
记一次 MySQL 数据库单表恢复事故处理
1 / 4 / 创建于 6年前 /
 Martist 的个人博客
Martist 的个人博客
公司web服务架设在阿里云全家桶上,数据库用的也是RDS
昨晚10点,运营同事在社区发文章,提示创建失败,查看接口项目的日志,是detail字段的类型为text,可能是不够,需要加长,我选择了mediumtext类型。
| 数据类型 | 长度 |
|---|---|
| TINYTEXT | 256 bytes |
| TEXT | 65,535 bytes~64kb |
| MEDIUMTEXT | 16,777,215 bytes~16M |
| BLONGTEXT | 4,294,967,295 bytes~4GB |
然后执行一个DDL语句,如下:
ALTER TABLE `databasename`.`tablename` CHANGE COLUMN `question_detail` `question_detail` mediumint DEFAULT NULL COMMENT '内容';执行完了,好的,告诉运营同事,看下可以发文章了么?
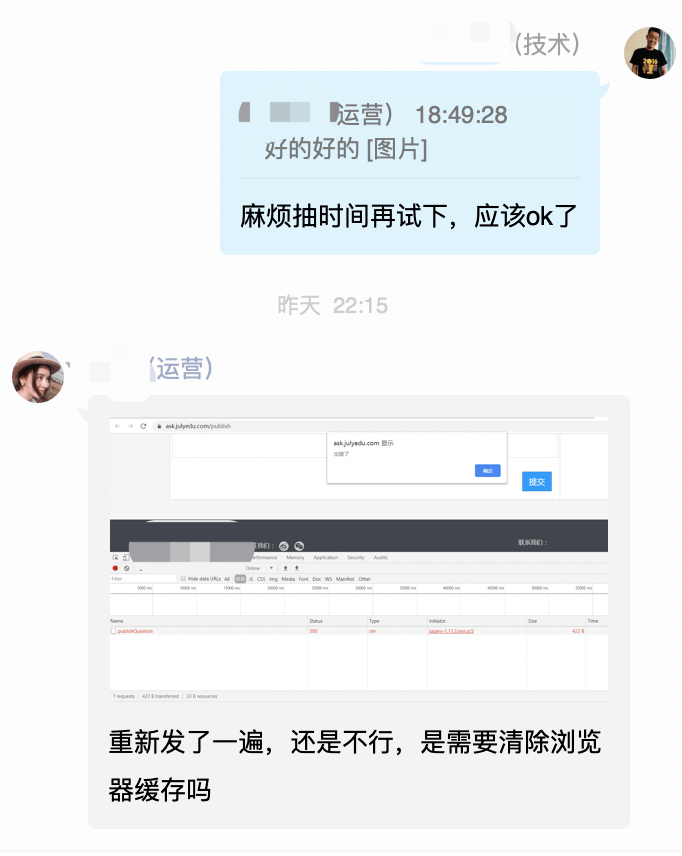
还是不行,哦,DDL写错了,应该是【mediumtext】,这里错了,把正确的DDL语句执行一遍,再问下运营同事
ALTER TABLE `databasename`.`tablename` CHANGE COLUMN `question_detail` `question_detail` mediumtext DEFAULT NULL COMMENT '内容';
基于一个好的习惯,我再去社区确认下,运营同事的新帖子内容挺不错,在随便点点别的帖子。
嗯?我凑???社区全部帖子的内容变成0了,如下
懵逼了,生产事故吖,看看咋回事,一个想法闪过,sql有问题,我用navicat生成的sql语句,更新后的数据类型应该是【mediumtext】,结果我敲到med的时候,他就主动补全了【mediumint】,没有看清,就放到生产执行了,一下子把所有detail的内容,强制转换成了数字??
黑人问号脸.jpg
ok,开始想办法恢复数据,中间各种想办法,最后依靠阿里云提供的数据备份管理功能,和本人一瞬间暴涨的工作效率和好运气,在今天凌晨1点搞定了。
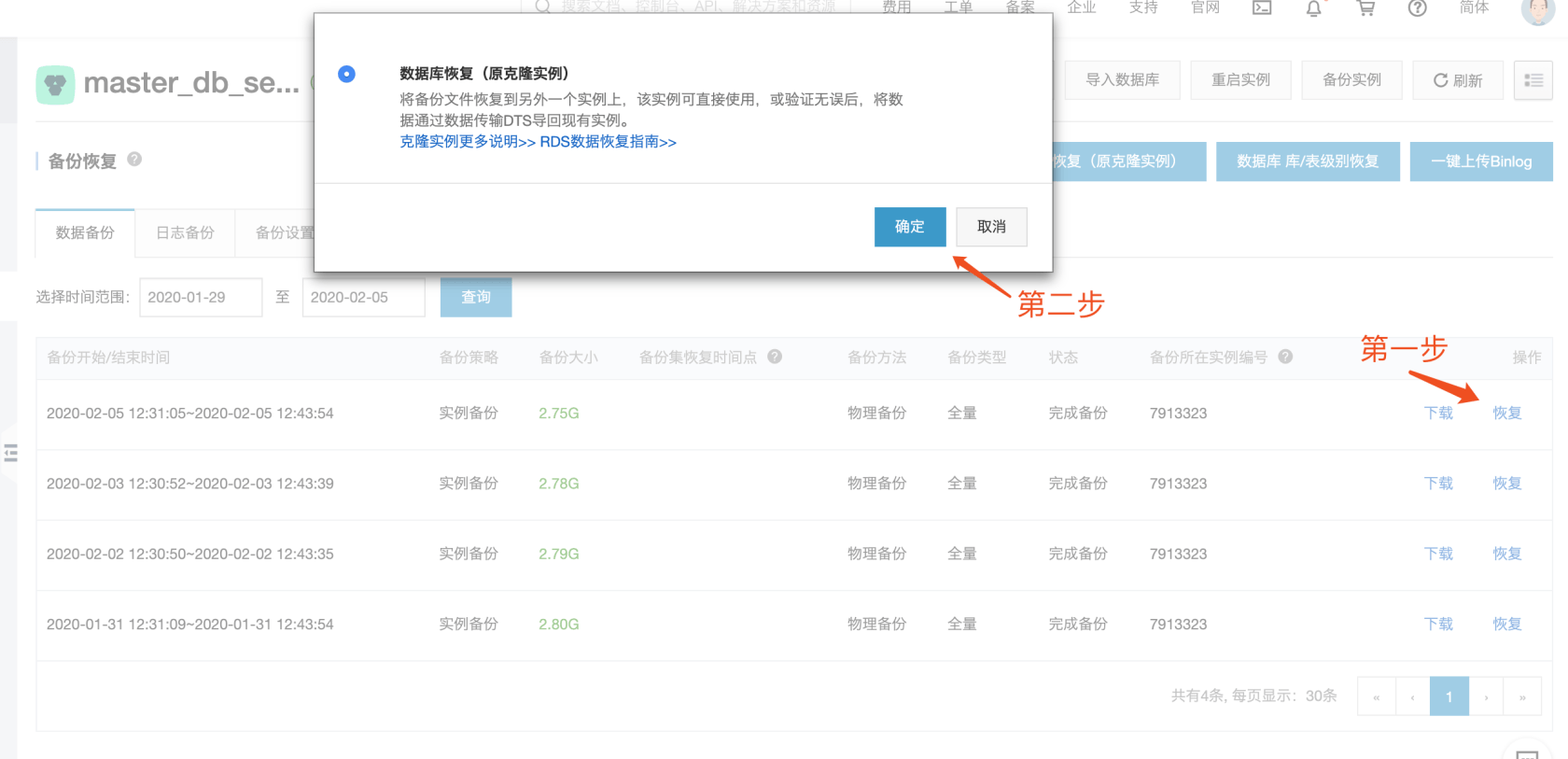
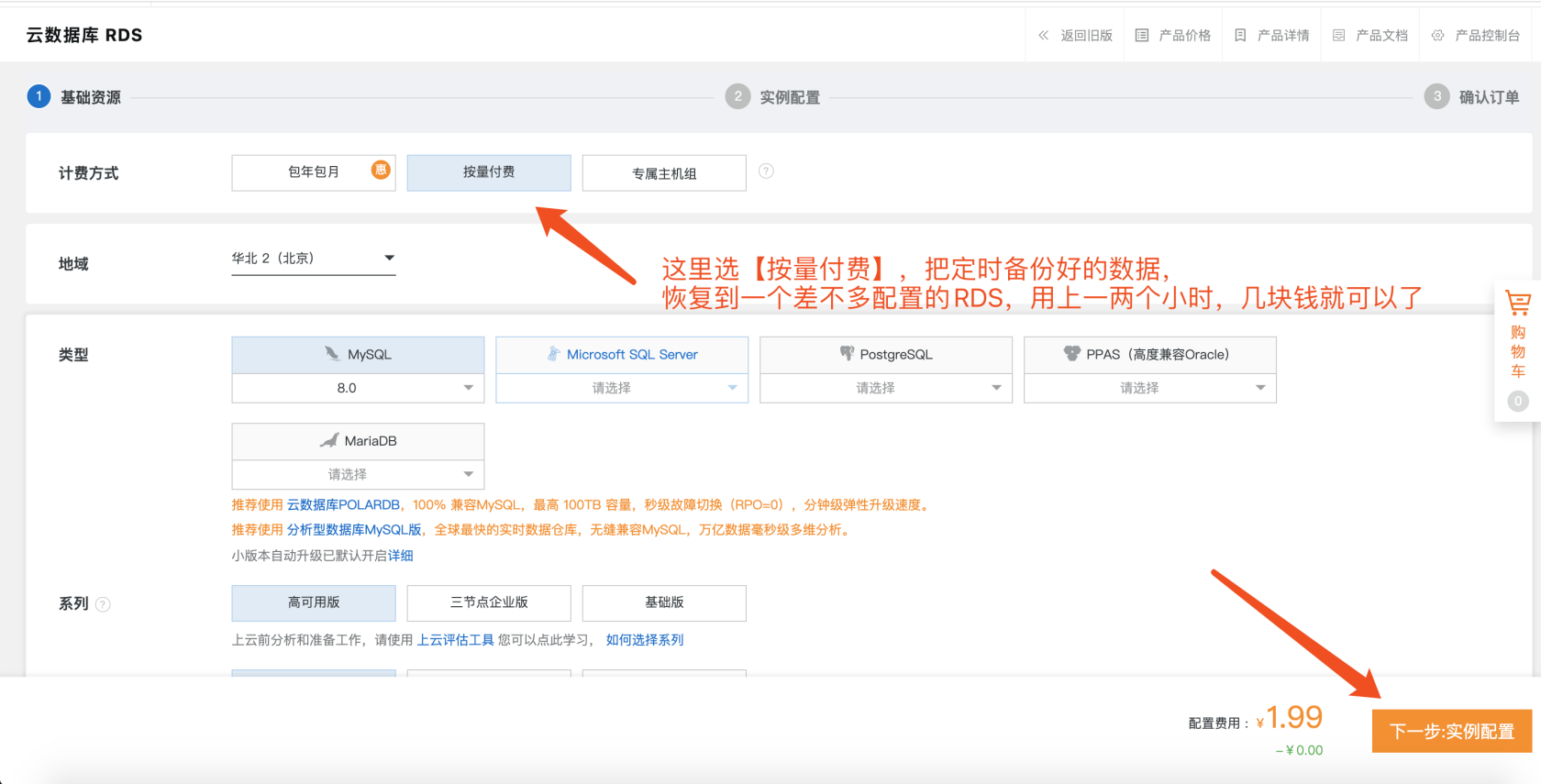
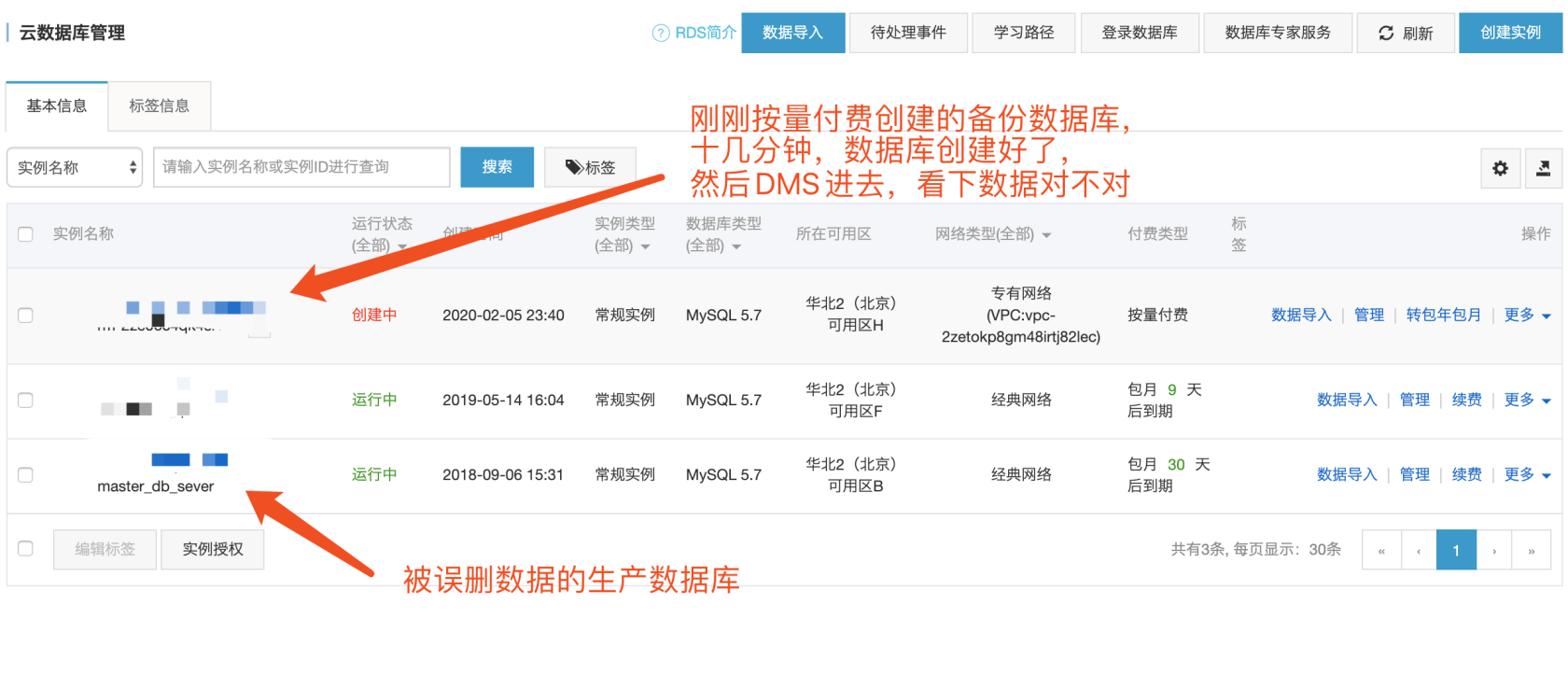
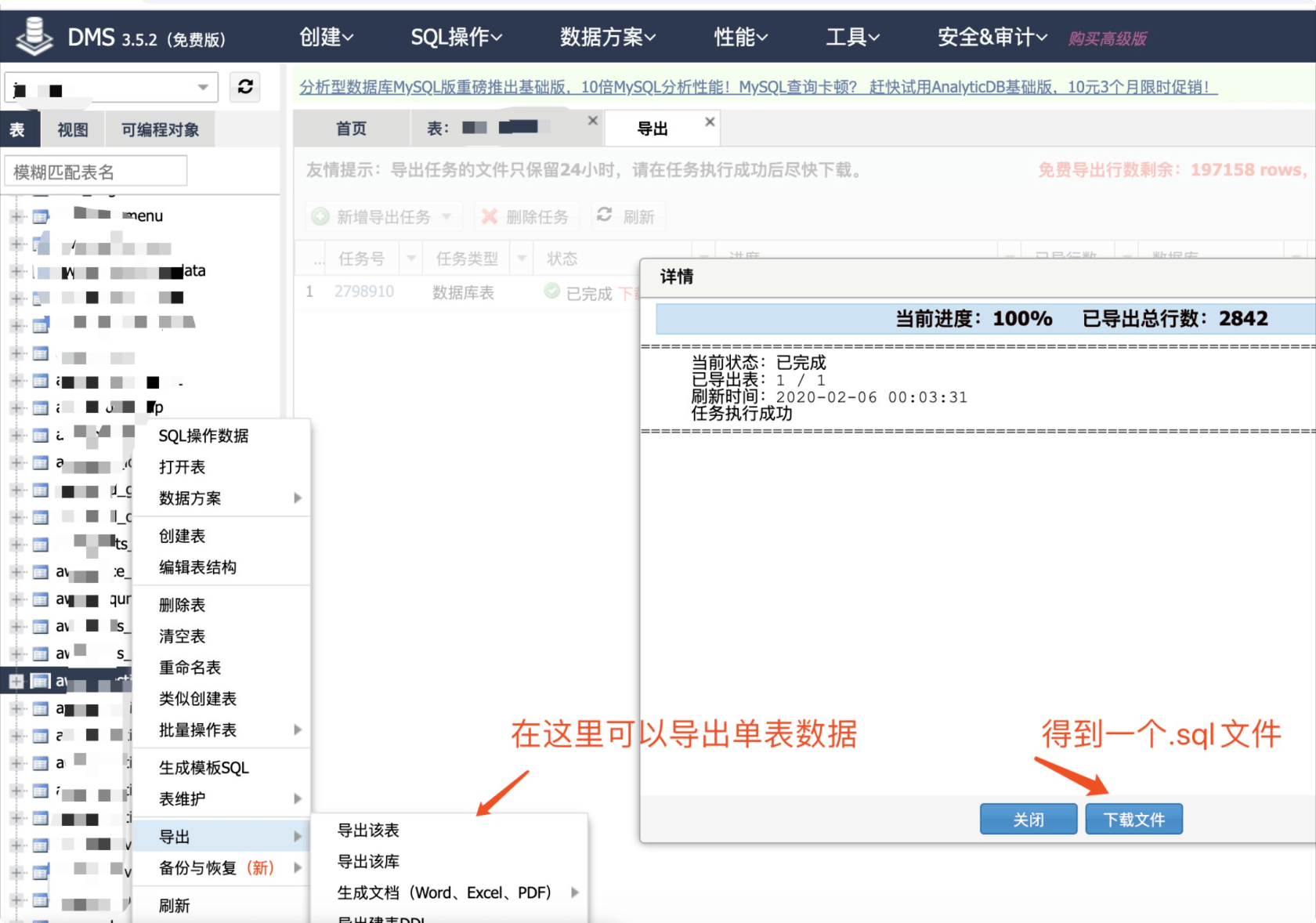
至此,我得到了这个表本来的数据了,好在备份时间和发成事故的时间很相近,又是过年期间发帖频率很低,查一下表内行数,好的,备份库的贴子表只差一个生产库一行,应该就是运营那一篇了,哈哈哈。
执行一个兜底命令,重命名帖子表,先不要删掉这个表,避免一错再错
RENAME TABLE aws_question to aws_question_bak;然后把导出来的.sql文件上传到可以连接生产库的服务器,然后把这个.sql执行下,导入到生产库里
$ mysql -h hostname -u username -p < restore.sql
Enter password: #输入root用户的密码。再回来看看贴子,好的,数据恢复了。

回过头来,我们在执行一遍更新字段数据类型的sql
ALTER TABLE `databasename`.`tablename` CHANGE COLUMN `question_detail` `question_detail` mediumtext DEFAULT NULL COMMENT '内容';把运营同事新写的文章,从bak表拿出来,导入到本表中,至此,数据完全存进去了。
😁Happyending😁

本作品采用《CC 协议》,转载必须注明作者和本文链接
















 关于 LearnKu
关于 LearnKu




推荐文章: