
swoole 的认识和强大之处
13 / 1 / 创建于 5年前 /
 huxiaobai_001 的个人博客
huxiaobai_001 的个人博客
技术的学习均来自 “程序员在囧途” 网址:www.jtthink.com
首先swoole是php的一个扩展程序
swoole是一个为php用c和c++编写的基于事件的高性能异步&协程并行网络通信引擎
swoole是一个多进程模型的框架,当启动一个进程swoole应用时,一共会创建2+n+m个进程,n为worker进程数,m为TaskWorker进程数,1个master进程和一个manager进程,关系如下图所示
Master进程为主进程,该进程会创建Manager进程、Reactor线程等工作进/线程
- Reactor线程:
- 负责维护客户端
TCP连接、处理网络IO、处理协议、收发数据- 完全是异步非阻塞的模式
- 全部为
C代码,除Start/Shudown事件回调外,不执行任何PHP代码- 将
TCP客户端发来的数据缓冲、拼接、拆分成完整的一个请求数据包Reactor以多线程的方式运行
- Worker进程:
- 接受由
Reactor线程投递的请求数据包,并执行PHP回调函数处理数据- 生成响应数据并发给
Reactor线程,由Reactor线程发送给TCP客户端- 可以是异步非阻塞模式,也可以是同步阻塞模式
Worker以多进程的方式运行
- TaskWorker进程 :
- 接受由
Worker进程通过swoole_server->task/taskwait方法投递的任务- 处理任务,并将结果数据返回(使用
swoole_server->finish)给Worker进程- 完全是同步阻塞模式
TaskWorker以多进程的方式运行

A:网络通信引擎
网络通信引擎,是为php提供网络通信能力的,传统的php程序都是启动php-fpm,前边再有一层nginx或者apache,打开浏览器访问就OK,但是从浏览器访问到服务器这一阶段涉及到了网络强求,但是这一阶段跟php脚本没有任何的关系,php只需要处理好数据生成需要展示的内容就完成使命了,声明周期当中,请求到来前和请求完成后都没有php脚本什么事,而swoole提供的一大能力就是扩展了php的生命周期,无需php-fpm或者nginx或者apache之类的工具帮助就可以启动一个web服务,并且从服务启动前,启动后,链接进入,请求到来,请求结束,链接切断,服务终止都在php脚本的掌控之中,这样的话php脚本就会涉及到大量的网络通讯处理,而这个网络通讯处理的能力正是来源于swoole! 网络通信引擎,是为php提供网络通信能力的,传统的php程序都是启动php-fpm,前边再有一层nginx或者apache,打开浏览器访问就OK,但是从浏览器访问到服务器这一阶段涉及到了网络强求,但是这一阶段跟php脚本没有任何的关系,php只需要处理好数据生成需要展示的内容就完成使命了,声明周期当中,请求到来前和请求完成后都没有php脚本什么事,而swoole提供的一大能力就是扩展了php的生命周期,无需php-fpm或者nginx或者apache之类的工具帮助就可以启动一个web服务,并且从服务启动前,启动后,链接进入,请求到来,请求结束,链接切断,服务终止都在php脚本的掌控之中,这样的话php脚本就会涉及到大量的网络通讯处理,而这个网络通讯处理的能力正是来源于swoole!
B:基于事件的高性能异步
同步:
就拿读取文件内容来说吧
file_get_contents()执行完才能执行下边的代码 这样就很容易造成程序的阻塞
否则下边的代码就无法输出文件的内容
传统php都是这样阻塞式的顺序执行的
这是常见的同步编程
异步:
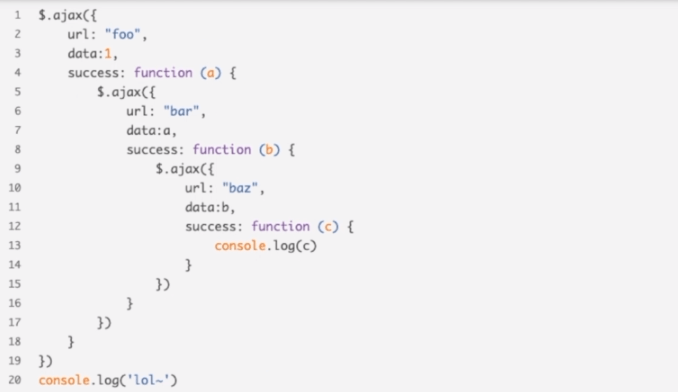
代码在执行到ajax的时候,函数会直接返回,你马上就可以看到屏幕上打印出的lol
这就是异步,这样你永远不会被IO阻塞,但是它带来了新的问题,在你运行到lol之后你就不知道现在代码运行到哪里去了,你只能等待回调被触发,然后屏幕上打印响应的log,它的执行不是单层顺序的,而是嵌套的
如果在业务代码当中 这样层层嵌套可读性可想而知
当然这是前端异步请求后端接口swoole当中处理异步回调嵌套使用的是协程
你知道什么叫协程吗?你知道线程是干啥的吗?你又知道进程吗?
如果想深入了解swoole的强大之处 你还得要了解传统php的lnmp环境的整套运行机制,这些你都了解吗?
如果不了解不要紧 兄嘚 看看我的另一篇博客吧:
swoole 当中协程的理解包括(进程、线程的讲解)
讲解的也未必清晰,不懂的话自己多去百度!
目前swoole当中的异步也是协程化的,所以你必须充分理解协程到底是个什么东西!

C:协程
到底什么是协程?
通俗的说,协程就是一段段协作方式执行的程序,协作来完成一件事,协作就是协同作业。我们知道团队协同来做事,比个人单独来做事,效率肯定要高,因为团队协同可以发挥各成员的能动性、优势互补。这是拿人来比喻。我们拿做事来比喻举个例子:比如我们做饭,比如有以下环节洗菜、切菜、烧水、炒菜、煮米饭,人作为主体来操作,那么如果按部就班的做,先烧水,再洗菜,在切菜,再炒菜,再煮饭,那这顿饭要做很长时间比如总共30分钟吧,如果我们通过协同方式,先烧水,放灶火上就可以做其他洗菜、切菜的准备,再煮米饭,然后再来洗菜、切菜,再查看煮米饭,再炒菜,…,如此循环往复切换,最后水烧好,米饭也煮好了,菜也炒好了,饭也OK了,这样我们耗时可能只有10-15分钟,看到了吗,这就是生活中的“协程”,由人来合理调度安排不同的环节,充分利用各种不同的资源和时间,来达到提高效率。协程是计算机程序,调用的则是不同的程序,处理者主要由CPU完成,处理对象是各种IO资源,处理的方式是不同的语言编写的程序。我们知道,CPU可以调度不同的程序,让程序调用不同的IO资源,最初的进程是通过CPU频繁的切换来完成调用程序的,是操作系统按一定算法分配的时间片抢占被动方式来切换的,未考虑程序实际执行状况,这样切换程序会带来一定问题,而协程作为一种新的工作模式,可以让程序协作方式来执行,在需要使用CPU时,交给程序处理,遇到耗时的IO资源操作时会让出CPU,交给处理其他程序,这样互相协作来执行,而不是抢占式的,就像交通规则,大家都遵守按一定规则礼让先行,不随便抢道,协同方式,程序都会执行的良好。
我们来看具体的案例:go(function () { echo "hello go1 \n"; }); echo "hello main \n"; go(function () { echo "hello go2 \n"; });上面的代码执行结果:
root@b98940b00a9b /v/w/c/p/swoole# php co.php hello go1 hello main hello go2执行结果和我们平时写代码的顺序, 好像没啥区别. 实际执行过程:
- 运行此段代码, 系统启动一个新进程
- 遇到
go(), 当前进程中生成一个协程, 协程中输出heelo go1, 协程退出- 进程继续向下执行代码, 输出
hello main- 再生成一个协程, 协程中输出
heelo go2, 协程退出
我们来稍微改一改, 体验协程的调度:\Co::sleep() 函数功能和 sleep() 差不多, 但是它模拟的是 IO等待(IO后面会细讲). 执行的结果如下:use Co; go(function () { Co::sleep(1); // 只新增了一行代码 echo "hello go1 \n"; }); echo "hello main \n"; go(function () { echo "hello go2 \n"; });怎么不是顺序执行的呢? 实际执行过程:root@b98940b00a9b /v/w/c/p/swoole# php co.php hello main hello go2 hello go1- 运行此段代码, 系统启动一个新进程
- 遇到
go(), 当前进程中生成一个协程- 协程中遇到 IO阻塞 (这里是
Co::sleep()模拟出的 IO等待), 协程让出控制, 进入协程调度队列- 进程继续向下执行, 输出
hello main- 执行下一个协程, 输出
hello go2- 之前的协程准备就绪, 继续执行, 输出
hello go1
到这里, 已经可以看到 swoole 中 协程与进程的关系, 以及 协程的调度, 我们再改一改刚才的程序我想你已经知道输出是什么样子了:go(function () { Co::sleep(1); echo "hello go1 \n"; }); echo "hello main \n"; go(function () { Co::sleep(1); echo "hello go2 \n"; });协程快在哪? 减少IO阻塞导致的性能损失root@b98940b00a9b /v/w/c/p/swoole# php co.php hello main hello go1 hello go2
大家可能听到使用协程的最多的理由, 可能就是 协程快. 那看起来和平时写得差不多的代码, 为什么就要快一些呢? 一个常见的理由是, 可以创建很多个协程来执行任务, 所以快. 这种说法是对的, 不过还停留在表面
首先, 一般的计算机任务分为 2 种- CPU密集型, 比如加减乘除等科学计算
- IO 密集型, 比如网络请求, 文件读写等
其次, 高性能相关的 2 个概念- 并行: 同一个时刻, 同一个 CPU 只能执行同一个任务, 要同时执行多个任务, 就需要有多个 CPU 才行
- 并发: 由于 CPU 切换任务非常快, 快到人类可以感知的极限, 就会有很多任务 同时执行 的错觉
了解了这些, 我们再来看协程, 协程适合的是 IO 密集型 应用, 因为协程在 IO阻塞 时会自动调度, 减少IO阻塞导致的时间损失!
更多案例请参考:www.jianshu.com/p/745b0b3ffae7
协程在遇到IO阻塞的时候会让出cpu的控制权,其他协程拿到去执行其他协程的任务,当IO阻塞过去之后回过头来继续往下执行!
要点:1.协程在阻塞的时候只是阻塞了当前这个协程 并不会阻塞整个的进程 因为协程是在线程内部的,即使阻塞了也会让出控制权,挂起,等待当前协程的IO不阻塞在回过头来继续执行,也就是同步的代码完成了异步的功能!相当强悍!
2.从宏观的角度看,程序员搞出来的多个协程在不发生任何协程阻塞的前提是是顺序执行的 一旦发生阻塞 你可以把多个协程理解为并行的 同时在执行的!
3.协程是在单进程单线程当中实现的 你可以在里面实现成千上万的协程 并且效果极高! 每个协程去干不同的事!协作制的无需加锁没有抢占,串行的!什么叫串行呢?每次执行一个协程 遇到IO阻塞 挂起 执行接下来的程序 可能还是个协程 如果再遇到IO阻塞再挂起 继续往下执行 当IO阻塞完成回过头来继续往下执行没执行完的协程程序 每次都是一个协程在执行,串行化的!
4.协程之间每秒可以进行百万千万次切换! 线程之间切换需要加锁 加锁就很浪费资源!进程间切换更浪费资源,因为上线文很大!更多详细内容请自行百度!
5.协程很小切换还快 每秒百万千万级别的切换 所以 一个进程里面 只要你的内存够用 你就可以无止境的创造协程出来干事情!
6.事件驱动和异步为swoole提供了高性能 而协程解决了异步回调代码嵌套的问题 提高了代码可读性和维护性 也是swoole最大的特色!
d:混合服务器
你可以随意创建一个http tcp websocket http2服务 并且能轻松承载成千上万的请求
这个可以去官网 看如何创建http服务 tcp服务 websocket服务
websocket是http升级而来的 创建了websocket服务就自带了http服务
创建好服务 直接start就可以运行一个http服务或者其他tcp等的服务了 而无需nginx apache的任何参与!
有服务端必有客户端 我们可以在代码里面通过
new Swoole\Coroutine\Http\Client(127.0.0.1,9501);
去链接http服务器
当然其他的也一样 自己去看手册 这里只是说明swoole有多么的强大
e:协程之间通讯 channel
通道(channel)是协程之间通信交换数据的唯一渠道,而协程+通道的开发组合即为著名的csp编程模型
在swoole当中 channel常用于连接池的实现和协程并发的调度
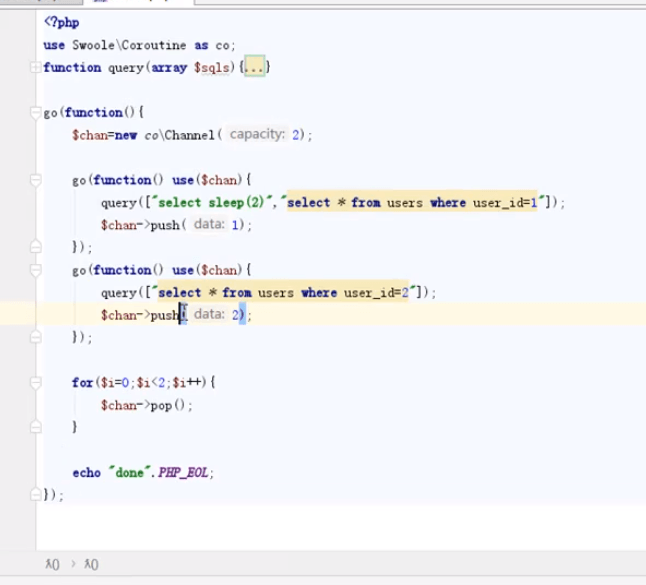
如图所示 第一个协程执行完成之后我们会往channel通道当中push一个元素 第二个也是 当然第一个一定是IO阻塞的 第二个没有 我们在for循环里面 获取channel里面的值的时候由于第一个阻塞 $chan->pop()也是阻塞的 因为整体都是在一个协程里面 只有当大的协程里面的两个小协程都完成了 这里的$chan->pop才会执行 接触阻塞 最后才会执行 echo语句! 这是swoole当中协程并发的一个很好的案例应用f:毫秒定时器
毫秒定时器是异步回调的方式来实现的!
还可以使用协程方式 采用同步阻塞的方式来实现定时器!之前用sleep会阻塞整个进程 现在你在协程里面搞 Co:sleep(0.1)阻塞的是当前协程 而不会阻塞整个进程!

本作品采用《CC 协议》,转载必须注明作者和本文链接











 关于 LearnKu
关于 LearnKu




推荐文章: