
laravel + guzzle 读取网站链接http状态
2 / 0 / 创建于 5年前 /
 ccflow 的个人博客
ccflow 的个人博客
介绍
基于laravel+ guzzle 实现的一个简单爬虫脚本(抓取网站所有连接获取http状态)。
路由
$router->get('reptile/index', 'ReptileController@index');代码
<?php
namespace App\Http\Controllers\Admin;
use App\Http\Controllers\Controller;
use GuzzleHttp\Client;
use GuzzleHttp\Pool;
use Illuminate\Http\Request;
use Illuminate\Support\Facades\DB;
/**
* 爬站点所有url-http状态
* Class ArticleController
* @package App\Http\Controllers\Admin
*/
class ReptileController extends Controller
{
/**
* 爬虫脚本
* @param Request $request
*/
public function index(Request $request)
{
//http://127.0.0.1:8000/admin/reptile/index?url=https://www.xxxx.com
$testUrl = $request->input('url');
if (empty($testUrl)) {
die('error');
}
$siteContent = $this->getUrlContent($testUrl);
if (!empty($siteContent)) {
$urlList = $this->crawler($testUrl, $siteContent);
$list = [];
foreach ($urlList as $item) {
//是否属于当前域名
$url = substr($item, 0, strlen($testUrl));
if (empty(strcmp($url, $testUrl))) {
$list[] = $item;
}
}
//查重
$list = array_unique($list);
//再次遍历刚才的结果链接列表
$list1 = $this->filter($list, $testUrl);
$this->getAllHeaderResponse($list1);
}
}
/**
* 读取网站内容并筛选出相同域名下的连接列表
* @param $result
* @param $testUrl
* @return array
*/
private function filter($result, $testUrl)
{
$list = [];
foreach ($result as $item) {
$siteContent = $this->getUrlContent($item);
if (!empty($siteContent)) {
$urlList1 = $this->crawler($item, $siteContent);
if (!empty($urlList1)) {
foreach ($urlList1 as $value) {
$url = substr($value, 0, strlen($testUrl));
if (empty(strcmp($url, $testUrl))) {
$list[] = $value;
}
}
$list = array_unique($list);
}
}
}
return $list;
}
/**
* 获取网站http相应状态
* @param $result
*/
private function getAllHeaderResponse($result)
{
//重置索引
$result = array_merge($result);
$count = count($result) ?? 0;
$res = $this->multiCheckNetResource($result);
$data = [];
foreach ($result as $k => $v) {
foreach ($res as $kk => $vv) {
if ($k == $kk) {
$data[] = [
'url' => $v,
'status' => $vv,
'count' => $count,
];
}
}
}
DB::table('site_status')->insert($data);
die('success');
}
/**
* 获取网站内容
* @param $url
* @return bool|false|string
*/
private function getUrlContent($url)
{
try {
$handle = file_get_contents($url);
return $handle;
} catch (\Throwable $exception) {
return false;
}
}
/**
* 获取网站内容链接
* @param $url
* @param string $content
* @return array|bool
*/
private function crawler($url, $content = '')
{
$urlList = $this->reviseUrl($url, $this->filterUrl($content));
if ($urlList) {
return $urlList;
} else {
return false;
}
}
/**
* 正则域名
* @param $webContent
* @return bool|mixed
*/
private function filterUrl($webContent)
{
$reg = '/<[a|A].*?href=[\'\"]{0,1}([^>\'\"\ ]*).*?>/';
$result = preg_match_all($reg, $webContent, $matchResult);
if ($result) {
return $matchResult[1];
} else {
return false;
}
}
/**
* 获取域名下面的所有子uri
* @param $baseUrl
* @param $urlList
* @return array|bool
*/
private function reviseUrl($baseUrl, $urlList)
{
$urlInfo = parse_url($baseUrl);
$baseUrl = $urlInfo["scheme"] . '://' . $urlInfo["host"];
$result = [];
if (is_array($urlList)) {
foreach ($urlList as $urlItem) {
if (preg_match('/^http/', $urlItem)) {
// 已经是完整的url
$result[] = $urlItem;
} else {
// 不完整的url
if (substr($urlItem, 0, 1) == '/') {
$realUrl = $baseUrl . $urlItem;
} else {
$realUrl = $baseUrl . '/' . $urlItem;
}
$result[] = $realUrl;
}
}
return $result;
} else {
return false;
}
}
/**
* 并发多请求 检查网络资源是否200
* @param $taskUrls
* @param int $concurrency
* @param array $config
* @return array
*/
private static function multiCheckNetResource(
$taskUrls,
$concurrency = 20,
$config = [
'verify' => false,
'timeout' => 3,
]
)
{
$client = new Client($config); //并发请求链接地址
$requests = function () use ($client, $taskUrls) {
foreach ($taskUrls as $item) {
yield new \GuzzleHttp\Psr7\Request('HEAD', $item);
}
};
$result = [];
$pool = new Pool($client, $requests(), [
'concurrency' => $concurrency, //同时并发抓取几个
'fulfilled' => function (\GuzzleHttp\Psr7\Response $response, $index) use (&$result) {
// this is delivered each successful response
$result[$index] = $response->getStatusCode();
},
'rejected' => function (\Throwable $throwable, $index) use (&$result) {
$result[$index] = $throwable->getCode();
// this is delivered each failed request
},
]);
$promise = $pool->promise();
$promise->wait();
return $result;
}
}
最终效果
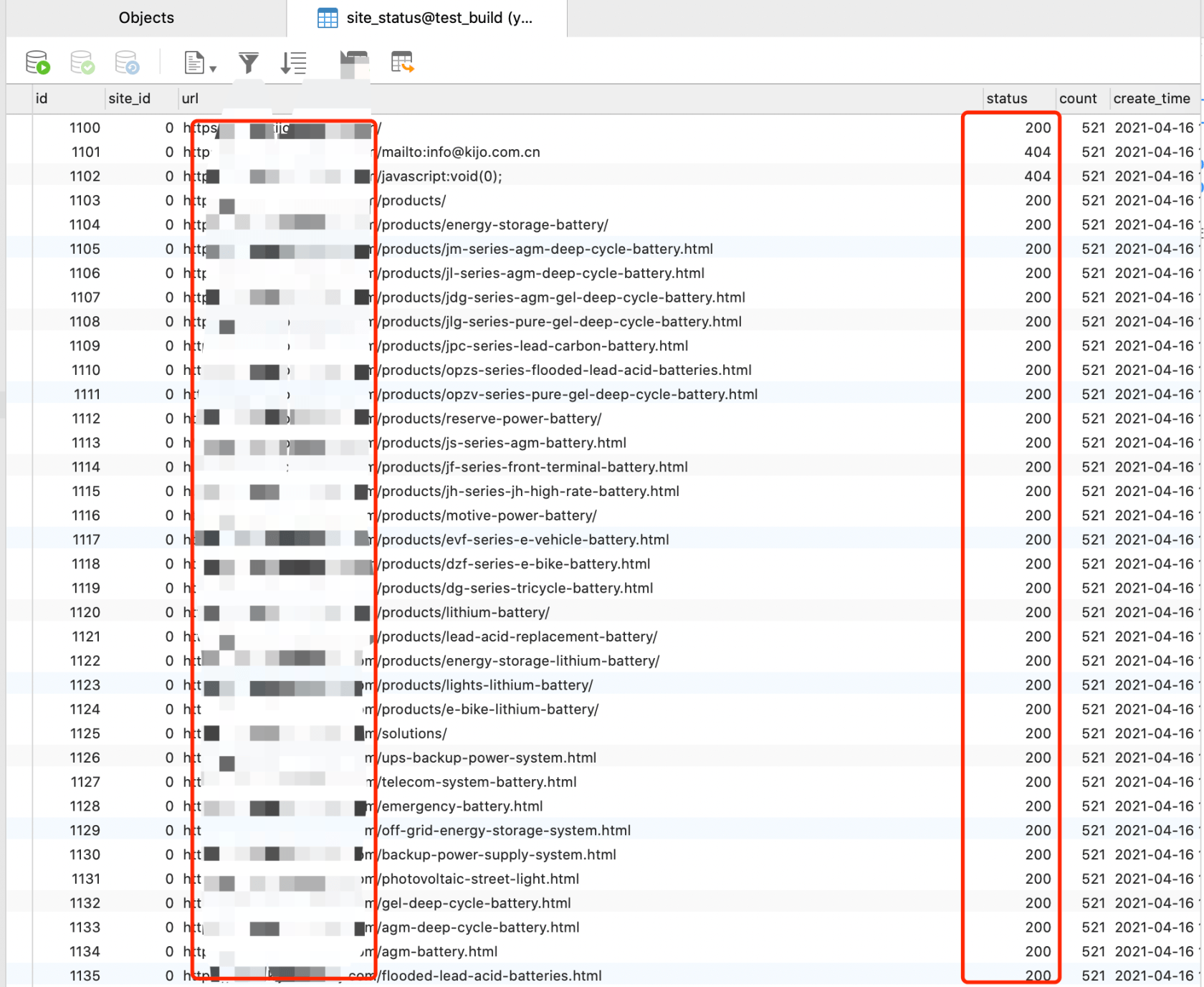
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: