
「Deep Interest Network for Click-Through Rate Prediction」- 论文摘要
9 / 0 / 创建于 4年前 /
 娃哈哈店长 的个人博客
娃哈哈店长 的个人博客
前言
目前深度学习已经运用在点击率预测上了,在这些方法中,首先将大规模稀疏输入特征映射到低维嵌入向量中,然后按照分组方式变换为定长向量,最后连接在一起馈入多层感知器(MLP)以学习非线性关系 特征。 通过这种方式,无论候选广告是什么,用户特征都被压缩成一个固定长度的表示向量。但是 使用定长的向量会带来瓶颈,这将会使 Embedding&MLP方法从历史信息中捕获用户的多样化的兴趣带来困难。
本文提出了DIN模型,可以
(1)使用兴趣分布代表用户多样化的兴趣(不同用户对不同商品有兴趣)
(2)与attention机制一样,根据ad局部激活用户兴趣相关的兴趣(用户有很多兴趣,最后导致购买的是小部分兴趣,仅仅取决于历史行为数据中的一小部分,而不是全部。attention机制就是保留并激活这部分兴趣)。
在输入层增加了激活单元。
Introduction
随着深度学习在CV、NLP等领域取得突破性进展,一些研究也开始尝试将DNN应用于CTR预测。
一般做法:
在输入上面加一层embedding层,把最原始高维度、稀疏的数据转换为低维度的实值表示上(dense vector)。
增加多个全连接层,学习特征之间的非线性关系。Sparse Features -> Embedding Vector -> MLPs -> Output
用户的历史行为数据由于存在一个用户有多个兴趣,仅仅通过embedding转成成定长的特征向量是有局限性的,即diverse问题。
DEEP INTEREST NETWORK
本文提出DIN模型,同时对Diversity和Local Activation进行建模。
- Diversity:针对用户广泛的兴趣,DIN用an interest distribution去表示。
- Local Activation:历史行为中部分数据主导是否会点击候选广告。DIN借鉴机器翻译中的Attention机制,设计了一种attention-like network structure, 针对当前候选Ad,去局部的激活(Local Activate)相关的历史兴趣信息。和当前候选Ad相关性越高的历史行为,会获得更高的attention score,从而会主导这一次预测。能够很好的捕获用户兴趣的多样性特征。
CTR中输入普遍存在的特点:
- 高纬度
- 高度稀疏
- 多值离散特征(涉及到用户行为数据,例如访问多个不同的商品id等)
用户购买过的good_id有多个,购买过的shop_id也有多个,而这也直接导致了每个用户的历史行为id长度是不同的。针对多值离散特征,为了得到一个固定长度的Embedding Vector表示,原来的做法是在Embedding Layer后面增加一个Pooling Layer。Pooling可以用sum或average。最终得到一个固定长度的Embedding Vector,是用户兴趣的一个抽象表示,常被称作User Representation。缺点是会损失一些信息。DIN使用Attention机制来解决这个问题。在DIN场景中,针对不同的候选广告需要自适应地调整User Representation。也就是说:在Embedding Layer -> Pooling Layer得到用户兴趣表示的时候,赋予不同的历史行为不同的权重,实现局部激活。
Feature Representation
把特征分为四大类:
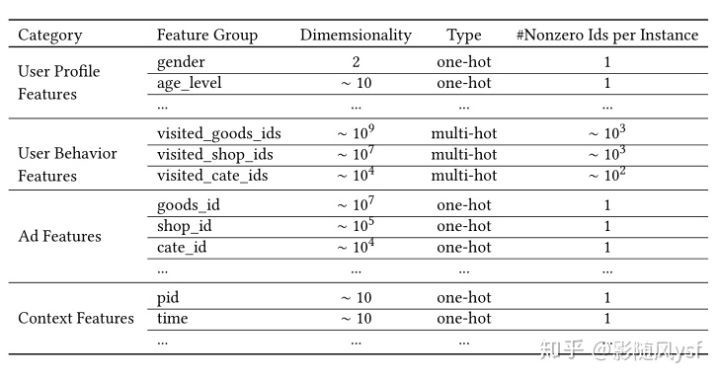
从图中可以看出主要的特征包括:用户特征、用户行为特征、广告特征、上下文特征。其中用户行为特征为多值离散特征,这就会导致每个用户的样本长度都是不同的,同时也需要对多样化的兴趣建模。解决方法:Embedding -> pooling + attention
Base Model(Embedding&MLP)
结构图:
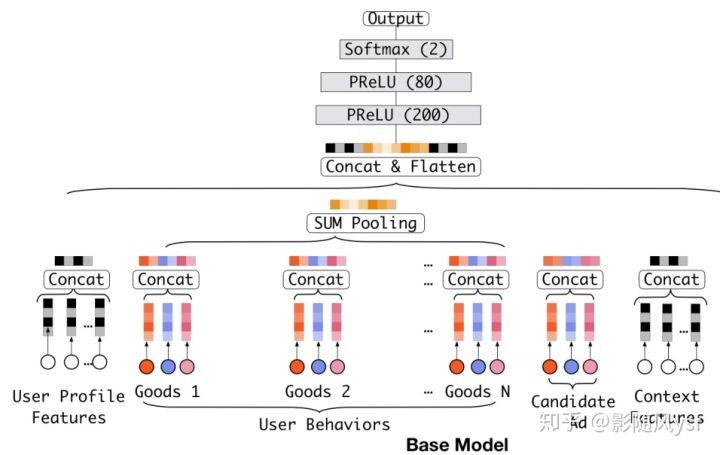
Embedding layer:输入的是高维度的二值向量(one-hot),通过Embedding layer后转化成低维dense vector。
Pooling layer and Concat layer:对于一个用户,之前购买过的good_ids组成了一个user behavior sequence ids。针对不同的用户,这个序列的长度是不同的(不同用户购买的物品数量不同),所以在Embedding Layer后加入Pooling Layer,使用的是sum operation,把这些goods或shops的embedding vector相加,得到一个固定长度的向量作为MLPs的输入。
MLP:全连接层
Loss:
L = - \frac{1}{N} \sum_{(x,y) \in S}(y logp(x)+(1-y)log(1-p(x)))
DIN
结构图:
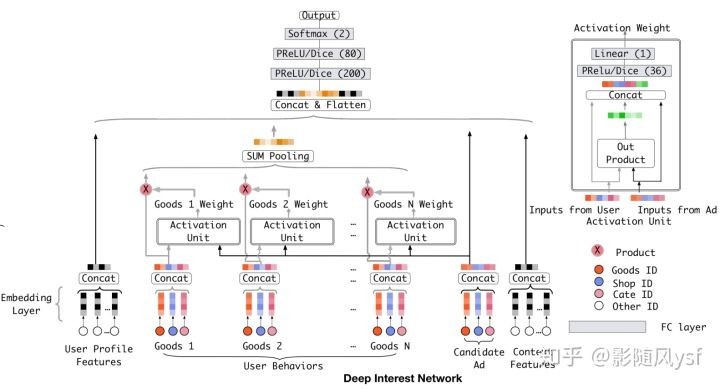
由于经过Pooling层后会损失一定的信息,则提出了DIN模型,实际上是在Embedding层和Pooling层之间加入activation单元,这个思想来自attention机制,实际上也可以说在 Base Model上加入了attention机制,而这个与传统的attention机制不同的是权重Wi的大小是针对用户兴趣的。举个例子:假设用户的历史行为中包含90%的衣服和10%的电子产品,现在 给两个候选广告T-shirt和iPhone,那么对应于T-shirt激活单元的权重应该远大于对应于iPhone的激活单元。
本文尝试用LSTM以序列的方式建模用户历史行为数据。但是并没有提升。与NLP任务中受语法约束的文本不同,用户历史行为的序列可能包含多个同时存在的兴趣。 快速跳跃和突然结束这些兴趣会导致用户行为的序列数据看起来是噪声。
模型的目标:基于用户历史行为,充分挖掘用户兴趣和候选广告之间的关系。用户是否点击某个广告往往是基于他之前的部分兴趣,这是应用Attention机制的基础。Attention机制简单的理解就是对于不同的特征有不同的权重,这样某些特征就会主导这一次的预测,就好像模型对某些特征pay attention。但是,DIN中并不能直接用attention机制。因为对于不同的候选广告,用户兴趣表示(embedding vector)应该是不同的。
在MLP中使用PReLu:
f(s) = \left\{\begin{matrix} s & if :s < 0 \\ \alpha s & if: s \leqslant 0 \end{matrix}\right. = p(s) \cdot s +(1-p(s)) \cdot \alpha s
无论是ReLU还是PReLU突变点都在0,论文里认为,对于所有输入不应该都选择0点为突变点而是应该依赖于数据的。于是提出了一种data dependent的方法:Dice激活函数:
f(s) = p(s) \cdot + (1-p(s)) \cdot \alpha s, p(s) = \frac{1}{1+e^{-\frac{s-E[s]}{\sqrt{Var[s]+\epsilon }}}}
pi的计算分两步:
1、 首先,对x进行均值归一化处理,这使得整流点是在数据的均值处,实现了data dependent的想法;
2、 其次,经过一个sigmoid函数的计算,得到了一个0到1的概率值。巧合的是最近google提出的Swish函数形式为x sigmoid(x) 在多个实验上证明了比ReLU函数xMax(x,0)表现更优。
另外,期望和方差使用每次训练的mini batch data直接计算,并类似于Momentum使用了指数加权平均:
{E[y_{i}]{t+1}}’ = {E[yi]}’ + \alpha E[y{i}]_{t+1}
{Var[y_{i}]{t+1}}’ = {Var[yi]}’ + \alpha Var[y{i}]_{t+1}
,\alpha是一个超参数,推荐值为0.99。
总结
- 用户有多个兴趣爱好,访问了多个good_id,shop_id。为了降低维度并使得商品店铺间的算术运算有意义,我们先对其进行Embedding嵌入。那么我们如何对用户多种多样的兴趣建模呢?使用Pooling对Embedding Vector求和或者求平均。同时这也解决了不同用户输入长度不同的问题,得到了一个固定长度的向量。这个向量就是用户表示,是用户兴趣的代表。
- 但是,直接求sum或average损失了很多信息。所以稍加改进,针对不同的behavior id赋予不同的权重,这个权重是由当前behavior id和候选广告共同决定的。这就是Attention机制,实现了Local Activation。
- DIN使用activation unit来捕获local activation的特征,使用weighted sum pooling来捕获diversity结构。
- 在模型学习优化上,DIN提出了Dice激活函数、自适应正则 ,显著的提升了模型性能与收敛速度。
本作品采用《CC 协议》,转载必须注明作者和本文链接


 关于 LearnKu
关于 LearnKu



