
「Wide & Deep Learning for Recommender Systems」- 论文阅读
0 / 0 / 创建于 6年前 /
 娃哈哈店长 的个人博客
娃哈哈店长 的个人博客
论文原址:https://arxiv.org/pdf/1606.07792.pdf
Wide & Deep Learning for Recommender Systems
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra,
Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil,
Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, Hemal Shah
∗ Google Inc.
ABSTRACT/摘要
Generalized linear models with nonlinear feature transformations are widely used for large-scale regression and classification problems with sparse inputs. Memorization of feature interactions through a wide set of cross-product feature transformations are effective and interpretable, while generalization requires more feature engineering effort. With less feature engineering, deep neural networks can generalize better to unseen feature combinations through low-dimensional dense embeddings learned for the sparse features. However, deep neural networks with embeddings can over-generalize and recommend less relevant items when the user-item interactions are sparse and high-rank. In this paper, we present Wide & Deep learning—jointly trained wide linear models and deep neural networks—to combine the benefits of memorization and generalization for recommender systems. We productionized and evaluated the system on Google Play, a commercial mobile app store with over one billion active users and over one million apps. Online experiment results show that Wide & Deep significantly increased app acquisitions compared with wide-only and deep-only models. We have also open-sourced our implementation in TensorFlow.
具有非线性特征变换的广义线性模型广泛用于稀疏输入的大规模回归和分类问题。通过广泛的跨产品特征转换来记忆特征交互是有效的和可解释的,而概括需要更多的特征工程工作。在较少特征处理的情况下,deep neural networks 可以通过为稀疏特征学习的低维密集嵌入来更好地概括为看不见的特征组合。但是,当用户项交互稀疏且等级较高时,具有嵌入的深层神经网络可以过度概括和推荐相关性较低的处理。在本文中,我们介绍了广深学习——联合训练的宽线性模型和深度神经网络——将推荐系统记忆和概括的好处结合起来。我们在 Google Play 上生产并评估了该系统,这是一个商业移动应用商店,拥有超过 10 亿活跃用户和 100 多万个应用程序。在线实验结果表明,与仅宽度和仅深度模型相比,宽和深综合模型显著提高了应用的获取量。我们还在 TensorFlow 中开源了我们的方法。
CCS Concepts/CCS 概念
- •Computing methodologies → Machine learning; Neural networks; Supervised learning;
- •Information systems → Recommender systems;
- Keywords
- Wide & Deep Learning, Recommender Systems.
1. INTRODUCTION/介绍
A recommender system can be viewed as a search ranking system, where the input query is a set of user and contextual information, and the output is a ranked list of items. Given a query, the recommendation task is to find the relevant items in a database and then rank the items based on certain objectives, such as clicks or purchases.
推荐系统可以被看作为搜索排名系统,其中输出是一组用户和上下文的信息,用户和上下文信息,输出是每一项的排名列表。给定查询,建议任务是查找数据库中的相关项目,然后根据特定目标(如点击或购买)对项目进行排名。
One challenge in recommender systems, similar to the general search ranking problem, is to achieve both memorization and generalization. Memorization can be loosely defined as learning the frequent co-occurrence of items or features and exploiting the correlation available in the historical data. Generalization, on the other hand, is based on transitivity of correlation and explores new feature combinations that
have never or rarely occurred in the past. Recommendations based on memorization are usually more topical and directly relevant to the items on which users have already performed actions. Compared with memorization, generalization tends to improve the diversity of the recommended items. In this paper, we focus on the apps recommendation problem for the Google Play store, but the approach should apply to generic recommender systems.
推荐系统的一个挑战,和一般的搜索排名系统类似,是实现两者 memorization 和 generalization 。
Memorization可以粗略地定义为学习项目或特征的频繁共发生,并利用历史数据中可用的关联。另一方面,Generalization基于相关性的传递性,并探索了新的特征组合,过去从未或很少发生。基于Memorization的推荐通常更热门,并且与用户已经执行的操作的项目直接相关。与Memorization相比,Generalization倾向于提高推荐项目的多样性。在本文中,我们重点介绍 Google Play 商店的应用推荐问题,但该方法应适用于通用推荐系统。
For massive-scale online recommendation and ranking systems in an industrial setting, generalized linear models such as logistic regression are widely used because they are simple, scalable and interpretable.
对于在产业化环境中的大规模的在线推荐和排名系统,广义线性模型(如逻辑回归)被广泛使用,因为它们简单、可扩展且可解释。
The models are often trained on binarized sparse features with one-hot encoding.
E.g., the binary feature “user_installed_app=netflix” has value 1 if the user installed Netflix. Memorization can be achieved effectively using cross-product transformations over sparse features, such as AND(user_installed_app=netflix, impression_app=pandora”), whose value is 1 if the user installed Netflix and then is later shown Pandora. This explains how the co-occurrence of a feature pair correlates with the target label.
Generalization can be added by using features that are less granular, such as AND(user_installed_category=video, impression_category=music), but manual feature engineering is often required. One limitation of cross-product transformations is that they do not generalize to query-item feature pairs that have not appeared in the training data.
模型通常使用one-hot encoding在二进制的稀疏特征上进行训练。
例如: 用户安装Netflix ,则二进制功能user_installed_app_netflix具有值1。Memorization可以通过跨产品对稀疏的特征如AND(user_installed_app=netflix, impression_app=pandora”)的转换来实现。这个解释了如何通过目标标签对匹配同时出现的特征值。
广义化Generalization可以通过粒度较低的特征值来添加,例如AND(user_installed_category=video, impression_category=music),但是通常需要认未的特征制造。跨产品转换的一个限制是它们不概括到未出现在训练数据中的查询项的特征对。
Embedding-based models, such as factorization machines [5] or deep neural networks, can generalize to previously unseen query-item feature pairs by learning a low-dimensional dense embedding vector for each query and item feature, with less burden of feature engineering.
However, it is difficult to learn effective low-dimensional representations for queries and items when the underlying query-item matrix is sparse and high-rank, such as users with specific preferences or niche items with a narrow appeal. In such cases, there should be no interactions between most query-item pairs, but dense embeddings will lead to nonzero predictions for all query-item pairs, and thus can over-generalize and make less relevant recommendations. On the other hand, linear models with cross-product feature transformations can memorize these “exception rules” with much fewer parameters.
嵌入式的模型,例如 分解机、深度学习网络,可以通过学习每个查询和项特征的低维密集嵌入向量来概括到以前看不到的查询项特征对,从而减特征值处理的负担。
但是,当基础查询项矩阵稀疏且排名较高(例如具有特定偏好的用户或吸引力较小的利基项目)时,很难学习查询和项的有效低维表示形式。在这种情况下,大多数查询项对之间不应有交互,但密集嵌入将导致对所有查询项对进行非零预测,从而可以过度概括和提出不太相关的建议。另一方面,具有跨产品特征转换的线性模型可以记住这些”异常规则”,而参数要少得多。
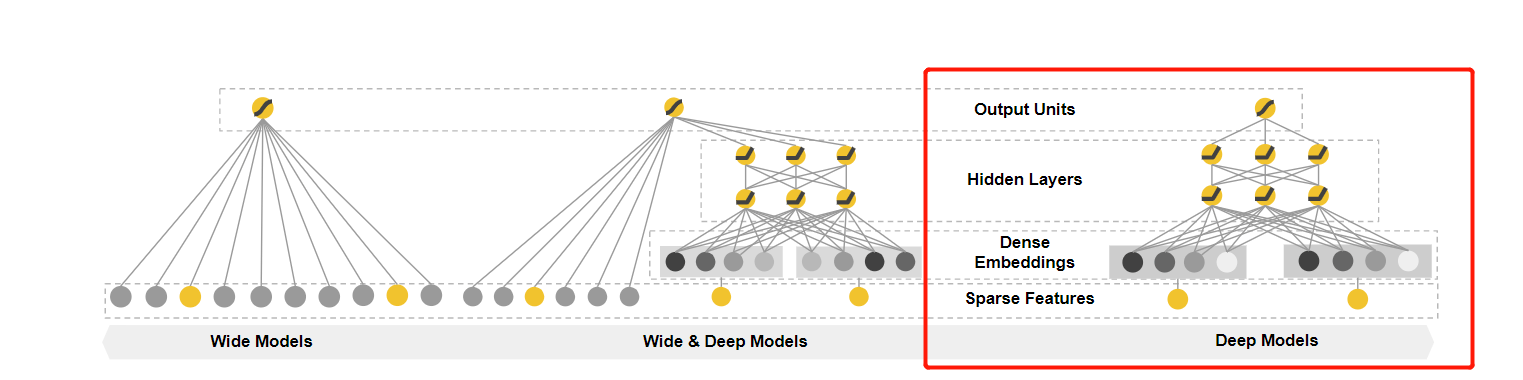
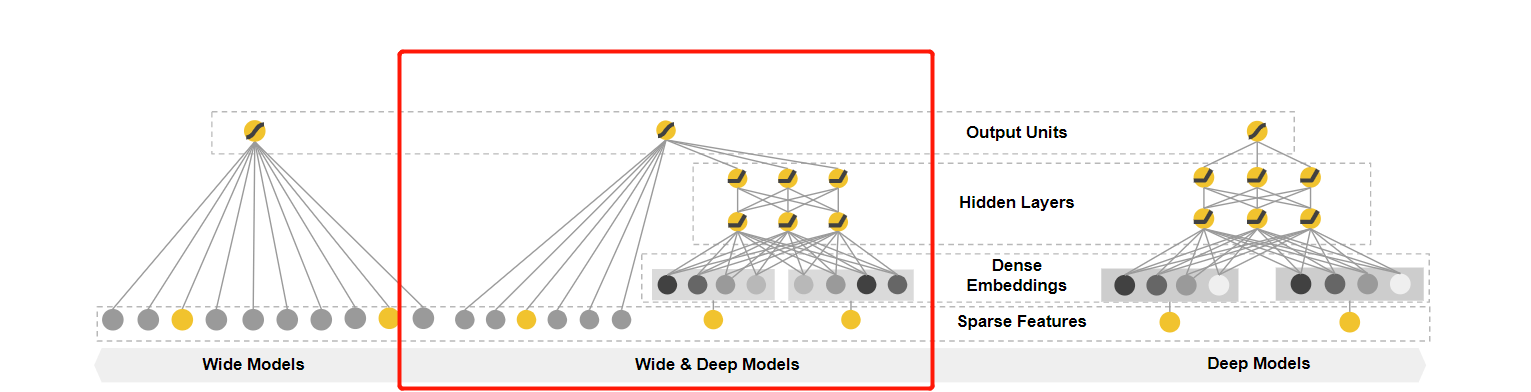
In this paper, we present the Wide & Deep learning framework to achieve both memorization and generalization in one model, by jointly training a linear model component and a neural network component as shown in Figure 1.
本论文通过如下所示的 Figure 1(该论文主要的贡献) 联合训练线性模型组件和神经网络组件,在一个广度和深度综合学习框架中通过一个模型实现memorization记忆化 和 generalization广泛化 。
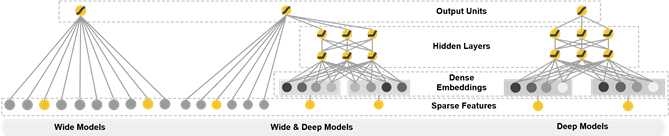
Figure 1: The spectrum of Wide & Deep models.
The main contributions of the paper include:
• The Wide & Deep learning framework for jointly training linear model with feature transformations for generic recommender systems with sparse inputs.
• The implementation and evaluation of the Wide & Deep recommender system productionized on Google Play, a mobile app store with over one billion active users and over one million apps.
We have open-sourced our implementation along with a high-level API in TensorFlow
feed-forward neural networks with embeddings and While the idea is simple, we show that the Wide & Deep framework significantly improves the app acquisition rate on the mobile app store, while satisfying the training and serving speed requirements.
该文件的主要贡献包括:
- 宽和深度学习框架,用于共同训练线性模型和具有稀疏输入的通用推荐系统的特征转换。
- Wide&Deep推荐系统的实施和评估是在Google Play(一家拥有超过10亿活跃用户和超过100万个应用程序的移动应用程序商店)上生产的。
我们在TensorFlow中将我们的实现以及高级API开源了
具有嵌入和的前馈神经网络虽然想法很简单,但我们证明Wide&Deep框架显着提高了移动应用商店中的应用获取率,同时满足了培训和服务速度方面的要求。
2. RECOMMENDER SYSTEM OVERVIEW / 推荐系统总览
An overview of the app recommender system is shown in Figure 2. A query, which can include various user and contextual features, is generated when a user visits the app store. The recommender system returns a list of apps (also referred to as impressions) on which users can perform certain actions such as clicks or purchases. These user actions, along with the queries and impressions, are recorded in the logs as the training data for the learner.
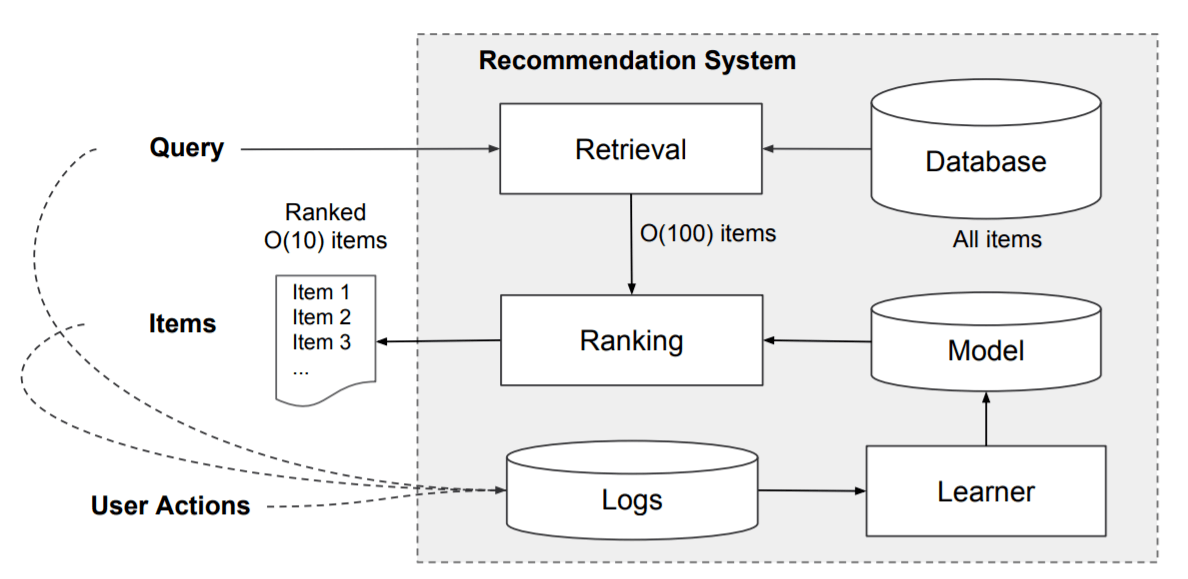
Figure 2: Overview of the recommender system.
应用程序推荐系统的概述如Figure 2所示。当用户访问应用程序商店时,将生成一个查询,其中可能包含各种用户和上下文功能。 推荐系统返回一个应用程序列表(也称为展示次数),用户可以在其上执行某些操作,例如点击或购买。 这些用户操作以及查询和印象将作为学习者的训练数据记录在日志中。
Since there are over a million apps in the database, it isintractable to exhaustively score every app for every querywithin the serving latency requirements (oftenO(10) mil-liseconds). Therefore, the first step upon receiving a queryisretrieval. The retrieval system returns a short list of itemsthat best match the query using various signals, usually acombination of machine-learned models and human-definedrules. After reducing the candidate pool, therankingsys-tem ranks all items by their scores. The scores are usuallyP(y|x), the probability of a user action labelygiven thefeaturesx, including user features (e.g., country, language,demographics), contextual features (e.g., device, hour of theday, day of the week), and impression features (e.g., app age,historical statistics of an app). In this paper, we focus on theranking model using the Wide & Deep learning framework.
由于数据库中有超过一百万个应用程序,因此在服务等待时间要求(通常为10(10毫秒)毫秒)内为每个查询详尽地为每个应用程序评分是很困难的。 因此,接收到查询的第一步是检索。 检索系统使用各种信号(通常是机器学习的模型和人工定义的规则的组合)返回简短匹配的项目清单。 减少候选库后,排名系统将所有项目按其得分进行排名。 分数通常为P(y | x),带有特征x的用户动作的概率,包括用户功能(例如,国家/地区,语言,人口统计信息),上下文功能(例如,设备,一天中的小时,星期几)以及 印象功能(例如,应用程序年龄,应用程序的历史统计信息)。 在本文中,我们重点研究使用广泛和深度学习框架的排名模型。
3. WIDE & DEEP LEARNING / 广泛和深度学习
3.1 The Wide Component / ‘wide’的组件
Figure 2: Overview of the recommender system.
The wide component is a generalized linear model of theformy=wTx+b, as illustrated in Figure 1 (left).yis theprediction,x= [x1,x2,…,xd] is a vector ofdfeatures,w=[w1,w2,…,wd] are the model parameters andbis the bias.The feature set includes raw input features and transformed features. One of the most important transformations is thecross-product transformation, which is defined as:
The wide component是形式= wTx + b的广义线性模型,如图1(左)所示👇。
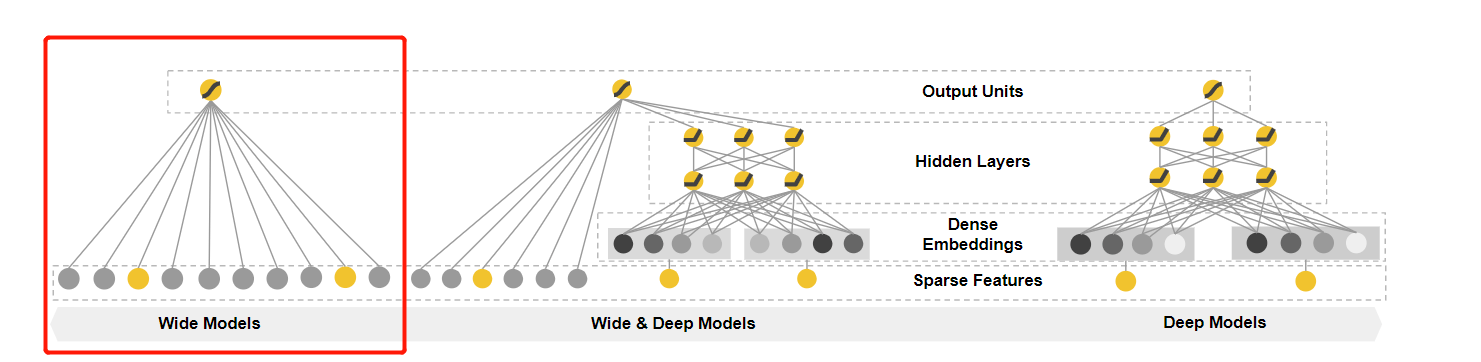
预测,x = [x1,x2,…,xd]是特征的向量,w = [w1, w2,…,wd]是模型参数,并且是偏差。特征集包括原始输入特征和变换特征。 最重要的转换之一是跨产品转换,其定义为:
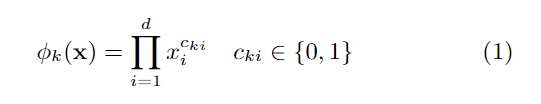
where cki is a boolean variable that is 1 if thei-th fea-ture is part of thek-th transformationφk, and 0 otherwise.For binary features, a cross-product transformation (e.g.,“AND(gender=female,language=en)”) is 1 if and only if theconstituent features (“gender=female” and “language=en”)are all 1, and 0 otherwise. This captures the interactionsbetween the binary features, and adds nonlinearity to thegeneralized linear model.
其中cki是一个布尔变量,如果第i个特征是第k个变换φk的一部分,则为1,否则为0。对于二进制特征,请进行叉积变换(例如,“ AND(gender = female,language = en )”)仅当构成要素(“性别=女性”和“语言= zh-CN”)全部为1时为1,否则为0。 这捕获了二元特征之间的相互作用,并为广义线性模型增加了非线性。
3.2 The Deep Component / ‘deep’的组件
The deep component is a feed-forward neural network, asshown in Figure 1 (right). For categorical features, the orig-inal inputs are feature strings (e.g., “language=en”). Eachof these sparse, high-dimensional categorical features arefirst converted into a low-dimensional and dense real-valuedvector, often referred to as an embedding vector. The di-mensionality of the embeddings are usually on the order ofO(10) toO(100). The embedding vectors are initialized ran-domly and then the values are trained to minimize the finalloss function during model training. These low-dimensionaldense embedding vectors are then fed into the hidden layersof a neural network in the forward pass. Specifically, eachhidden layer performs the following computation:
The deep component是前馈神经网络,如图1(右)所示👇。
对于分类要素,原始输入是要素字符串(例如,“ language = en”)。 首先将这些稀疏的高维分类特征转换为低维且密集的实值向量,通常将其称为嵌入向量。 嵌入的维度通常约为O(10)到O(100)。 随机初始化嵌入向量,然后训练值以最小化模型训练期间的finalloss函数。 然后将这些低维密集嵌入向量馈入神经网络的隐藏层中。 具体而言,每个隐藏层执行以下计算:

wherelis the layer number andfis the activation function,often rectified linear units (ReLUs).a(l),b(l), andW(l)arethe activations, bias, and model weights atl-th layer.
其中层号和激活函数通常为线性整流单元(ReLU)。a(l),b(l)和W(l)是第1层的激活,偏差和模型权重。
3.3 Joint Training of Wide & Deep Model / 深度模型联合训练
The wide component and deep component are combined using a weighted sum of their output log odds as the prediction, which is then fed to one common logistic loss func-tion for joint training. Note that there is a distinction be-tweenjoint trainingandensemble. In an ensemble, indi-vidual models are trained separately without knowing eachother, and their predictions are combined only at inferencetime but not at training time. In contrast, joint trainingoptimizes all parameters simultaneously by taking both thewide and deep part as well as the weights of their sum intoaccount at training time. There are implications on modelsize too: For an ensemble, since the training is disjoint, eachindividual model size usually needs to be larger (e.g., withmore features and transformations) to achieve reasonableaccuracy for an ensemble to work. In comparison, for jointtraining the wide part only needs to complement the weak-nesses of the deep part with a small number of cross-productfeature transformations, rather than a full-size wide model.
The wide component and deep component使用其输出对数比值的加权和作为预测进行组合,然后将其馈入一种常见的逻辑损失函数以进行联合训练。请注意,联合训练和综合之间是有区别的。联合的时候,单独模型在不相互了解的情况下进行单独训练,并且它们的预测仅在推理时组合,而在训练时不组合。相比之下,联合训练通过在训练时同时考虑最宽和最深的部分以及其总和的权重来同时优化所有参数。模型大小也会产生影响:对于整体而言,由于训练是不相交的,因此通常每个个体模型的大小都需要更大(例如具有更多特征和变换),以使整体工作达到合理的准确性。相比之下,对于联合训练,仅需使用少量跨产品功能变换来补充较深部分的弱点,而不是完整尺寸的较宽模型。
Joint training of a Wide & Deep Model is done by back-propagating the gradients from the output to both the wideand deep part of the model simultaneously using mini-batchstochastic optimization. In the experiments, we used Follow-the-regularized-leader (FTRL) algorithm [3] withL1regu-larization as the optimizer for the wide part of the model,and AdaGrad [1] for the deep part.
通过使用最小批量随机优化,同时从输出向模型的宽和深部分同时传播梯度,可以完成宽深模型的优化训练。 在实验中,我们使用具有L1规则化的跟随规则化领导(FTRL)算法[3]作为模型大部分的优化器,并使用AdaGrad [1]作为模型的最佳部分。
The combined model is illustrated in Figure 1 (center). For a logistic regression problem, the model’s prediction is:
组合模型如图1所示(中心)👇。
对于逻辑回归问题,模型的预测为:
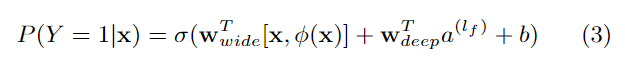
where Y is the binary class label,
σ(·) is the sigmoid func-tion,
φ(x) are the cross product transformations of the orig-inal featuresx,
and b is the bias term.
wwide is the vector ofall wide model weights,
and wdeepare the weights appliedon the final activations a(lf).
其中Y是二进制类标签,
σ(·)是S形函数,
φ(x)是原始特征x的叉积变换,
,并且b是偏差项。
wwide是所有模型权重的向量,
和wdeep是施加在最终激活a(lf)上的权重。
4. SYSTEM IMPLEMENTATION
The implementation of the apps recommendation pipeline consists of three stages: data generation, model training, and model serving as shown in Figure 3.
应用程序推荐传递途径的实现包括三个阶段:数据生成,模型训练和模型服务,如Figure 3所示。
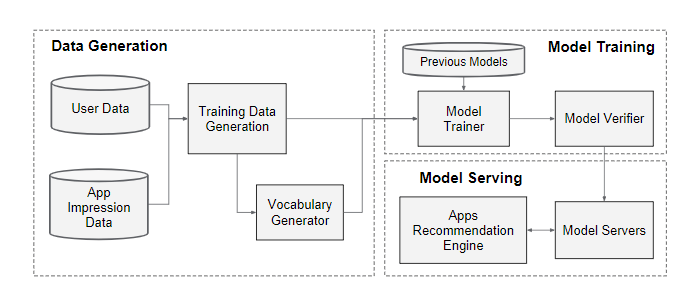
Figure 3: Apps recommendation pipeline overview.
4.1 Data Generation
In this stage, user and app impression data within a period of time are used to generate training data. Each example corresponds to one impression. The label is app acquisition: 1 if the impressed app was installed, and 0 otherwise.
在此阶段,一段时间内的用户和应用印象数据将用于生成训练数据。 每个示例对应一个印象。 标签为app acquisition:如果此程序被安装,则为1;否则为0。
Vocabularies, which are tables mapping categorical fea-ture strings to integer IDs, are also generated in this stage.The system computes the ID space for all the string featuresthat occurred more than a minimum number of times. Con-tinuous real-valued features are normalized to [0,1] by map-ping a feature valuexto its cumulative distribution functionP(X≤x), divided intonqquantiles. The normalized valueisi−1nq−1for values in thei-th quantiles. Quantile boundaries are computed during data generation.
在此阶段还会生成词汇表,这些表是将分类功能字符串映射为整数ID的表。系统会为所有出现最少次数的字符串特征计算ID空间。 通过将特征值x映射到其累积分布函数P(X≤x)(除以intonqquantiles),可以将连续的实值特征标准化为[0,1]。 第i个分位数中的值的归一化值。 在数据生成期间计算分位数边界。
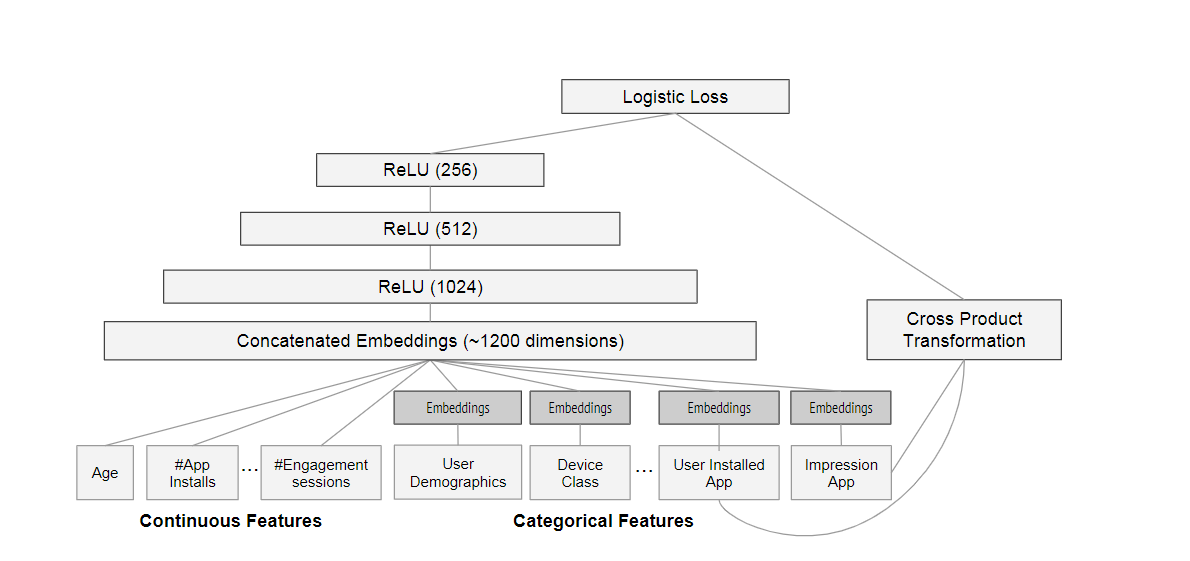
*Figure 4: Wide & Deep model structure for apps recommendation. *
4.2 Model Training
The model structure we used in the experiment is shown in Figure 4. During training, our input layer takes in training data and vocabularies and generate sparse and dense features together with a label. The wide component consists of the cross-product transformation of user installed apps and impression apps. For the deep part of the model, A 32dimensional embedding vector is learned for each categorical feature. We concatenate all the embeddings together with the dense features, resulting in a dense vector of approximately 1200 dimensions. The concatenated vector is then fed into 3 ReLU layers, and finally the logistic output unit.
我们在实验中使用的模型结构如图4所示。在训练期间,我们的输入层接收训练数据和词汇,并生成稀疏和密集特征以及标签。 广泛的组件包括用户安装的应用程序和展示应用程序的跨产品转换。 对于模型的深层部分,将为每个分类特征学习32维嵌入向量。 我们将所有嵌入与密集特征连接在一起,从而得到大约1200维的密集向量。 然后将级联的向量输入3个ReLU层,最后输入逻辑输出单元。
The Wide & Deep models are trained on over 500 billion examples. Every time a new set of training data arrives, the model needs to be re-trained. However, retraining from scratch every time is computationally expensive and delays the time from data arrival to serving an updated model. To tackle this challenge, we implemented a warm-starting system which initializes a new model with the embeddings and the linear model weights from the previous model.
wide 和 deep 联合模型已针对超过5,000亿个示例进行了训练。 每次收到一组新的训练数据时,都需要对模型进行重新训练。 但是,每次从头开始的重新训练在计算上都是昂贵的,并且会延迟从数据到达到提供更新模型的时间。 为了应对这一挑战,我们实施了热启动系统,该系统使用嵌入的模型和先前模型的线性模型权重来初始化新模型。
Before loading the models into the model servers, a dry run of the model is done to make sure that it does not cause problems in serving live traffic. We empirically validate the model quality against the previous model as a sanity check.
在将模型加载到模型服务器之前,需要对模型进行空运行以确保它不会在提供实时流量方面引起问题。 我们根据以前的模型经验性地验证模型质量,以进行完整性检查。
4.3 Model Serving
Once the model is trained and verified, we load it into the model servers. For each request, the servers receive a set of app candidates from the app retrieval system and user features to score each app. Then, the apps are ranked from the highest scores to the lowest, and we show the apps to the users in this order. The scores are calculated by running a forward inference pass over the Wide & Deep model.
对模型进行训练和验证后,我们会将其加载到模型服务器中。 对于每个请求,服务器从应用程序检索系统和用户功能部件接收一组应用程序候选者,以对每个应用程序进行评分。 然后,从最高得分到最低得分对应用程序进行排名,然后按顺序将这些应用程序显示给用户。 通过在Wide&Deep模型上运行前向推理过程来计算分数。
In order to serve each request on the order of 10 ms, we optimized the performance using multithreading parallelism by running smaller batches in parallel, instead of scoring all candidate apps in a single batch inference step.
为了满足10毫秒量级的每个请求,我们通过多线程并行运行来优化性能,方法是并行运行较小的批处理,而不是在单个批处理推理步骤中对所有候选应用程序评分。
5. EXPERIMENT RESULTS
To evaluate the effectiveness of Wide & Deep learning in a real-world recommender system, we ran live experiments and evaluated the system in a couple of aspects: app acquisitions and serving performance.
为了评估现实世界推荐系统中的广泛学习和深度学习的有效性,我们进行了现场实验,并从两个方面评估了该系统:应用程序获取和服务性能。
5.1 App Acquisitions
We conducted live online experiments in an A/B testing framework for 3 weeks. For the control group, 1% of users were randomly selected and presented with recommendations generated by the previous version of ranking model, which is a highly-optimized wide-only logistic regression model with rich cross-product feature transformations. For the experiment group, 1% of users were presented with recommendations generated by the Wide & Deep model, trained with the same set of features. As shown in Table 1, Wide & Deep model improved the app acquisition rate on the main landing page of the app store by +3.9% relative to the control group (statistically significant). The results were also compared with another 1% group using only the deep part of the model with the same features and neural network structure, and the Wide & Deep mode had +1% gain on top of the deep-only model (statistically significant).
我们在A / B测试框架中进行了3周的在线实时实验。 对于对照组,随机选择了1%的用户,并向其提供由先前版本的排名模型生成的推荐,该排名模型是高度优化的全范围逻辑回归模型,具有丰富的跨产品特征变换。 对于实验组,向1%的用户展示了由Wide&Deep模型产生的建议,并接受了相同的功能集培训。 如表1所示,
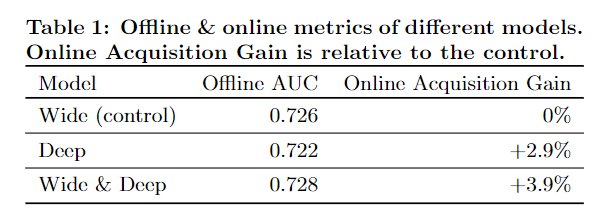
Wide&Deep模型相对于对照组(具有统计学意义)将应用商店主登陆页面上的应用获取率提高了+ 3.9%。 还仅使用具有相同特征和神经网络结构的模型的深层部分,将结果与另一个1%的小组进行了比较,宽和深层模式在仅深层模型之上具有+ 1%的增益(具有统计意义) 。
Besides online experiments, we also show the Area Under Receiver Operator Characteristic
Curve (AUC) on a holdout set offline. While Wide & Deep has a slightly higher offline AUC, the impact is more significant on online traffic. One possible reason is that the impressions and labels in offline data sets are fixed, whereas the online system can generate new exploratory recommendations by blending generalization with memorization, and learn from new user responses.
除了在线实验,我们还显示了接收器操作员区域下的特征
脱机设置的保持线上的曲线(AUC)。 虽然Wide&Deep的离线AUC略高,但对在线流量的影响更大。 一种可能的原因是,脱机数据集中的印象和标签是固定的,而在线系统可以通过将概括与记忆相结合来生成新的探索性建议,并从新的用户响应中学习。
5.2 Serving Performance
Serving with high throughput and low latency is challenging with the high level of traffic faced by our commercial mobile app store. At peak traffic, our recommender servers score over 10 million apps per second. With single threading, scoring all candidates in a single batch takes 31 ms. We implemented multithreading and split each batch into smaller sizes, which significantly reduced the client-side latency to 14 ms (including serving overhead) as shown in Table 2.
商业移动应用商店面临高流量,以高吞吐量和低延迟提供服务是一项挑战。 在流量高峰时,我们的推荐服务器每秒可记录超过1000万个应用程序。 使用单线程时,对单个批处理中的所有候选者评分需要31毫秒。 我们实施了多线程,并将每个批处理分成较小的大小,这将客户端延迟显着减少到14 ms(包括服务开销),如表2所示。
6. RELATED WORK
The idea of combining wide linear models with crossproduct feature transformations and deep neural networks with dense embeddings is inspired by previous work, such as factorization machines [5] which add generalization to linear models by factorizing the interactions between two variables as a dot product between two low-dimensional embedding vectors. In this paper, we expanded the model capacity by learning highly nonlinear interactions between embeddings via neural networks instead of dot products.
将宽线性模型与叉积特征变换以及具有密集嵌入的深层神经网络相结合的想法受到了以前的工作的启发,例如因式分解机[5],该因式分解机通过将两个变量之间的相互作用作为两个点之间的乘积进行因式分解,从而对线性模型进行了泛化。 低维嵌入向量。 在本文中,我们通过神经网络而非点积学习嵌入之间的高度非线性相互作用,从而扩展了模型的功能。
In language models, joint training of recurrent neural networks (RNNs) and maximum entropy models with n-gram features has been proposed to significantly reduce the RNN complexity (e.g., hidden layer sizes) by learning direct weights between inputs and outputs [4]. In computer vision, deep residual learning [2] has been used to reduce the difficulty of training deeper models and improve accuracy with shortcut connections which skip one or more layers. Joint training of neural networks with graphical models has also been applied to human pose estimation from images [6]. In this work we explored the joint training of feed-forward neural networks
在语言模型中,已提出通过* n * -gram特征联合训练递归神经网络(RNN)和最大熵模型,以通过学习输入和输出之间的直接权重来显着降低RNN的复杂性(例如,隐藏层大小)[4]。 ]。 在计算机视觉中,深度残差学习[2]已被用来减少训练更深层模型的难度并通过跳过一层或多层的快捷连接提高准确性。 神经网络与图形模型的联合训练也已应用于图像的人体姿势估计[6]。 在这项工作中,我们探索了前馈神经网络的联合训练
and linear models, with direct connections between sparse features and the output unit, for generic recommendation and ranking problems with sparse input data.
线性模型,在稀疏特征和输出单元之间具有直接连接,用于稀疏输入数据的通用推荐和排名问题。
In the recommender systems literature, collaborative deep learning has been explored by coupling deep learning for content information and collaborative filtering (CF) for the ratings matrix [7]. There has also been previous work on mobile app recommender systems, such as AppJoy which used CF on users’ app usage records [8]. Different from the CF-based or content-based approaches in the previous work, we jointly train Wide & Deep models on user and impression data for app recommender systems.
在推荐系统文献中,已经通过将内容信息的深度学习与评级矩阵的协作过滤(CF)耦合来探索协作深度学习[7]。 以前在移动应用推荐系统上也有过工作,例如AppJoy,它在用户的应用使用记录中使用CF [8]。 与先前工作中基于CF或基于内容的方法不同,我们联合针对应用推荐系统的用户和展示数据训练了Wide&Deep模型。
7. CONCLUSION
Memorization and generalization are both important for recommender systems. Wide linear models can effectively memorize sparse feature interactions using cross-product feature transformations, while deep neural networks can generalize to previously unseen feature interactions through lowdimensional embeddings. We presented the Wide & Deep learning framework to combine the strengths of both types of model. We productionized and evaluated the framework on the recommender system of Google Play, a massive-scale commercial app store. Online experiment results showed that the Wide & Deep model led to significant improvement on app acquisitions over wide-only and deep-only models.
记忆和概括对于推荐系统都很重要。 宽线性模型可以使用跨积特征变换有效地记住稀疏特征交互,而深度神经网络可以通过低维嵌入将其推广到以前看不见的特征交互。 我们提出了广泛和深度学习框架,以结合两种类型的模型的优势。 我们在大型商业应用商店Google Play的推荐系统上制作并评估了该框架。 在线实验结果表明,与“仅宽”和“仅深”模型相比,“宽和深”模型导致了应用获取方面的显着改善。
8. REFERENCES
[1] J. Duchi, E. Hazan, and Y. Singer. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12:2121–2159, July 2011.
[2] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. Proc. IEEE Conference on Computer Vision and Pattern Recognition, 2016.
[3] H. B. McMahan. Follow-the-regularized-leader and mirror descent: Equivalence theorems and l1 regularization. In Proc. AISTATS, 2011.
[4] T. Mikolov, A. Deoras, D. Povey, L. Burget, and J. H. Cernocky. Strategies for training large scale neural network language models. In IEEE Automatic Speech Recognition & Understanding Workshop, 2011.
[5] S. Rendle. Factorization machines with libFM. ACM Trans. Intell. Syst. Technol., 3(3) 1–57:22, May 2012.
1–57:22, May 2012.
[6] J. J. Tompson, A. Jain, Y. LeCun, and C. Bregler. Joint training of a convolutional network and a graphical model for human pose estimation. In Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q.
Weinberger, editors, NIPS, pages 1799–1807. 2014.
[7] H. Wang, N. Wang, and D.-Y. Yeung. Collaborative deep learning for recommender systems. In Proc. KDD, pages 1235–1244, 2015.
[8] B. Yan and G. Chen. AppJoy: Personalized mobile application discovery. In MobiSys, pages 113–126, 2011.
[1] See Wide & Deep Tutorial on http://tensorflow.org.
sum
- Memorization:
之前大规模稀疏输入的处理是:通过线性模型 + 特征交叉。通过特征交叉能够带来很好的效果并且可解释性强。但是Generalization(泛化能力)需要更多的人工特征工程。 - Generalization:
相比之下,DNN几乎不需要特征工程。通过对低纬度的dense embedding进行组合可以学习到更深层次的隐藏特征。但是,缺点是有点over-generalize(过度泛化)。推荐系统中表现为:会给用户推荐不是那么相关的物品,尤其是user-item矩阵比较稀疏并且是high-rank(高秩矩阵)
本作品采用《CC 协议》,转载必须注明作者和本文链接




 关于 LearnKu
关于 LearnKu




推荐文章: