
dremio使用简介
2 / 0 / 创建于 5年前 /
 城里的野山参 的个人博客
城里的野山参 的个人博客
适用人群:建议先花1天时间通读一遍官方文档之后再来看
dremio ,我理解是用来加工数据的,支持多种原始的数据格式,经过 dremio 的处理,可以加工出任何自己想要的数据。
资料方面目前来看,中文资源近乎没有,主要的参考资料还是官方文档,dremio官网。
依照个人有限的使用经验来看,需要了解几个 dremio 中的基本概念。
- sources
数据源,支持各种文件(.csv,.json等),数据库(mysql等),简而言之,市面上常规的基本支持,详细的需要参看官方文档。
- virtual dataset
虚拟数据集,这是核心,作用类似于中间表。
最重要的玩法就是virtual dataset的使用,通过各种各样的SQL,基于我们导入的数据源来生成各种各样的中间表来获得我们想要的数据,而且中间表查询到的数据可以作为另一个中间表的数据源,这样层层推进可以实现非常多的功能。
实战举例
假设我们的数据源是网站的nginx日志,设置了数据源之后,就有了一个基表(以此为基础表)dremio中的显示可能是这样的,这就是nginx日志经过dremio解析之后拿到的数据,后续所有的操作都是以这个为基础进行。
下面涉及到virtual dataset使用。
创建一个SQL对基表进行提取处理,拿到想要的数据或者处理成一个中间表,然后再在这个中间表的基础上进一步的提取处理(这个进一步可以多次),直到拿到想要的数据。
下面是一个示例。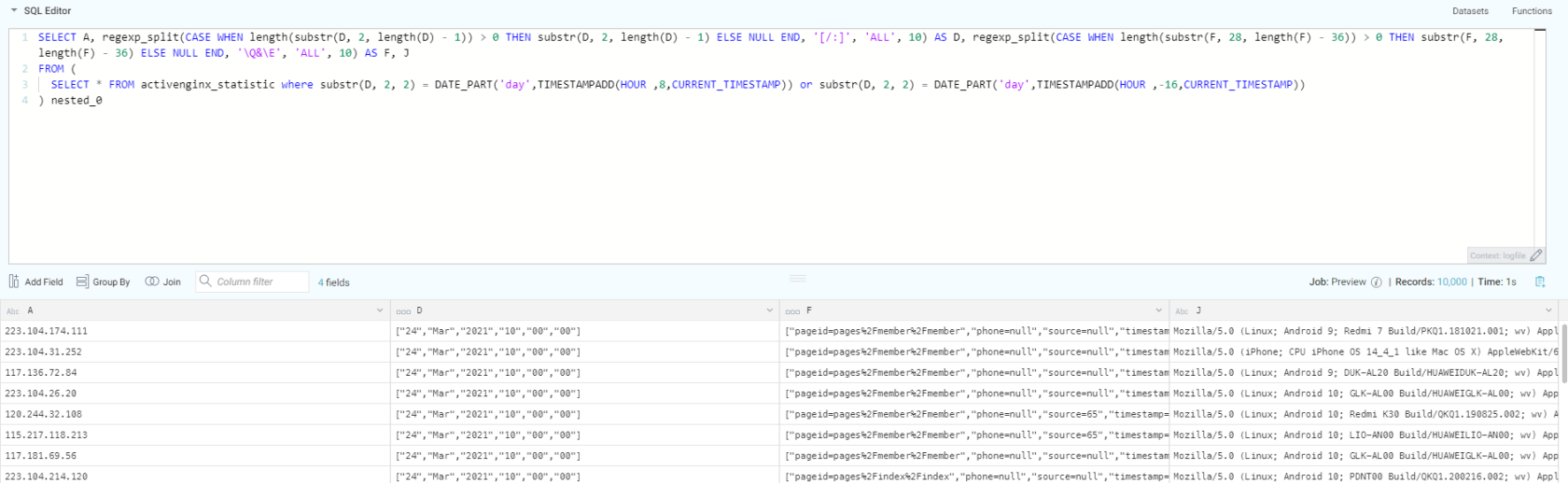
进行到这里,dremio的作用基本上就体现出来了,导入原始数据,然后一步步处理,生成众多的中间表(中间表并不真实存在,保存的只是执行语句),执行查询时才会层层翻译,去查询处理基表,dremio有提供API,一般来讲,处理的结果都会进行入库处理,数据显示都是直接从数据库拉取数据。
排错
基本的流程性问题明了之后,下一步是排错处理。
每一个查询都是一个job,在top level有job列表,展示了所有job的情况,执行时长,执行结果等信息。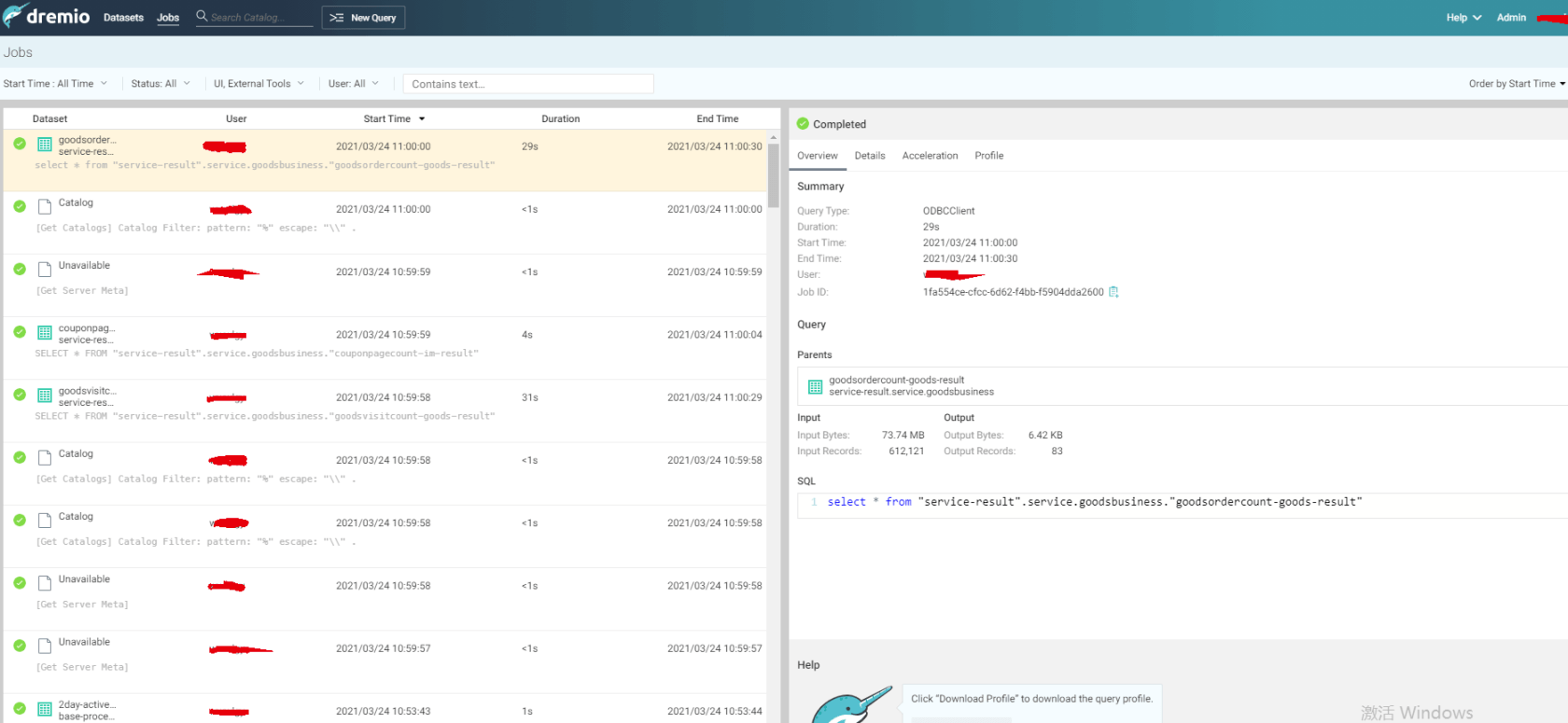
常规的错误根据抛出的error信息处理即可,一般都是中间表处理的结果不符合预期导致的。
特别注意的错误:
dremio,报错 exceeds the size limit of 32000 bytes
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



