
每天一个 PHP 语法六数组使用及内部结构
0 / 0 / 创建于 6年前 /
 ifelse 的个人博客
ifelse 的个人博客

说明
这里基于php7.2.5进行测试,php7之后内部结构变化应该不是太大,但与php5.X有差别。
我们今天学习PHP中的数组语法,数组在PHP中堪称万能结构,什么都能存什么都能放,非常灵活,因为PHP没有其他语言的如map、list等结构,PHParray就够了。
我们前面说变量的存储结构为zval, 值呢放在zend_value中,忘了的看这里
如何声明
$arr = [];
$arr[1] = "hello";
$arr1 = ['name' => '愤怒的鸟'];如何实现
数组的底层结构为zend_array 也叫HashTable,也就是通过对数组的key进行hash计算之后能直接获取value的地址,时间复杂度为O(1)那是很快的。
typedef struct _zend_array HashTable;
struct _zend_array {
zend_refcounted_h gc;// 引用计数
union {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar flags,
zend_uchar nApplyCount,
zend_uchar nIteratorsCount,
zend_uchar consistency)
} v;
uint32_t flags;
} u;
uint32_t nTableMask; // 中间映射计算
Bucket *arData; // 这里是真正存放数组元素的地方
uint32_t nNumUsed; // 已使用的bucket数量,可能包含已删除的元素
uint32_t nNumOfElements; // 数组中有效元素的数量
uint32_t nTableSize; // 数组的总容量
uint32_t nInternalPointer;
zend_long nNextFreeElement;// 数值索引的值
dtor_func_t pDestructor;
};
typedef struct _Bucket {
zval val; // 元素的值 实际是一个zval
zend_ulong h; /* 数组key 经过hash计算得出的值 */ /* hash value (or numeric index) */
zend_string *key; /*元素的key*/ /* string key or NULL for numerics */
} Bucket;我们知道数组的key可以是数字或者字符串,但是PHP中的数组是有序的,也就是跟插入顺序是保持一致的,那么是如何做到的。
结论:
key在存入bucket之前先通过一个中间映射表保存key的位置,先对key进行hash计算然后与数组大小值进行取模运算得出这个key在中间表的位置,然后在中间表的位置存储这个key在bucket中的位置。如图
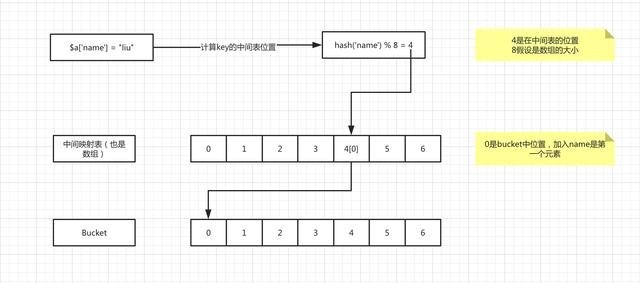
这里在key是字符串的时候需要进行hash计算,如果是数值就直接拿来用就行了。
插入元素
这个操作比较明晰了,先计算中间表的位置,再存储到bucket
add_to_hash:
// nMumUsed Bucket的数量 ++
idx = ht->nNumUsed++;
// 有效元素的数量 ++
ht->nNumOfElements++;
if (ht->nInternalPointer == HT_INVALID_IDX) {
ht->nInternalPointer = idx;
}
zend_hash_iterators_update(ht, HT_INVALID_IDX, idx);
// arData的内存位置 给当前元素用
p = ht->arData + idx;
// 设置bucket的key
p->key = key;
if (!ZSTR_IS_INTERNED(key)) {
zend_string_addref(key);
ht->u.flags &= ~HASH_FLAG_STATIC_KEYS;
zend_string_hash_val(key);
}
// 设置bucket的h值 ,这里其实是zend_string中的h
p->h = h = ZSTR_H(key);
// 设置bucket的val,
ZVAL_COPY_VALUE(&p->val, pData);
// 在bucket中的位置
nIndex = h | ht->nTableMask;
Z_NEXT(p->val) = HT_HASH(ht, nIndex);
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(idx);
return &p->val;查找元素
先自己思考一下我们在获取数组的值$a[‘name’],是如何获取的,先用key计算hash值,拿到中间表的位置,再拿到bucket的位置,就能取到值了
// 拿到key的hash值
h = zend_string_hash_val(key);
arData = ht->arData;
// 拿到中间表的位置
nIndex = h | ht->nTableMask;
// 拿到bucket的位置
idx = HT_HASH_EX(arData, nIndex);
// 这里先不看
while (EXPECTED(idx != HT_INVALID_IDX)) {
p = HT_HASH_TO_BUCKET_EX(arData, idx);
if (EXPECTED(p->key == key)) { /* check for the same interned string */
return p;
} else if (EXPECTED(p->h == h) &&
EXPECTED(p->key) &&
EXPECTED(ZSTR_LEN(p->key) == ZSTR_LEN(key)) &&
EXPECTED(memcmp(ZSTR_VAL(p->key), ZSTR_VAL(key), ZSTR_LEN(key)) == 0)) {
return p;
}
idx = Z_NEXT(p->val);
}hash冲突
hash计算不可避免的在数据量大的时候有冲突的几率,一般一个常用方法是拉链法,也就是冲突元素串成链表,当keyhash冲突后遍历这个位置的链表,最终拿到匹配的key, 也就是上面的查找元素中while那一段,来看下PHP hashTable是如何处理的,我们还是分析上面那一段代码
add_to_hash:
// nMumUsed Bucket的数量 ++
idx = ht->nNumUsed++;
// 有效元素的数量 ++
ht->nNumOfElements++;
if (ht->nInternalPointer == HT_INVALID_IDX) {
ht->nInternalPointer = idx;
}
zend_hash_iterators_update(ht, HT_INVALID_IDX, idx);
// arData的内存位置 给当前元素用
p = ht->arData + idx;
// 设置bucket的key
p->key = key;
if (!ZSTR_IS_INTERNED(key)) {
zend_string_addref(key);
ht->u.flags &= ~HASH_FLAG_STATIC_KEYS;
zend_string_hash_val(key);
}
// 设置bucket的h值 ,这里其实是zend_string中的h
p->h = h = ZSTR_H(key);
// 设置bucket的val,
ZVAL_COPY_VALUE(&p->val, pData);
// 在bucket中的位置
nIndex = h | ht->nTableMask;
// 这一步,把 bucket当前位置nIndex的元素,设置为新值的next
// 也就是 ht[idx] = p->newval , p->nexal -> next -> p->oldval
Z_NEXT(p->val) = HT_HASH(ht, nIndex);
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(idx);
return &p->val;
// 这里是 zval.u2.next 下一个元素,忘了的看zval结构
#define Z_NEXT(zval) (zval).u2.next
// 这里就是取到 data[idx]的元素
#define HT_HASH_EX(data, idx)
((uint32_t*)(data))[(int32_t)(idx)]
#define HT_HASH(ht, idx)
HT_HASH_EX((ht)->arData, idx)上图
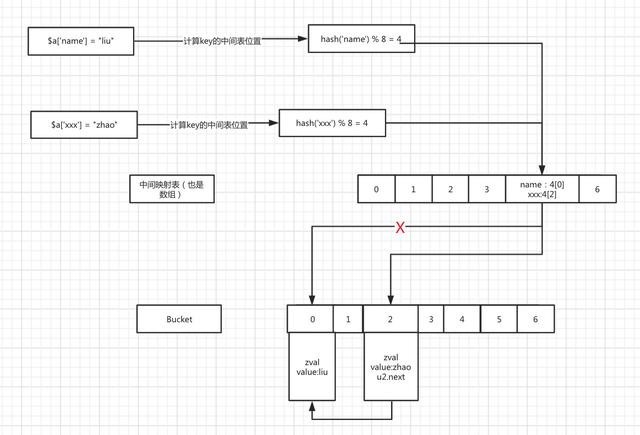
扩容
PHP数组在初始化时不需要指定容量大小,也就是它是自动扩容的,如何实现呢。
结论:
如果插入元素时发现容量不够了,如果已删除的元素达到一定比例就重建索引,如果没有达到就会进行原大小2倍的扩容,然后复制元素到新数组。
IS_CONSISTENT(ht);
HT_ASSERT_RC1(ht);
// 是否达到了这个值
if (ht->nNumUsed > ht->nNumOfElements + (ht->nNumOfElements >> 5)) { /* additional term is there to amortize the cost of compaction */
zend_hash_rehash(ht);
} else if (ht->nTableSize < HT_MAX_SIZE) { /* Let's double the table size */
// 这里会扩容2倍
void *new_data, *old_data = HT_GET_DATA_ADDR(ht);
// 2倍
uint32_t nSize = ht->nTableSize + ht->nTableSize;
Bucket *old_buckets = ht->arData;
// 申请内存
new_data = pemalloc(HT_SIZE_EX(nSize, -nSize), ht->u.flags & HASH_FLAG_PERSISTENT);
// 设置一些属性
ht->nTableSize = nSize;
ht->nTableMask = -ht->nTableSize;
HT_SET_DATA_ADDR(ht, new_data);
// 复制buckets
memcpy(ht->arData, old_buckets, sizeof(Bucket) * ht->nNumUsed);
// 删除老bucket
pefree(old_data, ht->u.flags & HASH_FLAG_PERSISTENT);
zend_hash_rehash(ht);
} else {
zend_error_noreturn(E_ERROR, "Possible integer overflow in memory allocation (%u * %zu + %zu)", ht->nTableSize * 2, sizeof(Bucket) + sizeof(uint32_t), sizeof(Bucket));
}总结
PHP数组底层是hashTable, 通过一个中间映射表实现顺序性,自动扩容,value可以任何类型,key可以是int也可以是string
参考资料:
《PHP内核剖析》
本作品采用《CC 协议》,转载必须注明作者和本文链接







 关于 LearnKu
关于 LearnKu




推荐文章: