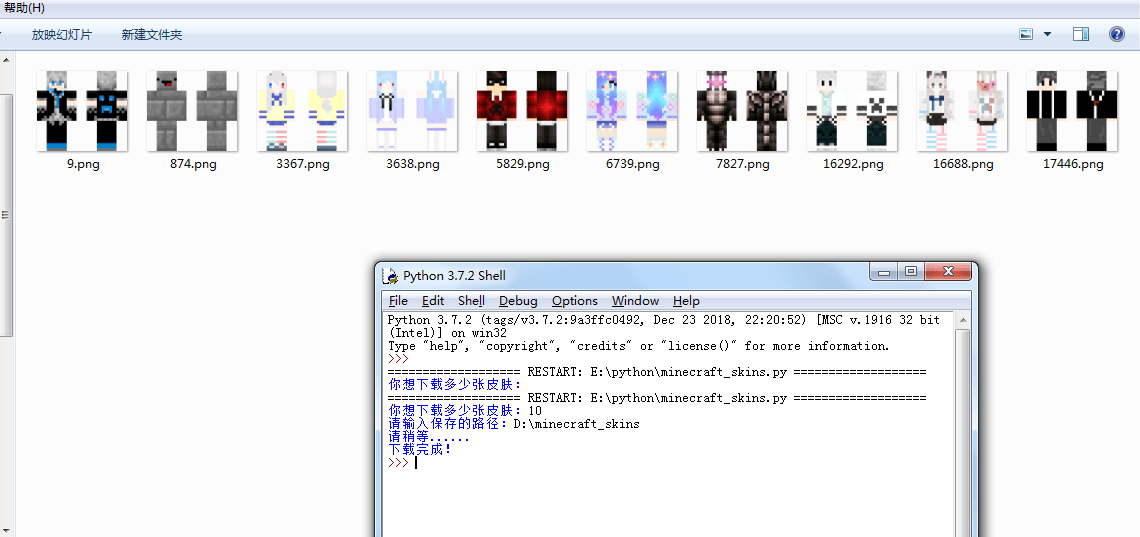
皮肤爬取的原理是通过json格式来查看网站的每一张图片的id号,再用拼接的方式组成一个图片地址,最后再用二进制的方式把图片存放在我们的文件夹里。希望各位能通过这篇文章学到东西。
本作品采用《CC 协议》,转载必须注明作者和本文链接
喜欢的朋友点个赞吧!









 关于 LearnKu
关于 LearnKu




{kind=link}
推荐文章: