
PHP 实现 HTTP 表单请求服务器
11 / 7 / 创建于 6年前 /
 Dennis_Ritchie 的个人博客
Dennis_Ritchie 的个人博客

在前面的几篇博文老司机带你用 PHP 实现 Websocket 协议和PHP 编写基本的 Socket 程序中,我们使用到了基本的socket程序编写技巧,在今天的这一篇博文中,我们将继续深化这一知识,同时我们会用到HTTP协议的相关知识,借助PHP实现表单上传服务器,作为一个后台开发者,我们必须对这一块知识,有深入的理解,今天要讲的内容有些地方可能不是那么容易理解(老司机讲起来也不是那么容易的,写本篇博文的代码和博文总共花了2天半时间,因为在这里要求大家对代码的掌控能力更强),希望大家仔细的琢磨分析代码,代码我已经长传到了码云,仓库为php-http-form-server,如果你看懂了我这里写的代码,以后不管你用什么语言写socket程序,程序就算再怎么复杂,套路和这篇博文是一样的。
高能预警
这篇博客与以往的博客有所不同,请一定要下载代码,对照着我下面讲的看。
预期效果
- 彻底搞懂form表单提交(不再是一个黑匣子,因为我们自己实现了)
- 更加深入的理解http协议
- 复杂的socket编程技巧
- 练习代码掌控能力(这个很重要)
推荐链接
背景
在写这篇博文之前,我也没有写过相关的代码,所以这算是第一次和大家一起实现这个功能,前天利用业余时间编写了代码,代码的基本思想很简单,就是实现表单上传这个功能,相信你如果理解了我今天所讲的东西,大家以后对socket编程这块,会更加的自信(就算是以后学习其他的语言,这也是非常有用的,基本编程思想才是最重要的),在阅读下面的内容之前,如果你没有socket编程相关的基本知识,请先阅读我上面提到的PHP 编写基本的 Socket 程序,这可能会需要你几分钟的阅读时间。
知识背景
相信对于后台的开发人员而言,form表单并不陌生,form表单的请求方法有2种,分别是GET和POST。但是我们今天的服务器不会分析GET请求,我们需要把主要的经历集中在POST请求,这才是form请求的精华和常用方式。form表单的编码类型有2中,分别为application/x-www-form-urlencoded和multipart/form-data,下面一一分析。
application/x-www-form-urlencoded 这种编码方式从它的名字后面的一部分就可以看出来urlencode,也就是说表单的内容和url的编码方式是一样的,这个大家总知道吧,比如说,一个form表单,有name="obama"和pwd="123456",那么url方式编码就是name=obama&pwd=123456,是不是很简单,没错就是这么简单。只是如果字段名和字段值中包含特殊字符,会被编码。比如说,name="=obama",pwd="&123456",那么编码之后的结果就像是这样:name=%3Dobama&pwd=%26123456。再比如name="= obama",pwd="& 123456"(name和pwd中都包含空格),那么编码结果就是这样:name=%3D+obama&pwd=%26+123456。具体的编码如何转换,我们暂时不必知道,php中已经有函数可以帮助我们urlencode,我们只需要知道的有2个字符不会被转换,它就是 & 和 = ,请大家一定要记住这一点,切记,因为在我们后面的代码实现中,会用到这一点。
multipart/form-data 编码要稍微复杂一些,但是有老司机在,不用慌,下面的内容是我服务器收到的,但是被我处理过,二进制文件太长了,不利于我们的分析:
------WebKitFormBoundaryVBmvbscTaKzHhTLA
Content-Disposition: form-data; name="name"
obama
------WebKitFormBoundaryVBmvbscTaKzHhTLA
Content-Disposition: form-data; name="pwd"
123456
------WebKitFormBoundaryVBmvbscTaKzHhTLA
Content-Disposition: form-data; name="file"; filename="images.jpg"
Content-Type: image/jpeg
����JFIF��� ( %!read num:2048
����JFIF��� ( %!1!%)+...383-7(-.+
------WebKitFormBoundaryVBmvbscTaKzHhTLA--上面的内容足以说明了multipart/form-data编码的套路,仔细看上面的,你是不是发现------WebKitFormBoundaryVBmvbscTaKzHhTLA出现了4次,这是啥?如果你有这样的疑问,非常好,在解释它之前,我们还需要看另外一个东西,表单提交的时候,传递了下面的
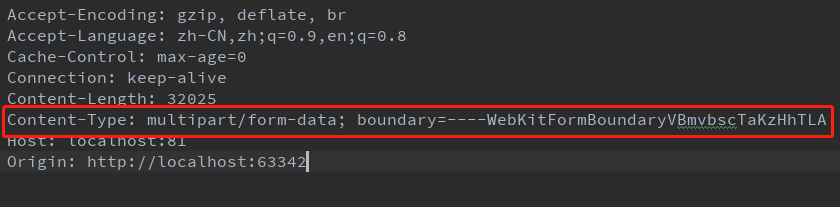
为了大家看得更清楚,我采用了截图的方式,标出来的内容和一般的请求有所不同,这是表单所特有的的,采用multipart/form-data编码的时候,Content-Type就是multipart/form-data,那么后面的boundary是啥呢(如果你不知道这个单词的含义,可以查一下:边界)。说白了,它的意思就是用来分割表单每一个输入字段的,这也就是我上面贴出来的文本,name,pwd,file字段都被boundary给分割了,但是你要记住了,分割的时候,在boundary的前面加上了2个额外的“-”,所以总共6个"-",这个请大家一定要记住,我之前实现的时候,踩了这个坑,希望大家引以为戒。还有一点需要记住,在每一个post请求的请求体中,在最末尾也有一个boundary,这个boundary和前面说的基本是一样的,为啥是基本?因为它的后面还有2个“-”(这个可是把我害惨了,一步一步调试才发现这个问题)。
回到上面贴出来的post请求内容,除了我上面说的分割字符串boundary,还有一个头部是必须的,它就是Content-Disposition,它描述了当前字段的元数据,如果当前字段只是普通文本的话,那么就只有当前字段的名称,如果当前字段代表的是文件的话,除了刚才说的,还有一个filename字段,表示当前上传文件的文件名。
另外一个就是Content-Type,他表示当前字段的内容类型,我们这里只管普通文本和文件。对于普通文本来说,这个字段可能是不存在的(我们不能假设它一定不存在),对于普通文本它的类型一定是以text开头(这个结论很重要),比如:text/plain。对于图片来说,它的类型以image开头,我们只要知道这个足够了,总的来说,我们只要能区分他是文本还是文件就足够了,至于他是什么文件类型,已经没有任何讨论的意义。
还有很重要的一点,大家需要非常注意,字段值,比如说name这个字段它的值为obama,和字段的最后一个约束信息(上面说的Content-Disposition,Content-Type,或者其他的什么字段)之间有个\r\n,下图所示的红色箭头(字段约束的每一行后面的\r\n不算在内,如果算在内的话,就有两个连续的\r\n了),这个特性是我们用来区分字段约束的字段值的唯一依据。

最后要和大家说的是,我们永远都不能猜测每次从套接字中能够读取多少个字节,这是不现实也是没有意义的,所以这大大增加了代码的复杂度,因为每一步操作之前,我们都要判断内部缓冲区中是否有完整的匹配,这是不可或缺的,这也是为什么这篇博文这么长的原因,希望大家能够明白我的良苦用心。因此下面我会仔细的给大家讲解下流程。
代码流程
上面说了这么多就是为了代码实现中走更少的弯路,代码已经被上传到了码云,仓库见博客的开头,因为这次的代码,相对于以前来说,流程可能稍微有些复杂,所以在讲解代码实现之前,我先讲代码的流程,请看下图,为了画出这个图,硬是花费了一个小时,我靠,画出这个图比写代码难多了,一点儿都不夸张,可能是因为我平时很少画图吧,如果流程图不清晰,在代码仓库中可以看到,希望大家认认真真看:
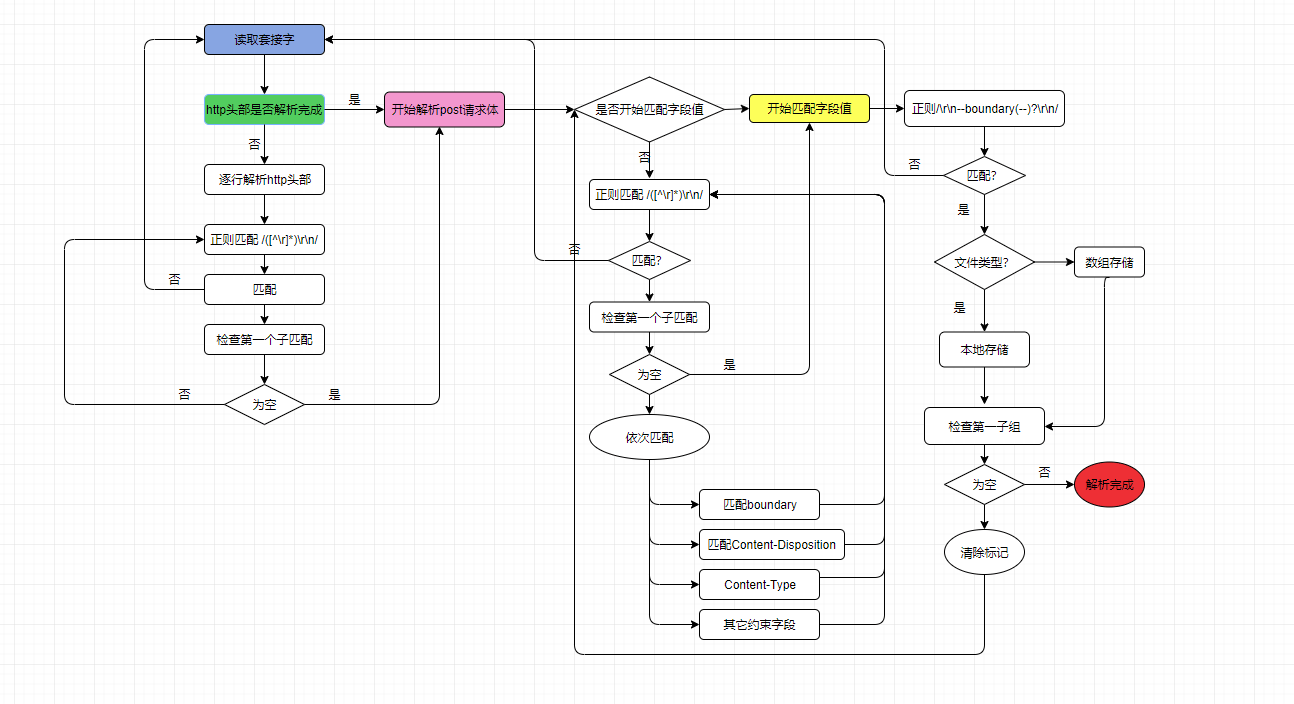
下面分析上面的这个图,跟着这张图,你看懂了的话,后面的代码也不是问题:
- 读取套接字,每次读取2048字节(这个你可以随便设,一般不能太大)。
- 判断http头部是否已经解析完成。
- 如果http头部没有解析完成,就开始解析http头部,我们知道http头部的每一行末尾都是\r\n,所以匹配它的正则表达式为:/([^\r])\r\n/。检查正则表达式的匹配结果,如果没有匹配到,那么说明缓冲区的字节数量不够,此时需要继续读取套接字,所以返回第1步,如果正则表达式匹配到了结果,说明已经匹配到了完整的行,但是这还是不够,我们还需要检查第一个子匹配是否为空,如果不为空的话,当前行是完整的http头部,我们可以检测Content-Type和Content-Length等等头部,并且把它们存起来,再次执行第3步,如果为空,那么说明http头部已经解析完成了(http最后一个头部的下一行只有\r\n),此时开始执行第4步。
- 此时http头部已经解析完成了,我们需要开始解析它的请求体,请求体有多个字段(字段是啥?举个例子,对于form表单来说,我假设有个input,它的name属性值为“”name“”,所以我说name是一个字段,它由三个部分组成,必须的部分包括boundary,约束信息(Content-Disposition,可选的Content-Type,或者其他的字段),还有字段值,例如:obama)组成。对于每一个字段来说,我们依次匹配boundary,Content-Disposition,匹配的依据是什么呢?很简单,每一行末尾都有\r\n,这个和http头部的匹配原则是一样的,上面我们提到过字段值和约束信息之间有一行,只包含\r\n,所以只要检测到这样的一行,我们就知道当前字段可以开始匹配字段值了,这个时候,我们可以设置当前的匹配状态为开始匹配字段值,执行流程跳转到第5步。如果没有匹配到这样的行,我们需要一直匹配约束信息,也就是执行第4步。
- 约束信息匹配完了之后,我们就开始匹配字段值了,那么我们以什么为依据呢?啥时候可以确定字段值匹配到了呢?/\r\n-boundary(--)?\r\n/ 就是我们的匹配依据,只要我们执行正则表达式,匹配到了结果,也就代表匹配到了字段值。在当前的程序中,如果当前字段代表的是文件,那么直接本地存储,如果是普通的文本数据则存储在对象中。那么你也许还会问,怎么判断所有的字段匹配完成了呢?这个问题问的非常好,还记得我之前说的不,post请求体的最后一行的boundary后面有2个“-”,所以只要检测到了这个,就代表匹配完成了,对于当前的正则表达式而言,就是检测第一个匹配子组的值,如果不为空的话,就说明已经完成了,否则就需要继续执行第4步,开始匹配下一个字段。
上面就是整个代码的执行流程,请一定要理解,下面我们来看代码,再次提醒大家,请下载代码,对照着我上面讲的,理解应该没有问题。
实现代码
读取套接字
$bytes_num = socket_recv($client_socket_handle, $buffer, 2048, 0);
$this->internal_buffer .= $buffer;
if (!$bytes_num) {
echo "socket_recv failed\n";
exit(1);
} 读取套接字的代码很简单,这里解释一下internal_buffer 属性,我们读取到的所有数据都会存储到internal_buffer 中,它就是我们的内部缓冲区。
解析http头部
if (!$this->http_header_parsed) {
while (true) {
if (preg_match("/([^\r]*)\r\n/", $this->internal_buffer, $match) > 0) {
if (empty($match[1])) {
//http 头部匹配完成
$this->http_header_parsed = true;
} else {
if (!$this->request_line_parsed) {
$this->request_line_parsed = true;
$line_parts = explode(" ", $match[1]);
$this->request_method = trim($line_parts[0], " ");
$this->uri = $line_parts[1];
} else {
$parts = explode(":", $match[1]);
$key = $parts[0];
$value = trim($parts[1], " ");//value的左侧可能有空格
$this->http_headers[$key] = trim($value, "\r\n ");
if (strcmp($key, "Content-Type") == 0) {
//检查内容的类型
$multipart_type = "multipart/form-data";
//如果有上传文件的话
if (strncmp($multipart_type, $value, strlen($multipart_type)) == 0) {
$this->multiple_part_enabled = true;
//获取边界也就是boundary
$this->http_boundary = explode("=",
trim(substr($value, strlen($multipart_type) + 1), " "))[1];
} else {
//此时内容类型为application/x-www-form-urlencoded
}
} else if (strcmp("Content-Length", $key) == 0) {
//检查内容的长度
$this->content_length = intval($value);
}
}
}
$this->internal_buffer = substr($this->internal_buffer, strlen($match[0]));
} else {
break;
}
if ($this->http_header_parsed) {
break;
}
}
}
if (!$this->http_header_parsed) {
continue;
}关于preg_match的使用,大家一定要先搞清楚,如果不清楚,请先参考文档preg_match,如果它的返回值大于0,也就是说匹配到了,虽然匹配到了,我们还是要先判断$match[1]的值,是不是为空,就和之前分析的一样,为空就说明头部解析完成了,所以设置http_header_parsed 为true,如果不为空的话,正常解析。解析之前要检查request_line_parsed的值,它表示请求行是否已经被解析(开始为false),所以第一行肯定是请求行,此时request_line_parsed设置true,那么下一次匹配就不会进入到这个分支了,看到没,最外层是个while循环,所以我们假设如果缓冲区里面有足够的的字节数,preg_match还是会匹配到,$match[1]的检查是必须的,我们假设头部还是没有解析完成,由于之前request_line_parsed设置为true,所以代码会进入else语句,这里面的代码很简单吧?http头部的名称和值以冒号(:)进行分割,分割完之后得到$parts,$key就是头部名了,
$value就是头部值了,我们把key,value存储到了http_headers中,以备将来使用,获取到这些值之后,我们检测它是不是Content-Type,如果是的话,我们判断$value是否包含multipart/form-data,如果包含的话,那么说明当前的post请求体,是以boundary分割的,此时设置multiple_part_enabled 为true,同时也获取到了boundary的值,存储到http_boundary 中,至于为啥是这样?看我上面的请求图,很简单。同样的,我们也可以检测Content-Length的值,这样我们就可以知道post包体的大小了,这个在后面的代码中会使用到,在处理完一行http头部之后,我们需要从内部缓冲区中删除掉刚才已经读取的这一行,也就是 substr($this->internal_buffer, strlen($match[0]))的作用了。如果之前preg_match返回值为0的话,那么就说明缓冲区的字节数是不够的,此时执行else语句,它里面就一行代码,break,此时代码会跳出内层while循环,跳出循环之后,因为$this->http_header_parsed的值为false,所以当前while循环执行完毕,所以代码从最外层while循环开始执行(上面没有贴出来),代码如下:
while (true) {
//每一次读取2048字节的数据
$bytes_num = socket_recv($client_socket_handle, $buffer, 2048, 0);
$this->internal_buffer .= $buffer;
if (!$bytes_num) {
echo "socket_recv failed\n";
exit(1);
} else {
echo "read num:" . $bytes_num . "\n";
if (!$this->http_header_parsed) {
while (true) {
if (preg_match("/([^\r]*)\r\n/", $this->internal_buffer, $match) > 0)经过多次解析http头部之后,之前分析的$match[1]就是空的,所以 $this->http_header_parsed = true,此时http头部解析完成,跳出内层while循环。
解析字段
接着上面的代码,继续分析:
if (strlen($this->internal_buffer) == 0) {
continue;
}
if ($this->http_header_parsed) {
if (strpos($this->request_method, "GET") === false) {
if ($this->multiple_part_enabled) {
//检测boundary
while (true) {
//隐藏掉了
}
} else {
//隐藏掉了
}
} else {
echo "GET request not supported";
}
}在解析完http头部之后,我们还需要检查一下internal_buffer的长度,如果为0的话,那么返回到最外层的while循环,继续读取套接字,和上面的一模一样,这里在解析字段之前,还检查了请求方法,我们之前就说过了,当前的程序不处理get请求的form表单请求,所以打印出"GET request not supported",就完事儿了。从前面的分析,我们知道multiple_part_enabled为true表示编码类型为multipart/form-data,所以此时代码进入到if语句中,否则进入到else中,下面我们分两种情况进行分析。
如果multiple_part_enabled为true的话,代码如下:
while (true) {
if (!$this->start_match_field_content) {
if (preg_match("/([^\r]*)\r\n/", $this->internal_buffer, $match) > 0) {
if (!$this->boundary_start_matched) {
$this->boundary_start_matched = true;
}
if (strncmp($match[1], "Content-Disposition:", strlen('Content-Disposition:')) == 0) {
$disposition_parts = explode(';',
str_replace(" ", "", substr($match[1], strlen("Content-Disposition:"))));
$this->current_field_name = str_replace("\"", "", substr($disposition_parts[1], 5));
if (count($disposition_parts) > 2) {
$this->current_file_name = str_replace("\"", "",
substr(trim($disposition_parts[2], " "), strlen("filename=")));
}
}
if (strncmp($match[1], "Content-Type:", strlen('Content-Type:')) == 0) {
$content_value = str_replace(" ", "", substr($match[1], strlen("Content-Type:")));
if (($pos = strpos($content_value, ";")) > 0) {
$this->current_field_content_type = substr($content_value, 0, $pos);
} else {
$this->current_field_content_type = $content_value;
}
}
if (empty($match[1])) {
$this->start_match_field_content = true;
if (strpos($this->current_field_content_type, "text") !== false
|| empty($this->current_field_content_type)) {
$this->field_type_is_file = false;
} else {
$this->field_type_is_file = true;
}
}
$this->has_read_bytes_num += strlen($match[0]);
$this->internal_buffer = substr($this->internal_buffer, strlen($match[0]));
} else {
break;
}
} else {
if (preg_match("/\r\n--{$this->http_boundary}(--)?\r\n/",
$this->internal_buffer, $match, PREG_OFFSET_CAPTURE, 0) > 0) {
if ($this->field_type_is_file) {
file_put_contents(__DIR__ . '/' . $this->current_file_name,
substr($this->internal_buffer, 0, $match[0][1]));
} else {
$this->http_form_data[$this->current_field_name]
= substr($this->internal_buffer, 0, $match[0][1]);
}
$this->internal_buffer = substr($this->internal_buffer, $match[0][1] + 2);
$this->has_read_bytes_num += ($match[0][1] + 2);
if (($this->content_length - $this->has_read_bytes_num) == (strlen($this->http_boundary) + 6)) {
echo "client content parsed finished\n";
//http内容解析完成
foreach ($this->http_form_data as $key => $value) {
echo $key . "=>" . $value . "\n";
}
} else {
$this->start_match_field_content = false;
$this->boundary_start_matched = false;
$this->form_part_field_matched = false;
$this->field_content_type_checked = false;
$this->current_field_name = null;
$this->current_file_name = null;
$this->current_field_content_type = null;
$this->field_type_is_file = false;
}
} else {
break;
}
}
}代码有点儿长,所以首先从结构上看,这段代码根据$this->start_match_field_content的值分为2部分,$this->start_match_field_content表示啥呢?它表示是否开始匹配字段值,这个值为默认为false,所以代码会进入到if中,这里还是用到了preg_match,之前在分析流程时候,已经分析过它了,之所这么做,因为每一行的末尾都有\r\n,这里的preg_match如果返回0,就表示缓冲区的字节数不够了,所以break,退出while循环,这样代码会从最外层while开始执行起,继续读取套接字。我们假设preg_match匹配到了,那么代码会匹配Content-Disposition,Content-Type等字段的值,current_field_name 记录当前解析到的字段名,比如说name,current_file_name 记录着解析上传文件的名称,比如我测试的时候是1240.gif,current_field_content_type 记录着字段的类型(之所以会判断分号“;”,是因为可能会出现Content-Type:text/plain;charset=utf-8),从前面的代码流程中,我们就说了,字段约束信息和字段值之间有一个只有\r\n的行,这就对应着上面的$match[1],所以如果$match[1]的为空的话, $this->start_match_field_content = true;就表示需要开始匹配字段值了,但是这里还有一个操作,判断字段是属于文件还是普通文本,如果是文本的话,那么Content-type必定包含text前缀或者Content-type缺失。
从上面的分析,知道$this->start_match_field_content 为true,表示可以开始匹配字段值了,此时匹配也是通过preg_match实现的,具体的原理在流程分析已经仔细的讲过了,如果preg_match的返回值等于0,就表示缓冲区的字节数不够了,所以break,退出while循环,这样代码会从最外层while开始执行起,继续读取套接字。这次的preg_match调用和之前有所区别,我们传递了额外的一个参数PREG_OFFSET_CAPTURE,如果你不清楚它的用法,请参阅官方文档。简单来说,如果传递了这个参数,就可以获取到每一个匹配的偏移,包括完整匹配,匹配子组。
$this->field_type_is_file的值,表示当前字段是文件,还是文本,这里还要再说一点,就是$match[0][1],它是什么意思呢?刚才我们讲到了,我们传递了额外的一个参数PREG_OFFSET_CAPTURE,所以对于完整匹配(完整匹配就是正则表达式匹配到的完整字符串),$match[0][1]就表示完整匹配的第一个字节在内部缓冲区中的偏移,同时也表示完整匹配的长度,所以 substr($this->internal_buffer, 0, $match[0][1]))的值就是字段值的实际内容。同样的,我们需要删除掉缓冲区中已经读取的内容,但是为什么删除的长度是 $match[0][1] + 2呢?因为在我们的正则表达式的前面有\r\n2个字节,所以要加上他们(这个特别注意,因为字段值的后面会有\r\n,这个对于字段值是不需要的)。我们之前好像还没说$this->has_read_bytes_num这个字段是干嘛用的对吧?在我们之前每一次解析post请求体的时候,不管是解析字段约束信息还是字段值,都会记录着当前消耗的字节数,所以我们可以用这个值计算出是否已经完整的读取了post请求体,具体计算公式在代码里,我解释一下,($this->content_length - $this->has_read_bytes_num)表示内部缓冲区中还未读取的字节数,(strlen($this->http_boundary) + 6),$this->http_boundary表示boundary,你已经知道了,关键是后面的6,6包含4个字符"-"(最后一个boundary后面有2个,前面已经说过了,加上前面的2个),还有一个\r还有一个\n。
下面我们分析编码为application/x-www-form-urlencoded的情况,这种情况很简单,具体的原理在这篇博客的开头,已经有过2详细的论述,不多说,看代码:
if (strlen($this->internal_buffer) < $this->content_length) {
//还有数据没有读取,不进行任何操作
} else {
foreach (explode('&', $this->internal_buffer) as $pair) {
$pair_parts = explode('=', $pair);
$this->http_form_data[urldecode($pair_parts[0])] = urldecode($pair_parts[1]);
}
foreach ($this->http_form_data as $key => $value) {
echo $key . "=>" . $value . "\n";
}
}
这段代码首先判断当前内部缓冲区的字节数是不是和post请求体的内容长度(Content-Length的值)是一样的,如果不一样,说明套接字中还有数据待读取,直接结束本次循环就行了。否则,数据读取完毕,我们用&和=对请求体内容进行分割处理(至于为啥这么做,看这篇博客的开头),值得注意的是字段名和字段值都有可能被编码过,所以需要解码,php的函数urldecode可以做到这一点,这种编码方式非常简单,就不多少了。
经过上面的分析,代码就算走完了,这里的代码非常具有现实意义,希望大家理解。
告诫
上面仔细的分析过了代码的执行流程,但是请大家一定要下载原始代码,自己仔细看一哈,实践是检验真理的唯一标准,如果你发现了代码中的错误,请联系我(联系方式在这篇博文的最后面)或者给我留言,都可以。
运行代码示例
主要是这2个文件

控制台运行 php TcpServer.php ,然后再打开form.html文件,你可以修改这个文件,以观察不同的编码的打印输出,在我当前的测试情况下,控制台打印如下:
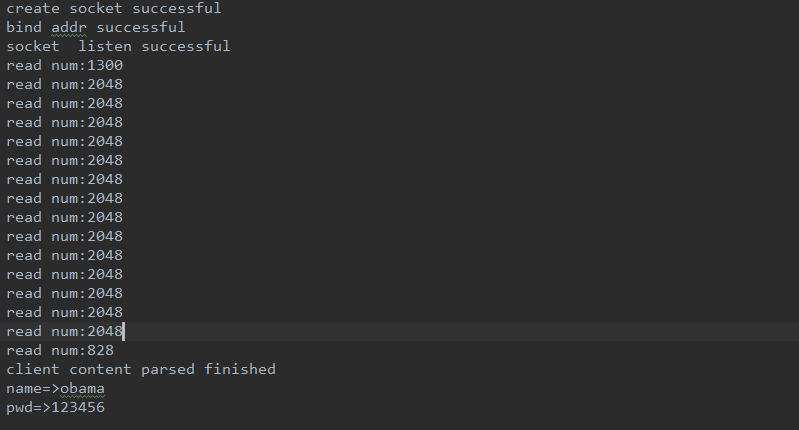
可以看到我的程序总共读取了16次套接字,传递2个post字段,同时在我的文件夹下面生成了如下的文件
学习不容易,希望大家坚持和忍耐,为了写这篇博客,都熬到了凌晨1点了,不懂的请问我,我会耐心解答。

交流学习
有个qq群,大家有需要深入学习的可以加一下。
本作品采用《CC 协议》,转载必须注明作者和本文链接
































 关于 LearnKu
关于 LearnKu




推荐文章: