
「DNN for YouTube Recommendations」- 论文阅读
0 / 0 / 创建于 6年前 /
 娃哈哈店长 的个人博客
娃哈哈店长 的个人博客
论文原址:https://cseweb.ucsd.edu/classes/fa17/cse29...
Deep Neural Networks for YouTube Recommendations
Paul Covington, Jay Adams, Emre Sargin
Google
Mountain View, CA
{pcovington, jka, msargin}@google.com
ABSTRACT
YouTube represents one of the largest scale and most sophisticated industrial recommendation systems in existence. Inthis paper, we describe the system at a high level and focus on the dramatic performance improvements brought by deep learning. The paper is split according to the classic two-stage information retrieval dichotomy: first, we detail a deep candidate generation model and then describe a sepa-rate deep ranking model. We also provide practical lessons and insights derived from designing, iterating and maintain-ing a massive recommendation system with enormous user-facing impact.
YouTube代表了目前规模最大,最复杂的行业推荐系统之一。 在本文中,我们从较高的角度描述了该系统,并着重讨论了深度学习带来的显着性能提升。
本文根据经典的两阶段信息检索二分法进行了拆分:
首先,我们详细介绍了深层候选生成模型,然后描述了一个单独的深度排名模型。 我
们还提供从设计,迭代和维护庞大的推荐系统中获得的实践经验和见解,这些建议系统具有巨大的面向用户的影响。
Keywords
recommender system; deep learning; scalability(可扩展性)
1. INTRODUCTION
YouTube is the world’s largest platform for creating, shar-ing and discovering video content. YouTube recommenda-tions are responsible for helping more than a billion usersdiscover personalized content from an ever-growing corpusof videos. In this paper we will focus on the immense im-pact deep learning has recently had on the YouTube videorecommendations system.
YouTube是世界上最大的创建,共享和发现视频内容的平台。 YouTube的建议负责帮助超过十亿用户从不断增长的视频库中发现个性化内容。 在本文中,我们将重点介绍最近在YouTube视频推荐系统上深度学习产生的巨大影响(immense impact).

Figure 1 illustrates the recom-mendations on the YouTube mobile app home.
Recommending YouTube videos is extremely challenging from three major perspectives:
Scale:Many existing recommendation algorithms provento work well on small problems fail to operate on ourscale. Highly specialized distributed learning algorithmsand efficient serving systems are essential for handlingYouTube’s massive user base and corpus.
Freshness:YouTube has a very dynamic corpus withmany hours of video are uploaded per second. Therecommendation system should be responsive enoughto model newly uploaded content as well as the lat-est actions taken by the user. Balancing new content with well-established videos can be understood froman exploration/exploitation perspective.
Noise:Historical user behavior on YouTube is inher-ently difficult to predict due to sparsity and a vari-ety of unobservable external factors. We rarely ob-tain the ground truth of user satisfaction and insteadmodel noisy implicit feedback signals. Furthermore,metadata associated with content is poorly structuredwithout a well defined ontology. Our algorithms need to be robust to these particular characteristics of ourtraining data.
从三个主要方面来看,推荐YouTube视频具有极大的挑战性:
Scale:许多现有的推荐算法被证明可以很好地解决小问题,但无法在我们的规模上运行。 高度专业的分布式学习算法和高效的服务系统对于处理YouTube庞大的用户群和语料库至关重要。
Freshness:YouTube具有非常动态的语料库,每秒上传多个小时的视频。 推荐系统应具有足够的响应能力,以对新上传的内容以及用户采取的最新操作进行建模。 从探索/开发的角度来看,可以将新内容与成熟的视频相结合。
Noise:由于稀疏性和各种不可观察的外部因素,YouTube上的历史用户行为本来就很难预测。 我们很少获得用户满意度的基本事实,而是建模嘈杂的隐式反馈信号。 此外,与内容相关的元数据在没有定义良好的本体的情况下结构较差。 我们的算法必须对训练数据的这些特定特征具有健壮性(robust)。
In conjugation with other product areas across Google,YouTube has undergone a fundamental paradigm shift to-wards using deep learning as a general-purpose solution fornearly all learning problems. Our system is built on GoogleBrain [4] which was recently open sourced as TensorFlow [1].TensorFlow provides a flexible framework for experimenting with various deep neural network architectures using large-scale distributed training. Our models learn approximatelyone billion parameters and are trained on hundreds of bil-lions of examples.
与Google的其他产品领域相结合( In conjugation with),YouTube已经发生了根本的模范式地(paradigm)转变,即使用深度学习作为解决所有学习问题的通用解决方案。 我们的系统建立在Google Brain (最近在TensorFlow中开源)的基础上。TensorFlow提供了灵活的框架,可使用大规模分布式训练来尝试各种深度神经网络架构。 我们的模型学习了大约十亿个参数,并针对数十亿个示例进行了训练。
In contrast to vast amount of research in matrix factorization methods [19], there is relatively little work using deep neural networks for recommendation systems. Neural net-works are used for recommending news in [17], citations in[8] and review ratings in [20]. Collaborative filtering is for-mulated as a deep neural network in [22] and autoencodersin [18]. Elkahkyet al. used deep learning for cross domainuser modeling [5]. In a content-based setting, Burgeset al.used deep neural networks for music recommendation.
与矩阵分解方法(matrix factorization methods)的大量研究相反[19],使用深度神经网络进行推荐系统的工作相对较少。 神经网络在[17]中用于推荐新闻,在[8]中用于引用,在[20]中用于评价等级。 协作过滤(Collaborative filtering)在[22]中被模拟为一个深度神经网络,在[18]中被模拟为自动编码器。 Elkahkyet等使用深度学习进行跨域用户建模[5]。 在基于内容的设置中,Burgeset等人使用深度神经网络进行音乐推荐。
The paper is organized as follows: A brief system overviewis presented in Section 2. Section 3 describes the candidategeneration model in more detail, including how it is trainedand used to serve recommendations. Experimental resultswill show how the model benefits from deep layers of hiddenunits and additional heterogeneous signals. Section 4 detailsthe ranking model, including how classic logistic regressionis modified to train a model predicting expected watch time(rather than click probability). Experimental results willshow that hidden layer depth is helpful as well in this situa-tion. Finally, Section 5 presents our conclusions and lessonslearned.
本文的组织结构如下:在第2节中进行了简要的系统概述。第3节更详细地描述了候选代模型,包括如何训练候选者模型以及如何使用它来提供建议。 实验结果将显示该模型如何受益于隐藏单元的深层和其他异构信号。 第4节详细介绍了排名模型,包括如何修改经典逻辑回归以训练模型以预测预期观看时间(而非点击概率)。 实验结果表明,在这种情况下,隐藏层的深度也是有帮助的。 最后,第5节介绍了我们的结论和经验教训。
2. SYSTEM OVERVIEW
The overall structure of our recommendation system is il-lustrated in Figure 2. The system is comprised of two neuralnetworks: one forcandidate generation and one forranking.
我们的推荐系统的总体结构如图2所示。该系统由两个神经网络组成:一个候选代和一个排名。
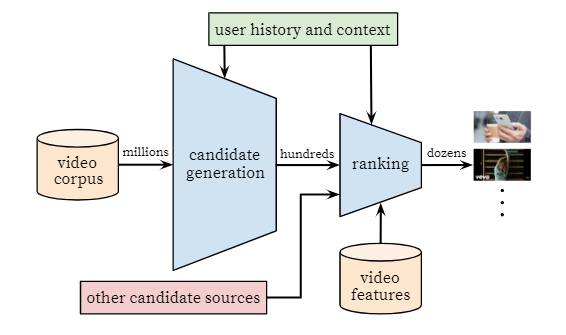
Figure 2: Recommendation system architecturedemonstrating the “funnel” where candidate videosare retrieved and ranked before presenting only afew to the user.
The candidate generation network takes events from the user’s YouTube activity history as input and retrieves a small subset (hundreds) of videos from a large corpus. Thesecandidates are intended to be generally relevant to the userwith high precision. The candidate generation network onlyprovides broad personalization via collaborative filtering.The similarity between users is expressed in terms of coarsefeatures such as IDs of video watches, search query tokensand demographics
候选生成网络从用户的YouTube活动历史记录中获取事件作为输入,并从大型语料库中检索(retrieves)一小部分(数百个)视频。 这些候选人通常与高精度的用户相关。 候选生成网络仅通过协作过滤来提供广泛的个性化。用户之间的相似性通过诸如视频观看ID,搜索查询令牌和人口统计等粗略特征来表达
Presenting a few “best” recommendations in a list requires a fine-level representation to distinguish relative importance among candidates with high recall. The ranking networkaccomplishes this task by assigning a score to each videoaccording to a desired objective function using a rich set offeatures describing the video and user.
在列表中提出一些“最佳”建议需要一个精细的表述,以区分具有较高回忆性的候选人之间的相对重要性。 分级网络通过使用描述视频和用户的丰富功能集,根据期望的目标功能,为每个视频分配分数,从而完成此任务。
The highest scoringvideos are presented to the user, ranked by their score.The two-stage approach to recommendation allows us tomake recommendations from a very large corpus (millions)of videos while still being certain that the small number ofvideos appearing on the device are personalized and engag-ing for the user. Furthermore, this design enables blendingcandidates generated by other sources, such as those de-scribed in an earlier work [3].
向用户展示得分最高的视频(按其得分排序)。两阶段推荐方法使我们可以从非常大的视频库(数百万个)中进行推荐,同时仍然可以确保设备上出现的视频数量很少 并吸引用户。 此外,这种设计可以混合其他来源生成的候选对象,例如早期工作中描述的那些[3]。
During development, we make extensive use of offline met-rics (precision, recall, ranking loss, etc.) to guide iterative improvements to our system. However for the final deter-mination of the effectiveness of an algorithm or model, werely on A/B testing via live experiments. In a live experi-ment, we can measure subtle changes in click-through rate,watch time, and many other metrics that measure user en-gagement. This is important because live A/B results arenot always correlated with offline experiments.
在开发过程中,我们广泛使用离线方法(metrics)(精度,召回率,排名损失等)来指导系统的迭代改进。 但是,对于最终确定算法或模型有效性的方法,主要是通过实时实验进行A / B测试。 在现场实验中,我们可以衡量点击率,观看时间以及许多其他衡量用户参与度的指标的细微变化。 这很重要,因为实时A / B结果并不总是与离线实验相关。
3. CANDIDATE GENERATION
During candidate generation, the enormous YouTube cor-pus is winnowed down to hundreds of videos that may berelevant to the user. The predecessor to the recommenderdescribed here was a matrix factorization approach trainedunder rank loss [23]. Early iterations of our neural networkmodel mimicked this factorization behavior with shallownetworks that only embedded the user’s previous watches.From this perspective, our approach can be viewed as a non-linear generalization of factorization techniques.
在候选人生成过程中,巨大的YouTube视频会被逐出数百个可能与用户相关的视频。 此处介绍的推荐程序的前身是在秩损失下训练的矩阵分解方法[23]。 我们的神经网络模型的早期迭代使用浅层网络模拟了这种分解行为,该浅层网络仅嵌入了用户以前的观看。从这个角度来看,我们的方法可以看作是分解技术的非线性概括。
3.1 Recommendation as Classification
We pose recommendation as extreme multiclass classifica-tion where the prediction problem becomes accurately clas-sifying a specific video watch wt at time t among millionso f videosi(classes) from a corpusV based on a user U and contextC,
我们将推荐作为极端的多类分类,在这种情况下,预测问题变得非常准确,从而可以根据用户 U 和上下文C从语料库 V 中准确分类特定视频 wt 观看时间 t,其中包括数百万个视频 i(类)。
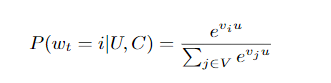
where u∈RN represents a high-dimensional “embedding” ofthe user, context pair and the vj∈RN represent embeddings of each candidate video. In this setting, an embedding issimply a mapping of sparse entities (individual videos, usersetc.) into a dense vector inRN.
The task of the deep neuralnetwork is to learn user embeddings u as a function of theuser’s history and context that are useful for discriminatingamong videos with a softmax classifier.Although explicit feedback mechanisms exist on YouTube(thumbs up/down, in-product surveys, etc.)
we use the im-plicit feedback [16] of watches to train the model, where auser completing a video is a positive example. This choice is based on the orders of magnitude more implicit user historyavailable, allowing us to produce recommendations deep in the tail where explicit feedback is extremely sparse.
其中u∈RN代表用户的高维“嵌入”,上下文对和 vj∈RN 代表每个候选视频的嵌入。 在这种情况下,嵌入就是将稀疏实体(单个视频,用户等)映射到RN中的密集向量。
深度神经网络的任务是根据用户的历史和上下文来学习用户嵌入 u ,这对于用softmax分类器区分视频非常有用。尽管YouTube上存在显式反馈机制(explicit feedback mechanisms)(点赞/反对,产品内调查等)
我们使用观看的隐式反馈[16]来训练模型,其中用户完成视频就是一个很好的例子。 该选择基于可提供的更多隐式用户历史记录的数量级,这使我们能够在显式反馈极为稀少的尾部深处产生推荐。
Efficient Extreme Multiclass/高效的极端多类
To efficiently train such a model with millions of classes, werely on a technique to sample negative classes from the back-ground distribution (“candidate sampling”) and then correct for this sampling via importance weighting [10]. For each ex-ample the cross-entropy loss is minimized for the true labeland the sampled negative classes. In practice several thou-sand negatives are sampled, corresponding to more than 100times speedup over traditional softmax. A popular alterna-tive approach is hierarchical softmax [15], but we weren’t able to achieve comparable accuracy. In hierarchical soft-max, traversing each node in the tree involves discriminat-ing between sets of classes that are often unrelated, makingthe classification problem much more difficult and degradingperformance
为了有效地训练具有数百万个类别的模型,主要采用了一种从背景分布中抽取负面类别的技术(“候选抽样”),然后通过重要性加权对该抽样进行校正[10]。 对于每个示例,对于真实标签和采样的负类,交叉熵损失最小。 在实践中,对几千个负片进行了采样,对应于传统softmax的100倍以上的加速。 一种流行的替代方法是分层softmax [15],但我们无法达到可比的准确性。 在分层soft-max中,遍历树中的每个节点都涉及在通常不相关的类集之间进行区分,这使分类问题变得更加困难并降低了性能
At serving time we need to compute the most likely N classes (videos) in order to choose the topNto present to the user. Scoring millions of items under a strict serv-ing latency of tens of milliseconds requires an approximatescoring scheme sublinear in the number of classes. Previoussystems at YouTube relied on hashing [24] and the classi-fier described here uses a similar approach. Since calibratedlikelihoods from the softmax output layer are not neededat serving time, the scoring problem reduces to a nearestneighbor search in the dot product space for which generalpurpose libraries can be used [12]. We found that A/B re-sults were not particularly sensitive to the choice of nearestneighbor search algorithm.
在投放时,我们需要计算最可能的N类(视频),以便选择要呈现给用户的最合适的 N。 在数十毫秒的严格服务等待时间下对数百万个项目进行评分需要在类数上近似线性的近似评分方案。 YouTube以前的系统依赖于哈希[24],这里描述的分类器使用类似的方法。 由于在服务时间不需要来自softmax输出层的经过校准的似然性,因此计分问题减少到可以使用通用库的点积空间中的最近邻居搜索[12]。 我们发现,A / B结果对最近邻居搜索算法的选择不是特别敏感。
3.2 Model Architecture/模型架构
Inspired by continuous bag of words language models [14],we learn high dimensional embeddings for each video in afixed vocabulary and feed these embeddings into a feedfor-ward neural network. A user’s watch history is representedby a variable-length sequence of sparse video IDs which ismapped to a dense vector representation via the embed-dings. The network requires fixed-sized dense inputs andsimply averaging the embeddings performed best among sev-eral strategies (sum, component-wise max, etc.). Impor-tantly, the embeddings are learned jointly with all othermodel parameters through normal gradient descent back-propagation updates. Features are concatenated into a widefirst layer, followed by several layers of fully connected Rec-tified Linear Units (ReLU) [6]. Figure 3 shows the generalnetwork architecture with additional non-video watch fea-tures described below.
受连续的单词语言模型[14]的启发,我们为固定词汇表中的每个视频学习高维嵌入,并将这些嵌入馈入前馈神经网络。 用户的观看历史记录由可变长度的稀疏视频ID序列表示,该序列通过嵌入映射为密集的矢量表示形式。 该网络需要固定大小的密集输入,并在几种策略(求和,逐分量最大值等)中简单地对执行效果最好的嵌入进行平均。 重要的是,嵌入是通过正常梯度下降反向传播更新与所有其他模型参数一起学习的。 功能被连接到第一层,然后是几层完全连接的整流线性单元(ReLU)[6]。 图3显示了通用网络架构,并具有以下所述的其他非视频观看功能。
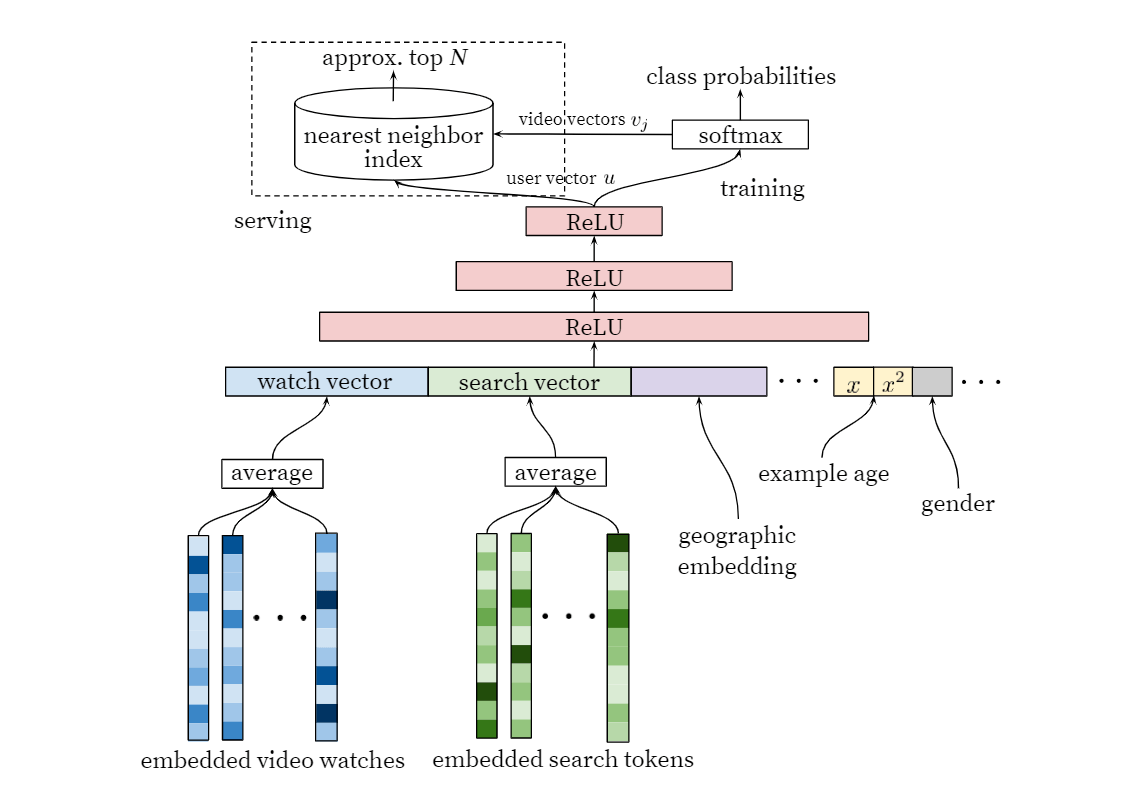
Figure 3: Deep candidate generation model architecture showing embedded sparse features concatenated withdense features. Embeddings are averaged before concatenation to transform variable sized bags of sparse IDsinto fixed-width vectors suitable for input to the hidden layers. All hidden layers are fully connected. Intraining, a cross-entropy loss is minimized with gradient descent on the output of the sampled softmax.At serving, an approximate nearest neighbor lookup is performed to generate hundreds of candidate videorecommendations./显示候选稀疏特征与密集特征串联在一起的深度候选生成模型体系结构。 在连接之前对嵌入进行平均,以将可变大小的稀疏ID袋转换为适合输入到隐藏层的固定宽度矢量。 所有隐藏层均已完全连接。 训练时,在采样softmax的输出上使用梯度下降使交叉熵损失最小化。在服务时,执行近似最近邻居查找以生成数百个候选视频建议。
3.3 Heterogeneous Signals
A key advantage of using deep neural networks as a gener-alization of matrix factorization is that arbitrary continuousand categorical features can be easily added to the model.Search history is treated similarly to watch history - each query is tokenized into unigrams and bigrams and each to-ken is embedded. Once averaged, the user’s tokenized, em-bedded queries represent a summarized dense search history.Demographic features are important for providing priors sothat the recommendations behave reasonably for new users.The user’s geographic region and device are embedded andconcatenated. Simple binary and continuous features suchas the user’s gender, logged-in state and age are input di-rectly into the network as real values normalized to [0,1].
使用深度神经网络作为矩阵分解的一般化的主要优势在于,可以轻松地将任意连续和分类特征添加到模型中。将搜索历史与观看历史类似地对待-每个查询都被标记为( is tokenized into)字母组合(unigram)和bigrams,每个查询token已嵌入。 取平均后(Once averaged),用户的标记化嵌入式查询代表了汇总的密集搜索历史记录。人口统计功能对于提供优先级至关重要,因此建议对于新用户而言行为合理。用户的地理区域和设备已嵌入并连接在一起。 简单的二进制和连续功能(例如用户的性别,登录状态和年龄)直接以标准化为[0,1]的实际值直接输入到网络中
“Example Age” Feature
Many hours worth of videos are uploaded each second toYouTube. Recommending this recently uploaded (“fresh”)content is extremely important for YouTube as a product.We consistently observe that users prefer fresh content, thoughnot at the expense of relevance. In addition to the first-ordereffect of simply recommending new videos that users want to watch, there is a critical secondary phenomenon of boot-strapping and propagating viral content [11].
每秒需要花费数小时的时间将视频上传到YouTube。 对于YouTube作为产品,推荐最近上传的(“新鲜”)内容非常重要。我们始终观察到,用户更喜欢新鲜的内容,尽管这样做并不以牺牲相关性为代价。 除了简单推荐用户想要观看的新视频的第一效果之外,还有一种严重的辅助现象,即引导和传播病毒内容[11]。
Machine learning systems often exhibit an implicit biastowards the past because they are trained to predict future behavior from historical examples. The distribution of videopopularity is highly non-stationary but the multinomial dis-tribution over the corpus produced by our recommender willreflect the average watch likelihood in the training windowof several weeks. To correct for this,we feed the age of thetraining example as a feature during training. At servingtime, this feature is set to zero (or slightly negative) to re-flect that the model is making predictions at the very endof the training window.
Figure 4 demonstrates the efficacy of this approach on anarbitrarily chosen video [26]
机器学习系统经常表现出对过去的隐性偏见,因为它们经过训练可以根据历史示例预测未来的行为。 视频受欢迎度的分布是高度不稳定的,但是由我们的推荐者在语料库上生成的多项分布会反映出几周的训练窗口中的平均观看可能性。 为了解决这个问题,我们在训练过程中以训练示例的年龄为特征。 在服务时间,此功能设置为零(或略微为负)以反映模型正在训练窗口的尽头进行预测。
图4展示了这种方法对任意选择的视频的有效性[26]
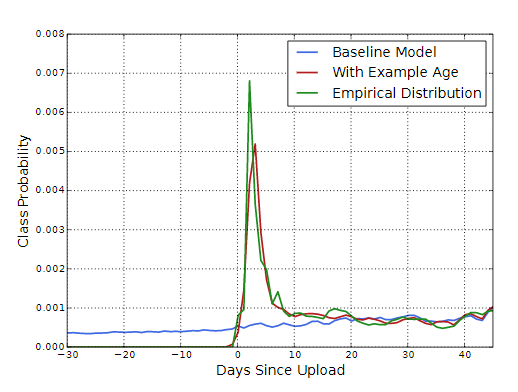
Figure 4: For a given video [26], the model trainedwith example age as a feature is able to accuratelyrepresent the upload time and time-dependant pop-ularity observed in the data. Without the feature,the model would predict approximately the averagelikelihood over the training window./对于给定的视频[26],以示例年龄作为特征进行训练的模型能够准确表示数据中观察到的上传时间和时间相关的受欢迎程度。 如果没有该功能,该模型将在训练窗口内大致预测出平均可能性。
3.4 Label and Context Selection
t is important to emphasize that recommendation ofteninvolves solving asurrogate problemand transferring theresult to a particular context. A classic example is the as-sumption that accurately predicting ratings leads to effectivemovie recommendations [2]. We have found that the choiceof this surrogate learning problem has an outsized impor-tance on performance in A/B testing but is very difficult tomeasure with offline experiments.
重要的是要强调推荐通常涉及解决替代问题并将结果转移到特定的环境。 一个典型的例子是假设,准确预测收视率会导致有效的电影推荐[2]。 我们已经发现,选择这种替代学习问题对A / B测试的性能具有极大的重要性,但是很难通过离线实验进行测量。
Training examples are generated from all YouTube watches(even those embedded on other sites) rather than just watcheson the recommendations we produce. Otherwise, it wouldbe very difficult for new content to surface and the recom-mender would be overly biased towards exploitation. If usersare discovering videos through means other than our recom-mendations, we want to be able to quickly propagate thisdiscovery to others via collaborative filtering. Another keyinsight that improved live metrics was to generate a fixednumber of training examples per user, effectively weightingour users equally in the loss function. This prevented a smallcohort of highly active users from dominating the loss.
培训示例是从所有YouTube观看(甚至是嵌入在其他网站上的观看)中生成的,而不仅仅是观看我们提出的建议。 否则,将很难使新内容浮出水面,并且推荐者将过度偏向于利用。 如果用户通过我们的建议之外的其他方式发现视频,我们希望能够通过协作过滤将该发现快速传播给其他人。 改进实时指标的另一个关键见解是为每个用户生成固定数量的培训示例,从而在损失函数中有效地加权用户。 这阻止了一小群高活跃用户控制损失。
Somewhat counter-intuitively, great care must be takentowithhold information from the classifierin order to pre-vent the model from exploiting the structure of the site andoverfitting the surrogate problem. Consider as an example a case in which the user has just issued a search query for “tay-lor swift”. Since our problem is posed as predicting the nextwatched video, a classifier given this information will predictthat the most likely videos to be watched are those whichappear on the corresponding search results page for “tay-lor swift”. Unsurpisingly, reproducing the user’s last searchpage as homepage recommendations performs very poorly.By discarding sequence information and representing searchqueries with an unordered bag of tokens, the classifier is nolonger directly aware of the origin of the label.
有点反直觉的是,必须格外小心地保留来自分类器的信息,以防止模型利用站点的结构和替代问题。 以一个示例为例,其中用户刚刚发出了“保持快速”搜索查询。 由于我们的问题在于预测下一个观看的视频,因此,根据该信息,分类器将预测最可能观看的视频是出现在相应搜索结果页面上的“超快”视频。 毫不奇怪,将用户的最后一个搜索页面作为首页推荐来执行的效果非常差。通过丢弃序列信息并用无序的令牌袋来表示搜索查询,分类器将不再直接知道标签的来源。
Natural consumption patterns of videos typically lead tovery asymmetric co-watch probabilities. Episodic series areusually watched sequentially and users often discover artistsin a genre beginning with the most broadly popular beforefocusing on smaller niches. We therefore found much betterperformance predicting the user’s next watch, rather thanpredicting a randomly held-out watch (Figure 5). Many col-laborative filtering systems implicitly choose the labels andcontext by holding out a random item and predicting it fromother items in the user’s history (5a). This leaks future infor-mation and ignores any asymmetric consumption patterns.In contrast, we “rollback” a user’s history by choosing a ran-dom watch and only input actions the user took before theheld-out label watch (5b)
视频的自然消费模式通常会导致非常不对称的共同观看概率。 通常会顺序观看情节剧系列,用户通常会先发现一种艺术家,然后再着眼于较小的壁ni,从最广泛使用的流派开始。 因此,我们发现预测用户的下一只观看记录要比预测随机伸出的观看记录要好得多(图5)。 许多协作过滤系统会通过隐藏随机项并根据用户历史记录中的其他项对其进行预测来隐式选择标签和上下文(5a)。 这样做会泄漏未来的信息,并且会忽略任何不对称的消费模式。相反,我们通过选择随机观看记录来“回滚”用户的历史记录,并且仅输入用户在未使用标签观看记录之前进行的操作(5b)
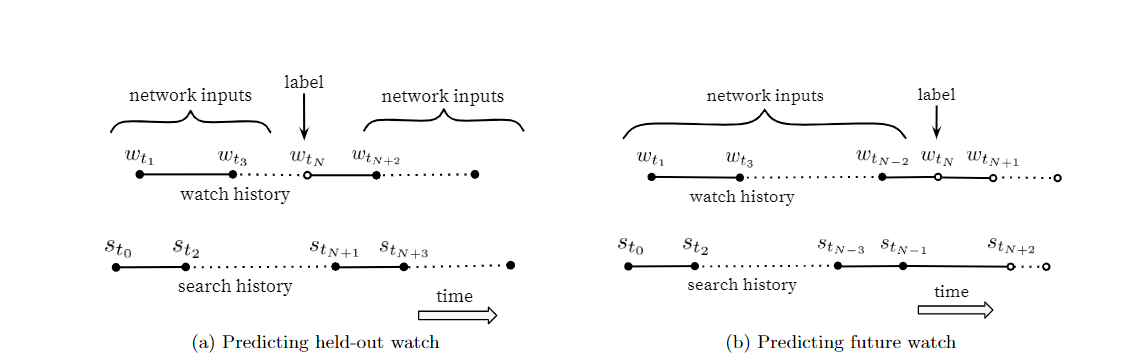
Figure 5: Choosing labels and input context to the model is challenging to evaluate offline but has a largeimpact on live performance. Here, solid events•are input features to the network while hollow events◦areexcluded. We found predicting a future watch (5b) performed better in A/B testing. In (5b), the exampleage is expressed astmax−tNwheretmaxis the maximum observed time in the training data./选择模型的标签和输入上下文对于离线评估具有挑战性,但对实时性能有很大影响。 此处,固定事件是网络的输入特征,而排除了空心事件。 我们发现预测未来的观看(5b)在A / B测试中表现更好。 在(5b)中,示例表示为astmax-tN,其中txaxis为训练数据中的最大观察时间。
3.5 Experiments with Features and Depth
Adding features and depth significantly improves preci-sion on holdout data as shown in Figure 6. In these exper-iments, a vocabulary of 1M videos and 1M search tokenswere embedded with 256 floats each in a maximum bag sizeof 50 recent watches and 50 recent searches. The softmaxlayer outputs a multinomial distribution over the same 1Mvideo classes with a dimension of 256 (which can be thoughtof as a separate output video embedding). These modelswere trained until convergence over all YouTube users, corre-sponding to several epochs over the data. Network structurefollowed a common “tower” pattern in which the bottom ofthe network is widest and each successive hidden layer halvesthe number of units (similar to Figure 3). The depth zeronetwork is effectively a linear factorization scheme which performed very similarly to the predecessor system. Widthand depth were added until the incremental benefit dimin-ished and convergence became difficult:
- Depth 0: A linear layer simply transforms the concate-nation layer to match the softmax dimension of 256
- Depth 1: 256 ReLU
- Depth 2: 512 ReLU→256 ReLU
- Depth 3: 1024 ReLU→512 ReLU→256 ReLU
- Depth 4: 2048 ReLU→1024 ReLU→512 ReLU→256 ReLU
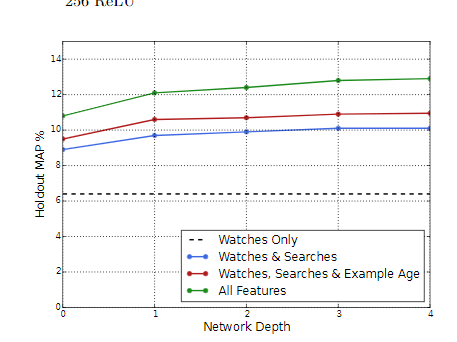
Figure 6: Features beyond video embeddings im-prove holdout Mean Average Precision (MAP) andlayers of depth add expressiveness so that the modelcan effectively use these additional features by mod-eling their interaction.
4. RANKING
The primary role of ranking is to use impression data tospecialize and calibrate candidate predictions for the partic-ular user interface. For example, a user may watch a givenvideo with high probability generally but is unlikely to clickon the specific homepage impression due to the choice ofthumbnail image. During ranking, we have access to manymore features describing the video and the user’s relation-ship to the video because only a few hundred videos arebeing scored rather than the millions scored in candidategeneration. Ranking is also crucial for ensembling differentcandidate sources whose scores are not directly comparable.
排名的主要作用是使用印象数据为特定的用户界面专门化和校准候选预测。 例如,用户通常可以高概率观看给定的视频,但是由于选择了缩略图图像,因此不太可能点击特定的主页印象。 在排名过程中,我们可以使用更多功能来描述视频以及用户与视频的关系,因为仅对几百个视频进行了评分,而不是候选代数中的数百万个评分。 排名对于汇总分数不能直接比较的不同候选人资源也至关重要。
We use a deep neural network with similar architecture ascandidate generation to assign an independent score to eachvideo impression using logistic regression (Figure 7). Thelist of videos is then sorted by this score and returned to theuser. Our final ranking objective is constantly being tunedbased on live A/B testing results but is generally a simplefunction of expected watch time per impression. Rankingby click-through rate often promotes deceptive videos thatthe user does not complete (“clickbait”) whereas watch timebetter captures engagement [13, 25].
我们使用具有类似架构的无扫描残基生成的深层神经网络,通过逻辑回归为每个视频展示分配独立的得分(图7)。 视频列表然后按此分数排序并返回给用户。 我们的最终排名目标是根据实时A / B测试结果不断调整的,但通常是预期的每次观看观看时间的简单函数。 按点击率进行排名通常会宣传用户未完成的欺骗性视频(“点击诱饵”),而观看时机则可以吸引用户参与[13,25]。
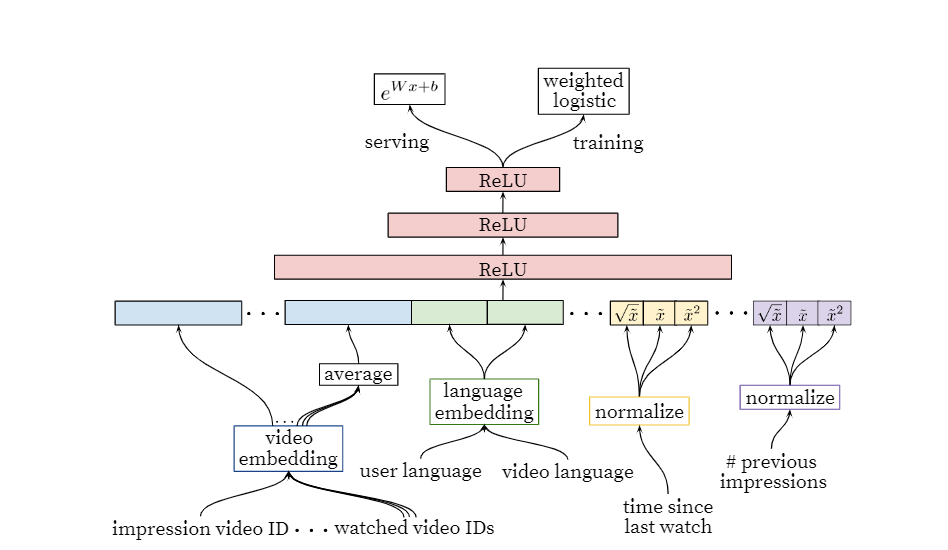
Figure 7: Deep ranking network architecture depicting embedded categorical features (both univalent andmultivalent) with shared embeddings and powers of normalized continuous features. All layers are fullyconnected. In practice, hundreds of features are fed into the network/深度排名网络体系结构,它描述了具有共享嵌入和归一化连续功能的强大功能的嵌入式分类功能(单价和多价)。 所有层均已完全连接。 实际上,将数百种功能馈入网络
4.1 Feature Representation
Our features are segregated with the traditional taxonomyof categorical and continuous/ordinal features. The categor-ical features we use vary widely in their cardinality - someare binary (e.g. whether the user is logged-in) while othershave millions of possible values (e.g. the user’s last searchquery). Features are further split according to whether theycontribute only a single value (“univalent”) or a set of values(“multivalent”). An example of a univalent categorical fea-ture is the video ID of the impression being scored, while acorresponding multivalent feature might be a bag of the lastNvideo IDs the user has watched. We also classify featuresaccording to whether they describe properties of the item(“impression”) or properties of the user/context (“query”).Query features are computed once per request while impres-sion features are computed for each item scored.
我们的功能与分类和连续/常规功能的传统分类法分开。 我们使用的分类功能的基数差异很大-有些是二进制的(例如,用户是否登录),而其他的则有数百万个可能的值(例如,用户的上一次搜索查询)。 根据特征只贡献一个值(“单价”)还是一组值(“多价”)进一步细分。 单价分类功能的一个示例是对印象进行评分的视频ID,而相应的多价功能可能是用户观看过的lastNvideo ID包。 我们还根据特征是描述项目的属性(“印象”)还是用户/上下文的属性(“查询”)对特征进行分类。查询特征是针对每个请求计算一次,印象分数是针对所评分的每个项目计算。
Feature Engineering
We typically use hundreds of features in our ranking mod-els, roughly split evenly between categorical and continu-ous. Despite the promise of deep learning to alleviate theburden of engineering features by hand, the nature of ourraw data does not easily lend itself to be input directly intofeedforward neural networks. We still expend considerable engineering resources transforming user and video data intouseful features. The main challenge is in representing a tem-poral sequence of user actions and how these actions relateto the video impression being scored
我们通常在排名模型中使用数百个功能,这些功能在分类和连续模式之间大致平均分配。 尽管有深度学习有望通过手工减轻工程特征的负担,但是我们原始数据的性质并不容易将其直接输入到前馈神经网络中。 我们仍然会花费大量工程资源,将用户和视频数据转换为有用的功能。 主要挑战在于呈现用户操作的临时顺序以及这些操作与得分视频印象之间的关系
We observe that the most important signals are those thatdescribe a user’s previous interaction with the item itself andother similar items, matching others’ experience in rankingads [7]. As an example, consider the user’s past history withthe channel that uploaded the video being scored - how manyvideos has the user watched from this channel? When wasthe last time the user watched a video on this topic? Thesecontinuous features describing past user actions on relateditems are particularly powerful because they generalize wellacross disparate items. We have also found it crucial topropagate information from candidate generation into rank-ing in the form of features, e.g. which sources nominatedthis video candidate? What scores did they assign?
我们观察到,最重要的信号是那些描述用户先前与商品本身和其他相似商品互动的信息,与其他人对广告的排名相匹配[7]。 例如,考虑用户过去上传该频道的历史记录,该频道已被计分-用户从该频道观看了多少个视频? 用户最后一次观看有关该主题的视频是什么时候? 这些连续的功能描述了过去用户在相关项目上的动作,这些功能特别强大,因为它们可以将完全不同的项目进行概括。 我们还发现至关重要的是,以特征形式(例如, 哪个来源提名了该视频候选人? 他们分配了什么分数?
Features describing the frequency of past video impres-sions are also critical for introducing “churn” in recommen-dations (successive requests do not return identical lists). If a user was recently recommended a video but did not watchit then the model will naturally demote this impression onthe next page load. Serving up-to-the-second impressionand watch history is an engineering feat onto itself outsidethe scope of this paper, but is vital for producing responsiverecommendations.
描述过去视频输入频率的特征对于在建议中引入“用户流失”也很关键(成功的请求不会返回相同的列表)。 如果最近向用户推荐了一个视频但没有观看,那么该模型自然会在下一页加载时降级此印象。 提供最新的印象和观看历史记录是在本文范围之外的一项工程壮举,但对于产生响应性建议至关重要。
Embedding Categorical Features
Similar to candidate generation, we use embeddings to mapsparse categorical features to dense representations suitablefor neural networks. Each unique ID space (“vocabulary”)has a separate learned embedding with dimension that in-creases approximately proportional to the logarithm of thenumber of unique values. These vocabularies are simplelook-up tables built by passing over the data once beforetraining. Very large cardinality ID spaces (e.g. video IDsor search query terms) are truncated by including only thetopNafter sorting based on their frequency in clicked im-pressions. Out-of-vocabulary values are simply mapped tothe zero embedding. As in candidate generation, multivalentcategorical feature embeddings are averaged before being fedin to the network.
与候选生成类似,我们使用嵌入将稀疏分类特征映射到适用于神经网络的密集表示。 每个唯一ID空间(“词汇表”)都有一个单独的学习嵌入,其嵌入的维数大约与唯一值个数的对数成正比。 这些词汇表是通过在训练之前将数据传递一次而建立的简单查找表。 通过根据点击印象中的频率仅包含thetopNafter排序,可以截断非常大的基数ID空间(例如视频ID或搜索查询字词)。 语音外的值仅映射到零嵌入。 与候选生成一样,在将多价分类特征嵌入馈入网络之前对其进行平均。
Importantly, categorical features in the same ID space alsoshare underlying emeddings. For example, there exists a sin-gle global embedding of video IDs that many distinct fea-tures use (video ID of the impression, last video ID watchedby the user, video ID that “seeded” the recommendation,etc.). Despite the shared embedding, each feature is fed sep-arately into the network so that the layers above can learnspecialized representations per feature. Sharing embeddingsis important for improving generalization, speeding up train-ing and reducing memory requirements. The overwhelmingmajority of model parameters are in these high-cardinalityembedding spaces - for example, one million IDs embeddedin a 32 dimensional space have 7 times more parametersthan fully connected layers 2048 units wide.
重要的是,同一ID空间中的分类特征也共享基本的嵌入。 例如,存在许多不同功能使用的视频ID的单一全局嵌入(印象的视频ID,用户观看的最后一个视频ID,“植入”推荐的视频ID等)。 尽管有共享的嵌入,但每个要素仍被单独馈送到网络中,因此上面的层可以学习每个要素的专门表示。 共享嵌入对于提高通用性,加快训练速度并减少内存需求非常重要。 绝大多数模型参数都位于这些高基数嵌入空间中,例如,嵌入32维空间中的100万个ID具有比2048单位宽的完全连接层多7倍的参数。
Normalizing Continuous Features
Neural networks are notoriously sensitive to the scaling anddistribution of their inputs [9] whereas alternative approachessuch as ensembles of decision trees are invariant to scalingof individual features. We found that proper normalization of continuous features was critical for convergence. A con-tinuous featurexwith distributionfis transformed to ̃xbyscaling the values such that the feature is equally distributedin [0,1) using the cumulative distribution, ̃x=∫x−∞df.This integral is approximated with linear interpolation onthe quantiles of the feature values computed in a single passover the data before training begins.
众所周知,神经网络对其输入的缩放和分布非常敏感[9],而诸如决策树的集成之类的替代方法则对单个特征的缩放不变。 我们发现适当的归一化196
连续的特征对于收敛至关重要。 通过对值进行缩放将连续的特征x的分布fis转换为̃x,以便使用累积分布̃x =∫x-∞df将特征均匀分布在[0,1)中。通过对所计算特征值的分位数进行线性插值来近似该积分 在一次逾越节中,训练开始之前的数据
In addition to the raw normalized feature ̃x, we also inputpowers ̃x2and√ ̃x, giving the network more expressive powerby allowing it to easily form super- and sub-linear functionsof the feature. Feeding powers of continuous features wasfound to improve offline accuracy.
除了原始归一化特征̃x之外,我们还输入功率̃x2和√̃x,使网络可以轻松形成特征的超线性和亚线性函数,从而赋予网络更高的表达能力。 发现连续功能的馈电能力可提高离线精度。
4.2 Modeling Expected Watch Time
Our goal is to predict expected watch time given trainingexamples that are either positive (the video impression wasclicked) or negative (the impression was not clicked). Pos-itive examples are annotated with the amount of time theuser spent watching the video. To predict expected watchtime we use the technique of weighted logistic regression,which was developed for this purpose.
我们的目标是在给定的培训示例为正面(点击视频印象)或负面(未点击印象)的情况下预测预期观看时间。 以用户观看视频所花费的时间来说明正例。 为了预测预期的收看时间,我们使用了为此目的而开发的加权逻辑回归技术。
The model is trained with logistic regression under cross-entropy loss (Figure 7). However, the positive (clicked)impressions are weighted by the observed watch time onthe video. Negative (unclicked) impressions all receive unitweight. In this way, the odds learned by the logistic regres-sion are∑TiN−kwhereNis the number of training examples,kis the number of positive impressions, andTiis the watchtime of theith impression. Assuming the fraction of pos-itive impressions is small (which is true in our case), thelearned odds are approximately E[T](1 +P), wherePis theclick probability and E[T] is the expected watch time of theimpression. SincePis small, this product is close to E[T].For inference we use the exponential functionexas the fi-nal activation function to produce these odds that closelyestimate expected watch time.
该模型通过交叉熵损失下的逻辑回归进行训练(图7)。 但是,正面(点击)展示会根据视频上观看的观看时间进行加权。 负数(未点击)印象数均以单位重量计。 这样,逻辑回归学习到的几率就是∑TiN-k,其中Nis是训练样本的数量,kis是正面印象的数量,Tis是该印象的观察时间。 假设正面印象的分数很小(在我们的情况下是正确的),则学习的几率约为E [T](1 + P),其中Pis点击概率,E [T]是预期的展示时间。 由于Pis很小,因此该乘积接近E [T]。为了进行推断,我们使用指数函数(例如最终的激活函数)来产生这些几率,这些几率会密切估计预期的观看时间。
4.3 Experiments with Hidden Layers
Table 1 shows the results we obtained on next-day holdoutdata with different hidden layer configurations. The valueshown for each configuration (“weighted, per-user loss”) wasobtained by considering both positive (clicked) and negative(unclicked) impressions shown to a user on a single page.We first score these two impressions with our model. If thenegative impression receives a higher score than the posi-tive impression, then we consider the positive impression’swatch time to bemispredicted watch time. Weighted, per-user loss is then the total amount mispredicted watch timeas a fraction of total watch time over heldout impressionpairs
表1显示了我们在具有不同隐藏层配置的第二天保持数据上获得的结果。 每种配置所显示的值(“加权的每用户损失”)是通过考虑在单个页面上显示给用户的正面(点击)和负面(未点击)印象获得的。我们首先使用模型对这两个印象进行评分。 如果负面印象获得的得分高于正面印象,则我们将正面印象的观看时间视为错误的观看时间。 加权的每位用户损失则是错误预测的观看时间总数,占总保留时间对的观看时间总数的一部分

Table 1: Effects of wider and deeper hidden ReLUlayers on watch time-weighted pairwise loss com-puted on next-day holdout data.
These results show that increasing the width of hiddenlayers improves results, as does increasing their depth. Thetrade-off, however, is server CPU time needed for inference.The configuration of a 1024-wide ReLU followed by a 512-wide ReLU followed by a 256-wide ReLU gave us the bestresults while enabling us to stay within our serving CPUbudget.
这些结果表明,增加隐藏层的宽度可以改善结果,增加深度也可以改善结果。 但是,折衷方案是推理所需的服务器CPU时间。配置1024宽的ReLU,然后配置512宽的ReLU,再配置256宽的ReLU,可以使我们获得最佳结果,同时使我们能够保持服务CPU预算之内。
For the 1024→512→256 model we tried only feeding thenormalized continuous features without their powers, whichincreased loss by 0.2%. With the same hidden layer con-figuration, we also trained a model where positive and neg-ative examples are weighted equally. Unsurprisingly, thisincreased the watch time-weighted loss by a dramatic 4.1%
5. CONCLUSIONS
We have described our deep neural network architecturefor recommending YouTube videos, split into two distinctproblems: candidate generation and ranking.
我们已经介绍了用于推荐YouTube视频的深度神经网络体系结构,它分为两个不同的问题:候选人生成和排名。
Our deep collaborative filtering model is able to effectivelyassimilate many signals and model their interaction with lay-ers of depth, outperforming previous matrix factorizationapproaches used at YouTube [23]. There is more art thanscience in selecting the surrogate problem for recommenda-tions and we found classifying a future watch to perform wellon live metrics by capturing asymmetric co-watch behaviorand preventing leakage of future information. Withholdingdiscrimative signals from the classifier was also essential toachieving good results - otherwise the model would overfitthe surrogate problem and not transfer well to the home-page.
我们的深度协作过滤模型能够有效地吸收许多信号,并模拟它们与深度层之间的相互作用,胜过YouTube之前使用的矩阵分解方法[23]。 在选择替代问题进行推荐时,艺术比科学还多,我们发现,通过捕获不对称合作手表行为并防止将来信息泄漏,可以对未来手表进行分类,以实现良好的实时指标。 保留来自分类器的区分性信号对于获得良好结果也是必不可少的-否则该模型将适合替代问题,并且无法很好地传递到首页。
We demonstrated that using the age of the training exam-ple as an input feature removes an inherent bias towards thepast and allows the model to represent the time-dependentbehavior of popular of videos. This improved offline holdoutprecision results and increased the watch time dramaticallyon recently uploaded videos in A/B testing.
我们证明了使用训练样本的年龄作为输入特征可以消除对过去的内在偏见,并允许模型表示随时间变化的流行视频行为。 这样改善了离线保持精度结果,并大大延长了A / B测试中最近上传的视频的观看时间。
Ranking is a more classical machine learning problem yetour deep learning approach outperformed previous linearand tree-based methods for watch time prediction. Recom-mendation systems in particular benefit from specialized fea-tures describing past user behavior with items. Deep neuralnetworks require special representations of categorical andcontinuous features which we transform with embeddingsand quantile normalization, respectively. Layers of depthwere shown to effectively model non-linear interactions be-tween hundreds of features.
排名是一个更为经典的机器学习问题,但我们的深度学习方法优于以前的基于线性和基于树的观看时间预测方法。 推荐系统尤其受益于描述项目过去用户行为的专门功能。 深度神经网络需要分类和连续特征的特殊表示,分别通过嵌入和分位数归一化进行转换。 显示了深度层,可以有效地建模数百个要素之间的非线性相互作用。
Logistic regression was modified by weighting training ex-amples with watch time for positive examples and unity fornegative examples, allowing us to learn odds that closelymodel expected watch time. This approach performed muchbetter on watch-time weighted ranking evaluation metricscompared to predicting click-through rate directly.
通过对训练示例进行加权,对正例和统一否定例的观看时间进行加权,对逻辑回归进行了修改,从而使我们能够了解与预期观看时间密切相关的赔率。 与直接预测点击率相比,该方法在观看时间加权排名评估指标上表现更好。
6. ACKNOWLEDGMENTS
The authors would like to thank Jim McFadden and PranavKhaitan for valuable guidance and support. Sujeet Bansal,Shripad Thite and Radek Vingralek implemented key com-ponents of the training and serving infrastructure. ChrisBerg and Trevor Walker contributed thoughtful discussionand detailed feedback.
作者要感谢Jim McFadden和PranavKhaitan的宝贵指导和支持。 Sujeet Bansal,Shripad Thite和Radek Vingralek实施了培训和服务基础设施的关键组件。 ChrisBerg和Trevor Walker进行了周到的讨论并提供了详细的反馈。
7. REFERENCES
[1] M. Abadi, A. Agarwal, P. Barham, E. Brevdo,Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean,M. Devin, S. Ghemawat, I. Goodfellow, A. Harp,G. Irving, M. Isard, Y. Jia, R. Jozefowicz, L. Kaiser,M. Kudlur, J. Levenberg, D. Man ́e, R. Monga,S. Moore, D. Murray, C. Olah, M. Schuster, J. Shlens,B. Steiner, I. Sutskever, K. Talwar, P. Tucker,V. Vanhoucke, V. Vasudevan, F. Vi ́egas, O. Vinyals,P. Warden, M. Wattenberg, M. Wicke, Y. Yu, andX. Zheng. TensorFlow: Large-scale machine learningon heterogeneous systems, 2015. Software availablefrom tensorflow.org.
[2] X. Amatriain. Building industrial-scale real-worldrecommender systems. InProceedings of the SixthACM Conference on Recommender Systems, RecSys’12, pages 7–8, New York, NY, USA, 2012. ACM.
[3] J. Davidson, B. Liebald, J. Liu, P. Nandy,T. Van Vleet, U. Gargi, S. Gupta, Y. He, M. Lambert,B. Livingston, and D. Sampath. The youtube videorecommendation system. InProceedings of the FourthACM Conference on Recommender Systems, RecSys’10, pages 293–296, New York, NY, USA, 2010. ACM.
[4] J. Dean, G. S. Corrado, R. Monga, K. Chen,M. Devin, Q. V. Le, M. Z. Mao, M. Ranzato,A. Senior, P. Tucker, K. Yang, and A. Y. Ng. Largescale distributed deep networks. InNIPS, 2012.
[5] A. M. Elkahky, Y. Song, and X. He. A multi-view deeplearning approach for cross domain user modeling inrecommendation systems. InProceedings of the 24thInternational Conference on World Wide Web, WWW’15, pages 278–288, New York, NY, USA, 2015. ACM.
[6] X. Glorot, A. Bordes, and Y. Bengio. Deep sparserectifier neural networks. In G. J. Gordon and D. B.Dunson, editors,Proceedings of the FourteenthInternational Conference on Artificial Intelligence andStatistics (AISTATS-11), volume 15, pages 315–323.Journal of Machine Learning Research - Workshopand Conference Proceedings, 2011.
[7] X. He, J. Pan, O. Jin, T. Xu, B. Liu, T. Xu, Y. Shi,A. Atallah, R. Herbrich, S. Bowers, and J. Q. n.Candela. Practical lessons from predicting clicks onads at facebook. InProceedings of the EighthInternational Workshop on Data Mining for OnlineAdvertising, ADKDD’14, pages 5:1–5:9, New York,NY, USA, 2014. ACM.
[8] W. Huang, Z. Wu, L. Chen, P. Mitra, and C. L. Giles.A neural probabilistic model for context based citationrecommendation. InAAAI, pages 2404–2410, 2015.
[9] S. Ioffe and C. Szegedy. Batch normalization:Accelerating deep network training by reducinginternal covariate shift.CoRR, abs/1502.03167, 2015.
[10] S. Jean, K. Cho, R. Memisevic, and Y. Bengio. Onusing very large target vocabulary for neural machinetranslation.CoRR, abs/1412.2007, 2014.
[11] L. Jiang, Y. Miao, Y. Yang, Z. Lan, and A. G.Hauptmann. Viral video style: A closer look at viralvideos on youtube. InProceedings of InternationalConference on Multimedia Retrieval, ICMR ’14, pages193:193–193:200, New York, NY, USA, 2014. ACM.
[12] T. Liu, A. W. Moore, A. Gray, and K. Yang. Aninvestigation of practical approximate nearestneighbor algorithms. pages 825–832. MIT Press, 2004.
[13] E. Meyerson. Youtube now: Why we focus on watchtime. http://youtubecreator.blogspot.com/2012/08...: 2016-04-20.
[14] T. Mikolov, I. Sutskever, K. Chen, G. Corrado, andJ. Dean. Distributed representations of words andphrases and their compositionality.CoRR,abs/1310.4546, 2013.
[15] F. Morin and Y. Bengio. Hierarchical probabilisticneural network language model. InAISTATSˆa ̆A ́Z05,pages 246–252, 2005.
[16] D. Oard and J. Kim. Implicit feedback forrecommender systems. Inin Proceedings of the AAAIWorkshop on Recommender Systems, pages 81–83,1998.
[17] K. J. Oh, W. J. Lee, C. G. Lim, and H. J. Choi.Personalized news recommendation using classifiedkeywords to capture user preference. In16thInternational Conference on Advanced CommunicationTechnology, pages 1283–1287, Feb 2014.
[18] S. Sedhain, A. K. Menon, S. Sanner, and L. Xie.Autorec: Autoencoders meet collaborative filtering. InProceedings of the 24th International Conference onWorld Wide Web, WWW ’15 Companion, pages111–112, New York, NY, USA, 2015. ACM.
[19] X. Su and T. M. Khoshgoftaar. A survey ofcollaborative filtering techniques.Advances inartificial intelligence, 2009:4, 2009.
[20] D. Tang, B. Qin, T. Liu, and Y. Yang. User modelingwith neural network for review rating prediction. InProc. IJCAI, pages 1340–1346, 2015.
[21] A. van den Oord, S. Dieleman, and B. Schrauwen.Deep content-based music recommendation. InC. J. C. Burges, L. Bottou, M. Welling,Z. Ghahramani, and K. Q. Weinberger, editors,Advances in Neural Information Processing Systems26, pages 2643–2651. Curran Associates, Inc., 2013.
[22] H. Wang, N. Wang, and D.-Y. Yeung. Collaborativedeep learning for recommender systems. InProceedingsof the 21th ACM SIGKDD International Conferenceon Knowledge Discovery and Data Mining, KDD ’15,pages 1235–1244, New York, NY, USA, 2015. ACM.
[23] J. Weston, S. Bengio, and N. Usunier. Wsabie: Scalingup to large vocabulary image annotation. InProceedings of the International Joint Conference onArtificial Intelligence, IJCAI, 2011.
[24] J. Weston, A. Makadia, and H. Yee. Label partitioningfor sublinear ranking. In S. Dasgupta andD. Mcallester, editors,Proceedings of the 30thInternational Conference on Machine Learning(ICML-13), volume 28, pages 181–189. JMLRWorkshop and Conference Proceedings, May 2013.
[25] X. Yi, L. Hong, E. Zhong, N. N. Liu, and S. Rajan.Beyond clicks: Dwell time for personalization. InProceedings of the 8th ACM Conference onRecommender Systems, RecSys ’14, pages 113–120,New York, NY, USA, 2014. ACM.
[26] Zayn. Pillowtalk.https://www.youtube.com/watch?v=C3d6GntKbk.
本作品采用《CC 协议》,转载必须注明作者和本文链接







 关于 LearnKu
关于 LearnKu




推荐文章: