
语音技术——关键词搜索
0 / 0 / 创建于 5年前 /
 Galois 的个人博客
Galois 的个人博客
说明
此任务的目的是构建和研究最简单形式的关键字搜索(KWS)系统,该系统可在大量语音数据中查找信息。
下图显示了一个典型的 KWS 系统的示例,该系统由索引和搜索模块组成。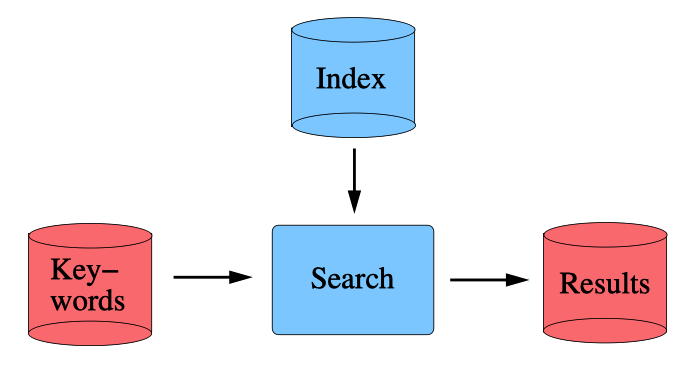
该索引提供语音数据的紧凑表示。给定一组关键字,搜索模块查询索引以检索根据可能性排序的所有可能出现。评估 KWS 的质量取决于其可以准确检索所有实际出现的关键字的准确性。已经提出并检查了 KWS 的许多索引表示形式。最受欢迎的表示形式是从自动语音识别(ASR)系统的输出中得出的。研究了各种形式的输出。关于语音数据内容的保留信息量有所不同,最简单的形式是最可能的单词序列或 1-best。还可以为每个单词提供其他信息,例如开始和结束时间以及识别置信度。给定 1-best 的集合,可以构建以下索引:
w_1\ (f_{1,1},s_{1,1},e_{1,1})\ \cdots\ (f_{1,n_1},s_{1,n_1},,e_{1,n_1})\\{}\\ w_2\ (f_{2,1},s_{2,1},e_{2,1})\ \cdots\ (f_{2,n_2},s_{2,n_2},e_{2,n_2})\\{}\\ \cdots\\{}\\ w_N\ (f_{N,1},s_{N,1},e_{N,1})\ \cdots\ (f_{N,n_N},s_{N,n_N},e_{N,n_N})\\{}\\
其中 wi 是一个词,ni 是单词 wi 出现的次数,fi,j 是单词 wi 第 j 次出现的文件名,si,j 和 ei,j 是开始时间和结束时间。在这样的索引中搜索单个单词的关键字可以很简单,就像固定正确的行(例如 k)并返回所有可能的元组 (fk,1,sk,1,ek,1),…,(fk,nk,sk,nk,ek,nk)。
预计搜索模块将检索所有可能的关键字出现。如果 ASR 没有出错,那么可以很简单地创建这样的模块。为了解决可能的检索错误,搜索模块为每个潜在的事件提供相关性得分。相关性分数反映了对给定事件相关性的置信度。关联得分极低的事件可能会被淘汰。如果这些分数准确无误则淘汰的发生将减少错误警报的数量。如果不是这样,那么错过的次数将会增加。分数极低可能不是很容易确定。多个因素可能会影响相关性得分:置信度得分,持续时间,单词混淆性,单词上下文,关键字长度。因此,简单的相关性分数(例如基于置信度分数的相关性分数)可能具有较大的动态范围,并且在不同的关键字之间可能无法比拟。为了确保相关性得分在不同关键字之间具有可比性,需要对其进行「校准」。
一种简单的校准方案称为 sum-to-one(STO)归一化,
\displaystyle \hat{r}_{i,j}=\frac{r_{i,j}^\gamma}{\sum_{k=1}^{n_i}r_{i,j}^\gamma}
其中 ri,j 是第 i 个关键字的第 j 次出现的原始相关性得分,γ 是可以使相关度得分的分布变尖或变平的标度。更复杂的方案也已经过审查。给定一组具有相关性相关分数的事件,可以使用几种选项来消除虚假事件。一种流行的方法是阈值化。给定全局或关键字特定阈排除任何下限发生的情况。简单的校准方案(例如 STO)要求在开发集上估算阈值并调整为不同的集合大小。诸如关键字特定阈值(KST)之类的更复杂的方法会在不同的关键字和集合大小之间产生一个固定的阈值。
KWS 系统的准确性可以通过多种方式进行评估。标准方法包括精度(所有检索到的事件中相关检索到的事件所占比例)和召回率(所有相关事件中的相关检索到的事件所占比例),平均平均精度和语音单元加权值。为不同阈值计算的精度和召回值的集合会产生精度召回(PR)曲线。PR 曲线下的面积(AUC)提供了独立于阈值的汇总统计量,用于比较不同的检索方法。这意味着平均精度(mAP)是另一种流行的,与阈值无关的基于精度的指标。考虑一个 KWS 系统,根据相关性得分返回3个正确和4个不正确的事件,如下所示:True, False, False, True, True, False, False,其中 True 代表正确的发生,False 代表错误的发生,每个等级(从 1 到 7)的平均精度为:\frac{1}{1},\frac{0}{2},\frac{0}{3},\frac{2}{4},\frac{4}{5},\frac{0}{6},\frac{0}{7}。这意味着这个关键词的平均精度是 0.7。可以通过平均关键字特定的 mAPs 来计算集合级别的 mAP。一旦 KWS 系统在合理的 AUC 或 mAP 水平下运行,就有可能使用项加权值(TWV)来评估阈值的准确性。
TWV 定义:
\displaystyle \mathrm{TWV}(\mathcal{K},\theta)=1-\left(\frac{1}{|\mathcal{K}|}\sum_{k\in\mathcal{K}}P_{miss}(k,\theta)+\beta P_{fa}(k,\theta)\right)
其中 k∈K 是关键字,Pmiss 和 Pfa 是未命中和错误警报的概率,β 是分配给虚假警报的惩罚。
任务
给定一个集合 1-best,编写代码以检索所有可能出现的关键字列表。描述搜索过程,包括索引格式,处理多字关键字,匹配标准,相关性分数校准和阈值设置方法。根据 β=20,根据 AUC,mAP 和 TWV 标准使用参考转录评估检索性能。评论这些标准之间的差异,包括参数 β 的影响。假设事件的开始和结束时间必须在真实事件的 0.5 秒以内,才能进行匹配。
资源
该任务提供了三种资源:1-best 在 NIST CTM 文件格式的副本(dev.ctm,eval.ctm)。CTM文件格式包括以下形式的多个记录:
<F> <H> <T> <D> <W> <C>其中 <F> 是音频文件名称,<H> 是频道,<T> 是开始时间,以秒为单位,<D> 是持续时间,以秒为单位,<W>是词,<C> 是置信度分数。每条记录对应一个识别的单词。任何空行或以 ;; 开头的行被忽略。CTM 文件的摘录如下所示:
7654 A 11.34 0.2 YES 0.5
7654 A 12.00 0.34 YOU 0.7
7654 A 13.30 0.5 CAN 0.1参考副本采用 NIST STM 文件格式(dev.stm,eval.stm)。STM 文件格式包含以下格式的多个记录:
<F> <H> <S> <T> <E> <L> <W>...<W>其中 <S> 是发言人,<E> 是结束时间,<L> 主题,<W> ... <W> 是单词序列。每条记录对应一个手动转录的音频文件片段。STM 文件的摘录如下所示:
2345 A 2345-a 0.10 2.03 <soap> uh huh yes i thought
2345 A 2345-b 2.10 3.04 <soap> dog walking is a very
2345 A 2345-a 3.50 4.59 <soap> yes but it’s worth it请注意,每个单词的确切开始和结束时间不可用。使用均匀分段作为近似值。
关键字列表关键字。每个关键字包含一个或多个单词,如下所示:
PROUD OF YOURSELF
DON
TWENTY THOUSAND POUNDS
LIB DEM
LIABILITY使用开发集文件(dev.ctm 和 dev.stm)来开发方法。将评估集文件(eval.ctm 和 eval.stm)仅用于评估。
阅读清单
M. Saraclar, R. Sproat, ”Lattice-Based Search for Spoken Utterance Retrieval”, Proc. NAACL, 2004.
本作品采用《CC 协议》,转载必须注明作者和本文链接








 关于 LearnKu
关于 LearnKu



