
掌握它才说明你真正懂 Elasticsearch - Lucene (二)
1 / 2 / 创建于 6年前 /
 CrazyZard 的个人博客
CrazyZard 的个人博客
分段存储
在早期的全文检索中为整个文档集合建立了一个很大的倒排索引,并将其写入磁盘中,如果索引有更新,就需要重新全量创建一个索引来替换原来的索引。
这种方式在数据量很大时效率很低,并且由于创建一次索引的成本很高,所以对数据的更新不能过于频繁,也就不能保证实效性。
现在,在搜索中引入了段的概念(将一个索引文件拆分为多个子文件,则每个子文件叫做段),每个段都是一个独立的可被搜索的数据集,并且段具有不变性,一旦索引的数据被写入硬盘,就不可修改。
在分段的思想下,对数据写操作的过程如下:
-
新增:当有新的数据需要创建索引时,由于段段不变性,所以选择新建一个段来存储新增的数据。
-
删除:当需要删除数据时,由于数据所在的段只可读,不可写,所以 Lucene 在索引文件新增一个 .del 的文件,用来专门存储被删除的数据 id。
当查询时,被删除的数据还是可以被查到的,只是在进行文档链表合并时,才把已经删除的数据过滤掉。被删除的数据在进行段合并时才会被真正被移除。
-
更新:更新的操作其实就是删除和新增的组合,先在.del文件中记录旧数据,再在新段中添加一条更新后的数据。
段不可变性的优点如下:
-
不需要锁:因为数据不会更新,所以不用考虑多线程下的读写不一致情况。
-
可以常驻内存:段在被加载到内存后,由于具有不变性,所以只要内存的空间足够大,就可以长时间驻存,大部分查询请求会直接访问内存,而不需要访问磁盘,使得查询的性能有很大的提升。
-
缓存友好:在段的声明周期内始终有效,不需要在每次数据更新时被重建。
-
增量创建:分段可以做到增量创建索引,可以轻量级地对数据进行更新,由于每次创建的成本很低,所以可以频繁地更新数据,使系统接近实时更新。
段不可变性的缺点如下:
-
删除:当对数据进行删除时,旧数据不会被马上删除,而是在 .del 文件中被标记为删除。而旧数据只能等到段更新时才能真正地被移除,这样会有大量的空间浪费。
-
更新:更新数据由删除和新增这两个动作组成。若有一条数据频繁更新,则会有大量的空间浪费。
-
新增:由于索引具有不变性,所以每次新增数据时,都需要新增一个段来存储数据。当段段数量太多时,对服务器的资源(如文件句柄)的消耗会非常大,查询的性能也会受到影响。
-
过滤:在查询后需要对已经删除的旧数据进行过滤,这增加了查询的负担。
为了提升写的性能,Lucene 并没有每新增一条数据就增加一个段,而是采用延迟写的策略,每当有新增的数据时,就将其先写入内存中,然后批量写入磁盘中。
若有一个段被写到硬盘,就会生成一个提交点,提交点就是一个用来记录所有提交后的段信息的文件。
一个段一旦拥有了提交点,就说明这个段只有读的权限,失去了写的权限;相反,当段在内存中时,就只有写数据的权限,而不具备读数据的权限,所以也就不能被检索了。
从严格意义上来说,Lucene 或者 Elasticsearch 并不能被称为实时的搜索引擎,只能被称为准实时的搜索引擎。
写索引的流程如下:
-
新数据被写入时,并没有被直接写到硬盘中,而是被暂时写到内存中。Lucene 默认是一秒钟,或者当内存中数据量达到一定阶段时,再批量提交到磁盘中。
当然,默认的时间和数据量的大小是可以通过参数控制的。通过延时写的策略,可以减少数据往磁盘上写的次数,从而提升整体的写入性能,如图 3。
-
在达到出触发条件以后,会将内存中缓存的数据一次性写入磁盘中,并生成提交点。
-
清空内存,等待新的数据写入,如下图所示。
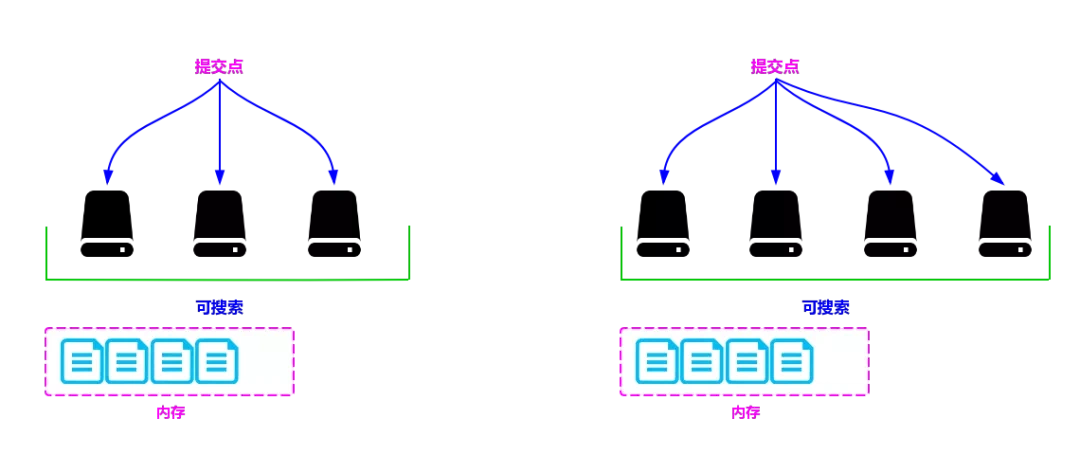
从上述流程可以看出,数据先被暂时缓存在内存中,在达到一定的条件再被一次性写入硬盘中,这种做法可以大大提升数据写入的速度。
但是数据先被暂时存放在内存中,并没有真正持久化到磁盘中,所以如果这时出现断电等不可控的情况,就会丢失数据,为此,Elasticsearch 添加了事务日志,来保证数据的安全。
段合并策略
虽然分段比每次都全量创建索引有更高的效率,但是由于在每次新增数据时都会新增一个段,所以经过长时间的的积累,会导致在索引中存在大量的段。
当索引中段的数量太多时,不仅会严重消耗服务器的资源,还会影响检索的性能。
因为索引检索的过程是:查询所有段中满足查询条件的数据,然后对每个段里查询的结果集进行合并,所以为了控制索引里段的数量,我们必须定期进行段合并操作。
但是如果每次合并全部的段,则会造成很大的资源浪费,特别是“大段”的合并。
所以 Lucene 现在的段合并思路是:根据段的大小将段进行分组,再将属于同一组的段进行合并。
但是由于对于超级大的段的合并需要消耗更多的资源,所以 Lucene 会在段的大小达到一定规模,或者段里面的数据量达到一定条数时,不会再进行合并。
所以 Lucene 的段合并主要集中在对中小段的合并上,这样既可以避免对大段进行合并时消耗过多的服务器资源,也可以很好地控制索引中段的数量。
段合并的主要参数如下:
-
mergeFactor:每次合并时参与合并的最少数量,当同一组的段的数量达到此值时开始合并,如果小于此值则不合并,这样做可以减少段合并的频率,其默认值为 10。
-
SegmentSize:指段的实际大小,单位为字节。
-
minMergeSize:小于这个值的段会被分到一组,这样可以加速小片段的合并。
-
maxMergeSize:若有一段的文本数量大于此值,就不再参与合并,因为大段合并会消耗更多的资源。
段合并相关的动作主要有以下两个:
-
对索引中的段进行分组,把大小相近的段分到一组,主要由 LogMergePolicy1 类来处理。
-
将属于同一分组的段合并成一个更大的段。
在段合并前对段的大小进行了标准化处理,通过 logMergeFactorSegmentSize 计算得出。
其中 MergeFactor 表示一次合并的段的数量,Lucene 默认该数量为 10;SegmentSize 表示段的实际大小。通过上面的公式计算后,段的大小更加紧凑,对后续的分组更加友好。
段分组的步骤如下:
①根据段生成的时间对段进行排序,然后根据上述标准化公式计算每个段的大小并且存放到段信息中,后面用到的描述段大小的值都是标准化后的值,如图 4 所示:
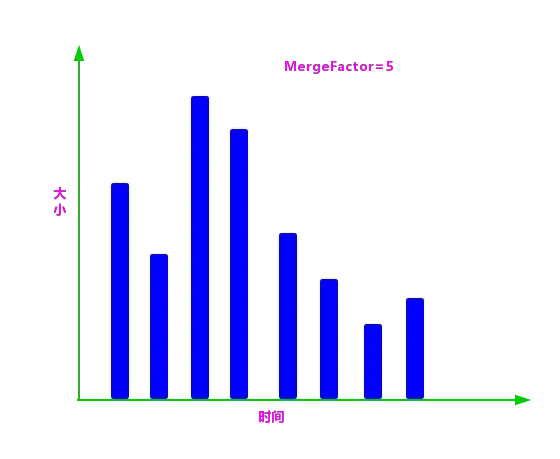
图 4:Lucene 段排序
②在数组中找到最大的段,然后生成一个由最大段的标准化值作为上限,减去 LEVEL_LOG_SPAN(默认值为 0.75)后的值作为下限的区间,小于等于上限并且大于下限的段,都被认为是属于同一组的段,可以合并。
③在确定一个分组的上下限值后,就需要查找属于这个分组的段了,具体过程是:创建两个指针(在这里使用指针的概念是为了更好地理解)start 和 end。
start 指向数组的第 1 个段,end 指向第 start+MergeFactor 个段,然后从 end 逐个向前查找落在区间的段。
当找到第 1 个满足条件的段时,则停止,并把当前段到 start 之间的段统一分到一个组,无论段的大小是否满足当前分组的条件。
如图 5 所示,第 2 个段明显小于该分组的下限,但还是被分到了这一组。
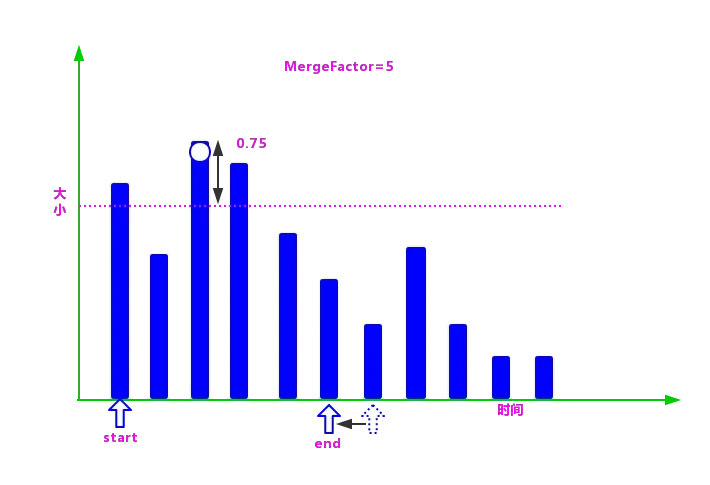
这样做的好处如下:
-
增加段合并的概率,避免由于段的大小参差不齐导致段难以合并。
-
简化了查找的逻辑,使代码的运行效率更高。
④在分组找到后,需要排除不参加合并的“超大”段,然后判断剩余的段是否满足合并的条件。
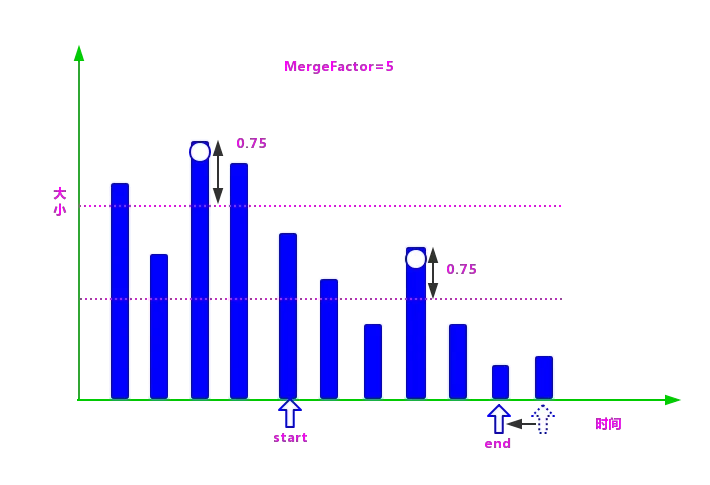
如图 5 所示,mergeFactor=5,而找到的满足合并条件的段的个数为 4,所以不满足合并的条件,暂时不进行合并,继续找寻下一个组的上下限。
⑤由于在第 4 步并没有找到满足段合并的段的数量,所以这一分组的段不满足合并的条件,继续进行下一分组段的查找。
具体过程是:将 start 指向 end,在剩下的段(从 end 指向的元素开始到数组的最后一个元素)中寻找最大的段,在找到最大的值后再减去 LEVEL_LOG_SPAN 的值,再生成一下分组的区间值。
然后把 end 指向数组的第 start+MergeFactor 个段,逐个向前查找第 1 个满足条件的段:重复第 3 步和第 4 步。
⑥如果一直没有找到满足合并条件的段,则一直重复第 5 步,直到遍历完整个数组,如图所示:
⑦在找到满足条件的 mergeFactor 个段时,就需要开始合并了。但是在满足合并条件的段大于 mergeFactor 时,就需要进行多次合并。
也就是说每次依然选择 mergeFactor 个段进行合并,直到该分组的所有段合并完成,再进行下一分组的查找合并操作。
⑧通过上述几步,如果找到了满足合并要求的段,则将会进行段的合并操作。
因为索引里面包含了正向信息和反向信息,所以段合并的操作分为两部分:
-
一个是正向信息合并,例如存储域、词向量、标准化因子等。
-
一个是反向信息的合并,例如词典、倒排表等。
在段合并时,除了需要对索引数据进行合并,还需要移除段中已经删除的数据。
Lucene 相似度打分
我们在前面了解到,Lucene 的查询过程是:首先在词典中查找每个 Term,根据 Term 获得每个 Term 所在的文档链表;然后根据查询条件对链表做交、并、差等操作,链表合并后的结果集就是我们要查找的数据。
这样做可以完全避免对关系型数据库进行全表扫描,可以大大提升查询效率。
但是,当我们一次查询出很多数据时,这些数据和我们的查询条件又有多大关系呢?其文本相似度是多少?
本节会回答这个问题,并介绍 Lucene 最经典的两个文本相似度算法:基于向量空间模型的算法和基于概率的算法(BM25)。
如果对此算法不太感兴趣,那么只需了解对文本相似度有影响的因子有哪些,哪些是正向的,哪些是逆向的即可,不需要理解每个算法的推理过程。但是这两个文本相似度算法有很好的借鉴意义。
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




单一进程的大批量频繁写入会影响查询吗?