
Elasticsearch 入门
10 / 0 / 创建于 5年前 /
 jrh 的个人博客
jrh 的个人博客
Elasticsearch 简介
Elasticsearch 是什么

在探究 Elasticsearch(简称ES)是什么之前,我希望你能搞清楚,ES 是如何诞生的,或者说,ES 的诞生解决了什么样的问题。
假设我们的系统数据量达到了十亿,百亿的级别,在这样的大规模海量级数据下,我们如何检索?
- 传统关系型数据库
对于关系型数据库,我们通常采用以下的架构去解决查询瓶颈:

解决要点:
通过主从备份解决数据安全性的问题
通过数据库代理中间件心跳监测,解决单点故障问题
通过数据库代理中间件将查询语句分发到各个 slave 节点进行查询,并汇总结果,减轻主库的访问压力
- 非关系型数据库
对于非关系型数据库,例如 MongoDB :
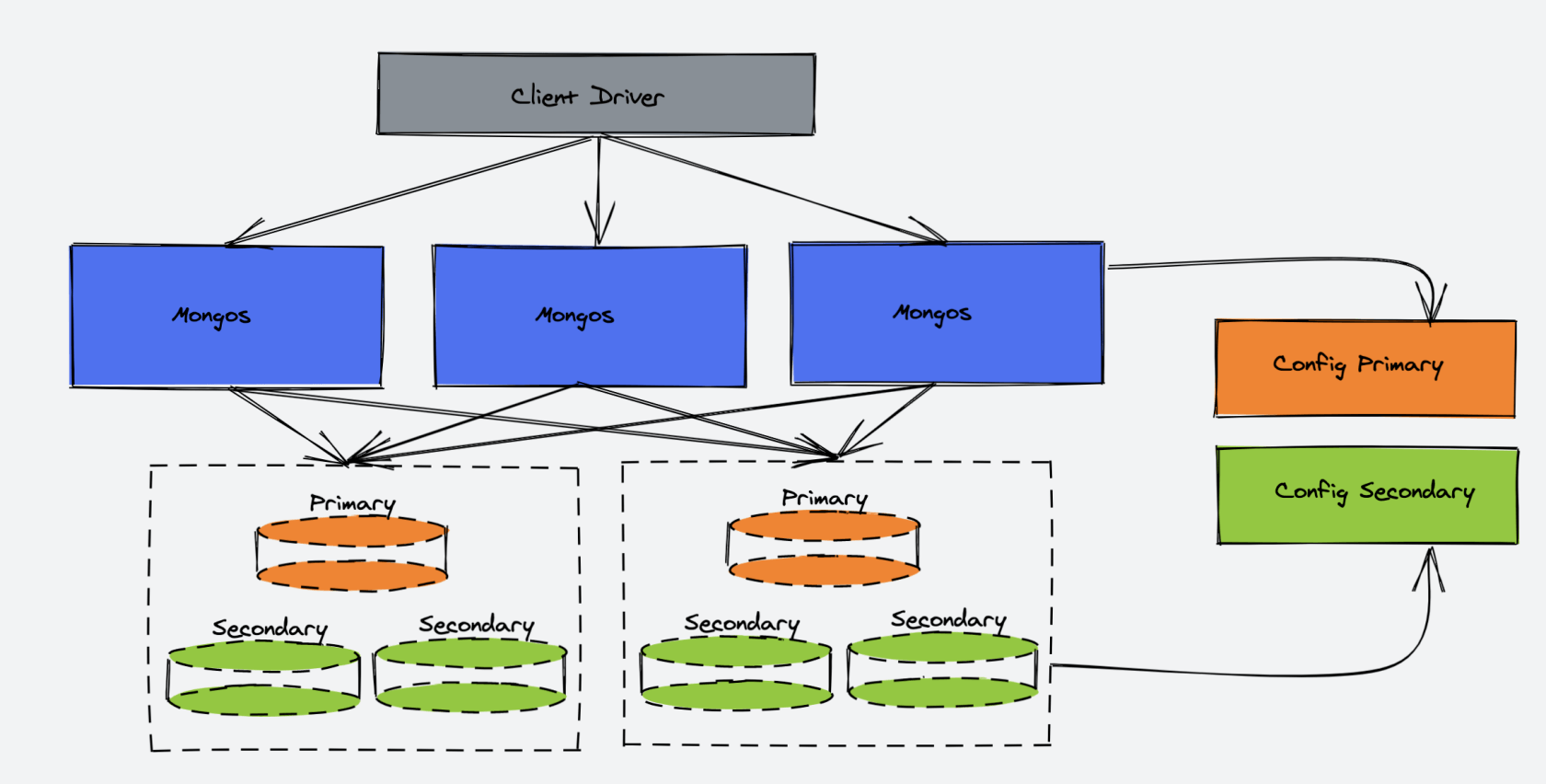
解决要点:
通过副本备份保证数据安全性
通过节点竞选机制来解决单点故障问题
先从配置库检索分片信息,然后将请求分发到各个节点,最后由路由节点合并汇总结果
我们看到,无论是关系型数据库方案,还是非关系型数据库方案,我们都需要考虑各种各样的问题:单点故障,数据安全等等,是否有将上述问题一网打尽的解决方案?
于是,Elasticsearch 诞生了。
Elasticsearch 是一个分布式的开源搜索和分析引擎;在 Apache Lucene 基础上开发而成,Elasticsearch 使用 Lucene 作为核心来实现所有索引和搜索的功能。Elasticsearch 以其简单的 RESTful API 隐藏了 Lucene 的复杂性,使得让全文搜索变得简单。Elasticsearch 以其分布式特性,速度和可扩展性闻名。Elasticsearch 每秒可以处理 PB 级海量数据。
Elasticsearch 的用途
应用程序搜索
网站搜索
企业搜索
日志处理和分析
基础设施指标和容器监测
应用程序性能测试
地理空间数据分析和可视化
安全分析
业务分析
Elasticsearch 的核心概念
Cluster
Cluster :集群,一个 ES 集群由一个或多个节点(Node)组成,每个集群都有一个 cluster-name 作为标识。
ES 集群的健康状态有三种:green,yellow,red。
green 为健康状态; 表示所有的 Primary Shard 以及 Replica Shard 都可以用
yellow 为部分故障状态;表示所有的 Primary Shard 可用,但不是所有的 Replica Shard 都可用
red 为严重故障状态;表示不是所有的 Primary Shard 都可用
Node
Node:节点,一个节点就是一个运行的 ES 实例;所谓的运行实例就是一个 ES 的进程,节点可以在同一台机器上,也可以在不同的机器上,生产环境中建议,每台服务器只设置一个节点,运行一个服务器进程。
在一个分布式系统中,可以通过多个节点组成一个 ES 集群,这个集群中有一个节点作为主节点(Master),ES 是去中心化的,如果主节点(Master)挂掉,那么 Master-eligible 节点可以参加选主流程,成为 Master 节点,所以 ES 不存在所谓的单点故障问题。当第一个节点启动时,它会将自己选举成 Master 节点。
Master Node & Master eligible Node
每个节点启动后,默认就是一个 Master eligible 节点(可以设置 node.master:false 来禁止),Master eligible 节点可以参与选主流程,成为 Master 节点。当第一个节点启动时,它会将自己选举成 Master 节点
Master 节点负责管理集群的状态,当集群的拓扑结构改变时,将索引分片分派到相应的节点上。
从用户的角度来看,主节点在 ElasticSearch 中并没有占据着重要的地位,这与其它的系统(比如数据库系统)是不同的。实际上用户并不需要知道哪个节点是主节点;所有的操作需求可以分发到任意的节点,ElasticSearch 内部会完成这些让用户感到不明觉历的工作。在必要的情况下,任何节点都可以并发地把查询子句分发到其它的节点,然后合并各个节点返回的查询结果。最后返回给用户一个完整的数据集。所有的这些工作都不需要经过主节点转发(节点之间通过 P2P 的方式通信)。
除了 Master Node,Master eligible Node 外,节点还可以分为很多类型,例如 Data Node,Ingest Node,Tribe Node 等等,在这里我们就不逐一解释了。
Shard
Shard:分片;当有大量的文档(Document)时,由于内存的限制,磁盘处理能力不足,无法足够快响应客户端的请求,ES 的处理机制是将数据分为较小的分片,每个分片分放到不同的服务器上。当你查询的索引分布在多个分片上时,ES 会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序是不知道分片的存在的,这个过程对于用户来说是透明的。
分片分为主分片(primary shard) 以及 从分片(replica shard)。
从分片是主分片的一个副本,当硬件故障或其他因素导致节点服务器宕机,存储在该节点的主分片失效,其他的节点存储的从分片会提供备份的作用以防止数据丢失。
Index/Type/Document/Field
ES6 以前
Index/Type/Document/Field 的概念等同于关系型数据库(例如:MySQL)的数据库/数据表/行/列
| MySQL | Elasticsearch |
|---|---|
| DB | Index |
| Table | Type |
| Row | Document |
| Column | Field |
不过从 ES7 开始,Type 这个概念正式被废弃了。
为什么?因为在 Elasticsearch 设计的初期,是直接参考了关系型数据库的设计模式,从而设计了 Type(数据表)的概念。但是 ES 本质上是基于 Lucene 的,Lucene 的全文检索功能之所以这么快是因为其采用了倒排索引算法,而倒排索引的生成本身是基于 Index 的,而并非 Type,多个 Type 反而会减慢搜索的速度。所以,从 ES7 开始,便正式舍弃了 Type 。
Elasticsearch 基本原理
ES 搜索引擎的原理
ES 搜索引擎的原理为:倒排索引。
我们知道 MySQL 的索引使用了 B+树 这种数据结构。但是如果对于文本而言,B+树 很显然就不适用了。
在这里,我们不会深入探究倒排索引这个算法,我们只是简单涉猎,了解究竟什么是倒排索引?
倒排索引是一种使用 “单词 -> 文档” 存储格式的算法,通过倒排索引,我们可以根据单词快速获取包含这个单词的文档列表。
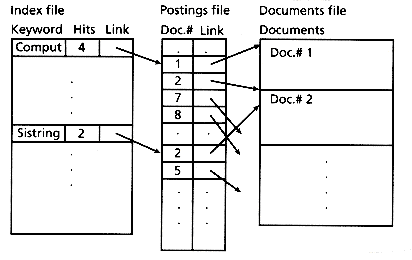
我来举个例子:
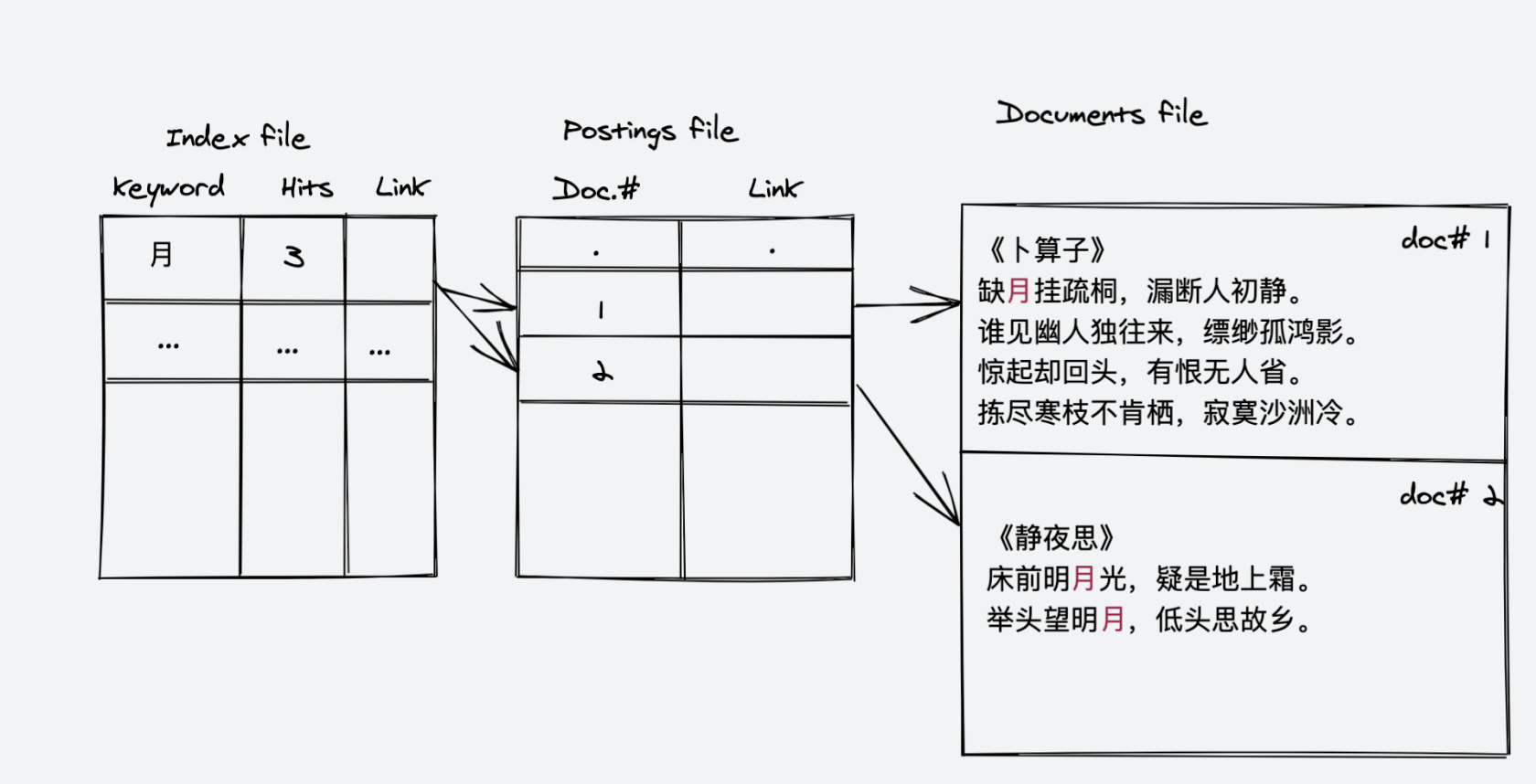
假设我们的文档库中存储两个文档,分别是李白的《静夜思》和 苏东坡的《卜算子》
《卜算子》
缺月挂疏桐,漏断人初静。谁见幽人独往来,缥缈孤鸿影。
惊起却回头,有恨无人省。拣尽寒枝不肯栖,寂寞沙洲冷。
《静夜思》
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
所谓的倒序索引,就是单词到文档的映射,假设我们要检索的单词是 “月”
那么对于这个示例,倒排索引的示意图大概就是这个样子的:
ES 节点的通信
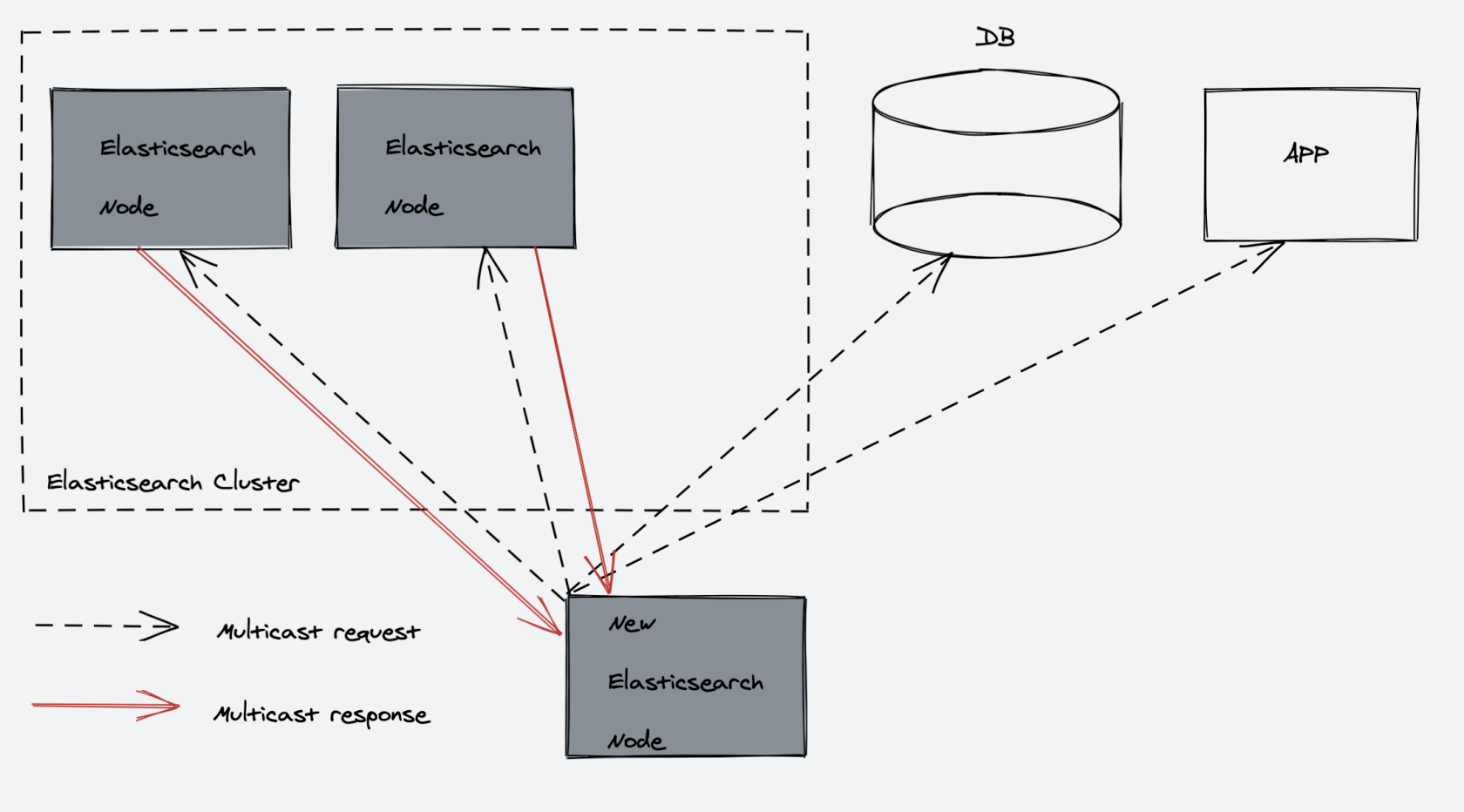
首先,我们能够与集群中的任何节点进行通信,包括主节点。任何一个节点都互相知道文档(Document)存在于哪个节点上,它们可以转发请求到我们需要数据所在的节点上。我们通信的节点负责收集各节点返回的数据,最后一起返回给客户端。这一切都由 Elasticsearch 透明的管理。
当 Elasticsearch 启动后,它会利用多播(Multicast)或者单播(Unicast)(使用单播模式通信需要用户手动设置)寻找集群中的其他节点,并与之建立连接:
ES 数据的备份
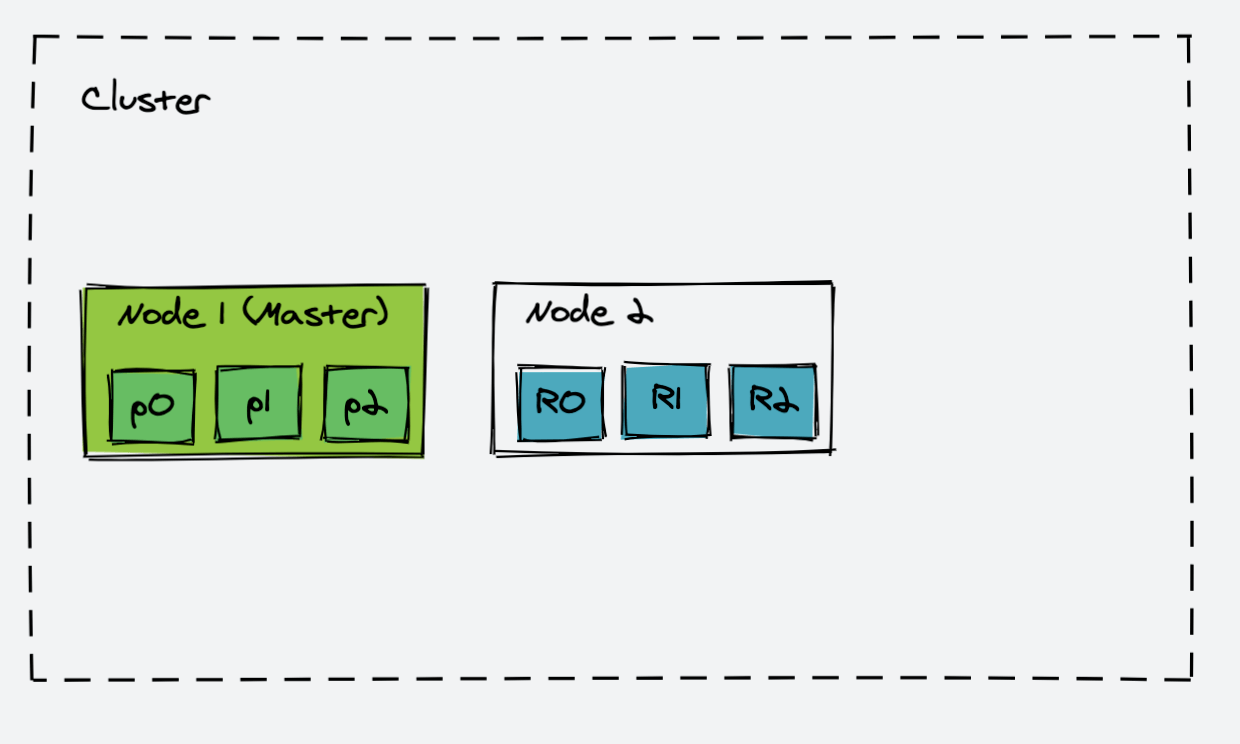
假设我们当前的集群只有一个节点,该节点中有三个主分片:p0,p1,p2

为了防止 Node1 挂掉致使整个 Cluster 不可用,我们选择新增一个 ES 实例。
在我们新增一个节点时,ES 内部会将 Node1 所有的 Primary Shard 备份到新的节点中。
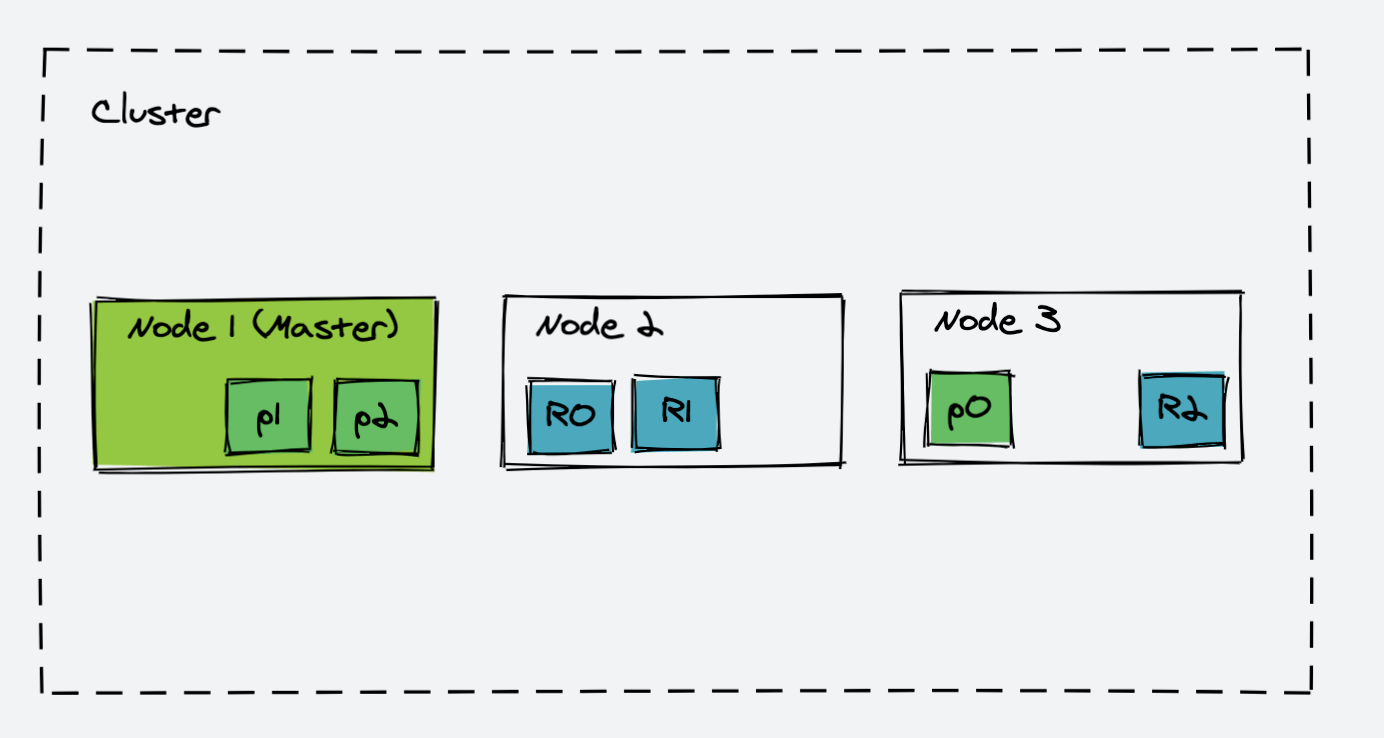
如果主节点挂掉,那么 Node2 会自动变成主节点,并且 Node2 中的 Repica Shard 会升级为 Primary Shard。
如果我们再添加一个节点呢?
ES 对于分片(Shard)的分配遵循一个原则:Scale horizontally 即:水平扩展。所谓的水平扩展就是将并发访问的压力分散到各个节点上,来减轻每个节点的压力;至于主分片( Primary Shard)与备份( Repica Shard) 是如何被分配到各个节点的,这是 ES 内部的算法逻辑来实现的,我们无需关心。
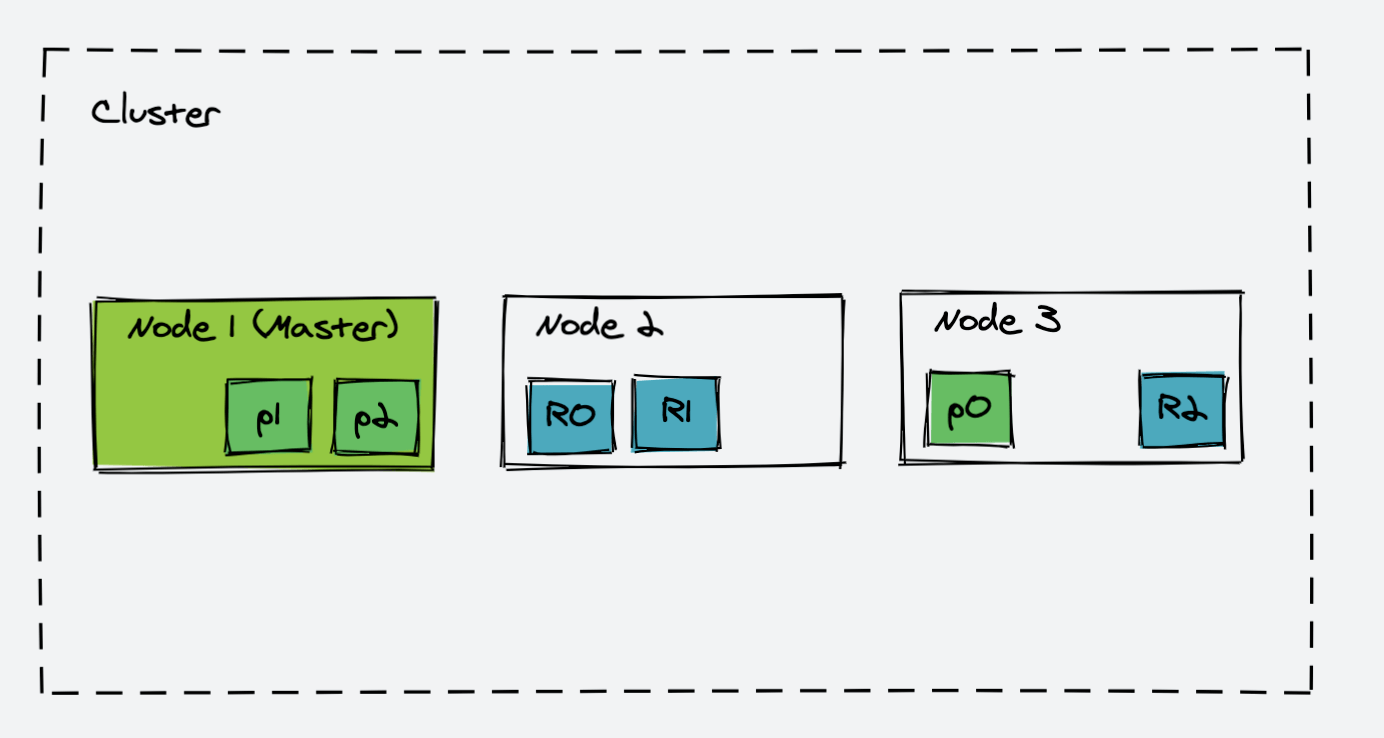
ES 失效节点的处理
在正常工作时,主节点会监控所有的节点,查看各个节点是否工作正常。如果在指定的时间段,节点无法访问,那么该节点就会被视为出现故障,接下来错误处理程序就会启动;如果主节点失效,那么所有的 Master eligible Node 会通过选举机制选出一个新的 Master Node。由于该节点出现了故障,那么分配到该节点的分片丢失,集群需要重新均衡分片到有效的节点上:
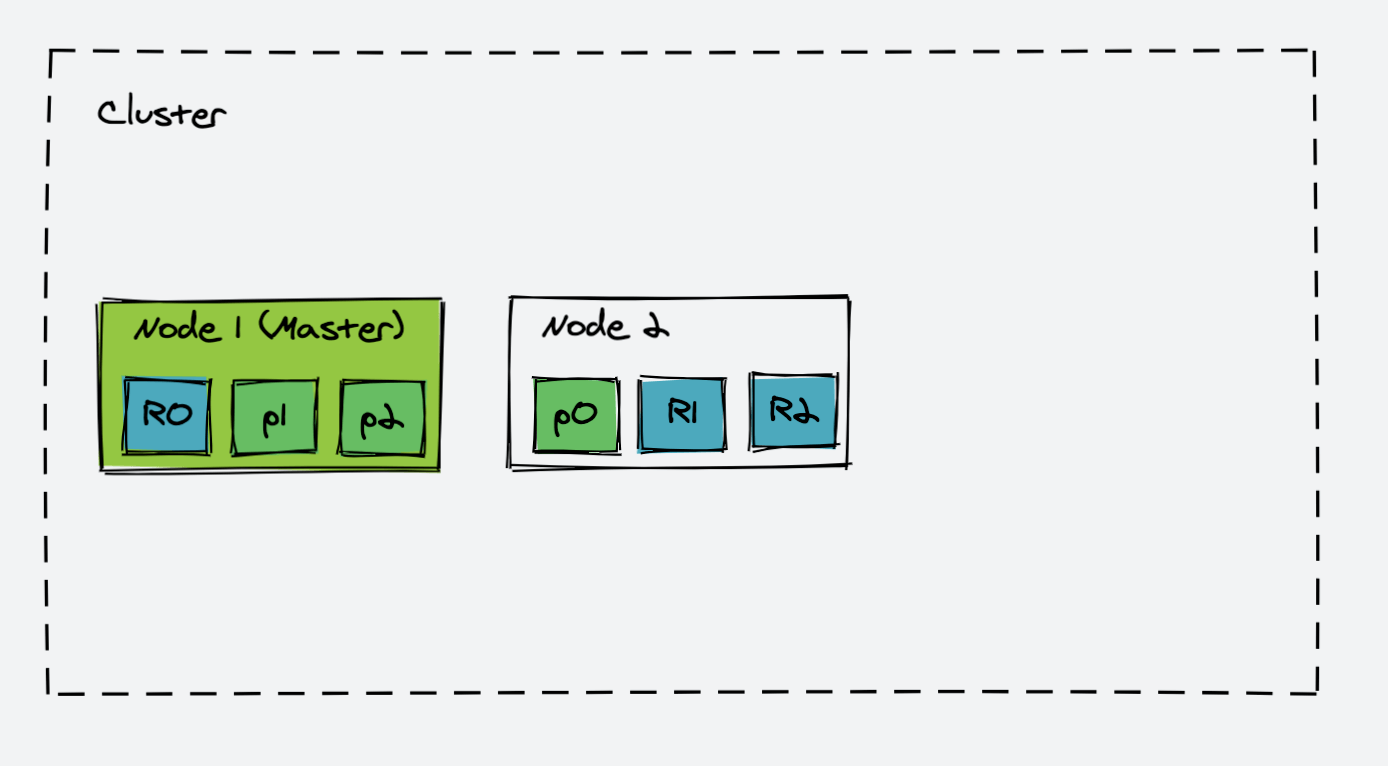
如果 Node3 失效,那么 Node3 会从 ES Cluster 中被移除,并且 Node2 中备份的 R0 会升级为 P0,各个节点之间会检测将没有备份的 Primary Shard 备份好。
Elasticsearch 的安装
Elasticsearch
版本:Elasticsearch 6.4.3
下载地址:www.elastic.co/cn/downloads/past-r...
下载完毕后,进入到 elasticsearch-6.4.3 /config 目录下,修改 elasticsearch.yml 文件
- cluster.name: 集群名称
- path.data: 存放数据的路径
- path.logs: 存放日志的路径
配置环境变量,因为我是用的是 Mac 的 zsh ,所以需要在 .zshrc 文件中配置环境变量
vi ~/.zshrcexport PATH=/Users/macbook/Downloads/elasticsearch-6.4.3/bin:$PATHsource .zshrc
配置完毕后,输入命令
elasticsearch --version成功返回 ES 的版本号,说明配置成功
➜ bin elasticsearch --version
Java HotSpot(TM) 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
Version: 6.4.3, Build: default/tar/fe40335/2018-10-30T23:17:19.084789Z, JVM: 11.0.8Elasticsearch ik
推荐下载 ES 中文分词插件:elasticsearch ik
版本:elasticsearch-analysis-ik 6.4.3
下载地址:github.com/medcl/elasticsearch-ana...
我们下载好插件后,需要将该压缩包解压到 elasticsearch/plugins/ik 目录下。
Elasticsearch 的基本使用
在我们安装好 Elasticsearch 后,进入到 bin 目录下,执行命令:(double-click elasticsearch.bat on Windows)
elasticsearchES 服务就开启了
查看集群的健康状态
curl -X GET "localhost:9200/_cat/health?v"返回结果:
➜ ~ curl -X GET "localhost:9200/_cat/health?v" epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent 1624379527 00:32:07 test green 1 1 0 0 0 0 0 0 - 100.0%可以看到,我们的集群名称为 test,集群的健康状态为 green。
查看集群的所有节点
curl -X GET "localhost:9200/_cat/nodes?v"获取所有索引
curl -X GET "localhost:9200/_cat/indices?v"返回结果:
➜ ~ curl -X GET "localhost:9200/_cat/indices?v" health status index uuid pri rep docs.count docs.deleted store.size pri.store.size当前我们没有创建任何索引。
创建索引 “test“
curl -X PUT "localhost:9200/test"返回结果:
➜ ~ curl -X PUT "localhost:9200/test" {"acknowledged":true,"shards_acknowledged":true,"index":"test"}%再次查看所有的索引:
➜ ~ curl -X GET "localhost:9200/_cat/indices?v" health status index uuid pri rep docs.count docs.deleted store.size pri.store.size yellow open test 5lIDUy-8QcironBi2m8Auw 5 1 0 0 1.1kb 1.1kb我们看到,test 索引的健康状况为 yellow,这是因为,我们在创建该索引时,没有为这个索引创建任何分片,ES 认为该索引是没有任何备份的,所以其健康状况为 yellow。
删除索引 “test“
curl -X DELETE "localhost:9200/test"返回结果:
➜ ~ curl -X DELETE "localhost:9200/test" {"acknowledged":true}%说明 “test“ 索引删除成功,再次查询所有节点:
➜ ~ curl -X GET "localhost:9200/_cat/indices?v" health status index uuid pri rep docs.count docs.deleted store.size pri.store.size可以看到,”test“ 索引已被删除。
向 ES 中 插入/修改 数据(向 test 索引中插入一条 id 为 1 的数据,数据内容见 JSON)
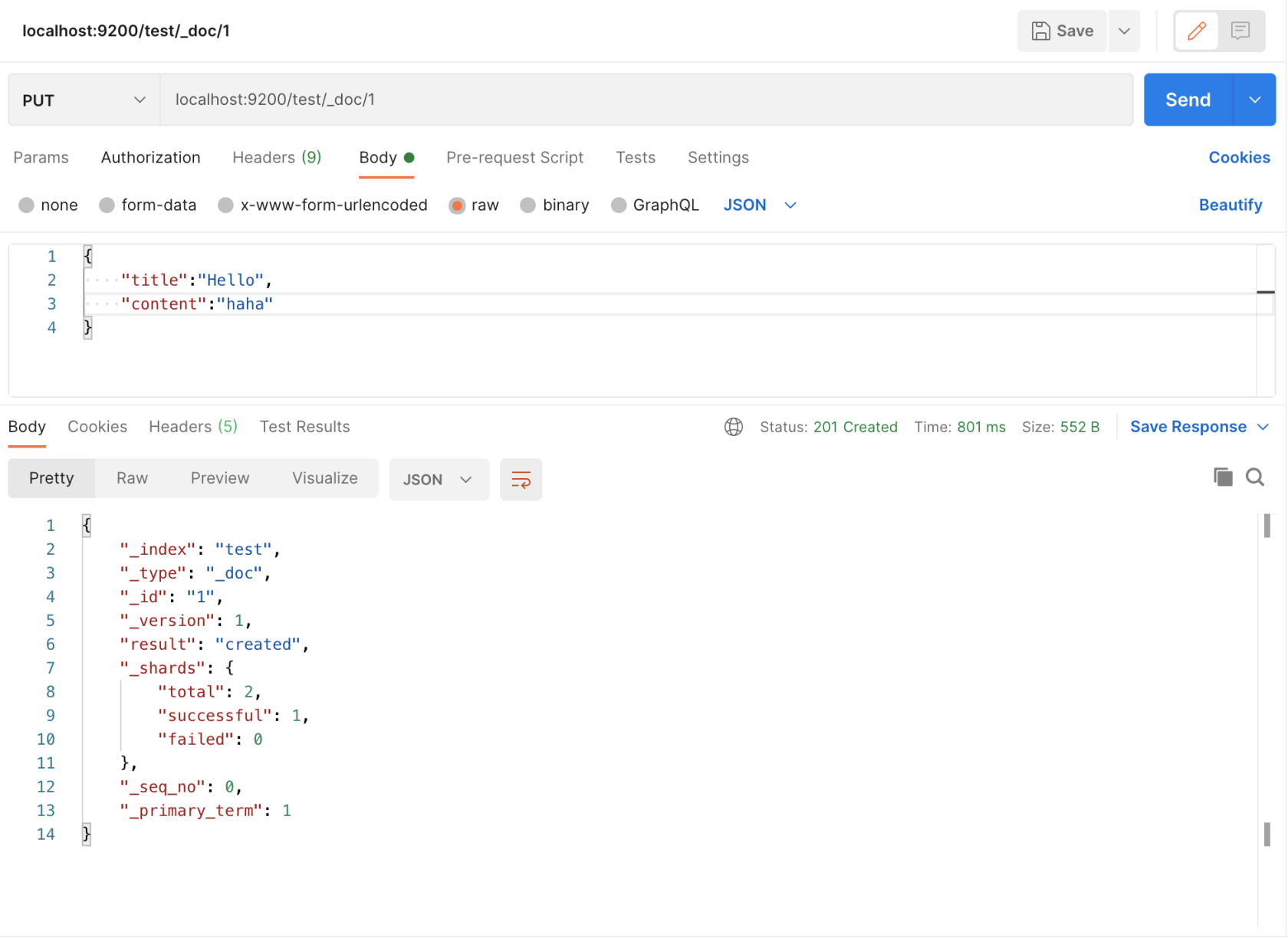
- 查询数据(查询索引为 test,id 为 1 的数据)
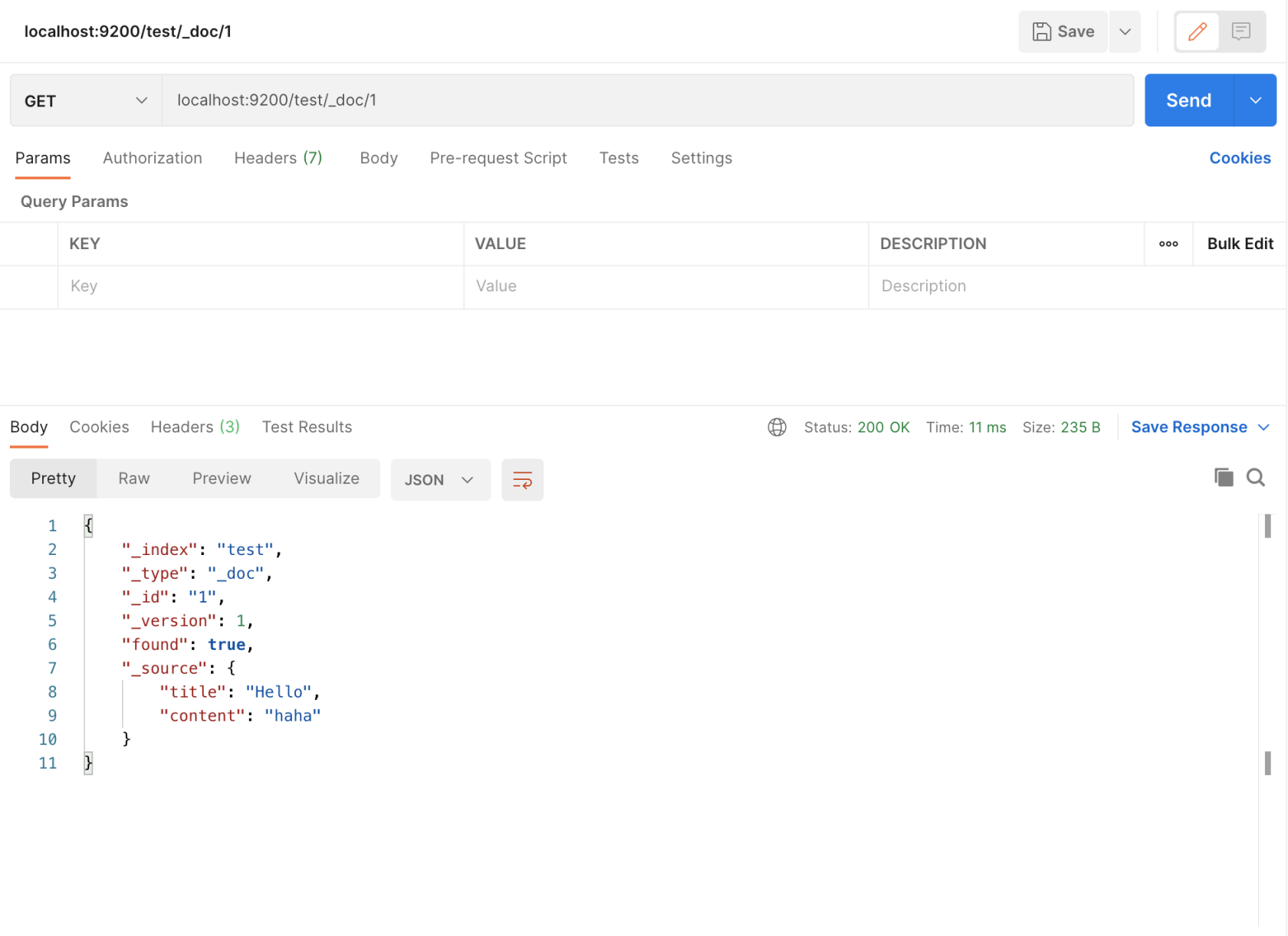
- 删除数据 (删除索引为 test,id 为 1 的数据)
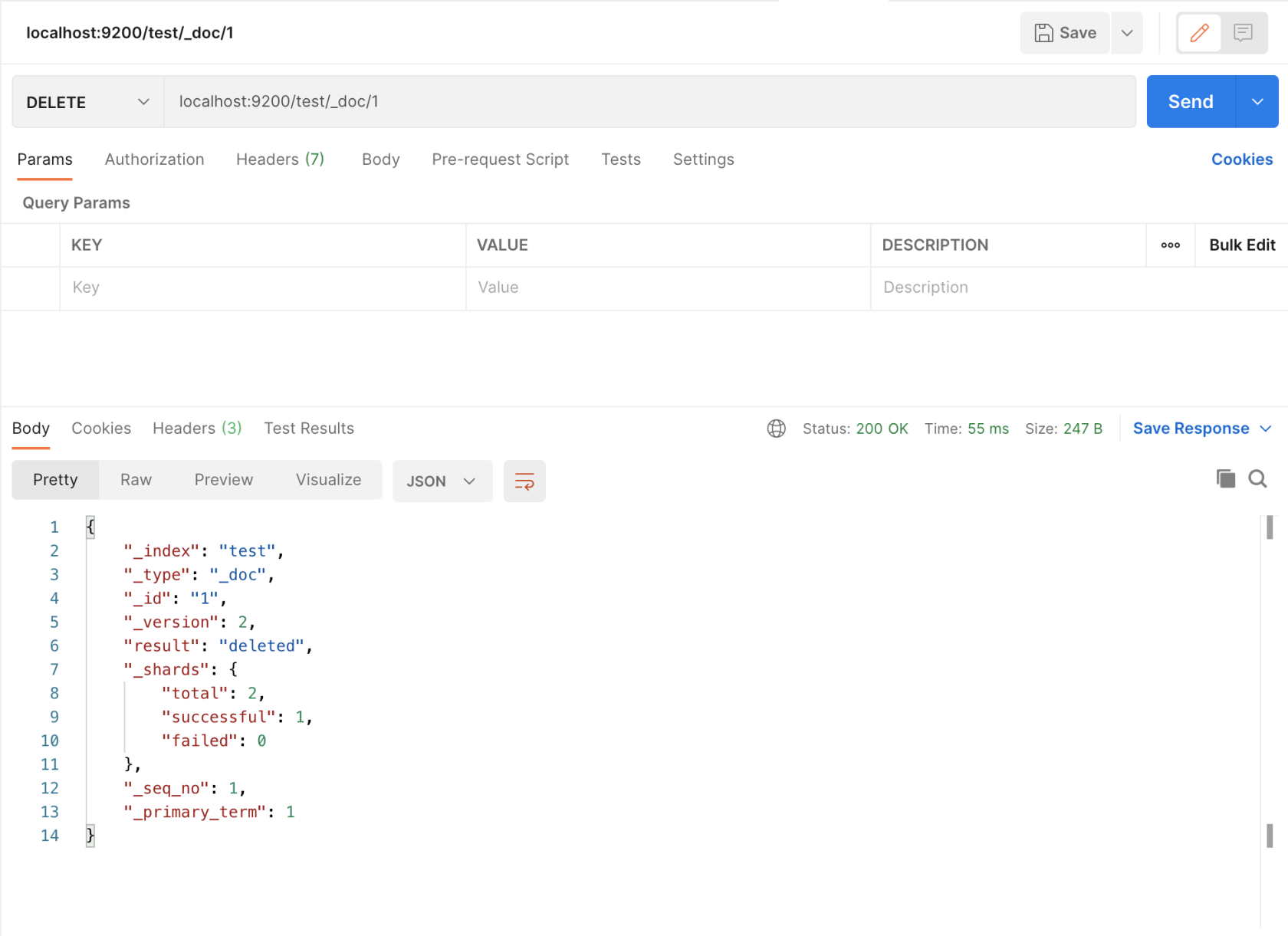
- 搜索
搜索是 ES 的重点,我们先向 test 索引中插入三条数据;
搜索全部内容:
GET: localhost:9200/test/_search返回结果:
{
"took": 118,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1.0,
"hits": [
{
"_index": "test",
"_type": "_doc",
"_id": "2",
"_score": 1.0,
"_source": {
"title": "互联网招聘",
"content": "招聘一名资深程序员"
}
},
{
"_index": "test",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"title": "互联网求职",
"content": "寻求一份运营的岗位"
}
},
{
"_index": "test",
"_type": "_doc",
"_id": "3",
"_score": 1.0,
"_source": {
"title": "实习生推荐",
"content": "本人资深Java开发,0薪酬免费给各大公司实习"
}
}
]
}
}以 title 作为条件进行搜索,搜索 title 中包含 “互联网” 的所有命中结果
GET: localhost:9200/test/_search?q=title:互联网返回结果:
{
"took": 87,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.8630463,
"hits": [
{
"_index": "test",
"_type": "_doc",
"_id": "2",
"_score": 0.8630463,
"_source": {
"title": "互联网招聘",
"content": "招聘一名资深程序员"
}
},
{
"_index": "test",
"_type": "_doc",
"_id": "1",
"_score": 0.8630463,
"_source": {
"title": "互联网求职",
"content": "寻求一份运营的岗位"
}
}
]
}
}以 content 作为条件进行搜索,搜索 content 中包含 “Java” 的所有命中结果
GET localhost:9200/test/_search?q=content:Java返回结果:
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.2876821,
"hits": [
{
"_index": "test",
"_type": "_doc",
"_id": "3",
"_score": 0.2876821,
"_source": {
"title": "实习生推荐",
"content": "本人资深Java开发,0薪酬免费给各大公司实习"
}
}
]
}
}搜索 title 和 content 中包含 “互联网” 的所有命中结果
GET: localhost:9200/test/_search请求头:
{
"query":{
"multi_match":{
"query":"互联网",
"fields":["title","content"]
}
}
}返回结果:
{
"took": 35,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 2.1307154,
"hits": [
{
"_index": "test",
"_type": "_doc",
"_id": "4",
"_score": 2.1307154,
"_source": {
"title": "吹水帖子",
"content": "互联网大牛就是我"
}
},
{
"_index": "test",
"_type": "_doc",
"_id": "2",
"_score": 1.9890311,
"_source": {
"title": "互联网招聘",
"content": "招聘一名资深程序员"
}
},
{
"_index": "test",
"_type": "_doc",
"_id": "1",
"_score": 0.8630463,
"_source": {
"title": "互联网求职",
"content": "寻求一份运营的岗位"
}
}
]
}
}Spring 整合 Elasticsearch
Maven dependency
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>在这里提供我的 demo 示例,我使用的 Spring Boot version 为 2.1.3.RELEASE
Elasticsearch 版本为 6.4.3
源代码地址:github.com/jinrunheng/low-version-...
参考文章
www.cnblogs.com/ottll/p/9470732.ht...
www.cnblogs.com/jpfss/p/11505845.h...
blog.csdn.net/duanduanpeng/article...
www.cnblogs.com/dennisit/p/4133131...
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



