
正则表达式必知必会(上)
0 / 0 / 创建于 5年前 /
 Taylor 的个人博客
Taylor 的个人博客
正则表达式必知必会(上)
正则表达式0. 介绍
《正则表达式必知必会》这本书非常简洁明了的介绍了正则表达式常见的应用场景,按部就班的让读者掌握正则表达式这个强大的工具。
本文在于简化书中的内容,抽取核心知识点,在保留书中举例学习的特色上进行整理总结。
正则表达式必知必会(上)希望通过下面的3个章节、10个例子让读者朋友们去理解正则表达式,以便愉快的使用这个强大的工具。本文阅读大概需要10分钟,如果你觉得正则表达式对你不可或缺请耐心读完它。
定义:正则表达式是一些用来匹配和处理文本的字符串,正则表达式是由正则表达式语言创建的。可以解决如下场景:
- 将文件中 car 的单词找出来并替换,但包含 car 字符串的其他单词不在其中(如 scar、carry 等)。
- 将数据库检索出来的 URL 加入 <a> 标签,使其可点击。
- 检查用户提交的表单中的邮件地址是否合法。
以上的场景包含的两种情况也是正则表达式的两种基本用途,它们分别是搜索:查找特定的信息,替换:查找并编辑特定的信息。
关于正则表达式的几个事实:
- 在使用正则表达式的时候,同一个问题会有多种解决方案,有的比较简单,有的比较快速,有的兼容性更好,有的功能更齐全。
- 掌握正则表达式的关键就是实践,实践,再实践。
1. 匹配纯文本
例1:
1.1. 有多少个匹配结果
例1中匹配 my,找到了两个匹配结果。绝大数正则表达式引擎默认只返回第一个匹配结果,但可以通过特定标志匹配所有匹配结果,比如 JavaScript 中可以通过 g 标记返回一个包含所有匹配结果的数组。
1.2 字母大小写问题
另外正则表达式是区分字母大小写的,在 JavaScript 中可以通过 i 标记强制执行一次不区分字母大小写搜索。
2. 元字符
2.1 转义特殊字符
元字符是一些在正则表达式里有着特殊含义的字符。英文句号 . 是一个元字符,匹配任意一个单字符。左方括号 [ 也是一个元字符,标志一个字符集合的开始。因为元字符在正则表达式有特殊的含义,所以这些字符不能匹配它们本身。比如不能用 [ 匹配 [ 本身,. 匹配 . 本身。
例2:
例2中原本需要匹配 myArray[0],但是没有匹配结果。因为 [0] 代表一个字符区间,只能匹配到字符 myArray0。修改如下即可完成匹配 myArray\[0\]。
所以如果想匹配元字符本身需要使用 \ 转义元字符对它们进行转义,以便让正则表达式知道 \. 仅仅匹配 . 本身,而不需要将 . 当成一个元字符匹配任意一个字符。
2.2 匹配空白字符
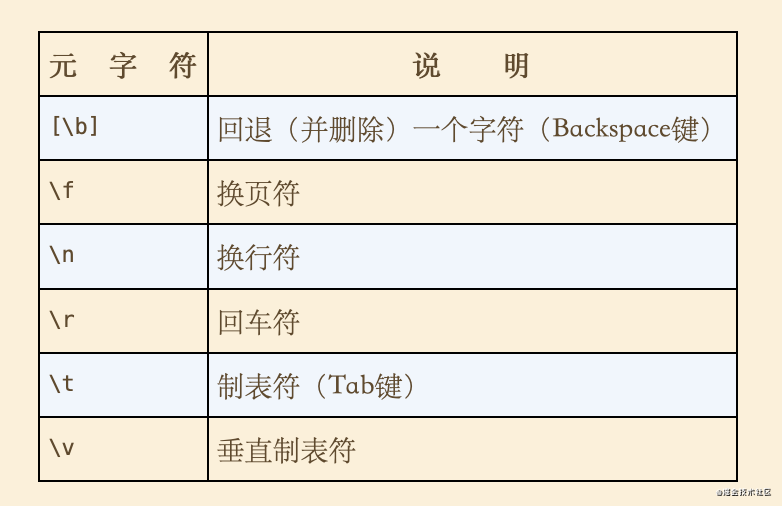
例3:
例3 \r\n 匹配一个 “回车+换行”组合,Windows 使用这个组合作为文本行结束标签(Unix/Linux/Mac 使用 \n)。使用正则 \r\n\r\n 匹配两个连续的行尾符号,所以最终匹配出两条记录之间的空行。
.和[是元字符,但前提是没有对它们进行转移。f和n也是元字符,前提是需要对它们进行转移。如果没有对r和n进行转移,它们只能匹配本身。
2.3 匹配特定的字符类别
.用于匹配任意单个字符[]匹配多个字符集合。[0123456789]匹配任意一个数字,缩写为[0-9]。[abcdefghijklmnopqrstuvwxyz]可以匹配任意字母,缩写为[a-z]。^取非匹配。字符集合取非:[^0-9]匹配一个除数字除数字外的其他字符。[^abc]匹配任意一个字符不等于 a, b 或 c。^取非用于给定字符集合所有字符或字符区间,而不仅是紧跟^后面的那个字符。
2.3.1 匹配数字(与非数字)
例4:
在例4中,\[ 匹配 [,\d 匹配任意单个数字字符,\]. 匹配 ],所以 myArray\[\d\] 匹配出 myArray[0]。 myArray\[\d\] 是 myArray\[[0-9]\] 的缩写。同时还可以匹配 myArray[1], myArray[2], myArray[9] 等。
2.3.2 匹配字母和数字(与非字母和数字)
例5:
在例5中,纯数字的记录行是美国的邮政编码,数字字母混合的是加拿大的邮政编码。为什么只匹配出加拿大的邮政编码呢,这里读者可以自己思考一下。掌握正则表达式的要点是实践和举一反三。
2.3.3 使用 POSIX 字符类
例6:

在例6中,[[ 正则等同与使用6个字符集合的正则  ]]
]][0-9A-Fz-f] ,注意这里要用 [[ 开头和]] 结束。注意 POSIX 字符类必须扩在 [: 和 :] 之间(不是 [ 和 ] 字符用来定义一个字符集合,内层 [ 和 ]是 POSIX 字符类本身的组成部分。
重复匹配
前面介绍了如何使用各种元字符、字符集合和字符类去匹配单个字符,本章介绍如何匹配多个连续重复出现的字符或字符集合。
有多少个匹配
电子邮件地址的基本格式如下图所示:
使用前面章节介绍的正则 \w@\w.\w,\w 可以匹配所有字母和数字字符(以及下划线字符_);@ 字符不需要被转移,但 . 字符是元字符需要转移。这个正则只能匹配 a@b.c 格式的电子邮件地址,因为 \w 只能匹配单个字符。
匹配一个或多个字符
可以使用限定符 + 进行某个指定字符的多次重复匹配。+ 匹配一个或多个字符(至少一个)。a 匹配 a 本身,a+ 匹配一个或多个连续出现的 a。[0-9] 匹配任意单个数字,[0-9]+ 匹配一个或多个连续的数字。
对一个字符集合加限定符后缀需要把限定符放到集合外面。如
[0-9]+而不是[0-9+],后者之匹配数字0到9和+字符构成的字符集合。
匹配零个或多个字符
* 同样也是一个限定符,表示匹配零个或任意多个字符(或字符集合)。
例7:
例7中只匹配到了5个电子邮件,其中有两个不够完整。因为 @ 后面有一个 . 字符分开的情况(有些邮件地址会有多层域名/主机名),@ 前面也有会若干个 . 字符。
对于 ben.bforta.ben.bforta 这种字符可以使用字符集合 [\w.]+ 去匹配,\w 匹配任意字母和数字,. 匹配 . ,限定符 + 匹配符合字符集合中连续重复的匹配。
所以对于 ben.bforta.ben2.bforta2@urgent.ben.forta.com 这种邮件格式的地址,最终匹配邮件地址的正则如下:\w+[\w.]*@[\w.]+\.\w+。对这个正则分析如下:\w+ 匹配 ben,[\w.]* 匹配 bforta.ben2.bforta2(可以包含多个或者零个字母数字和 . 字符),@ 匹配 @,[\w.]+ urgent.ben.forta(注1),\. 匹配 . ,\w+ 匹配 com。
注一:这里可能有同学有些疑惑,为什么 @ 后面的那个
[\w.]+不匹配 urgent.ben.forta.com 呢。简单说可以理解成正则不是完全的从左向右执行,而是根据上下文去智能的匹配。正则表达式发现[\w.]+后面还有一个\.和一个\w+,所以最后一个 . 字符给了.去匹配,com 给了\w+去匹配。
可能这个正则对于初学者有些难度,知道大致的思想就可以了,随着后续的多摸索和逐渐的深入就会熟练起来。
匹配零个或一个字符
另一个非常有用的字符是 ? 。? 只能匹配一个字符(或字符集合)的零次或一次出现。如果需要在一段文本中匹配某个特定的字符(或字符集合)而该字符可能出现,也能不出现。可以把 ? 理解为可选项。
例8:
这个模式的开头部分是 https? 。? 在这里的意思前面的字符 s 是要么出现一次,要么不出现。所以 https?:// 可以匹配 http:// 也可以匹配 https://。
例9:
[\r]?\n[\r]?\n,这个表达式的意思是前面的换行字符可以出现也可以不出现,满足Windows 的行尾符号 \r\n\r\n 和 Unix/Linux/Mac 的行尾符号 \n\n。
\r?和[\r]?在这里是一样的,后者这种写法增加了可读性。另外注意[\r?]这种写法是错误的,?应该放在[\r]字符集合的外面。
匹配指定重复次数
前面介绍的 +、* 和 ? 无法匹配指定的字符个数。可以使用 {} 来匹配指定的字符个数,这里可以理解成 Python/Golang 的数组。想为重复匹配次数设为具体精确的值把数字写在 {} 之间即可,比如过 {3}意味模式里的前一个字符(或字符集合)必须在原始文本中连续重复出现3次才算一个匹配。
例10:

[:xdigit]匹配一个十六进制数字,{6} 要求这个 POSIX 字符类必须连续出现6次。类似地,使用模式 [09AFaf]{6} 也可以解决这个问题。
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: