
为什么所有的查询条件都命中索引还是那么慢?记一次慢查询优化过程
3 / 1 / 创建于 6年前 /
 jeremy1127 的个人博客
jeremy1127 的个人博客
引子
话说,自从前段时间用granafa配好后端微服务prometheus监控的Dashboard后,我就有了一个新习惯,每天上班第一件事就是盯着这个Dashboard瞅一会儿。
你还别说,很快我就发现了问题,一些名字看似不复杂的查询接口,却慢到要2到3秒,这是很不正常的。
于是,我就是这样盯上了一个接口。
排查过程
这是一个查询文章列表的接口,支持分页,最终执行的SQL如下:
SELECT DISTINCT
C.*,
B.nickname,
D.feed_id,
D.home_feed,
D.read_scope,
D.publish_time
FROM
XXcloud.mp_pubno_info A,
XXcloud.wechat_pubno B,
XXcloud.wechat_article C
LEFT JOIN
XXcloud.mp_feed_info D ON D.element_id = C.article_id
AND D.element_type = 3
AND D.valid = 1
AND D.app_id = 'pf'
WHERE
A.app_id = 'pf' AND A.pubno = C.pubno AND A.pubno = B.pubno
ORDER BY C.create_time DESC
LIMIT 0 , 20咋一看这么多表联查,还有一个左联接,心想能快就奇怪了!
一开始真不想理这段sql的业务逻辑,就快速用工具分析了一下查询计划,想着如果是没加索引,那偷个懒:)加个索引就好了。
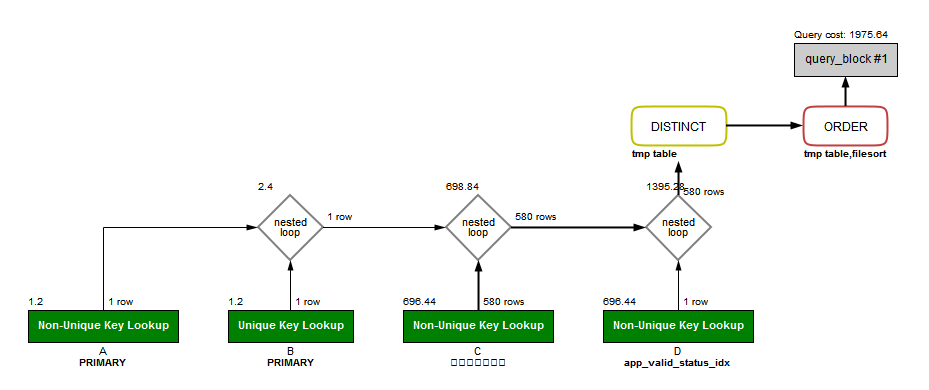
结果一看,竟然全部都命中索引了… >_<!!!
心想有点麻烦呀,没办法只能耐着性子一点点看起。
首先,对于select部分,因为是C表在左的左联,那么distinct关键字是明显不需要的。但是去掉后,也没有快太多。
接着,因为个人风格偏好,内联查询更喜欢写inner join on,于是,我把sql的from和where整理了一下,虽然看起来规整些,但并无任何提升。
这时,我把注意力转移到limit部分,心想如果能早点做limit,这样就可以减少表联接笛卡尔积的集合大小。
突破口就在这里!
当我把sql调整成,
SELECT
C.*, B.nickname,
D.feed_id,
D.home_feed,
D.read_scope,
D.publish_time
FROM
XXcloud.wechat_article C
INNER JOIN (
SELECT
C2.article_id
FROM
XXcloud.mp_pubno_info A
INNER JOIN XXcloud.wechat_article C2 ON A.app_id = 'sc'
AND A.pubno = C2.pubno
ORDER BY
C2.create_time DESC
LIMIT 20
) ai ON C.article_id = ai.article_id
INNER JOIN XXcloud.wechat_pubno B ON C.pubno = B.pubno
LEFT JOIN XXcloud.mp_feed_info D ON D.valid = 1
AND D.app_id = 'sc'
AND D.element_type = 3
AND D.element_id = C.article_id
ORDER BY
C.create_time DESC再分析一下查询计划,
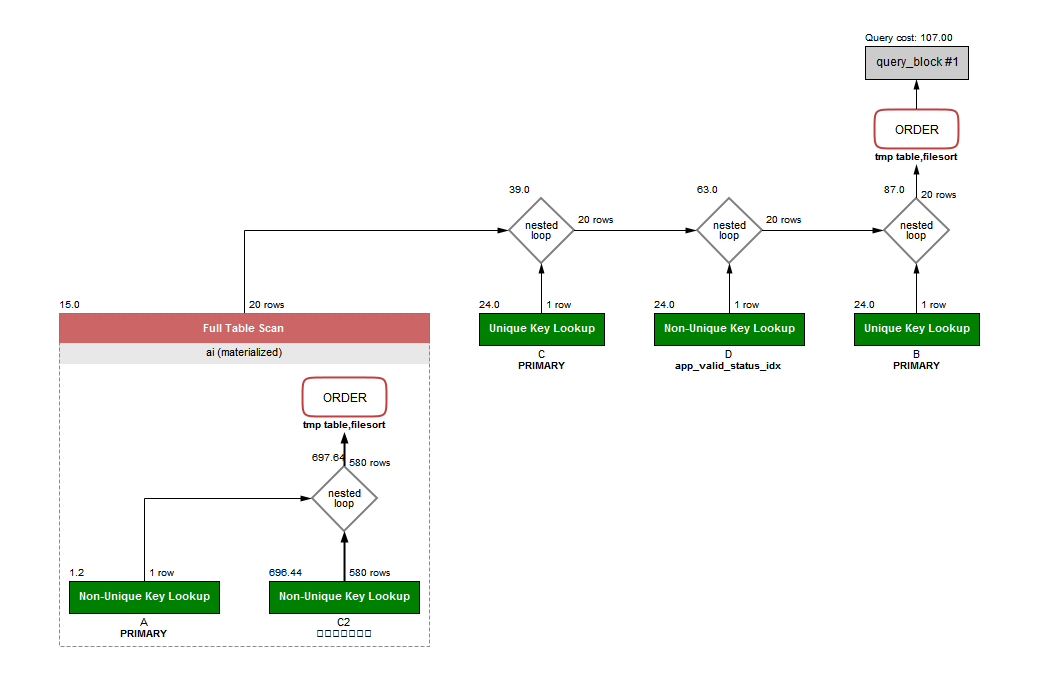
清爽的看到query cost从1975降到107!
但还有优化空间,在这里为了能够一句sql实现查询,使用了临时表,实际上是可以在代码中通过两次查询,一次查询出前20的article_id, 第二次查询时,直接把这20个article_id当成in的命中条件即可。
总结与反思
话说,这次排查慢sql,打破了我原有的一个认知偏误,以为命中了索引查询速度就不会慢;同时也让我加深了对左联加内联查询性能消耗的认识,左联真心是拖油瓶,本质上还是会将一个表的数据全部查出,如果这个表的数据还是逐渐增加的,那么上了生产环境变慢是必然的。
值得反思的是,目前公司项目的后端是使用的微服务架构,但涉及到数据库查询方面还是比较随便,同库的表连接也许还可以接受,跨库的表连接实在是后患无穷。
我能想到的未来改进方向是:
- 要么是加索引,不断优化查询计划;
- 要么就是严格限制单表查询,在代码中完成联接等操作,方便以后分库分表的扩展;
- 特别复杂的需要group by的查询考虑场景做离线的ETL,或者用引入ELK。
最后,各位看官,关于数据库应用查询方面的优化,你们有什么好的实战经验可以分享一下吗?
本作品采用《CC 协议》,转载必须注明作者和本文链接








 关于 LearnKu
关于 LearnKu




推荐文章: