
「Attentional Factorization Machines」- 论文摘要
0 / 0 / 创建于 6年前 /
 娃哈哈店长 的个人博客
娃哈哈店长 的个人博客
前言
FM能够发现二阶组合特征,但是所有特征的权重都是一样的,这会阻碍FM的效果,因为不是所有的特征都是有用的,例如有些无用的特征进行组合会引入噪声,降低FM的效果。本文提出了AFM模型,通过引入attention机制,学习交互特征的重要程度。
Introduction
为了平衡特征之间的交互,可以利用polynomial regression(多项式回归)来学习交互特征的权重,但是会存在一个主要的问题(与Wide&Deep中的Wide部分一样):在稀疏数据集中仅能观察到少量交互特征,对于样本中没出现这个组合特征,Poly2学习不到权重,样本的不充分也会导致学习的参数不准确,Poly2中对于每个组合特征的权重是独立的,你无法从A特征的权重中得到关于B的任何信息。
为了解决ploy2这个问题,提出了FM模型。FM中组合特征的权重不再是独立的。对于一些无用的特征,应该设置很低的权重,但是FM缺少这个作用。本文引入attention机制来解决这个问题。自动学习组合特征的不同的权重。
Attentional Factorization Machines
FM
\hat{y} \cdot FM(x) =\underbrace{w_{0} + \sum_{i=1}^{n}w_{i}x_{i}}{linear regression} + \underbrace{\sum{i=1}^{n}\sum_{j=i+1}^{n} \hat w_{ij}x_{i}x_{j}}_{pair-wise feature interactions}
其中W0为偏差,Wi为第i个特征的权重,Wi,j为组合特征xixj的权重。
\hat{w}{ij} = v{i}^{T}v_{j}
,vi∈ Rk,且对应第i个特征的embedding vector。FM会赋给所有可能存在的交互特征以相同的权重,即使这个特征是无用的。
AFM
结构图:
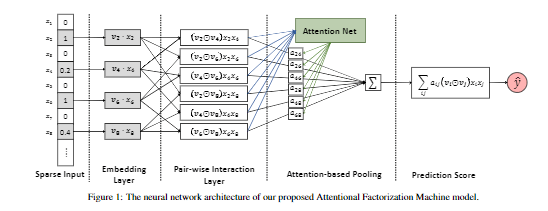
Input Layer&Embedding Layer
输入的特征向量X,去掉0值,经过Embedding Layer得到
\varepsilon = ( v_{i} x_{i} )_{i \in x}
Pair-wise Interaction Layer
受到FM的启发,使用内积得到组合特征(each pair of features),现在提出Pair-wise Interaction Layer,如果特征向量大小为m,通过这一层后会得到 大小为m(m − 1)/2的组合特征向量。把embedding后的向量进行两两组合,得到:
f_{PI}(\varepsilon) = [(v_{i} \bigodot v_{j})x_ix_j]_{(i,j)\in R_x}
然后经过sum pooling -> fc层得到最后的预测结果,表达式为:
\hat{y} = P^{T} \sum_{(i,j)\in R_x} (v_i \bigodot v_j)x_ix_j + b
其中p为权重,b为偏差,若p全为1,即所有特征的权重为1,b为0,则此模型变成FM模型。
Attention-based Pooling Layer
引入attention机制,给每组交互特征赋予权重,表达式为:
f_Att(f_PI(\varepsilon)) = \sum {(i,j)\in R_x} a{ij}(v_i \bigodot v_j)x_i x_j
其中ai,j的值是通过最小化损失函数得到的,所以还需要加入MLP,将此层称为attention network,现定义为:
score:
{a_{ij}}’ = h^{T}ReLU(W(v_{i}\bigodot v_j)x_i x_j + b)
对score进行 softmax 的归一化:
a_{ij} = \frac{exp({a_{ij}}’)}{\sum_{i,j}\in R_x exp({a_ij}’)}
最后AFM模型的输出:
\hat y_{AFM}(x) = w_{0} + \sum_{i=1}^{n}w_{i}x_{i} + p^T \sum^n_{i=1}\sum^n_{j=i+1} a_{ij} (v_i \bigodot v_j) x_i x_j
AFM = LR + Embedding + Attention + MLP
LR:
\sum ^n _{i=1} w_i x_i
AFM目标函数
回归任务:使用平方损失函数
L_r = \sum {x\in \tau }(\hat{y}{AFM}(x) - y(x))^2
二分类任务:logloss
使用SGD进行参数优化,加入L2正则项或者dropout来防止过拟合的情况。
欢AFM的做法:
在pair-wise interaction layer使用dropout正则化
在attention network使用L2正则化,不采用dropout正则化的原因,是因为当把dropout加入attention network后会出现问题,使效果降低。
L = \sum_{x\in \tau} (\hat(y)_{AFM}(x) - y{x})^2 +\lambda \left || W \right ||^2
总结
AFM是在FM的基础上进行优化,加入了attention Network,通过attention机制建立权重矩阵来学习两两向量组合时不同的权重,该权重矩阵将会作用到最后的二阶项中,进而得到最终的结果。
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu



