
「Wide & Deep Learning for Recommender Systems」- 论文摘要
0 / 0 / 创建于 6年前 /
 娃哈哈店长 的个人博客
娃哈哈店长 的个人博客
Introduction
现在推荐系统的一个难点就是同时实现Memorization以及Generalization,这个难点与搜索排名问题相似。
Memorization:
之前大规模稀疏输入的处理是:通过线性模型 + 特征交叉。通过特征交叉能够带来很好的效果并且可解释性强。但是Generalization(泛化能力)需要更多的人工特征工程。
Generalization:
相比之下,DNN几乎不需要特征工程。通过对低纬度的dense embedding进行组合可以学习到更深层次的隐藏特征。但是,缺点是有点over-generalize(过度泛化)。推荐系统中表现为:会给用户推荐不是那么相关的物品,尤其是user-item矩阵比较稀疏并且是high-rank(高秩矩阵)
Wide&Deep
本文中,介绍了一种新的方法,Wide&Deep,包括两部分,Wide Part和Deep Part。
Wide部分:利用了广义线性模型,提高可解释性。
在大规模的在线推荐系统中,logistic regression应用非常广泛,因为其简单、易扩展、可解释性。LR的输入多半是二值化后的one-hot稀疏特征。Memorization可通过在稀疏特征上做特征交叉来实现,例如:user_installed_app=netflix,impression_app=pandora,当user_installed_app与impression_app的取值都为1时,其组合特征AND(user_installed_app=netflix, impression_app=pandora)的值则为1,否则为0。
缺点:无法学习高阶组合特征,并且需要进行人工特征工程。
Deep部分:主要是发现训练集中未出现的高阶组合特征。
Embedding-based模型可以在很少的特征工程情况下,通过学习一个低维的embedding vector来学习训练集中从未见过的组合特征。例如,FM与DNN。不需要进行复杂的特征工程。
缺点:当query-item矩阵是稀疏并且是high-rank的时候(比如user有特殊的爱好,或item比较小众),很难非常效率的学习出低维度的表示。这种情况下,大部分的query-item都没有什么关系。但是dense embedding会导致几乎所有的query-item预测值都是非0的,这就导致了推荐过度泛化,会推荐一些不那么相关的物品。
总结
Wide&Deep结合以上两者的优点,平衡Memorization和Generalization。相比于wide-only和deep-only的模型,Wide&Deep提升显著。
推荐系统
推荐系统可以看成是一个search ranking问题,根据query得到items候选列表,然后对items通过ranking算法排序,得到最终的推荐列表。Wide&Deep模型是用来解决ranking问题的。
推荐系统示意图:
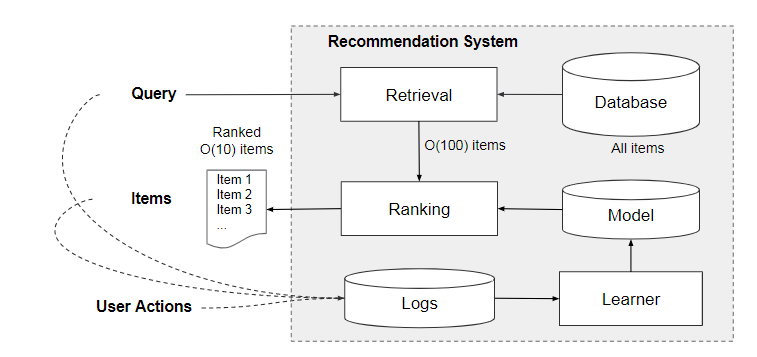
推荐系统会返回一个apps列表,这些列表中包含了user actions,例如点击或者购买。
本文是在Google APP store上的推荐,主要流程为:
Query: 当我们打开APP Store的时候,就产生了一次Query,它包含两部分的特征:user features, contextual features。user features 包括性别、年龄,国家,语言等人口统计特征,contextual features包括设备、时间(hour of the day, day of the week)等上下文特征。
Items: APP store接着展示给我们一系列的app,这些app就是推荐系统针对我们的Query给出的推荐。这个也被叫做impression。
User Actions: 针对推荐给你的任何一个APP,我们都可以点击、下载、购买等操作。也就是说推荐给你的APP,你产生了某种行为。
Logs: Logs = Query + Impression + UserAction 查询、展示列表、操作会被记录到logs中作为训练数据给Learner来学习。
Retrieval:针对这一次Query,来给出推荐列表。暴力做法:给数据库中所有的APP都打一个分数,然后按照分数从高到低返回前N个(比如说前100个)。机器学习方法:利用机器学习模型和一些人为定义的规则,来返回最匹配当前Query的一个小的items集合,这个集合就是最终的推荐列表的候选集。
Ranking:前面Learner学习到了一个Model,利用这个Model对Retrieval给出的候选集APP打分!并按照打分从高到低来排序,并返回前10个APP作为最终的推荐结果展示给用户。
Recommender system = Retrieval system + Ranking system
Retrieval system:对当前Query构造候选item集。
Ranking system:对候选item集中的item进行打分,减小候选item集数量。得分score表示成P(y|x), 表示的是一个条件概率。y是label,表示user可以采取的action,比如点击或者购买。x表示输入,特征包括:
User features(eg.country, language, demographics)
Contextual features(eg.device, hour of the day, day of the week)
Impression features(eg.app age, historical statistics of an app)
Wide&Deep Model主要是进行Ranking部分。
Wide&Deep模型
结构图:
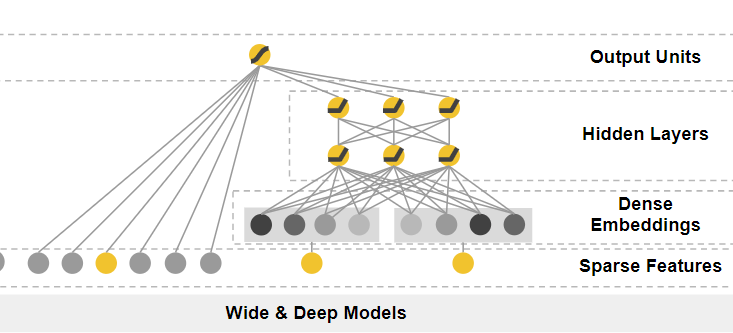
The Wide Component
广义线性模型
结构图:

输入特征:
raw input 原始特征
cross-product transformation 组合特征
组合特征公式:
\Phi(X) = \prod_{i = 1}^{d}x_{i}^{c_{ki}}, c_{ki} \in (0,1)
其中i表示输入x的第i维特征,cki表示这个第i维度特征是否要参与第k个组合特征的构造。
主要是category特征进行one-hot编码后进行交叉组合,例如,AND(gender=female, language=en)。
The Deep Component
这里采用了DNN模型,结构图如下:
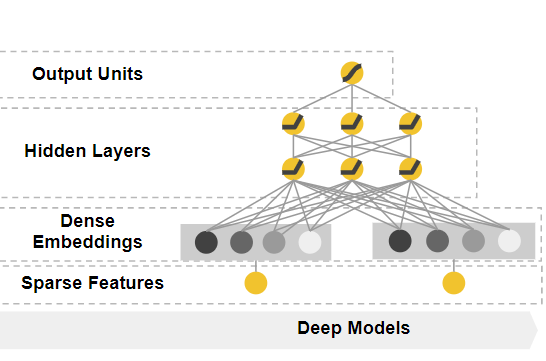
对于分类特征,原始输入是特征字符串(例如“language = en”)。 首先将这些稀疏高维分类特征中的每一个转换成低维且密集的实值向量,通常称为embedding vector。embedding vector传给隐藏层进行前向训练。隐藏层的激活函数通常使用ReLU。
系统实现
本文中采用的方法:
- 训练方法是用mini-batch stochastic optimization
- Wide组件是用FTRL(Follow-the-regularized-leader) + L1正则化学习。
- Deep组件是用AdaGrad来学习。
apps recommender结构图:
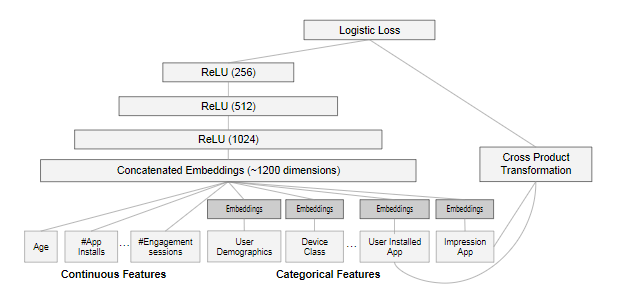
数据处理
- Categorical Features(种类特征)map 成id
过滤掉出现次数少于设定阈值的离散特征取值,然后把这些全部map成一个ID。离散特征取值少,就直接编号。多的话可能要Hash - Continuous Features(连续特征)通过分位数规范化到[0,1]
先把所有的值分成n份,那么属于第i部分的值规范化之后的值为 (i - 1)/(n - 1)。
训练
- Wide Part:
Cross Product Transformation(组合特征) - Deep Part:
Continuous Features + embedding(Categorical Features)
Embedding维度大小的建议:
Wide&Deep的作者指出,从经验上来讲Embedding层的维度大小可以用如下公式:
其中n是原始维度上特征不同取值的个数;K是一个常数,通常小于10.
结论
推荐系统中Memorization和Generalization都十分重要,Wide&Deep模型实现了对Memorization和Generalization的统一建模。
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



