
Go 的引用类型
4 / 5 / 创建于 6年前 /
 Runtoweb3 的个人博客
Runtoweb3 的个人博客
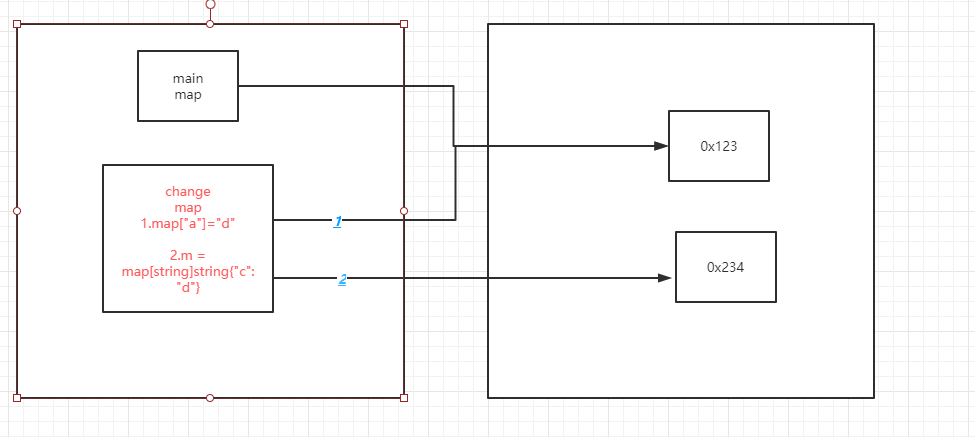
废话不多说,先看一段简化的代码
func main() {
m := make(map[int]int)
m[1]=1
change(m)
fmt.Println(m)
}
func change(m map[int]int){
m[1] = 100
}最终打印出来的结果
E:\go\projectOne\blog>go run main.go
map[1:100]虽然我们传递的是一个map变量给函数处理,打印出来后发现m已经被函数修改。类似于引用传递的效果。
这是由于Go的引用数据类型的结果
值类型
基本数据类型,int,float,bool,string,以及数组和struct 特点:变量直接存储值,内存通常在栈中分配,栈在函数调用完会被释放
type User struct {
Age int
}
func main() {
var user User
user.Age = 11
change(user)
fmt.Println(user) //{11}
}
func change(user User){ //值拷贝
user.Age = 100
}引用类型
变量存储的是一个地址,这个地址存储最终的值。内存通常在 堆上分配。通过GC回收。
引用类型: 指针、slice切片、管道channel、接口interface、map、函数等
func main() {
m := make(map[int]int)
m[1]=1
change(m)
fmt.Println(m) //map[1:100]
}
func change(m map[int]int){ //也是值拷贝,只是拷贝的是地址,相当于引用处理
m[1] = 100
}本作品采用《CC 协议》,转载必须注明作者和本文链接










 关于 LearnKu
关于 LearnKu




推荐文章: