
Python 数据科学之 Numpy
0 / 0 / 创建于 5年前 /
 Galois 的个人博客
Galois 的个人博客
NumPy - 简介
NumPy 是一个 Python 包。 它代表 “Numeric Python”。 它是一个由多维数组对象和用于处理数组的例程集合组成的库。
Numeric,即 NumPy 的前身,是由 Jim Hugunin 开发的。 也开发了另一个包 Numarray ,它拥有一些额外的功能。 2005 年,Travis Oliphant 通过将 Numarray 的功能集成到 Numeric 包中来创建 NumPy 包。 这个开源项目有很多贡献者。
NumPy 通常与 SciPy(Scientific Python)和 Matplotlib(绘图库)一起使用。 这种组合广泛用于替代「MatLab」,是一个流行的技术计算平台。 但是,Python 作为 「MatLab」的替代方案,现在被视为一种更加现代和完整的编程语言。
NumPy - Ndarray 对象
NumPy 中定义的最重要的对象是称为 ndarray 的 N 维数组类型。 它描述相同类型的元素集合。 可以使用基于零的索引访问集合中的项目。
ndarray中的每个元素在内存中使用相同大小的块。 ndarray中的每个元素是数据类型对象的对象(称为 dtype)。
从ndarray对象提取的任何元素(通过切片)由一个数组标量类型的 Python 对象表示。 下图显示了ndarray,数据类型对象(dtype)和数组标量类型之间的关系。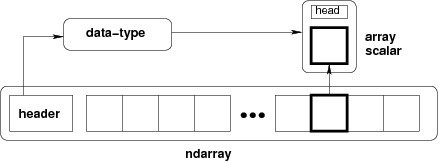
基本的ndarray是使用 NumPy 中的数组函数创建的,如下所示:
numpy.array 它从任何暴露数组接口的对象,或从返回数组的任何方法创建一个ndarray。
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)| 序号 | 参数及描述 |
|---|---|
| 1. | object任何暴露数组借口方法的对象都会返回一个数组或任何(嵌套)序列 |
| 2. | dtype数组的所需数据类型,可选 |
| 3. | copy默认为 true,对象是否被复制,可选 |
| 4. | orderC(按行)、F(按列)或 A(任意,默认)。 |
| 5. | subok默认情况下,返回的数组被强制为基类数组。如果为 true,则返回子类 |
| 6. | dnmin指定返回数组的最小维数。 |
# 一维
a = np.array([1,2,3])
print(type(a),a)
# 二维
b = np.array([[1, 2], [3, 4]])
print(b)
# 最小维度
c = np.array([1, 2, 3, 4, 5], ndmin = 2)
print(c)
# dtype 参数
d = np.array([1, 2, 3], dtype = complex)
print(d)NumPy - 数据类型
NumPy 支持比 Python 更多种类的数值类型。 下表显示了 NumPy 中定义的不同标量数据类型。
| 序号 | 数据类型及描述 |
|---|---|
| 1. | bool_ 存储为一个字节的布尔值(真或假) |
| 2. | int_ 默认整数,相当于 C 的 long,通常为 int32 或 int64 |
| 3. | intc 相当于 C 的 int,通常为 int32 或 int64 |
| 4. | intp 用于索引的整数,相当于 C 的 size_t,通常为 int32 或 int64 |
| 5. | int8 字节(-128 ~ 127) |
| 6. | int16 位整数(-32768 ~ 32767) |
| 7. | int32 位整数(-2147483648 ~ 2147483647) |
| 8. | int64 位整数(-9223372036854775808 ~ 9223372036854775807) |
| 9. | uint8 位无符号整数(0 ~ 255) |
| 10. | uint16 位无符号整数(0 ~ 65535) |
| 11. | uint32 位无符号整数(0 ~ 4294967295) |
| 12. | uint64 位无符号整数(0 ~ 18446744073709551615) |
| 13 | float_ float64 的简写 |
| 14 | float16 半精度浮点:符号位,5 位指数,10 位尾数 |
| 15 | float32 单精度浮点:符号位,8 位指数,23 位尾数 |
| 16 | float64 双精度浮点:符号位,11 位指数,52 位尾数 |
| 17 | complex_ complex128 的简写 |
| 18 | complex64 复数,由两个 32 位浮点表示(实部和虚部) |
| 19 | complex128 复数,由两个 64 位浮点表示(实部和虚步) |
NumPy 数字类型是dtype(数据类型)对象的实例,每个对象具有唯一的特征。 这些类型可以是np.bool_,np.float32等。
数据类型对象 (dtype)
数据类型对象描述了对应于数组的固定内存块的解释,取决于以下方面:
数据类型(整数、浮点或者 Python 对象)
数据大小
字节序(小端或大端)
在结构化类型的情况下,字段的名称,每个字段的数据类型,和每个字段占用的内存块部分。
如果数据类型是子序列,它的形状和数据类型。
字节顺序取决于数据类型的前缀
<或>。<意味着编码是小端(最小有效字节存储在最小地址中)。>意味着编码是大端(最大有效字节存储在最小地址中)。
dtype可由一下语法构造:
numpy.dtype(object, align, copy)Object: 被转换为数据类型的对象。
Align: 如果为 true,则向字段添加间隔,使其类似 C 的结构体。
Copy: 生成 dtype 对象的新副本,如果为 flase,结果是内建数据类型对象的引用。
# 使用数组标量类型
dt = np.dtype(np.int32)
print(dt)
#int8,int16,int32,int64 可替换为等价的字符串 'i1','i2','i4',以及其他。
import numpy as np
dt = np.dtype('i4')
print(dt)
# 使用端记号
dt = np.dtype('>i4')
print(dt)
# 首先创建结构化数据类型。
dt = np.dtype([('age',np.int8)])
print(dt)
# 现在将其应用于 ndarray 对象
dt = np.dtype([('age',np.int8)])
a = np.array([(10,),(20,),(30,)], dtype = dt)
print(a)
# 文件名称可用于访问 age 列的内容
dt = np.dtype([('age',np.int8)])
a = np.array([(10,),(20,),(30,)], dtype = dt)
print(a['age'])
# 定义名为 student 的结构化数据类型,其中包含字符串字段 name,整数字段 age 和浮点字段marks。 此 dtype 应用于 ndarray 对象。
student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
print(student)
student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
a = np.array([('abc', 21, 50),('xyz', 18, 75)], dtype = student)
print(a)
"""
每个内建类型都有一个唯一定义它的字符代码:
'b':布尔值
'i':符号整数
'u':无符号整数
'f':浮点
'c':复数浮点
'm':时间间隔
'M':日期时间
'O':Python 对象
'S', 'a':字节串
'U':Unicode
'V':原始数据(void)"""NumPy - 数组属性
ndarray.shape
a = np.array([[1,2,3],[4,5,6]])
print(a.shape)
# 调整数组大小
a.shape = (3,2)
print(a)
# reshape
a = np.array([[1,2,3],[4,5,6]])
b = a.reshape(3,2)
print(b)
# 等间隔数字的数组
a = np.arange(24)
print(a)
# 一维数组
a = np.arange(24)
a.ndim
# 现在调整其大小
b = a.reshape(2,4,3)
print(b)
# b 现在拥有三个维度
# 数组的 dtype 为 int8(一个字节)
x = np.array([1,2,3,4,5], dtype = np.int8)
print('x.itemsize: ', x.itemsize)
# 数组的 dtype 现在为 float32(四个字节)
x = np.array([1,2,3,4,5], dtype = np.float32)
print('x.itemsize: ', x.itemsize)numpy.flags ndarray 对象拥有以下属性。这个函数返回了它们的当前值。
| 序号 | 属性及描述 |
|---|---|
| 1. | C_CONTIGUOUS (C)数组位于单一的、C 风格的连续区段内 |
| 2. | F_CONTIGUOUS (F)数组位于单一的、Fortran 风格的连续区段内 |
| 3. | OWNDATA (O)数组的内存从其它的对象处借用 |
| 4. | WRITEABLE (W)数据区域可写入,将它设置位 false 会锁定数据,使其只读 |
| 5. | ALIGNED (A)数据和任何元素会为硬件适当对齐 |
| 6. | UPDATEIFCOPY (U)这个数组是另一数组的副本,当这个数组释放时,源数组会由这个数组中的元素更新 |
x = np.array([1,2,3,4,5])
print(x.flags)NumPy - 数组创建例程
新的 ndarray 对象可以通过任何下列数组创建例程或使用低级 ndarray 构造函数构造。
numpy.empty
它创建指定形状和 dtype 的未初始化数组。 它使用以下构造函数:
numpy.empty(shape, dtype = float, order = 'C')构造器接受下列参数:
| 序号 | 参数及描述 |
|---|---|
| 1. | Shape空数组的形状,整数或整数元祖 |
| 2. | Dtype所需输出的数组类型,可选 |
| 3. | Order‘C’为按行的 C 风格数组,’D’为按列的 Fortran 风格数组 |
x = np.empty([3,2], dtype = int, order = 'C')
print(x)numpy.zeros 以 0 填充的新数组
numpy.zeros(shape, dtype = float, order = 'C')# 含有 5 个 0 的数组,默认类型为 float
x = np.zeros(5)
print(x)
x = np.zeros((5,), dtype = np.int)
print(x)
# 自定义类型
x = np.zeros((2,2), dtype = [('x', 'i4'), ('y', 'f4')])
print(x)numpy.ones 以 1 填充的新数组
numpy.ones(shape, dtype = float, order = 'C')# 含有 5 个 1 的数组,默认类型为 float
x = np.ones(5)
print(x)
x = 5*np.ones([2,2], dtype = int)
print(x)NumPy - 来自现有数据的数组
numpy.asarray 此函数类似于numpy.array,除了它有较少的参数。 这个例程对于将 Python 序列转换为 ndarray 非常有用。
numpy.asarray(a, dtype = None, order = None)构造器接受下列参数:
| 序号 | 参数及描述 |
|---|---|
| 1. | a任意形式的输入参数,比如列表、列表和元祖、元祖、元祖的元祖、元祖的列表 |
| 2. | dtype通常,输入数据的类型会应用到返回的ndarray |
| 3. | order‘C’为按行的 C 风格数组,’D’为按列的 Fortran 风格数组 |
x = [1,2,3]
a = np.asarray(x)
print(a)
# 设置了 dtype
x = [1,2,3]
a = np.asarray(x, dtype = float)
print(a)
# 来自元组的 ndarray
x = (1,2,3)
a = np.asarray(x)
print(a)
# 来自元组列表的 ndarray
x = [(1,2,3),(4,5)]
a = np.asarray(x)
print(a)numpy.frombuffer
此函数将缓冲区解释为一维数组。 暴露缓冲区接口的任何对象都用作参数来返回 ndarray。
构造器接受下列参数:
| 序号 | 参数及描述 |
|---|---|
| 1. | buffer任何暴露缓冲区接口的对象 |
| 2. | dtype返回数组的数据类型,默认为 float |
| 3. | count需要读取的数据数量,默认为 -1,读取所有数据 |
| 4. | offset需要读取的起始位置,默认为 0 |
s = 'Hello World'
a = np.frombuffer(s.encode(), dtype = 'S1')
print(a)numpy.fromiter 此函数从任何可迭代对象构建一个 ndarray 对象,返回一个新的一维数组。
numpy.fromiter(iterable, dtype, count = -1)构造器接受下列参数:
| 序号 | 参数及描述 |
|---|---|
| 1. | iterable任何可迭代的对象 |
| 2. | dtype返回数组的数据类型 |
| 3. | count需要读取的数据数量,默认为 -1,读取所有数据 |
# 使用 range 函数创建列表对象
list = range(5)
print(list)
# 从列表中获得迭代器
list = range(5)
it = iter(list)
# 使用迭代器创建 ndarray
x = np.fromiter(it, dtype = float)
print(x)NumPy - 来自数值范围的数组
numpy.arange
这个函数返回ndarray对象,包含给定范围内的等间隔值。
numpy.arange(start, stop, step, dtype)构造器接受下列参数:
| 序号 | 参数及描述 |
|---|---|
| 1. | start范围的起始值,默认为 0 |
| 2. | stop范围的终止值(不包含) |
| 3. | step两个值的间隔,默认为 1 |
| 4. | dtype返回 ndarray 的数据类型,如果没有提供,则会使用输入数据的类型 |
x = np.arange(5)
print(x)
# 设置了 dtype
x = np.arange(5, dtype = float)
print(x)
# 设置了起始值和终止值参数
x = np.arange(10,20,2)
print(x)numpy.linspace
此函数类似于arange()函数。 在此函数中,指定了范围之间的均匀间隔数量,而不是步长。 此函数的用法如下。
numpy.linspace(start, stop, num, endpoint, retstep, dtype)构造器接受下列参数:
| 序号 | 参数及描述 |
|---|---|
| 1. | start序列的起始值 |
| 2. | stop序列的终止值,如果 endpoint 为 true,该值包含于序列中 |
| 3. | num要生成的等间隔阳历数量,默认为 50 |
| 4. | endpoint序列中是否包含 stop 值,默认为 true |
| 5. | restep如果为 true,返回样例,以及连续数字之间的步长 |
| 6. | dtype输出 ndarray 的数据类型 |
x = np.linspace(10, 20 ,5)
print(x)
# 将 endpoint 设为 false
x = np.linspace(10, 20, 5, endpoint = False)
print(x)
# 输出 retstep 值
x = np.linspace(1,2,5, retstep = True)
print(x)
# 这里的 retstep 为 0.25numpy.logspace
此函数返回一个ndarray对象,其中包含在对数刻度上均匀分布的数字。 刻度的开始和结束端点是某个底数的幂,通常为 10。
numpy.logscale(start, stop, num, endpoint, base, dtype)logspace函数的输出由以下参数决定:
| 序号 | 参数及描述 |
|---|---|
| 1. | start起始值是 base ** start |
| 2. | stop终止值是 base ** stop |
| 3. | num范围内的数值数量,默认为 50 |
| 4. | endpoint如果为 true,终止值包含在输出数组当中 |
| 5. | base对数空间的底数,默认为 10 |
| 6. | dtype输出数组的数据类型,如果没有提供,则取决于其它参数 |
# 默认底数是 10
a = np.logspace(1.0, 2.0, num = 10)
print(a)
# 将对数空间的底数设置为 2
a = np.logspace(1, 10, num = 10, base = 2)
print(a)NumPy - 切片和索引
ndarray对象的内容可以通过索引或切片来访问和修改,就像 Python 的内置容器对象一样。
如前所述,ndarray对象中的元素遵循基于零的索引。 有三种可用的索引方法类型: 字段访问,基本切片和高级索引。
基本切片是 Python 中基本切片概念到 n 维的扩展。 通过将start,stop和step参数提供给内置的slice函数来构造一个 Python slice 对象。 此 slice 对象被传递给数组来提取数组的一部分。
# ndarray 对象由 arange() 函数创建。
# 然后,分别用起始,终止和步长值 2,7 和 2 定义切片对象。 当这个切片对象传递给 ndarray 时,会对它的一部分进行切片,从索引 2 到 7,步长为 2。
a = np.arange(10)
s = slice(2,7,2)
print(a[s])
# 通过将由冒号分隔的切片参数(start:stop:step)直接提供给ndarray对象,也可以获得相同的结果。
a = np.arange(10)
b = a[2:7:2]
print(b)
# 如果只输入一个参数,则将返回与索引对应的单个项目。 如果使用a:,则从该索引向后的所有项目将被提取。
# 如果使用两个参数(以:分隔),则对两个索引(不包括停止索引)之间的元素以默认步骤进行切片。
# 对单个元素进行切片
a = np.arange(10)
b = a[5]
print(b)
# 对始于索引的元素进行切片
a = np.arange(10)
print(a[2:])
# 对索引之间的元素进行切片
a = np.arange(10)
print(a[2:5])
# 也可用于多维ndarray。
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print(a)
# 对始于索引的元素进行切片
print('现在从索引 a[1:] 开始对数组切片')
print(a[1:])
# 最开始的数组
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print('我们的数组是:')
print(a)
print('\n')
# 这会返回第二列元素的数组:
print('第二列的元素是:')
print(a[...,1])
print('\n')
# 现在我们从第二行切片所有元素:
print('第二行的元素是:')
print(a[1,...])
print('\n')
# 现在我们从第二列向后切片所有元素:
print('第二列及其剩余元素是:')
print(a[...,1:])
# 切片还可以包括省略号(...),来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它将返回包含行中元素的ndarray。NumPy - 高级索引
如果一个ndarray是非元组序列,数据类型为整数或布尔值的ndarray,或者至少一个元素为序列对象的元组,我们就能够用它来索引ndarray。高级索引始终返回数据的副本。 与此相反,切片只提供了一个视图。
有两种类型的高级索引:整数和布尔值。
整数索引
这种机制有助于基于 N 维索引来获取数组中任意元素。 每个整数数组表示该维度的下标值。 当索引的元素个数就是目标ndarray的维度时,会变得相当直接。
以下示例获取了ndarray对象中每一行指定列的一个元素。 因此,行索引包含所有行号,列索引指定要选择的元素。
x = np.array([[1, 2], [3, 4], [5, 6]])
y = x[[0,1,2], [0,1,0]]
print(y)
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print('我们的数组是:')
print(x)
print('\n')
rows = np.array([[0,0],[3,3]])
cols = np.array([[0,2],[0,2]])
y = x[rows,cols]
print('这个数组的每个角处的元素是:')
print(y)高级和基本索引可以通过使用切片:或省略号...与索引数组组合。 以下示例使用slice作为列索引和高级索引。 当切片用于两者时,结果是相同的。 但高级索引会导致复制,并且可能有不同的内存布局。
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print('我们的数组是:')
print(x)
print('\n')
# 切片
z = x[1:4,1:3]
print('切片之后,我们的数组变为:')
print(z)
print('\n')
# 对列使用高级索引
y = x[1:4,[1,2]]
print('对列使用高级索引来切片:')
print(y)布尔索引
当结果对象是布尔运算(例如比较运算符)的结果时,将使用此类型的高级索引。
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print('我们的数组是:')
print(x)
print('\n')
# 打印出大于 5 的元素
print('大于 5 的元素是:')
print(x[x > 5])
# ~ 取补运算符
a = np.array([np.nan, 1,2,np.nan,3,4,5])
print(a[~np.isnan(a)])
# 过滤非复数元素
a = np.array([1, 2+6j, 5, 3.5+5j])
print(a[np.iscomplex(a)])NumPy - 广播
术语广播是指 NumPy 在算术运算期间处理不同形状的数组的能力。 对数组的算术运算通常在相应的元素上进行。 如果两个阵列具有完全相同的形状,则这些操作被无缝执行。
a = np.array([1,2,3,4])
b = np.array([10,20,30,40])
c = a * b
print(c)如果两个数组的维数不相同,则元素到元素的操作是不可能的。 然而,在 NumPy 中仍然可以对形状不相似的数组进行操作,因为它拥有广播功能。 较小的数组会广播到较大数组的大小,以便使它们的形状可兼容。
如果满足以下规则,可以进行广播:
ndim较小的数组会在前面追加一个长度为 1 的维度。
输出数组的每个维度的大小是输入数组该维度大小的最大值。
如果输入在每个维度中的大小与输出大小匹配,或其值正好为 1,则在计算中可它。
如果输入的某个维度大小为 1,则该维度中的第一个数据元素将用于该维度的所有计算。
如果上述规则产生有效结果,并且满足以下条件之一,那么数组被称为可广播的。
数组拥有相同形状。
数组拥有相同的维数,每个维度拥有相同长度,或者长度为 1。
数组拥有极少的维度,可以在其前面追加长度为 1 的维度,使上述条件成立。
a = np.array([[0.0,0.0,0.0],[10.0,10.0,10.0],[20.0,20.0,20.0],[30.0,30.0,30.0]])
b = np.array([1.0,2.0,3.0])
print('第一个数组:')
print(a)
print('\n')
print('第二个数组:')
print(b)
print('\n')
print('第一个数组加第二个数组:')
print(a + b)数组 b 如何通过广播来与数组a兼容。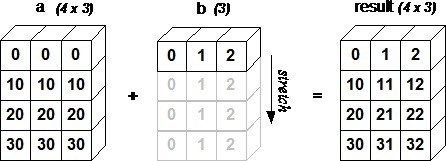
NumPy - 数组上的迭代
NumPy 包包含一个迭代器对象 numpy.nditer。 它是一个有效的多维迭代器对象,可以用于在数组上进行迭代。 数组的每个元素可使用 Python 的标准 Iterator 接口来访问。
# 使用arange()函数创建一个 3X4 数组,并使用 nditer 对它进行迭代。
a = np.arange(0,60,5)
a = a.reshape(3,4)
print('原始数组是:')
print(a)
print('\n')
print('修改后的数组是:')
for x in np.nditer(a):
print(x,)
# 迭代的顺序匹配数组的内容布局,而不考虑特定的排序。 这可以通过迭代上述数组的转置来看到。
a = np.arange(0,60,5)
a = a.reshape(3,4)
print('原始数组是:')
print(a)
print('\n')
print('原始数组的转置是:')
b = a.T
print(b)
print('\n')
print('修改后的数组是:')
for x in np.nditer(b):
print(x,)
# 如果相同元素使用 F 风格顺序存储,则迭代器选择以更有效的方式对数组进行迭代。
a = np.arange(0,60,5)
a = a.reshape(3,4)
print('原始数组是:')
print(a)
print('\n')
print('原始数组的转置是:')
b = a.T
print(b)
print('\n')
print('以 C 风格顺序排序:')
c = b.copy(order='C')
print(c)
for x in np.nditer(c):
print(x,)
print('\n')
print('以 F 风格顺序排序:')
c = b.copy(order='F')
print(c)
for x in np.nditer(c):
print(x,)
# 可以通过显式提醒,来强制 nditer 对象使用某种顺序:
a = np.arange(0, 60, 5)
a = a.reshape(3, 4)
print('原始数组是:')
print(a)
print('\n')
print('以 C 风格顺序排序:')
for x in np.nditer(a, order = 'C'):
print(x,)
print('\n')
print('以 F 风格顺序排序:')
for x in np.nditer(a, order = 'F'):
print(x,)修改数组的值
nditer 对象有另一个可选参数 op_flags。 其默认值为只读,但可以设置为读写或只写模式。 这将允许使用此迭代器修改数组元素。
a = np.arange(0,60,5)
a = a.reshape(3,4)
print('原始数组是:')
print(a)
print('\n')
for x in np.nditer(a, op_flags=['readwrite']):
x[...]=2*x
print('修改后的数组是:')
print(a)外部循环
nditer类的构造器拥有flags参数,它可以接受下列值:
| 序号 | 参数及描述 |
|---|---|
| 1. | c_index 可以跟踪 C 顺序的索引 |
| 2. | f_index 可以跟踪 Fortran 顺序的索引 |
| 3. | multi-index 每次迭代可以跟踪一种索引类型 |
| 4. | external_loop 给出的值时具有多个值的一维数组 |
a = np.arange(0,60,5)
a = a.reshape(3,4)
print('原始数组是:')
print(a)
print('\n')
print('修改后的数组是:')
for x in np.nditer(a, flags = ['external_loop'], order = 'F'):
print(x,)广播迭代
如果两个数组是可广播的,nditer 组合对象能够同时迭代它们。 假设数组 a 具有维度 3X4,并且存在维度为 1X4 的另一个数组 b,则使用以下类型的迭代器(数组 b 被广播到 a 的大小)。
a = np.arange(0, 60, 5)
a = a.reshape(3, 4)
print('第一个数组:')
print(a)
print('\n')
print('第二个数组:')
b = np.array([1, 2, 3, 4], dtype = int)
print(b)
print('\n')
print('修改后的数组是:')
for x,y in np.nditer([a, b]):
print("%d:%d" % (x, y),)NumPy - 数组操作
numpy.reshapenumpy.ndarray.flatnumpy.ravelnumpy.transpose(arr, axes)numpy.ndarray.Tnumpy.rollaxisnumpy.swapaxesnp.broadcastnumpy.broadcast_tonumpy.expand_dimsnumpy.squeezenumpy.concatenatenumpy.stack(arrays, axis)numpy.hstacknumpy.vstacknumpy.splitnumpy.hsplitnumpy.vsplit
添加/删除元素
| 序号 | 元素及描述 |
|---|---|
| 1. | resize返回指定形状的新数组 |
| 2. | append将值添加到数组末尾 |
| 3. | insert沿指定轴将值插入到指定下表之前 |
| 4. | delet返回删掉某个轴的子数组的新数组 |
| 5. | unique寻找数组内的唯一元素 |
numpy.resize(arr, shape)numpy.append(arr, values, axis)numpy.insert(arr, obj, values, axis)Numpy.delete(arr, obj, axis)numpy.unique(arr, return_index, return_inverse, return_counts)NumPy - 位操作
| 序号 | 元素及描述 |
|---|---|
| 1. | bitwise_and对数组元素执行位与操作 |
| 2. | bitwise_or对数组元素执行位或操作 |
| 3. | invert计算位非 |
| 4. | left_shift向左移动二进制表示的位 |
| 5. | right_shift向右移动二进制表示的位 |
np.bitwise_and()np.bitwise_or()np.invert()np.left_shift()np.right_shift()
NumPy - 字符串函数
用于对 dtype 为 numpy.string_ 或 numpy.unicode_ 的数组执行向量化字符串操作。 它们基于 Python 内置库中的标准字符串函数。
| 序号 | 函数及描述 |
|---|---|
| 1. | add() 返回两个 str 或 Unicode 数组的逐个字符串连接 |
| 2. | multiply() 返回按元素多重连接后的字符串 |
| 3. | center() 返回给定字符串的副本,其中元素位于特定字符串的中央 |
| 4. | capitalize() 返回给定字符串的副本,其中只有一个字符串大写 |
| 5. | title() 返回字符串或 Unicode 的按元素标题转换版本 |
| 6. | lower() 返回一个数组,其元素转换为小写 |
| 7. | upper() 返回一个数组,其元素转换为大写 |
| 8. | split() 返回字符串中的单词列表,并使用分隔符来分割 |
| 9. | splitlines 返回元素中的行列表,以换行符分割 |
| 10. | strip 返回数组副本,其中元素移除了开头或者结尾处的特定字符 |
| 11. | join() 返回一个字符串,它是序列中字符串的连接 |
| 12. | replace() 返回字符串的副本,其中所有子字符串的出现位置都被新字符串取代 |
| 13. | decode() 按元素调用 str.decode |
| 14. | encode() 按元素调用 str.encode |
这些函数在字符数组类(numpy.char)中定义。 较旧的 Numarray 包包含chararray类。 numpy.char类中的上述函数在执行向量化字符串操作时非常有用。
NumPy - 算数函数
很容易理解的是,NumPy 包含大量的各种数学运算功能。 NumPy 提供标准的三角函数,算术运算的函数,复数处理函数等。
np.sinnp.cosnp.tannp.arcsinnp.arccosnp.arctan
arcsin,arccos,和arctan函数返回给定角度的sin,cos和tan的反三角函数。 这些函数的结果可以通过numpy.degrees()函数通过将弧度制转换为角度制来验证。
numpy.around(a,decimals)四舍五入numpy.floor()此函数返回不大于输入参数的最大整数。 即标量x 的下限是最大的整数i ,使得 i <= x。 注意在 Python 中,向下取整总是从 0 舍入。numpy.ceil()ceil()函数返回输入值的上限,即,标量x的上限是最小的整数i ,使得 i >= x。
NumPy - 算数运算
用于执行算术运算(如add(),subtract(),multiply()和divide())的输入数组必须具有相同的形状或符合数组广播规则。
numpy.reciprocal()此函数返回参数逐元素的倒数,。 由于 Python 处理整数除法的方式,对于绝对值大于 1 的整数元素,结果始终为 0, 对于整数 0,则发出溢出警告。numpy.power()此函数将第一个输入数组中的元素作为底数,计算它与第二个输入数组中相应元素的幂。numpy.mod()此函数返回输入数组中相应元素的除法余数。 函数numpy.remainder()也产生相同的结果。numpy.real()返回复数类型参数的实部。numpy.imag()返回复数类型参数的虚部。numpy.conj()返回通过改变虚部的符号而获得的共轭复数。numpy.angle()返回复数参数的角度。 函数的参数是degree。 如果为true,返回的角度以角度制来表示,否则为以弧度制来表示
NumPy - 统计函数
numpy.amin()numpy.amax()numpy.ptp()numpy.percentile()numpy.median()numpy.mean()numpy.average()
标准差
std = sqrt(mean((x - x.mean())**2))np.std([1,2,3,4])方差
mean((x - x.mean())** 2)np.var([1,2,3,4])NumPy - 排序、搜索和计数函数
NumPy中提供了各种排序相关功能。 这些排序函数实现不同的排序算法,每个排序算法的特征在于执行速度,最坏情况性能,所需的工作空间和算法的稳定性。 下表显示了三种排序算法的比较。
| 种类 | 速度 | 最坏情况 |
工作空间 | 稳定性 |
|---|---|---|---|---|
quicksort(快速排序) |
1 | $O(n^2)$ | 0 | 否 |
mergesort(归并排序) |
2 | $O(n\log(n))$ | ~n/2 | 是 |
heapsort(堆排序) |
3 | $O(n\log(n))$ | 0 | 否 |
numpy.sort()numpy.sort(a, axis, kind, order)
| 序号 | 参数及描述 |
|---|---|
| 1. | a 要排序的数组 |
| 2. | axis 沿着它排序数组的轴,如果没有数组会被展开,沿着最后的轴排序 |
| 3. | kind 默认为 quicksort 返(快速排序) |
| 4. | order 如果数组包含字段,则是要排序的字段 |
numpy.argsort()对输入数组沿给定轴执行间接排序,并使用指定排序类型返回数据的索引数组。 这个索引数组用于构造排序后的数组。numpy.lexsort()使用键序列执行间接排序。 键可以看作是电子表格中的一列。 该函数返回一个索引数组,使用它可以获得排序数据。 注意,最后一个键恰好是 sort 的主键。numpy.nonzero()返回输入数组中非零元素的索引。numpy.where()返回输入数组中满足给定条件的元素的索引。
NumPy 模块有一些用于在数组内搜索的函数。 提供了用于找到最大值,最小值以及满足给定条件的元素的函数。
a = np.array([[30,40,70],[80,20,10],[50,90,60]])
print('我们的数组是:')
print(a)
print('\n')
print('调用 argmax() 函数:')
print(np.argmax(a))
print('\n')
print('展开数组:')
print(a.flatten())
print('\n')
print('沿轴 0 的最大值索引:')
maxindex = np.argmax(a, axis = 0)
print(maxindex)
print('\n')
print('沿轴 1 的最大值索引:')
maxindex = np.argmax(a, axis = 1)
print(maxindex)
print('\n')
print('调用 argmin() 函数:')
minindex = np.argmin(a)
print(minindex)
print('\n')
print('展开数组中的最小值:')
print(a.flatten()[minindex])
print('\n')
print('沿轴 0 的最小值索引:')
minindex = np.argmin(a, axis = 0)
print(minindex)
print('\n')
print('沿轴 1 的最小值索引:')
minindex = np.argmin(a, axis = 1)
print(minindex)NumPy - 字节交换
存储在计算机内存中的数据取决于 CPU 使用的架构。 它可以是小端(最小有效位存储在最小地址中)或大端(最小有效字节存储在最大地址中)。
numpy.ndarray.byteswap()
NumPy - 副本和视图
在执行函数时,其中一些返回输入数组的副本,而另一些返回视图。 当内容物理存储在另一个位置时,称为副本。 另一方面,如果提供了相同内存内容的不同视图,我们将其称为视图。
无复制
简单的赋值不会创建数组对象的副本。 相反,它使用原始数组的相同id()来访问它。 id()返回 Python 对象的通用标识符,类似于 C 中的指针。
此外,一个数组的任何变化都反映在另一个数组上。 例如,一个数组的形状改变也会改变另一个数组的形状。
视图或浅复制
ndarray.view()是一个新的数组对象,并可查看原始数组的相同数据。 与前一种情况不同,新数组的维数更改不会更改原始数据的维数。
深复制
ndarray.copy()
NumPy - 矩阵库
NumPy 包包含一个 Matrix库numpy.matlib。此模块的函数返回矩阵而不是返回ndarray对象。matlib.empty()函数返回一个新的矩阵,而不初始化元素。
numpy.matlib.empty(shape, dtype, order)| 序号 | 参数及描述 |
|---|---|
| 1. | shape 定义新矩阵形状的整数或整数元祖 |
| 2. | Dtype 可选,输出的数据类型 |
| 3. | oder C 或者 F |
numpy.matlib.zeros()numpy.matlib.ones()numpy.matlib.eye()numpy.matlib.eye(n, M,k, dtype)
| 序号 | 参数及描述 |
|---|---|
| 1. | n 返回矩阵的行数 |
| 2. | M 返回矩阵的列数,默认为 n |
| 3. | k 对角线的索引 |
| 4. | dtype 输出的数据类型 |
numpy.matlib.identity()返回给定大小的单位矩阵。单位矩阵是主对角线元素都为 1 的方阵。numpy.matlib.rand()函数返回给定大小的填充随机值的矩阵。
注意,矩阵总是二维的,而ndarray是一个 n 维数组。 两个对象都是可互换的。
NumPy - 线性代数
NumPy 包包含numpy.linalg模块,提供线性代数所需的所有功能。 此模块中的一些重要功能如下表所述。
| 函数 | 描述 |
|---|---|
dot |
两个数组的点积 |
vdot |
两个向量的点积 |
inner |
两个数组的内积 |
matmul |
两个数组的矩阵积 |
determinant |
数组的行列式 |
solve |
求解线性矩阵方差 |
inv |
寻找矩阵的乘法逆矩阵 |
numpy.dot()numpy.vdot()numpy.inner()numpy.matmul()numpy.linalg.det()计算矩阵的行列式numpy.linalg.solve()给出矩阵形式的线性方程的解numpy.linalg.inv()计算矩阵的逆
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



