
数据预处理-数据清理
8 / 0 / 创建于 4年前
 娃哈哈店长 的个人博客
娃哈哈店长 的个人博客
主要是针对数据之中包含缺失的数据,存在异常数据和数据包含噪声的情况。当出现这些情况的时候,需要对数据进行过滤清洗清理。
概况起来,常遇到的数据存在噪声、冗余、关联性、不完整性等。本章将考虑这些问题,在使用算法学习之前,首先需要对数据进行分析,根据数据的不同情况,采用不同的方法对数据进行预处理,数据预处理常见的方法如下:
1. 数据清理:主要是指将数据中缺失的值补充完整、消除噪声数据、识别或删除离群点并解决不一致性。主要是达到如下目标:将数据格式标准化,异常数据清除,错误纠正,重复数据的清除。
2. 数据集成:主要是将多个数据源中的数据进行整合并统一存储。
3. 数据变换:主要是指通过平滑聚集,数据概化,规范化等方式将数据转换成适用于数据挖掘的形式。
4. 数据归约:数据挖掘时往往数据量非常大,因此在少量数据上进行挖掘分析就需要很长的时间,数据归约技术主要是指对数据集进行归约或者简化,不仅保持原数据的完整性,并且数据归约后的结果与归约前结果相同或几乎相同。
这些数据处理技术在数据挖掘之前使用,然后才能输入到机器学习算法中进行学习。这样大大提高了数据挖掘模式的质量,降低实际挖掘所需要的时间
0x00异常数据分析和处理
- MAD法:
MAD又称为绝对值差中位数法(Median Absolute Deviation)。MAD 是一种先需计算所有因子与平均值之间的距离总和来检测离群值的方法。
处理的逻辑:第一步,找出所有因子的中位数 Xmedian;第二步,得到每个因子与中位数的绝对偏差值 Xi−Xmedian;第三步,得到绝对偏差值的中位数 MAD;最后,确定参数 n,从而确定合理的范围为 [Xmedian−nMAD,Xmedian+nMAD],并针对超出合理范围的因子值做如下的调整:
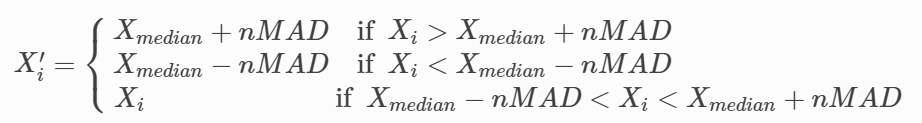
- 3σ法
又称为标准差法。标准差本身可以体现因子的离散程度,是基于因子的平均值 Xmean而定的。在离群值处理过程中,可通过用 Xmean±nσ来衡量因子与平均值的距离。
标准差法处理的逻辑与MAD法类似,首先计算出因子的平均值与标准差,其次确认参数 n(这里选定 n = 3),从而确认因子值的合理范围为 [Xmean−nσ,Xmean+nσ],并对因子值作如下的调整:
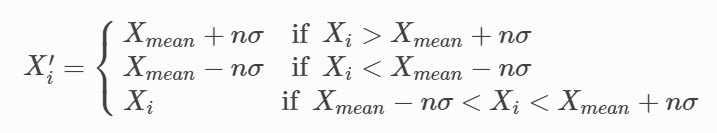
- 百分位法:
计算的逻辑是将因子值进行升序的排序,对排位百分位高于97.5%或排位百分位低于2.5%的因子值,进行类似于 MAD 、 3σ 的方法进行调整。
- 箱型图分析
箱型图提供了一个识别异常值的标准,即大于或小于箱型图设定的上下界的数值即为异常值,箱型图如下图所示:
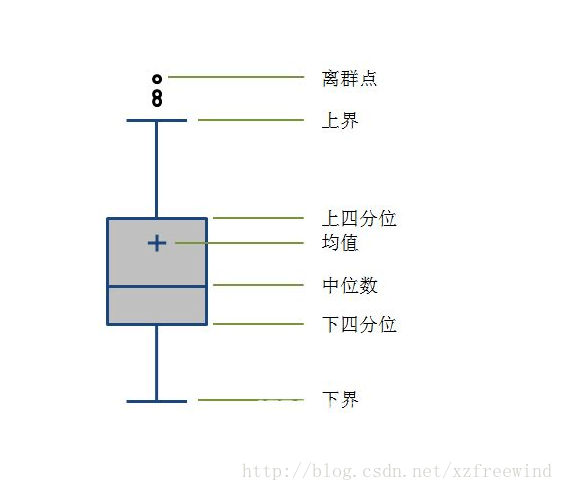
首先我们定义下上四分位和下四分位。
上四分位我们设为 U,表示的是所有样本中只有1/4的数值大于U
同理,下四分位我们设为 L,表示的是所有样本中只有1/4的数值小于L
那么,上下界又是什么呢?
我们设上四分位与下四分位的插值为IQR,即:IQR=U-L
那么,上界为 U+1.5IQR ,下界为: L - 1.5IQR
异常值的处理方法常用有四种:
1.删除含有异常值的记录
2.将异常值视为缺失值,交给缺失值处理方法来处理
3.用平均值来修正
4.不处理
需要强调的是,如何判定和处理异常值,需要结合实际。
0x01缺失值处理
造成数据缺失的原因是多方面的,主要可能有以下几种:
1. 有些信息暂时无法获取,致使一部分属性值空缺出来。
2. 有些信息因为一些人为因素而丢失了。
3. 有些对象的某个或某些属性是不可用的。如一个未婚者的配偶姓名。
4. 获取这些信息的代价太大,从而未获取数据。
空值的存在,造成了以下影响:
1. 系统丢失了大量的有用信息;
2. 系统的不确定性更加显著,系统中的确定性成分更难把握;
3. 包含空值的数据会使挖掘过程陷入混乱,导致不可靠的输出。
处理缺失值的方法有很多,如忽略存在缺失数据的记录、
手工填写缺失值、使用默认值代替缺失值、使用属性平均值 去掉包含缺失数据的属性、使用同类样本平均值代替缺失值、预测最可能的值代替缺失值等。(中位数或众数)代替缺失值、
其中,经常使用数据补插方法来代替缺失值,这些方法又可以细分为以下几种。
(1)最近邻补插:使用含有缺失值的样本附近的其他样本的数据替代:或者前后教据的平均值替代等。
(2)回归方法:对含有缺失值的属性,使用其他样本该属性的值建立拟合模型, 然后使用该模型预测缺失值。
(3)插值法:和回归法类似,该方法使用已知数据建立合适的插值函数,缺失值使用该函数计算出近似值代替。常见的插值函数有拉格朗日插值法、牛顿插值法、分段插值法、样条插值法、Hermite 插值法等。
0x02噪声数据处理
1.噪声是什么?数据集中的干扰数据(对场景描述不准确的数据)
2.噪声怎么产生的?举个例子:手机信号来自于基站发射的电磁波,有的地方比较强,有的地方比较弱。运营商的工程师会负责统计不同区域信号强弱来进行网络规划,工程师采集信号的方法就是将一个信号接受终端固定到车上,然后开车绕着基站转,信号终端就会自动采集不同区域的信号强度,生成一份数据。但是如果车在采集过程中遇到了突发事件、急刹车,就可能会对信号采集造成一定的影响,生成噪声数据。
3.噪声对模型训练有什么影响?很多算法,特别是线性算法,都是通过迭代来获取最优解的,如果数据中含有大量的噪声数据,将会大大的影响数据的收敛速度,甚至对于训练生成模型的准确也会有很大的副作用。
0x03去除噪声方法1-正态分布
根据不同的业务场景有不同的处理方法,这里只提出正态分布3σ原则。正态分布也叫常态分布,是连续随机变量概率分布的一种,自然界、人类社会、心理、教育中大量现象均按正态分布,如能力的高低、学生成绩的好坏都属于正态分布,我们可以把数据集的质量分布立杰成一个正态分布。它会随着随机变量的平均数、标准差与单位不同而有不同的分布形态。正态分布可以表示成一种概率密度函数。
正态分布公式
其中,σ可以表示成数据集的标准差,μ代表数据集的均值,x代表数据集的数据。相对于正常数据,噪声数据可以理解为小概率数据。
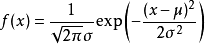
正态分布具有这样的特点:x落在(μ-3σ,μ+3σ)以外的概率小于千分之三。根据这一特点,我们可以通过计算数据集的标准差,把三倍于数据集的标准差的点设想为噪声数据排除。
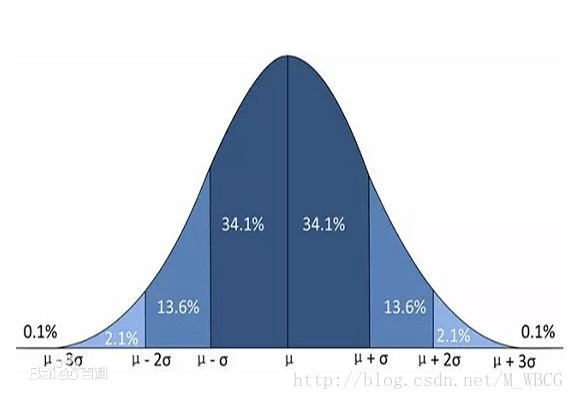
示例
from __future__ import division
mat = [[19, 26, 63], [13, 62, 65], [16, 69, 15], [14, 56, 17], [19, 6, 15], [11, 42, 15], [18, 58, 36], [12, 77, 33],
[10, 75, 47], [15, 54, 70], [10017, 1421077, 4169]]
# 获得矩阵的字段数量
def width(lst):
i = 0;
for j in lst[0]:
i += 1
return i
# 得到每个字段的平均值
def GetAverage(mat):
n = len(mat)
m = width(mat)
num = [0] * m
for i in range(0, m):
for j in mat:
num[i] += j[i]
num[i] = num[i] / n
return num
# 获得每个字段的标准差
def GetVar(average, mat):
ListMat = []
for i in mat:
ListMat.append(list(map(lambda x: x[0] - x[1], zip(average, i))))
n = len(ListMat)
m = width(ListMat)
num = [0] * m
for j in range(0, m):
for i in ListMat:
num[j] += i[j] * i[j]
num[j] /= n
return num
# 获得每个字段的标准差
def GetStandardDeviation(mat):
return list(map(lambda x:x**0.5,mat))
# 对数据集去噪声
def DenoisMat(mat):
average = GetAverage(mat)
variance = GetVar(average, mat)
standardDeviation=GetStandardDeviation(variance)
section = list(map(lambda x: x[0] + 3*x[1], zip(average, standardDeviation)))
n = len(mat)
m = width(mat)
num = [0] * m
denoisMat = []
noDenoisMat=[]
for i in mat:
for j in range(0, m):
if i[j] > section[j]:
denoisMat.append(i)
break
if j==(m-1):
noDenoisMat.append(i)
print("去除完噪声的数据:")
print(noDenoisMat)
print("噪声数据:")
return denoisMat
if __name__ == '__main__':
print("初始数据:")
print(mat)
print(DenoisMat(mat))
0x04去除噪声方法2-分箱
分箱方法是一种简单常用的预处理方法,通过考察相邻数据来确定最终值。所谓“分箱”,实际上就是按照属性值划分的子区间,如果一个属性值处于某个子区间范围内,就称把该属性值放进这个子区间所代表的“箱子”内。把待处理的数据(某列属性值)按照一定的规则放进一些箱子中,考察每一个箱子中的数据,采用某种方法分别对各个箱子中的数据进行处理。在采用分箱技术时,需要确定的两个主要问题就是:如何分箱以及如何对每个箱子中的数据进行平滑处理。
分箱的方法:有4种:等深分箱法、等宽分箱法、最小熵法和用户自定义区间法。
统一权重,也成等深分箱法,将数据集按记录行数分箱,每箱具有相同的记录数,每箱记录数称为箱子的深度。这是最简单的一种分箱方法。
统一区间,也称等宽分箱法,使数据集在整个属性值的区间上平均分布,即每个箱的区间范围是一个常量,称为箱子宽度。
用户自定义区间,用户可以根据需要自定义区间,当用户明确希望观察某些区间范围内的数据分布时,使用这种方法可以方便地帮助用户达到目的。
例:客户收入属性income排序后的值(人民币元):800 1000 1200 1500 1500 1800 2000 2300 2500 2800 3000 3500 4000 4500 4800 5000,分箱的结果如下。
统一权重:设定权重(箱子深度)为4,分箱后
箱1:800 1000 1200 1500
箱2:1500 1800 2000 2300
箱3:2500 2800 3000 3500
箱4:4000 4500 4800 5000
统一区间:设定区间范围(箱子宽度)为1000元人民币,分箱后
箱1:800 1000 1200 1500 1500 1800
箱2:2000 2300 2500 2800 3000
箱3:3500 4000 4500
箱4:4800 5000
用户自定义:如将客户收入划分为1000元以下、1000 ~ 2000、2000 ~ 3000、3000 ~ 4000和4000元以上几组,分箱后
箱1:800
箱2:1000 1200 1500 1500 1800 2000
箱3:2300 2500 2800 3000
箱4:3500 4000
箱5:4500 4800 5000
分箱后需要对每一个数据求平均值处理
数据平滑方法:按平均值平滑、按边界值平滑和按中值平滑。
⑴按平均值平滑
对同一箱值中的数据求平均值,用平均值替代该箱子中的所有数据。
⑵按边界值平滑
用距离较小的边界值替代箱中每一数据。
⑶按中值平滑
取箱子的中值,用来替代箱子中的所有数据。
0x05聚类方法
将物理的或抽象对象的集合分组为由类似的对象组成的多个类。
找出并清除那些落在簇之外的值(孤立点),这些孤立点被视为噪声。
0x06回归方法
试图发现两个相关的变量之间的变化模式,通过使数据适合一个函数来平滑数据,即通过建立数学模型来预测下一个数值,包括线性回归和非线性回归。
本作品采用《CC 协议》,转载必须注明作者和本文链接


 关于 LearnKu
关于 LearnKu



