
Laravel 手动搭建简单的数据爬虫
36 / 2 / 创建于 6年前
 GitPush 的个人博客
GitPush 的个人博客
很多爬虫都是使用 python 来写的,其优势是能简单模仿各种请求,以及对文档解析有比较好的支持。
对PHP来说,写一个爬虫就有些麻烦了,不过也有很多强大的第三方库来支撑。
比较知名的PHP爬虫框架
phpspider
git 地址
https://github.com/owner888/phpspider
文档地址
其优点是,简单配置就能直接运行,使用 xPath 选择器一般能获取想要的信息。支持多进程,使用redis能支持断点采集。自动扫描列表页匹配规则链接,自动化比较好。
缺点是如果是采集比较大型网站,很容易被反爬虫机制识别,导致无法获取数据。对Ajax数据没有比较好的处理方案,特别是使用POST方式获取数据。
总结:适合爬取静态页面,没有反爬虫机制的中小型网站。
PHP Selenium
文档地址
https://www.kancloud.cn/wangking/selenium/...
严格来说,这并不属于爬虫。Selenium 是一款前端自动化测试框架。可以使用各种语言来执行 JS 脚本来模拟用户访问界面。
比如提交,验证,点击等等操作事件。因为模仿真实操作来执行数据收集,所以能很好的应对很多反爬虫机制,也是很多人比较喜欢的工具。
其优点是,完美模仿用户行为,能绕过一般反爬虫机制。对数据来源没有要求,只要是在页面渲染的数据,都能获取。表单填写,注册验证也相对比较简单。
缺点是,需要模拟运行浏览器,消耗资源过大。需要写比较多的模拟操作代码来模拟行为。如果操作过于频繁,也会触发网站的机器人验证。
总结:适合少量数据爬取,或者比较深层跳转的页面数据抓取。
自己手动写一个爬虫
PHP并不是特别适合做专业的爬虫工具,但是如果上面两款你都不太满意,那就手动来写一款简易爬虫吧,优点是能应对各种数据类型,能抓取任何你想抓取的页面,缺点当然也很明显,自动化程度并不是很高。
第一步,选择你喜欢的 PHP 框架,我们这里当然选择 Laravel
第二部,安装两个必要的库
Goutte 以及 Guzzle
composer require fabpot/goutte
composer require guzzlehttp/guzzle:~6.0Goutte git 地址
https://github.com/FriendsOfPHP/Goutte
Guzzle git 地址
https://github.com/guzzle/guzzle
Guzzle 文档地址
https://guzzle-cn.readthedocs.io/zh_CN/lat...
Guzzle 库是一套强大的 PHP HTTP 请求套件,能模拟各种请求,例如GET,POST,PUT等,如果你只是用来获取请求的链接内容,例如json字符串,页面的文本信息,那它就足够了。
基本使用方法如下
use GuzzleHttp\Client;
use GuzzleHttp\Psr7\Request as GuzzleRequest;
public function index()
{
$url = "https://www.hao123.com/";
$request = new GuzzleRequest('GET', $url);
$response = $client->send($request, ['timeout' => 5]);
$content = $response->getBody()->getContents();
echo $content;
}其他高级用法请参考文档。
Goutte 库 其实依赖了 Guzzle 以及 DomCrawler
其原理是抓回来的页面数据使用 DomCrawler 来处理,基本爬虫也就是依靠这个来获取数据。
use Goutte\Client as GoutteClient;
public function index()
{
$client = new GoutteClient();
$url = 'https://www.hao123.com/';
$crawler = $client->request('GET', $url);
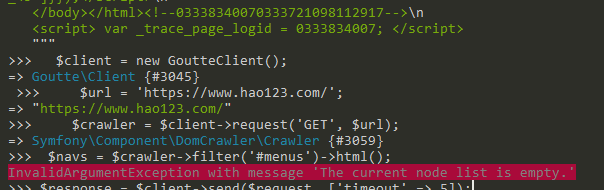
//hao123 导航分类
$navs = $crawler->filter('#menus')->html();
echo $navs;
}这段代码会返回 id 为 menus 的 html 结构,对的,它的filter选择器和Jquery一样,可以支持嵌套以及 each 循环,具体参考文档,我再贴一个循环代码
public function index()
{
$client = new GoutteClient();
$url = 'https://www.hao123.com/';
$crawler = $client->request('GET', $url);
//hao123 导航分类
$navs = $crawler->filter('#menus li');
$navs->each(function ($node) {
echo $node->text().'<br>';
});
}可以打印出该导航下的 li 标签内的每一个选项。其他高级用法请参考文档。
有这两个功能,分析一下需要抓取数据的规律,就可以去写一个自己的爬虫了。
当然,这个Url需要注意的是,并不能只是单纯的填写页面地址,这样可能什么也获取不到。
ajax 数据需要打开开发者面板,去查看获取数据的实际 url,这样就能直接获取结果了。
也有很多网站做了防 curl 获取源码,那就需要另辟蹊径,比如用 wget 命令直接把页面下载到本地,再用 DomCrawler 去截取数据。
参考文章
https://phpartisan.cn/?keyword=laravel%E7%...
本作品采用《CC 协议》,转载必须注明作者和本文链接












 关于 LearnKu
关于 LearnKu




推荐文章: