
面试官:如何在开发阶段就尽量避免写出慢 SQL ?
9 / 7 / 创建于 4年前 /
 Luson 的个人博客
Luson 的个人博客
1. 当使用索引列进行查询的时候尽量不要使用表达式,把计算放到业务层而不是数据库层
如下图 两个sql的结果是一样的,但是两个sql的执行计划是不一样,在type中index的效率远不如const where条件中 actor_id+4 表达式影响了执行计划

2. 尽量使用主键查询,而不是其他索引,主键查询不会出现回表查询。
我们所有的表基本都会有主键的,所以平时开发中能用索引就用索引,能用主键索引就用主键索引。
3. 使用前缀索引
很多时候我们的索引其实都是字符串,不可避免会出现长字符串,就会导致索引占用过大,降低其效率。尤其是对于blob,text, varchar这样的长列。这时候处理方式就是不使用字段的全值作为索引,而是只取其前半部分即可(选择的这部分前缀索引的选择性接近于整个列)。这样可以大大减少索引空间,从而提高效率,坏处就是降低了索引的选择性。
索引选择性:不重复的索引值和数据表记录总数的比值(#T),范围从1/#T到1之间。索引的选择性越高查询效率也高,因为数据的区分度很高,可以过滤掉更多的行。唯一性索引的选择性是1,其性能也最好。
例如公司的员工表中邮箱字段,一个公司的邮箱后缀都是一样的如xxxx@qq.com, 其实用邮箱作为索引有效的就xxxx部分,因为@qq.com都是一样的,对索引是无意义的,明显只用xxxx作为索引,其选择性和整个值的是一样的,但是xxxx作为索引明显就会减少索引空间。
下面我们已employee表为例子(表结构和数据看文末)
我们以email字段建立索引为例:
这个数据的邮箱其实是手机号+@qq.com为例的,其实前11位后面都是相同的。我用下面的sql来看看这些数据的选择性(分别取前10,11,12)位计算。
-- 当是11个前缀的时候选择性是1,在增加字段长度,选择性也不会变化select count(distinct left(email,10))/count(*) as e10, count(distinct left(email,11))/count(*) as e11, count(distinctleft(email,12))/count(*) as e12 from employee;
复制代码
从上图我们可以看出前10,前11,前12的选择性分别是0.14,1.0,1.0 ,在第11位的时候索引选择性是最高的1,就没必要使用全部作为索引,增加了索引的空间。
-- 创建前缀索引
alter table employee add key(email(11));
复制代码我们也可以使用count计算频率来统计(出现的次数越少,说明重复率越低,选择性越大)
-- 查找前缀出现的频率
select count(*) as cnt,left(email,11) as pref from employee group by pref order by cnt desc limit 10;
复制代码
4.使用索引扫描来排序
我们经常会有排序的需求,使用order by 但是order by是比较影响性能的,它是通过把数据加载到内存去排序的,如果数据量很大内存放不下,只能分多次处理。但是索引本身就是有序的,直接通过索引完成排序更省事。
扫描索引本身是很快的,因为只需要从一条索引记录移动到紧接着的下一条记录,但如果索引不能覆盖查询所需的所有列时,就不得不每扫描一条索引记录就回表查询一次对应行,这基本都是随机IO。因此按索引顺序读取数据的速度通常比顺序的全表扫描慢。
mysql可以使用同一个索引即满足排序,又用于查找行。如果可以的话请考虑建立这种索引。
只有当索引列顺序和order by子句的顺序完全一致,并且所有列的排序方向(倒叙或者正序)都是一样的,mysql才能使用索引对结果做排序。如果查询需要关联多张表,只有当order by子句的字段全是第一张表时才能使用索引排序。order by 查询同时也需要满足组合索引的最左前缀,否则也不能使用索引排序。
其实在开发中主要注意两点:
- where条件中的字段和order by中的字段能够是组合索引而且满足最左前缀。
- order by中的字段的顺序需要一致,不能存在desc,又存在asc。
5. union all ,in,or都能够使用索引,但是推荐使用in

如上union all 会有两次执行,而in 和or只有一次。同时看出or和in的执行计划是一样的,
但是我们在看一下他们的执行时间。如下图使用set profiling=1可以看到详细时间,使用show profiles 查看具体时间。下图看出or的时间0.00612000,in的时间0.00022800,差距还是很大的(测试的表数据只有200行)
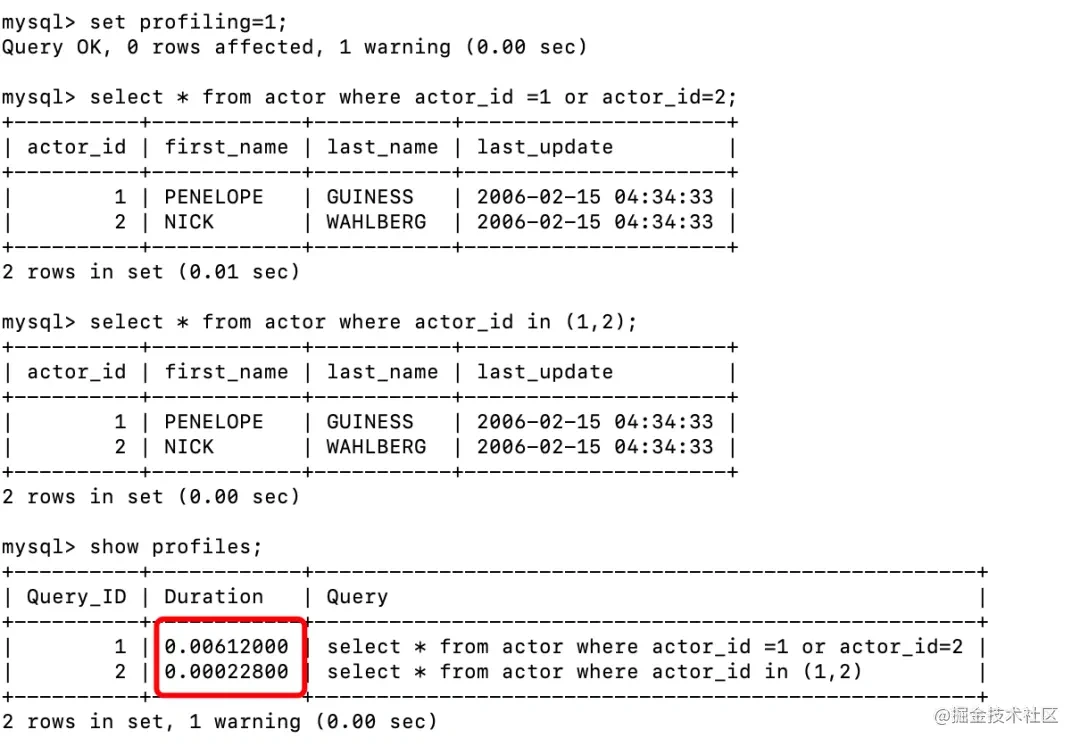
union all: 查询分为了两阶段,其实还有一个union,在平时开发中必须使用到union的时候推荐使用union all,因为union中多出了distinct去重的步骤。所以尽量用union all。
6. 范围列可以用到索引
范围的条件:>,>=,<,<=,between
范围列可以用到索引,但是范围列后面的列就无法用到索引了(索引最多用于一个范围列)
比如一个组合索引age+name 如果查询条件是where age>18 and name="纪"后面的name是用不到的索引的。
曾经面试被问到不等于是否能够走某个索引,平时没有注意过也没有回答成功,这次亲自做个实验,关于结论请看文末。
7. 强制类型转换会全表扫描
我在employee表中定义了mobile字段是varchar类型且建立索引,我分别用数字和字符串查询.
看看结果: 两者type是不一样的,而且只有字符串才用到索引。
如果条件的值的类型和表中定义的不一致,那么mysql会强制进行类型转换,但是结果是不会走索引,索引在开发中我们需要根据自己定义的类型输入对应的类型值。

8. 数据区分度不高,更新频繁的字段不宜建立索引
- 索引列更新会变更B+树的,频繁更新的会大大降低数据库性能。
- 类似于性别这类(只有男女,或者未知),不能有效过滤数据。
- 一般区分度在80%以上就可以建立索引,区分度可以使用count(distinct(列名))/count(*)
9. 创建索引的列不允许为null,可能会得到不符合预期的结果
也就是建立索引的字段尽量不要为空,可能会有些意想不到的问题,但是实际工作中也不太可能不为空,所以根据实际业务来处理吧,尽量避免这种情况。
10. 当需要进行表连接的时候,最好不要超过三张表
表连接其实就是多张表循环嵌套匹配,是比较影响性能的, 而且需要join的字段数据类型必须一致,提高查询效率。关于表连接原理后面专门写一篇吧。
11. 能使用limit的时候尽量使用limit。
limit的作用不是仅仅用了分页,本质作用是限制输出。
limit其实是挨个遍历查询数据,如果只需要一条数据添加 limit 1的限制,那么索引指针找到符合条件的数据之后就停止了,不会继续向下判断了,直接返回。如果没有limit,就会继续判断。
但是如果分页取1万条后的5条limit 10000,10005 就需要慎重了,他会遍历1万条之后取出5条,效率很低的。小技巧:如果主键是顺序的,可以直接通过主键获取分页数据。
12. 单表索引尽量控制在5个内
建立/维护索引也是需要代价的,也需要占用空间的。索引并不是越多越好,要合理使用索引。
13. 单个组合索引的字段个数不宜超过5个
字段越多,索引就会越大,占用的存储空间就越多。
索引并不是越多越好,而且索引并不需要在开始建表的时候就全部设计出来,过早优化反而不会是高效索引,需要在了解业务,根据相关业务sql做个统计权衡之后再去构建相关索引,这样考虑的更周全,建立的索引更有效和高效。
以上就是对应索引优化的小细节,希望能够帮助你写出嗖嗖的sql.
作者:纪先生
链接:juejin.cn/post/6997049092505337893
来源:掘金
本作品采用《CC 协议》,转载必须注明作者和本文链接





































 关于 LearnKu
关于 LearnKu




推荐文章: