
GO语言敏感词检测
10 / 2 / 创建于 5年前
 bean 的个人博客
bean 的个人博客
因为工作需求,需要一个敏感词检测的功能,本来准备接入云平台.但是后来想想还是自己做了吧.由于是第一次接触敏感词检测,刚开始的想法是使用字符串匹配,或者分词匹配,但是一想到如果敏感词有几千,而需要检测的内容又特别长的时候,效率就非常低,于是从《算法导论》里面查了一下,找到了
dfa算法.于是dfa的go语言包就诞生了.
DFA 全称为:Deterministic Finite Automaton,即确定有穷自动机。其特征为:有一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态。但不同于不确定的有限自动机,DFA 中不会有从同一状态出发的两条边标志有相同的符号。
这里我们用 Trie 树实现. 下面我们有and,as,at,cn,com这些关键词, 我们看下使用Tire 树怎么保存这些数据
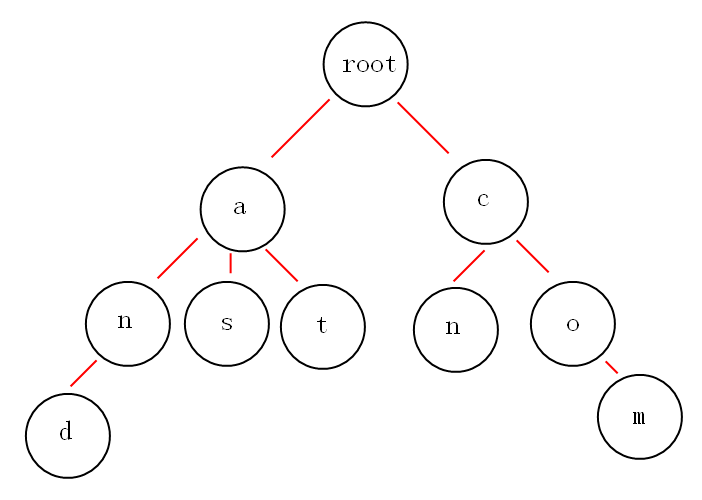
从这个图中可以看出这个树保存的数据规律:
根节点不包含字符,除根节点外的每一个子节点都包含一个字符。
从根节点到某一节点,路径上经过的字符连接起来,就是该节点对应的字符串。
每个单词的公共前缀作为一个字符节点保存
根据这些特性,我们构建一个 Trie 树, 我实现了一个敏感词检测包.代码非常简单,有需要使用的可以直接将文件拷贝到自己的项目中使用.
GitHub地址: github.com/bean-du/dfa
本作品采用《CC 协议》,转载必须注明作者和本文链接









 关于 LearnKu
关于 LearnKu




推荐文章: