
Python 下载笔趣阁文章
0 / 2 / 创建于 6年前 /
 我叫以赏 的个人博客
我叫以赏 的个人博客
前言
本文章没有恰饭,只是提供制作思路(这个是在我来Python论坛之前的作品)
一个同学要我下载笔趣阁的文章,我便同意了,一言既出,驷马难追。我用我网站搭建了一个“设备见外”平台(类似与盗版笔趣阁),就可以做到在线搜索笔趣阁文章、在线浏览目录与阅读,而且十分简洁没有广告,

那我我就使用Python从0开始搭建吧,(注意:UP一边写文章一边写程序,工作量很大,一步一个操作)
界面
先写一个简单的交互式页面,
# -*- coding:utf-8 -*-
# 导入使用到的模块
import requests
import gzip
import os
def search():
pass
def tip(Text):
os.system('cls')
print("\n状态:" + Text + "\n")
print(
"""------------------------------------
欢迎使用Python笔趣阁采集软件
软件由 @我叫以赏 制作
主要用于下载笔趣阁的小说
程序仅供学习使用
Web:http://blog.zhangyishang.top
------------------------------------
"""
)
if __name__ == '__main__':
safeexit = False
tip("准备就绪!等待用户输入!")
while True:
try:
user = input('[1.搜索器 2.目录查看 3.文章查看 4.采集工具 5(exit).退出程序]请输入您要使用的功能代号:')
user = user.lower()
if user == "1":
pass
elif user == "2":
pass
elif user == "3":
pass
elif user == "4":
pass
elif user == "exit" or user == "5":
safeexit = True
exit(0)
else:
tip("未输入任何操作!如果您想要退出请输入 5 或 exit ,或者点击右上角的 × !")
except:
if safeexit == False:
user = input("程序遭到意外关闭!程序检测并且已经拦截!部分代码已暂停运行,正在处理的程序很可能已经遭到关闭,是否继续?[Y(1)/N(2)] :")
user = user.lower()
if user == 'y' or user == "1":
continue
else:
exit(0)
else:
exit(0)搜索器
接下来我们要制作搜索器,搜索书的内容,首先打开笔趣阁,找到搜索页面,随意输入关键字,并进行抓包

所以我们先写一个引导用户输入,之后将输入内容进行POST地址获得网页!
def search():
tip('已打开搜索文章工具,等待用户输入......')
user = input("请问您想要搜索什么呢?请输入搜索的内容:")
try:
data = {
'searchkey':user
}
page = requests.post('http://www.xbiquge.la/modules/article/waps.php',data)
print(page.text)
except:
pass
pass
先测试一下,发现输出文本乱码,将
print(page.text) 改成 print(page.content.decode(‘utf-8’))
即可。
下面为输出数据部分:

看来是表格,我们要获取两个数据,一个是网址,另一个就是名称,

def search():
tip('已打开搜索文章工具,等待用户输入......')
user = input("请问您想要搜索什么呢?请输入搜索的内容:")
try:
data = {
'searchkey':user
}
page = requests.post('http://www.xbiquge.la/modules/article/waps.php',data)
Textpage = page.content.decode('utf-8')
position = 0
while position != -1 and position != len('<td class="even"><a href="')-1:
position = Textpage.find('<td class="even"><a href="',position) + len('<td class="even"><a href="')
nameposition = Textpage.find('" target="_blank">',position)
if (position != -1 and position != len('<td class="even"><a href="')-1) == True:
href = (Textpage[position:nameposition])
nameposition = nameposition + len('" target="_blank">')
end = Textpage.find('</a>',nameposition)
name = Textpage[nameposition:end]
print(href,name)
except:
pass
pass
由于position被加上的26个字符串的长度,所以也要判断是否为不等于25。
搜索“我的世界”打印出来的结果:

接下来我们把地址全部放入列表中,方便操作。完善搜索器操作:
global book
book = []
def print_book():
global book
a = 0
tip('共有 %d 搜索结果!输出中......' % (len(book)))
for x in book:
a = a + 1
print("[%d]%s" % (a, x[1]))
def search():
global book
tip('已打开搜索文章工具,等待用户输入......')
user = input("[#print打印出之前搜索结果 #exit返回主菜单]请问您想要搜索什么呢?请输入搜索的内容(此操作将会清空之前的搜索的内容):")
user = user.lower()
user = user.strip()
if user == '#print':
print_book()
search()
return
elif user == '#exit':
return
elif user == '':
tip('您隔着原地输入?')
search()
return
try:
data = {
'searchkey': user
}
page = requests.post('http://www.xbiquge.la/modules/article/waps.php', data)
Textpage = page.content.decode('utf-8')
position = 0
book = []
tip('正在搜索图书......')
while position != -1 and position != len('<td class="even"><a href="') - 1:
position = Textpage.find('<td class="even"><a href="', position) + len('<td class="even"><a href="')
nameposition = Textpage.find('" target="_blank">', position)
if (position != -1 and position != len('<td class="even"><a href="') - 1) == True:
href = (Textpage[position:nameposition])
nameposition = nameposition + len('" target="_blank">')
end = Textpage.find('</a>', nameposition)
name = Textpage[nameposition:end]
book.append((href, name))
tip('共有 %d 搜索结果!' % (len(book)))
print_book()
except BaseException as error:
tip('搜索失败,原因:'+str(error))
search()
输出结果:

目录查看
接下来我们完善目录查看,
入口点:
while True:
user = input('输入图书编号,若按错了请输入 #exit 返回,图书编号输入 #print 查看,如果没有编号,请返回至 搜索器 搜索!输入编号(也可以是您找到的网址,此操作会使上传获取的目录结果清空):')
user = user.lower()
user = user.strip()
if user == '#exit':
break
elif user == '#print':
print_book()
continue
else:
try:
dir(user)
except:
tip('出现错误!可能是输入不正确!')
input('回车键继续[Enter]')
break
def dir(id):
global book
try:
id = int(id)
except: # 输入网址
if id.find('http') == -1:
tip('不是合适网址或id!')
return
else: # 输入数字
id = id -1
if id > len(book) or id < 0:
tip('id无效!')
input('回车键继续[Enter]')
return
Page = requests.get('http://www.xbiquge.la/36/36339/')
PageText = Page.content.decode('utf-8')
print(PageText) 分析目录页面:

也是一个列表,不过简单多了!
我们只要查找
思路都是一样的,不过最后为了方便操作,我会在地址后面加上域名!
def print_dir():
global dir
a = 0
tip('共有 %d 章!输出中......' % (len(dir)))
for x in dir:
a = a + 1
print("[%d]%s" % (a, x[1])) def dir(id):
global book
global dir
src = ""
try:
id = int(id)
except: # 输入网址
if id.find('http') == -1:
tip('不是合适网址或id!')
input('回车键继续[Enter]')
return
src = id
else: # 输入数字
id = id - 1
if id > len(book) or id < 0:
tip('id无效!')
input('回车键继续[Enter]')
return
src = book[id]
Page = requests.get('http://www.xbiquge.la/36/36339/')
PageText = Page.content.decode('utf-8')
position = 0
dir = []
while position != -1 and position != len("<dd><a href='")-1:
position = PageText.find("<dd><a href='",position) + len("<dd><a href='")
name = PageText.find("' >",position)
if position != -1 and position != len("<dd><a href='")-1:
dir.append(("http://www.xbiquge.la"+PageText[position:name],PageText[name + 3: PageText.find("</a></dd>",name)]))
print_dir()文章获取
接下我们完善获取笔趣阁文章,随便找到一篇文章并查看网页源代码:




将data.text替换成data.content.decode(‘utf-8’)正常显示



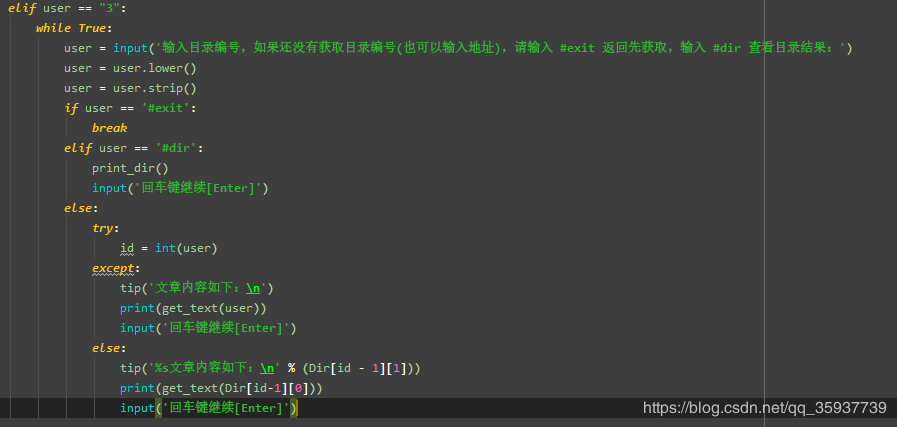
elif user == "3":
while True:
user = input('输入目录编号,如果还没有获取目录编号(也可以输入地址),请输入 #exit 返回先获取,输入 #dir 查看目录结果:')
user = user.lower()
user = user.strip()
if user == '#exit':
break
elif user == '#dir':
print_dir()
input('回车键继续[Enter]')
else:
try:
id = int(user)
except:
tip('文章内容如下:\n')
print(get_text(user))
input('回车键继续[Enter]')
else:
tip('%s文章内容如下:\n' % (Dir[id - 1][1]))
print(get_text(Dir[id-1][0]))
input('回车键继续[Enter]')
elif user == "4":
while True:
savesrc = input('(#exit退出 #dir查看文章章节)请输入保存文件名(写文件保存完整路径):')
savesrc = savesrc.lower()
savesrc = savesrc.strip()
if savesrc == '#exit':
break
elif savesrc == "#dir":
print_dir()
input('回车键继续[Enter]')
continue
else:
user = input('(#exit 退出)输入目录ID或者网址:')
try:
id = int(user)
except:
try:
fileid = open(savesrc,'w+')
fileid.write(get_text(user))
fileid.close()
except:
tip('写文件失败!原因:无效的保存路径!')
else:
tip("保存完毕!")
input('回车键继续[Enter]')
else:
try:
fileid = open(savesrc,'w+')
fileid.write(get_text(book[id][0]))
fileid.close()
except:
tip('写文件失败!原因:无效的保存路径!')
else:
tip("保存完毕!")
input('回车键继续[Enter]') 
本作品采用《CC 协议》,转载必须注明作者和本文链接







 关于 LearnKu
关于 LearnKu




下载地址:https://pan.baidu.com/s/1GS1NqJRGLtVImt-Da...
mc玩家捕捉!