
机器学习之模型选择
0 / 0 / 创建于 6年前 /
 Galois 的个人博客
Galois 的个人博客
模型选择
在选择模型时,我们将数据分为的 3 个不同部分:
- 训练集:模型训练,一般数据集中的 80
- 验证集:模型评估,一般数据集中的 20,又叫做留出集或开发集
- 测试集:模型预测,未知数据
一旦选择了模型,就会在整个数据集上进行训练,并在测试集上进行测试。如下图所示:

交叉验证
交叉验证,记为 CV,是一种不必特别依赖于初始训练集的模型选择方法。下表汇总了 几种不同的方式:

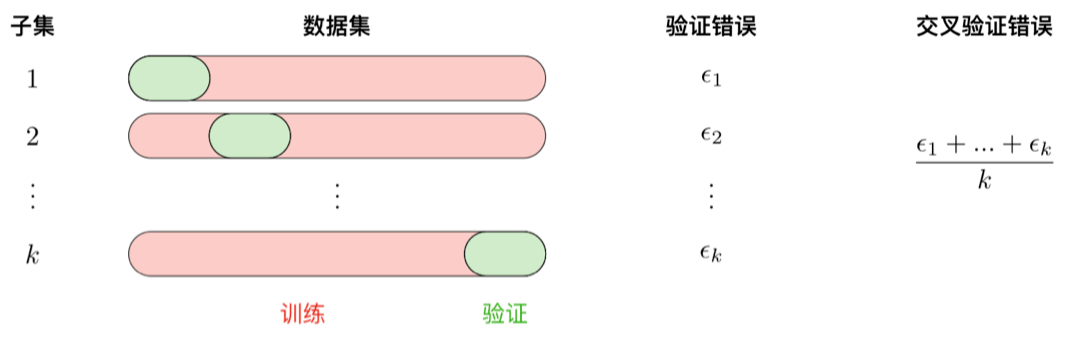
最常用的模型选择方法是 k折交叉验证,将训练集划分为 k 个子集,在 k − 1 个子集上训练模型,在剩 余的一个子集上评估模型,用这种划分方式重复训练k次。交叉验证损失是 k 次 k 折交叉验证的损失均值。
正则化
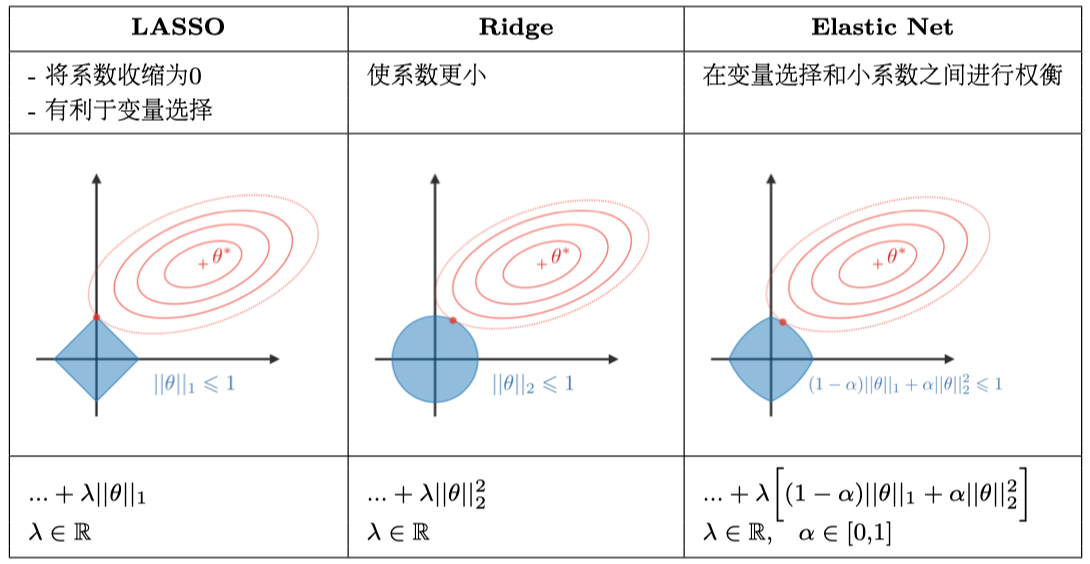
正则化方法可以解决高方差问题,避免模型对于训练数据产生过拟合。下表展示了常用的正则化方法:
本作品采用《CC 协议》,转载必须注明作者和本文链接







 关于 LearnKu
关于 LearnKu



