
初识时序数据库
3 / 0 / 创建于 6年前 /
 来杯可乐不加糖 的个人博客
来杯可乐不加糖 的个人博客
前言:
在物联网大数据时代,服务器面临着大量监控数据的上传,数据库的读写也有非常高的并发,毫无疑问,服务器性能逐渐下降而成本逐渐上升。在此大环境下,时序数据库应运而生,本文简单介绍从笔者角度对时序数据库的认知及学习,仅供参考。
1、什么是时序数据库?
概念:
时序数据库全称为时间序列数据库 Time Series Database (TSDB)。主要用于指处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时序数据。其具有不变性、唯一性、时间排序性的特点。
架构:
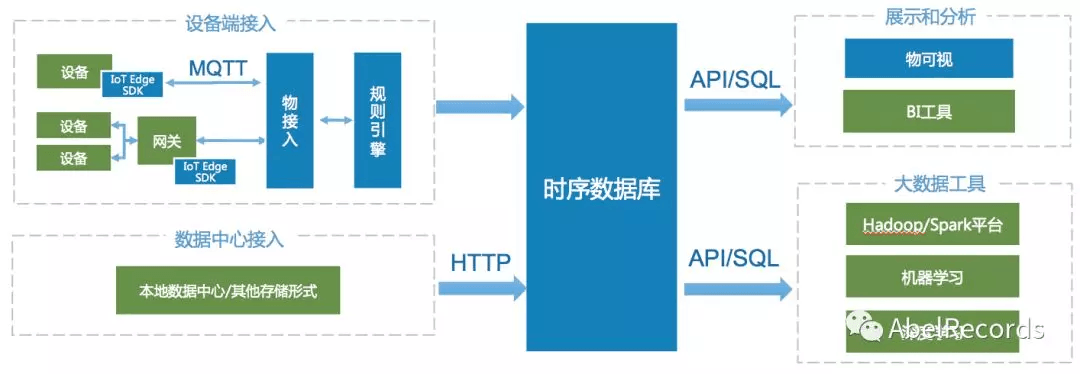
特点:
-
写入特点:
- 写多读少(这与其数据特性相关,例如报表,实时监控,通常只会关心几个特定的关键指标或者在特定的场景下才会去读数据)
- 写入平稳、持续、高并发高吞吐(时序数据的产生通常是以一个固定的时间频率产生,不会受其他因素的制约,其数据生成的速度是相对比较平稳的。)
- 实时写入最近生成的数据,无update。(跟时间数据特性有关,数据是随着时间推进的,每次数据都是新数据,故不存在旧数据的更新,但不排除人为数据的更正)
-
查询特点:
- 按时间范围读取:通常来说不会去关心某个特定点的数据,而是一段时间的数据。
- 最近的数据被读取的概率高
- 历史数据粗粒度查询的概率高(粗粒度和细粒度的区别主要是出于重用的目的,像类的设计,为尽可能重用,所以采用细粒度的设计模式,将一个复杂的类(粗粒度)拆分成高度重用的职责清晰的类(细粒度).对于数据库的设计,原责:尽量减少表的数量与表与表之间的连接,能够设计成一个表的情况就不需要细分,所以可考虑使用粗粒度的设计方式.)
- 多精度查询
- 多维度分析
-
存储特点:
- 数据量大(比如A节点的一个监控项上传周期是1s,该节点的这个监控项每天会产生86400个数据点,若有1万个监控项,则一天产生86400万条数据。实际应用会是TB甚至PB级)
- 冷热分明(越是历史的数据,被查询和分析的概率越低)
- 具有时效性(数据通常会有一个保存周期,超过这个保存周期的数据可以认为是失效的,可以被回收。一方面是因为越是历史的数据,可利用的价值越低;另一方面是为了节省存储成本,低价值的数据可以被清理)
- 多精度数据存储
时序数据:
- 时序数据是基于时间的一系列的数据。在有时间的坐标中将这些数据点连成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测和预警。
- 时序数据库就是存放时序数据的数据库,并且需要支持时序数据的快速写入、持久化、多纬度的聚合查询等基本功能。
时间标签:
时序数据中数据由于其采用数据模型的不同而不同,例如采用关系模型、对象模型和XML模型的时序数据分别称为时态关系、时态对象和时态XML数据。但无论那种时序数据,其中的时间标签都会根据情形选用下述的时间表示形式。
- 时间点(instant):连续模型中的时间就是在时间轴上实数点;离散模型中的时间点就是时间轴上的一个原子时间间隔,此时,时间点和时间粒度相关。例如当时间粒度为“天”时,2011年3月1日是时间点;而当时间粒度是“秒”时,上述时间点就由系统自动换算为2005年3月1日0时0分0秒。
- 时间期间(period):给定两个时间点t1和t2(t1≤t2),以t1为始点和以t2为终点的时间期间[t1 , t2]定义为集合{t| t是时间点并且t1≤t≤ t2}。时间点可以看作始点和终点的时间区间,此时的时间区间可以理解为延续时间为0的一段时间。在实际应用中,由于需要考虑时间区间兼容时间点的表示和时间区间的比较谓词,一般采用始点封闭,终点开放的“左闭右开”形式。
- 时间区间(interval):时间区间是指持续的一段时间,其基本特征是表示该段时间的长度。例如:“1 year 3 month”、“30天”、“28个小时”等。在数据库系统内,一般用一个整数表示时间区间。时间区间有时也称为时间跨度(Time Span)。
- 时间元素(periods):有限个时间期间(可以是时间点)的集合。有时时间元素在英文中也写为time element。时间元素对于正确有效表达复杂数据时间属性有着重要意义。
- 时间戳(timestamp):某一天中某一秒的一个部分,通常认为是一微秒。
数据模型:
由序列 和数据点组成 (由时间戳 + 数值构成 的数组)
- 序列 :就是标识符(维度),主要的目的是方便进行搜索和筛选
- 数据点:时间戳和数值构成的数组
- 行存:一个数组包含多个点,如 [{t: 2017-09-03-21:24:44, v: 0.1002}, {t: 2017-09-03-21:24:45, v: 0.1012}]
- 列存:两个数组,一个存时间戳,一个存数值,如[ 2017-09-03-21:24:44, 2017-09-03-21:24:45], [0.1002, 0.1012]
一般情况下:列存能有更好的压缩率和查询性能
基本概念:
- metric: 度量,相当于关系型数据库中的table。
- data point: 数据点,相当于关系型数据库中的row。
- timestamp:时间戳,代表数据点产生的时间。
- field: 度量下的不同字段。比如位置这个度量具有经度和纬度两个field。一般情况下存放的是会随着时间戳的变化而变化的数据。
- tag: 标签,或者附加信息。一般存放的是并不随着时间戳变化的属性信息。time加上所有的tags可以认为是table的primary key。
如下图,度量为weather,每一个数据点都具有一个time,两个field:humidity和temperature,两个tag:altitude、area。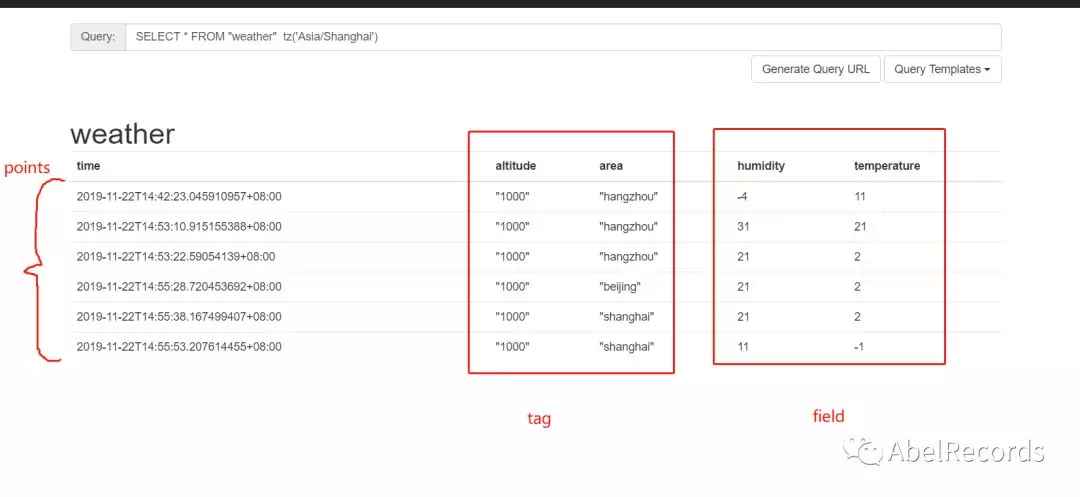
挑战:
- 时序数据的写入:如何支持每秒钟上千万上亿数据点的写入。
- 时序数据的读取:又如何支持在秒级对上亿数据的分组聚合运算。
- 成本敏感:由海量数据存储带来的是成本问题。如何更低成本的存储这些数据,将成为时序数据库需要解决的重中之重。
扩展:
关系型数据库有一些特殊的用法,比如用 MySQL 的 VividCortex, 用 Postgres 的 Timescale。mysql 的引擎,除了常见的 innodb 和 myisam ,还有一个引擎叫 archive ,它的作用和 RRD (Round Robin Database)数据库 差不多,支持插入和查询操作。
2、常见的时序数据库有哪些以及特点是什么?
- 1999/07/16 RRDTool First release
- 2009/12/30 Graphite 0.9.5
- 2011/12/23 OpenTSDB 1.0.0
- 2013/05/24 KairosDB 1.0.0-beta
- 2013/10/24 InfluxDB 0.0.1
- 2014/08/25 Heroic 0.3.0
- 2017/03/27 TimescaleDB 0.0.1-beta
RRDTool 是最早的时间序列数据库,它自带画图功能,现在大部分时间序列数据库都使用Grafana来画图。
Graphite 是用 Python 写的 RRD 数据库,它的存储引擎 Whisper 也是 Python 写的, 它画图和聚合能力都强了很多,但是很难水平扩展。
OpenTSDB 使用 HBase 解决了水平扩展的问题
KairosDB 最初是基于OpenTSDB修改的,但是作者认为兼容HBase导致他们不能使用很多 Cassandra 独有的特性, 于是就抛弃了HBase仅支持Cassandra。
新发布的 OpenTSDB 中也加入了对 Cassandra 的支持。故事还没完,Spotify 的人本来想使用 KairosDB,但是觉得项目发展方向不对以及性能太差,就自己撸了一个 Heroic。
InfluxDB 早期是完全开源的,后来为了维持公司运营,闭源了集群版本。增加专门的时间序列数据库单元。
3、InfluxDB
概念:
InfluxDB是一个用于存储和分析时间序列数据的开源数据库。
存储引擎:
Time Structured Merge Tree (TSM) 和 Log Structured Merge Tree (LSM)
- 写入的时候,数据先写入到内存里,之后批量写入到硬盘。
- 读的时候,同时读内存和硬盘然后合并结果。
- 删除的时候,写入一个删除标记,被标记的数据在读取时不会被返回。
- 后台会把小的块合并成大的块,此时被标记删除的数据才真正被删除
- 相对于普通数据,有规律的时间序列数据在合并的过程中可以极大的提高压缩比。
特性:
- 内置HTTP接口,使用方便
- 数据可以打标记,这样查询可以很灵活
- 类SQL的查询语句
- 安装管理很简单,并且读写数据很高效
- 能够实时查询,数据在写入时被索引后就能够被立即查出
4、应用InfluxDB
准备:
安装InfluxDB包需要root或是有管理员权限才可以。
网络:
InfluxDB默认使用下面的网络端口:
- TCP端口8086用作InfluxDB的客户端和服务端的http api通信
- TCP端口8088给备份和恢复数据的RPC(Remote Procedure Call)服务使用
NTP:
InfluxDB使用服务器本地时间给数据加时间戳,而且是UTC时区的。并使用NTP来同步服务器之间的时间,如果服务器的时钟没有通过NTP同步,那么写入InfluxDB的数据的时间戳就可能不准确。
Linux安装:
#下载
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.7.9.x86_64.rpm
#安装
sudo yum localinstall influxdb-1.7.9.x86_64.rpm配置:
安装完成后,可通过 influxd config 来查看默认配置。配置文件路径在:/etc/influxdb/influxdb.conf
配置文件里任意没有注释的配置都可以用来覆盖内部默认值,需要注意的是,本地配置文件不需要包括每一项配置。
使用自定义配置启动InfluxDB:
- 运行的时候通过可选参数-config来指定
- influxd -config /etc/influxdb/influxdb.conf
- 设置环境变量INFLUXDB_CONFIG_PATH来指定
注:其中-config的优先级高于环境变量
5、Reference:
简书:https://www.jianshu.com/p/31afb8492eff
WIKI:https://en.wikipedia.org/wiki/Time_series_...
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: