
Redis 主从复制详细解读
0 / 1 / 创建于 6年前 /
 周小帅 的个人博客
周小帅 的个人博客
单台 redis 面临的问题
在实际场景中,单一节点的 redis 容易面临风险
-
机器故障
- 我们部署到一台 redis 服务器,当发生机器故障时,需要迁移到另一台服务器并且要保证数据是同步的,而数据是最重要的。单台机器无法保证数据的安全
-
容量瓶劲
- 当我们有需求需要扩容 redis 内存时,从16G 内存升级到 64G,单机肯定是满足不了,除非重新买一个128G的机器
-
总结
- 要实现分布式数据库更大的存储容量和承受高并发访问量,我们会将原来集中式数据库的数据分别存储到其他多个网络节点上
- Redis 为了解决这个单一节点的问题,也会把数据复制多个副本部署到其他节点上进行复制,实现 Redis 的高可用,实现对数据的冗余备份,从而保证数据和服务的高可用
什么是主从复制
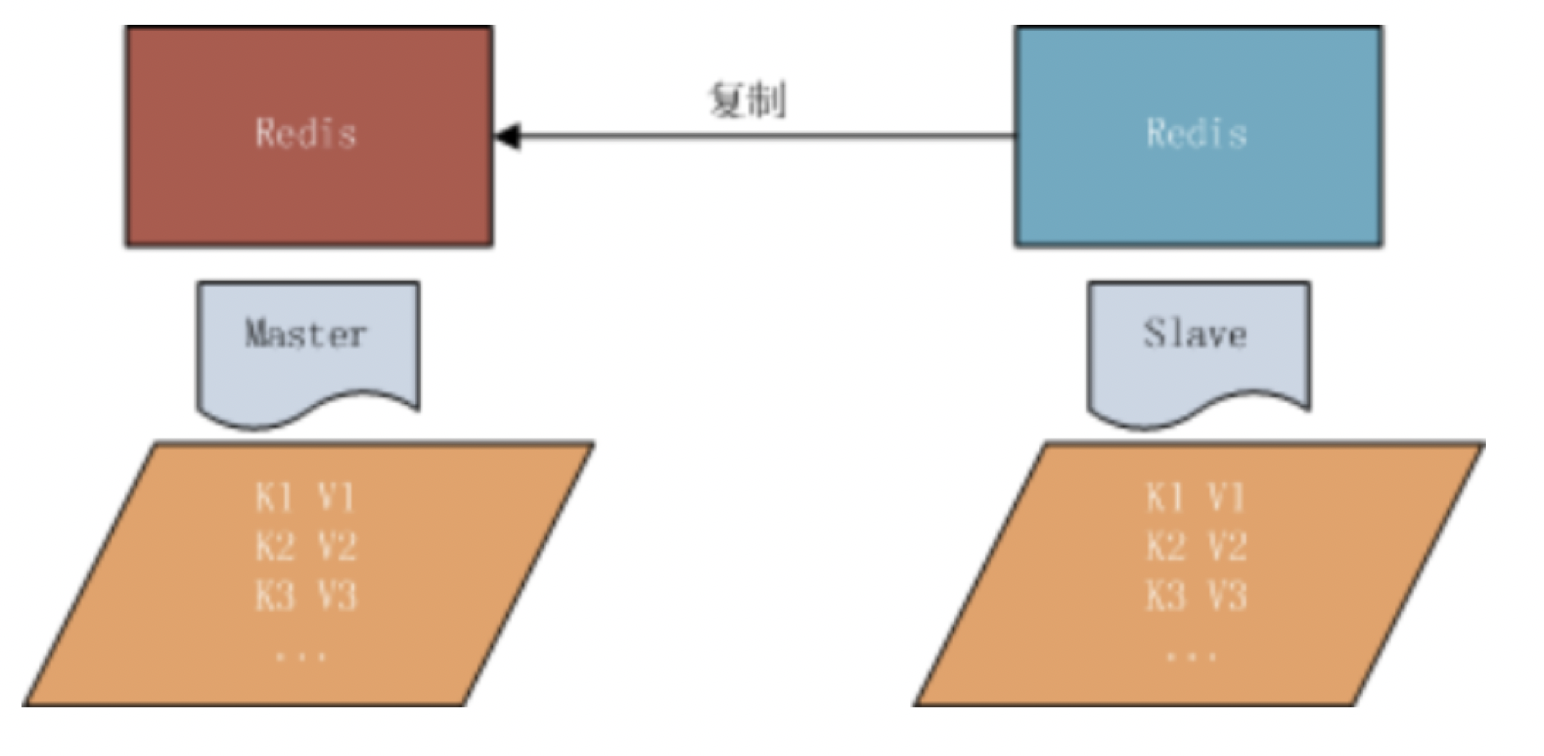
- 主从复制,是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器,前者成为 master 主节点,后者成为 slave 从节点,数据的复制是单向的,只能由主节点到从节点。
- 默认情况下,每台 redis 服务器都是主节点,且一个主节点可以有多个从节点,但一个从节点只能有一个主节点
主从复制的作用
数据冗余
- 主从复制实现了数据的热备份,是持久化之外的另一种数据冗余方式
故障恢复
- 当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复,实际上是一种服务的冗余
负载均衡
- 在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务。「即写 Redis 数据时应用连接主节点,读 Redis 数据时应用连接从节点」分担服务器负载,尤其是在 「写少读多」 的场景下,通过多个从节点分担读负载,可以大大提高 Redis 服务器的并发量
读写分离
- 可以用于实现读写分离,主库写,从库读,读写分离不仅可以提高服务器的负载能力,同时可根据需求的变化,改变从库的数量
高可用的基石
- 除了上述的作用外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是 Redis 高可用的基石
主从复制启用
从节点开启主从复制,有3中方式
-
配置文件
- 在从服务器的配置文件中加入: slaveof
-
启动命令
- redis-server 启动命令后加上 --slaveof
-
客户端命令
- Redis 服务器启动后,直接通过客户端执行命令 slaveof 则该Redis实例成为从节点
查看复制信息
- 通过 info replication 命令可以看到复制的一些信息
配置文件中注意事项
- 查看 LOG 文件位置
- 保护模式
- 密码配置
主从复制原理
-
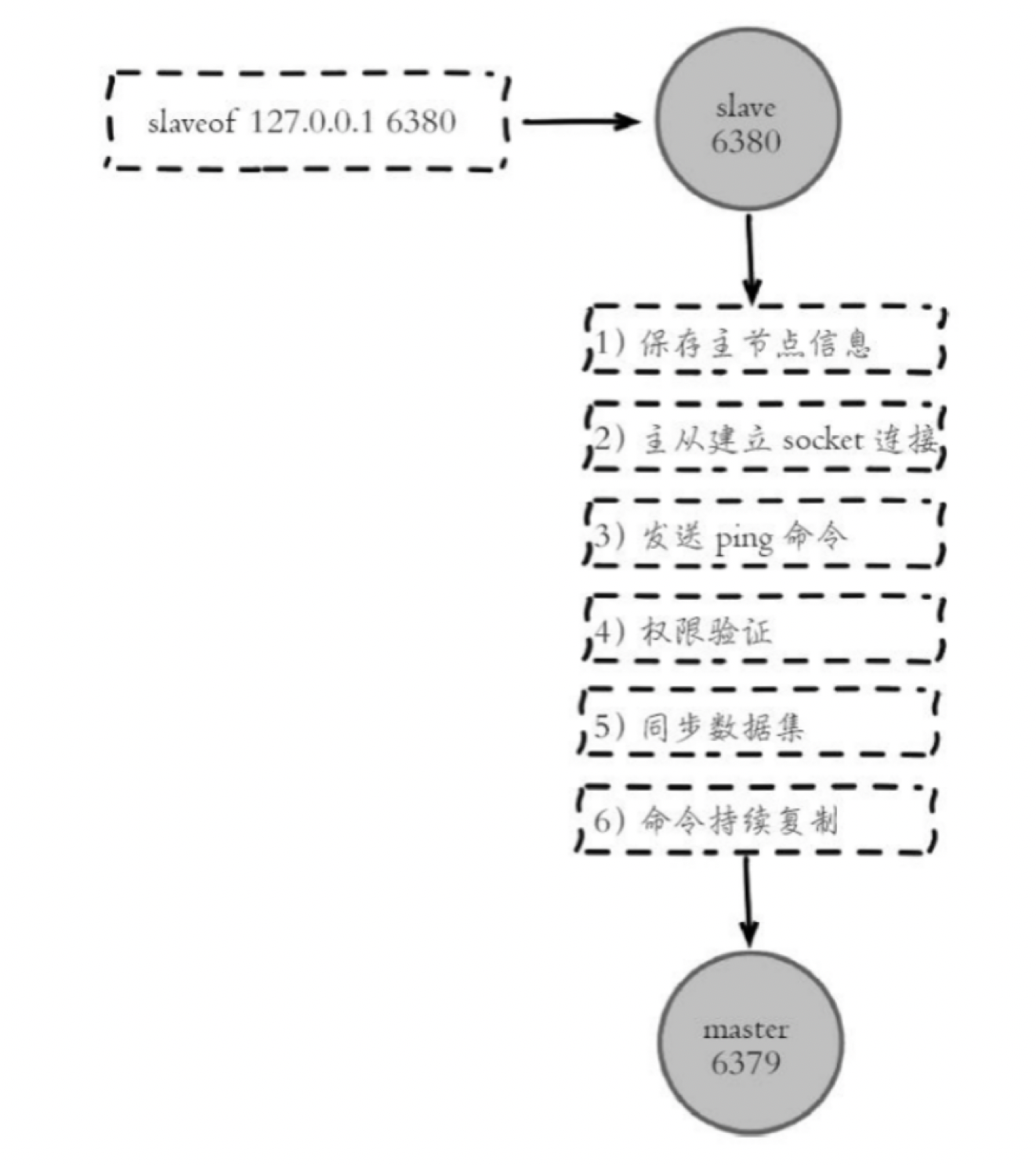
主从复制大体分为3个步骤:
1.连接建立阶段「准备阶段」
2.数据同步阶段
3.命令传播阶段
-
从节点执行 slaveof 命令后,会进行以下步骤进行复制
-
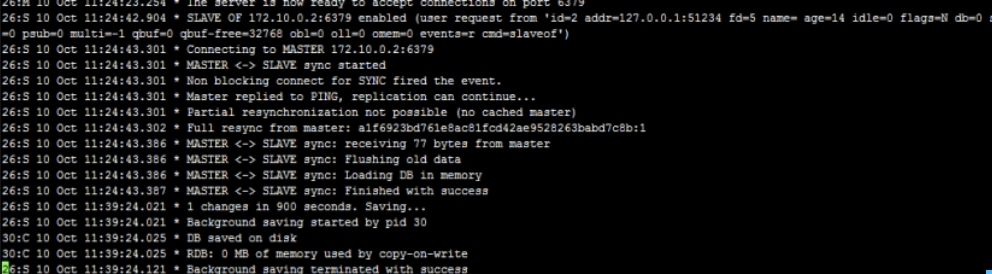
主从配置信息之后的日志记录也可以看出以上流程
- 保存主节点信息
-
执行 slaveof 后,redis 会打印以下日志信息\

-
主从节点建立 socket 连接
-
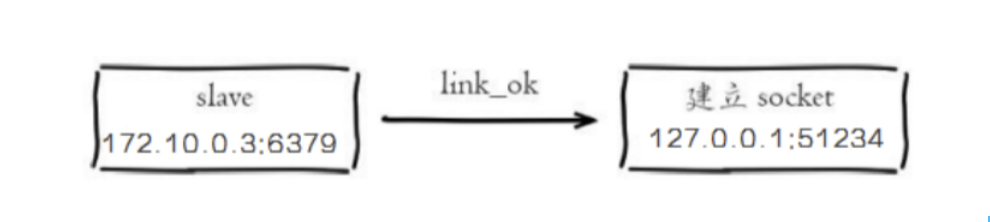
从节点通过内部运行定时任务,维护复制相关逻辑,当定时任务发现新的主节点后,会尝试与该节点进行网络连接
-
从节点与主节点建立网络连接\
-
从节点会建立一个 socket 套接字,然后建立一个端口为 51234 的套接字,专门用户接收主节点发送的复制命令,从节点建立连接后的日志\

-
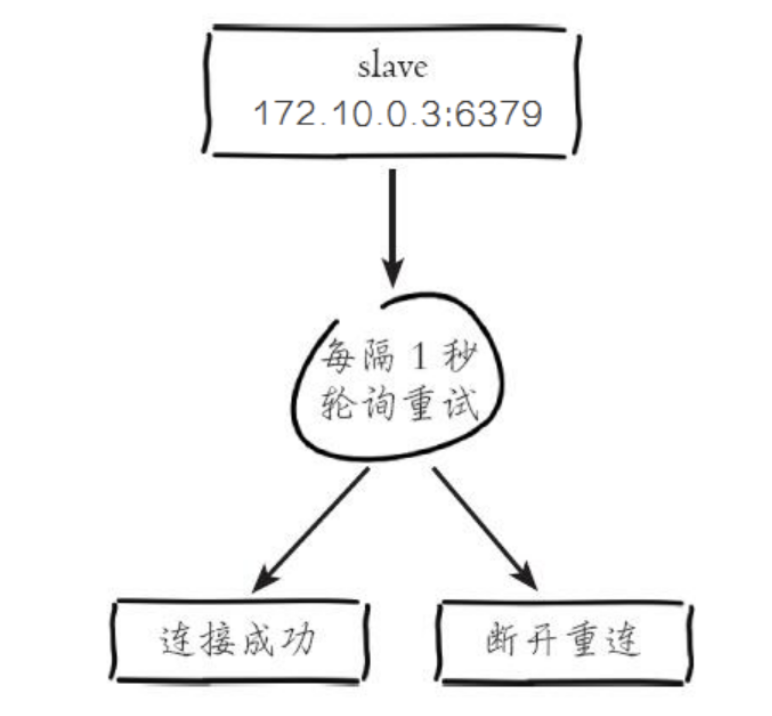
如果从节点无法建立连接,定时任务会无限重试直到连接成功或者执行 slaveof no one 取消复制
-
关于连接失败
- 在从节点执行 info replication 命令查看 master_link_down_since_seconds 这个指标,它会记录与主节点连接失败的系统时间
- 从节点连接主节点失败时,也会在日志中每秒打印失败信息 # Error condition on socket for SYNC: {socket_error_reason}
-
-
-
发送Ping 命令
-
建立连接成功后,从节点发送 Ping 请求进行首次通信,Ping 命令的主要目的
- 检测主从之间网络套接字是否可用
- 检测主节点当前是否可以接收命令
- 如果发送 Ping 命令之后,从节点没有收到主节点的 Pong 回复或者网络超时,比如网络超时或者主节点阻塞无法响应命令,从节点会断开复制连接,下次定时任务会发起重连
\
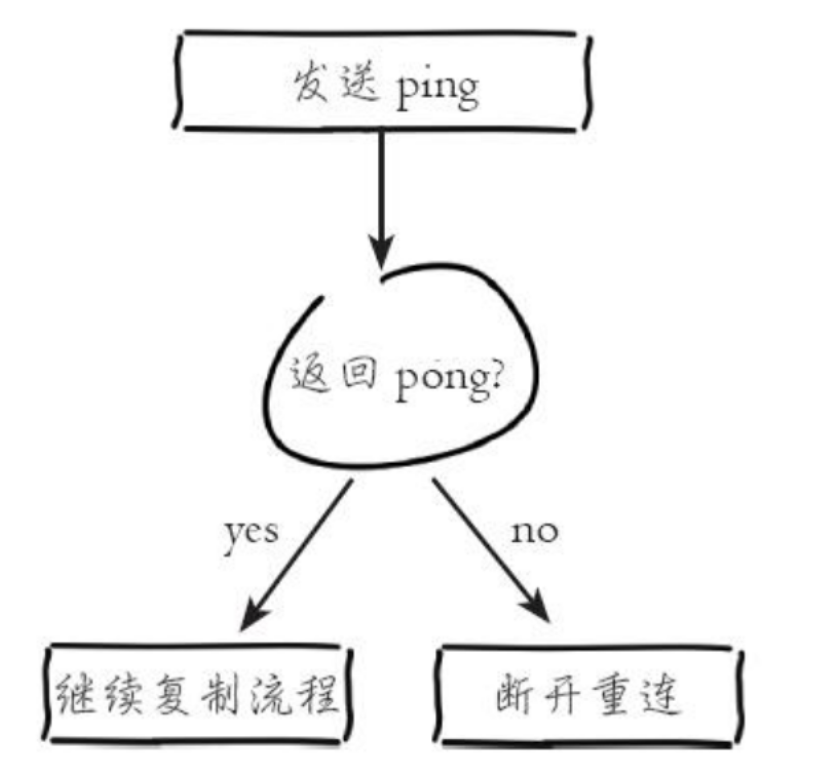
- 从节点发送的 Ping 命令成功返回后,Redis 打印日志,并继续后续的复制流程

-
-
权限验证
- 如果主节点设置了 requirepass 参数,则需要密码验证,从节点必须配置 masterauth 参数保证与主节点相同的密码才能验证通过,如果验证失败,复制将终止,从节点重新发起复制流程
-
同步数据集
- 主从复制连接正常通信后,对于首次建立的复制场景,主节点会把所有的数据全部发送给从节点,这步是耗时最长的步骤
-
命令持续复制
- 当主节点把当前数据全部发送到从节点后,便完成了复制流程,接下来主节点会持续的把命令发送给从节点,保证主从数据的一致性
-
全量复制和部分复制
全量复制
-
用于初次复制或者其他无法进行部分复制的情况,将主节点的所有数据都发送给从节点,是一个非常重型的操作,当数据量较大时,会对主从节点和网络造成很大的开销
-
全量复制过程
- redis-slave 内部会发出一个同步命令,刚开始是 Psync 命令 , Psync?-1 表示请求 master 主节点同步数据
- 主机向从节点发送 runid 和 offset ,因为从节点并没有 对应 的 offset ,所以是全量复制
- 从节点会保存主机的相关信息 save masterinfo
- 主机接收到复制命令后,执行 bgsave「异步执行」在后台生成 RDB 快照文件,并使用一个缓冲区「复制缓冲区」来记录现在开始执行的所有写命令
- 主机 send RDB 发送 RDB 快照文件给从机
- 发送缓冲区数据
- 刷新旧的数据,从节点在接收主节点数据之前将之前原有的老数据清空
- 加载 RDB 快照文件,将数据库状态更新直主机执行 gbsave 时的数据库状态和缓冲区数据的加载
-
全量复制的开销
- bgsave 的时间
- RDB 文件网络传输时间
- 从节点清空数据的时间
- 从节点加载 RDB 文件的时间
部分复制
-
部分复制是 Redis 2.8 以后出现的,之所以要加上部分复制,是因为全量复制会出现很多的问题,比如开销时间大,无法隔离等问题。\
redis 希望在网络抖动的时候,可以有一些机制将复制的损失降到最低; -
用于处理在主从复制中因网络闪断等原因造成的数据丢失场景,当从节点再次连上主节点后,如果条件允许,主节点会补发丢失数据给从节点,因为补发的数据远远小于全量数据,可以有效避免全量复制的过高开销,需要注意的是,如果网络中断时间过长,造成主节点没有能够完整的保存中断期间执行的写命令,则无法进行部分复制,仍使用全量复制
-
部分复制的过程
- 如果网络抖动(connection lost)
- Redis 主机还是会写 replbackbuffer「复制积压缓冲区」
- 从机 slave 会继续连接从机
- 从机把自己当前的 runid 和 offset 发送给主机,并且执行 Pysnc 执行同步
- 如果 master 主机发现偏移量在复制积压缓冲区的范围内,就会返回 continue 命令,继续执行同步
- 同步了 offset 的数据,所以部分复制是基于 offset 「偏移量」的
redis 是如何决定使用全量复制或部分复制的?
-
redis 选择决策
- 从节点将 offset 发送给主节点后,主节点根据偏移量和复制缓冲区大小来决定是否执行部分复制
- 如果offset 偏移量之后的数据,仍然在复制积压缓冲区的话,使用部分复制
- 如果 offset 偏移量之后的数据,已经不在积压缓冲区的话,说明数据已经被挤出,所以进行全量复制
-
如何避免全量复制?
-
调整积压缓冲区的大小
- 由于缓冲区大小固定且有限,因此可以备份的数据也有限,当主从节点的 offset 差距过大超过积压缓冲区时,无法进行部分复制,只能使用全量复制;
- 反过来说,为了提高网络中断时部分复制的使用概率,可以根据需要增大复制缓冲区的大小来调节「通过配置 repl_backlog_size」来设置。
- 例如:如果网络中断的平均时间是 60S,而主节点平均每秒执行的写命令是 100KB,则复制积压缓冲区的平均需求为 6MB, 为了保险期间,设置成 12MB来保证绝大多数断线情况下可以使用部分复制
-
服务器运行ID「runid」
- 每个redis 机器「无论主从」在启动时都会随机生成一个随机的ID「每次启动都不一样」,由40个随机的十六进制的字符组成;runid 用来唯一表示 redis 节点,通过 info server 命令查看 runid
- 主节点初次复制时,主节点将自己的runid 发送给从节点,从节点把这个 runid 保存起来,当断线重连时,从节点将这个 runid 发送给主节点,主节点用这个 runid 来判断是否可以进行部分复制
- 如果从节点发送的runid 和 主节点的runid 相同,说明主从节点之前通不过,主节点会尝试继续使用部分复制「真正决定使用部分复制的还是offset 和复制积压缓冲区的大小」
- 如果从节点发送「保存」的 runid 和现在主节点的 runid 不同,说明之前主从没有同步过数据,只能进行全量复制
-
复制偏移量
-
参与复制中的从节点都会维护自身复制偏移量。
-
主节点
- 主节点在处理完写入命令后,会把命令的字节长度做累加记录,统计信息在 info replication 中的 master_repl_offset 指标中
-
从节点
- 从节点每秒钟上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量
- 从节点在接收到主节点发送的命令后,也会累加记录自身的偏移量。统计信息在 info replication 中的 slave_repl_offset 中
复制积压缓冲区
- 复制积压缓冲区:是保存在主节点上的一个固定长度的队列,默认大小是 1MB,当主节点有连接的从节点时被创建,这时主节点响应写命令时,不但会把命令发送给从节点,还会写入复制积压缓冲区
- 命令传播阶段,主节点除了将写命令发送给从节点,还会发送一份给复制积压缓冲区,作为写命令的备份;
- 除了存储写命令,复制积压缓冲区中还存储了其中的每个字节对应的复制偏移量「offset」。
- 由于复制积压缓冲区定长,并且先进先出。所以它保存的是主节点最近执行的写命令,时间较早的写命令会被挤出缓冲区
主从复制的常用相关配置
从数据库配置
-
1. slaveof
slave 节点需要配置该项,指向 master 的 IP 和 端口
-
2.masterauth
如果 master 启用了密码保护,则配置该项需要填写 master 的启动密码,如果master 未启动该项,则该项需要注释
-
3. slave-server-stale-data
指定 master 和 slave 连接中断时的动作。\
默认是 yes,表示 slave 会继续应答来自 client的请求,但这些数据可能已经过期「因为连接中断可能无法进行master同步」;若配置为 no , 则 slave 除正常应答 INFO 和 slaveof 「配置命令」外,其余来自客户端的请求命令均会得到 “SYNC with master in progress” 的应答,直到该 slave 和master重建连接成功或者 slave 提升为 master
-
4. slave-read-only
指定 slave 是否为只读,默认为 yes\
若配置为 no ,表示slave 是可写的,但写的内容在主从同步以后会被清空 -
5. repl-disable-tcp-nodaly
指定向 slave 同步数据时,是否禁用 socket 的NO_DALY 选项,若配置为 yes ,则表示禁用 NO_DALY ,则 tcp 协议栈会合并小包统一发送,这样可以减少主从传输间的包数量和减少带宽,但会增加同步到 slave 的时间;
若配置为 no , 表明启用 NO_DALY,则 tcp 协议栈 不会延迟小包的发送时机,这样数据同步的延时会减少,但需要更大的宽带;
通常情况下,应该配置为 no 以降低同步的延时,但在主从节点间网络负载很高的情况下,可以配置为 yes
-
6. slave-priority
指定 slave 的优先级,在不只一个 slave 节点的部署环境下,当 master 宕机时,redis-sentinel 会将 priorty 值最小的 slave 提升为 master 。\
需要注意的是,如果该配置项值为 0,则对应的 slave 永远不会提升为 master
主从复制进阶常见问题解决
读写分离

-
流量分摊到从节点,这是个非常好的特性,如果一个业务只需要读数据,那么可以建立一台从机进行读数据操作
-
虽然读写有优势,能够让读这部分分配给各个从节点,如果不够直接添加 slave 从节点,但是会出现以下问题
-
复制数据延迟
- 可能出现 从节点同步数据不及时,导致数据不一致的问题,当然可以使用监控偏移量,如果 offset 超出偏移量,就切换到 master 机器上,逻辑切换,具体延迟多少可以使用 info replication 命令查看 offset 指标进行排查
- 对于无法容忍大量延迟的场景,可以编写外部监控程序,「如consul」监听主从节点的复制偏移量,当延时较大时出发报警,或通知客户端,避免读取延时过高的节点
-
对于N个从节点连接的时候才允许写入「比较极端的方式」
-
Redis2.8 以后,可以设置主节点只有在N台从节点连接的时候可以写入请求。\
然而,因为 redis 使用的是异步复制,所有没有办法保证从节点确实收到的给定的写入请求,所以存在一个窗口期的数据丢失的可能性。 -
解释以下这个特性是怎么工作的
-
从节点每秒都会 Ping 主节点,告知它所有的复制流工作。主节点会记住从每个从节点收到的最新的 Ping
-
用户可以给主节点配置一个在等于从节点的数量的最低值和不超过最高值之间的延迟,如果至少有N个从节点,如果少于延迟M秒,则写入将被接受。
-
可能觉得经最大努力保证数据安全的机制,虽然数据一致性无法保证,但是至少只是几面的时间窗口内丢失数据,通常情况下范围数据丢失可比无范围数据丢失好多了
-
如果条件不满足,主节点将会返回一个错误,并且写入请求将不被接受
-
主节点配置需要两个参数
- min-slaves-to-write
- min-slaves-max-lag
-
-
-
从节点故障问题
- 对于从节点的故障问题,需要在客户端维护一个可用从节点列表,当从节点故障时,立即切换到其他从节点或主节点
-
主从配置不一致
-
经常导致主机和从机的配置不同,并带来问题
-
主机和从机有时候会发生配置不一致的情况,
例如:maxmemory 不一致,如果主机配置 maxmemory 为8G,从机 slave 设置为 4G,这个时候是可以用的,还不会报错,单数如果要做高可用,让从节点变成主节点的时候,就会发现数据已经丢失了,而且无法挽回
规避全量复制
-
全量复制指的是,当 slave 从机断掉并重启后,runid 产生变化而导致需要在 master 主机里拷贝全部数据,这种拷贝全部数据的过程非常耗资源
-
全量复制是不可避免的。
例如:第一次的全量复制是不可避免的,这时需要选择小主节点,且 maxmemory 值不要过大,这样就会比较快,同时选择在低峰值的时候做全量复制
-
造成全量复制的原因
- 主从机的运行 runid 不匹配。
主节点如果重启,runid 将会发生变化,如果从节点监控到 runid 是不同一个,它就会认为你的节点不安全,当发生故障转移的时候,如果主节点发生故障,那么从机就会变成主节点。
- 复制缓冲区空间不足。
比如默认值:1M 可以部分复制,但如果缓冲区不够大的话,首先需要网络中断,部分复制就无法满足,其次需要增大复制缓冲区配置「relbacklogsize」,对网络的缓冲增强
解决方案:
- 在一些场景下,可能希望对主节点进行重启。
例如:主节点内存碎片率过高,或者希望调整一些只能在启动时调整的参数,如果使用普通的手段重启主节点,会使得 runid 发生变化,可能导致不必要的全量复制
- 为了解决这个问题,redis 提供了 debug reload 的重启的方式,重启后,主节点的 runid 和 offset 都不受影响,避免了 全量复制
3.当一个主机下面挂了很多个 slave 从机的时候,主机master 挂了,这时 master 主机重启后,因为 runid 发生了变化,所有的 slave 从机都要做一次全量复制,这将引起但节点和但机器的复制风暴,开销会非常大
-
解决方案:
- 一般使用一主多从,因为主节点还同时担任写操作
- 可以采用树状结构降低多个从节点对主节点的消耗
-
从节点采用树状结构非常有用,网络开销给位于中间层的从节点,而不必消耗顶层的主节点,但是这种树状结构也带来了运维的复杂性,增加了手动和自动处理故障转移的难度\
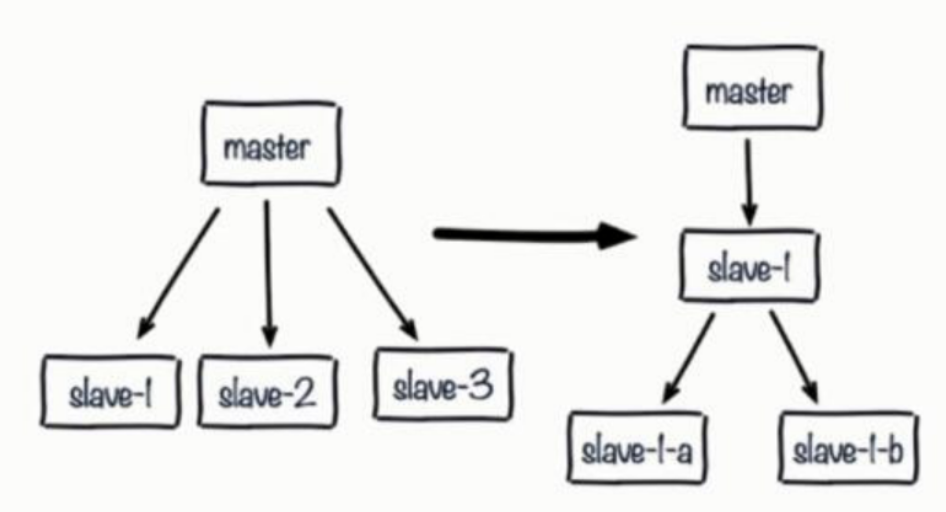
规避复制风暴
-
解决方案:
- 由于 redis 的单线程架构,通常单台机器会部署多个 redis 实例,当一台机器上同时部署多个主节点「master」时,如果每个 master 主机只有一台 slave 从机,那么当机器宕机以后,会产生大量的全量复制,这种情况是非常危险的,带宽马上被占用,会导致不可用
- 应该把主节点尽量分散在多台机器上,避免在单台机器上部署过多的主节点。当主节点所在的机器故障后提供故障转移机制,避免机器恢复后进行密集的全量复制
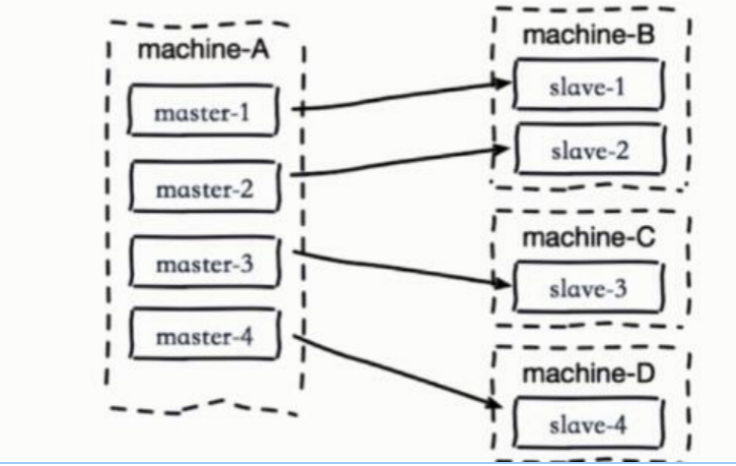
如何选择,要不要读写分离
没有最合适的方案,只有最合适的场景,读写分离需要业务可以容忍一定程度的数据不一致,适合读多写少的业务场景,读写分离,是为了要建立一主多从的架构,才能横向任意扩展 slave node 去支撑更大的读吞吐量
本作品采用《CC 协议》,转载必须注明作者和本文链接









 关于 LearnKu
关于 LearnKu




推荐文章: