
在MySQL中管理分层数据---邻接表模型和嵌套集模型
1 / 0 / 创建于 4年前
 hickey 的个人博客
hickey 的个人博客
背景
在我们的日常开发中,我们一定会接触到的一种数据就是分层数据。哪些是分层数据呢?业务组织结构图,内容管理类别,RBAC权限管理,产品类别等等,这些都是分层数据,以下是一个电子商店的产品类别层次结构:
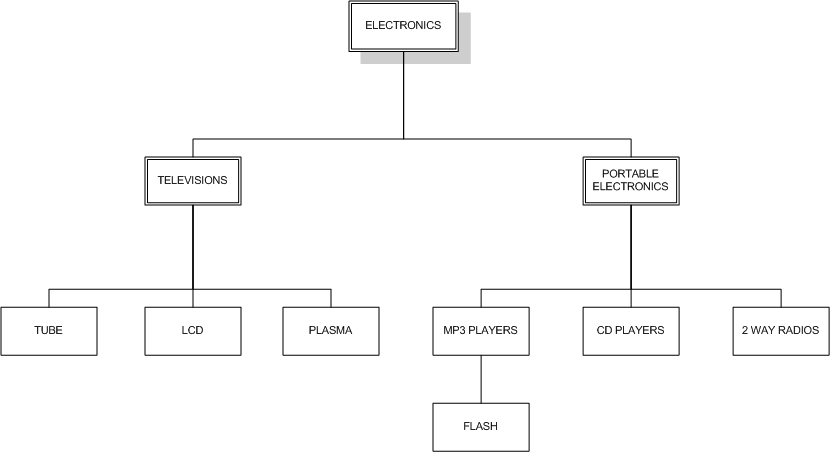
在本文中,我们将研究在 MySQL 中处理分层数据的两种模型,从传统的邻接表模型开始。
邻接表模型
通常,上面显示的示例类别将存储在如下表中(我把 CREATE 和 INSERT 语句都写下来,你可以跟着运行):
CREATE TABLE category(
category_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20) NOT NULL,
parent INT DEFAULT NULL
);
INSERT INTO category VALUES(1,'ELECTRONICS',NULL),(2,'TELEVISIONS',1),(3,'TUBE',2),
(4,'LCD',2),(5,'PLASMA',2),(6,'PORTABLE ELECTRONICS',1),(7,'MP3 PLAYERS',6),(8,'FLASH',7),
(9,'CD PLAYERS',6),(10,'2 WAY RADIOS',6);
SELECT * FROM category ORDER BY category_id;
+-------------+----------------------+--------+
| category_id | name | parent |
+-------------+----------------------+--------+
| 1 | ELECTRONICS | NULL |
| 2 | TELEVISIONS | 1 |
| 3 | TUBE | 2 |
| 4 | LCD | 2 |
| 5 | PLASMA | 2 |
| 6 | PORTABLE ELECTRONICS | 1 |
| 7 | MP3 PLAYERS | 6 |
| 8 | FLASH | 7 |
| 9 | CD PLAYERS | 6 |
| 10 | 2 WAY RADIOS | 6 |
+-------------+----------------------+--------+
10 rows in set (0.00 sec)在邻接表模型中,表中的每一项都包含一个指向其父项的指针。最上面的元素,在本例中是 ELECTRONICS ,其父元素是 NULL 值。邻接表模型的优点是比较简单,很容易看出 FLASH 是 MP3 PLAYERS 的子级,PORTABLE ELECTRONICS 的子级,ELECTRONICS 的子级。缺点也很明显,我们要查某个节点的所有上级或者是所有下级都是要递归的去查询的。如果某个业务场景下,分层的层数增加到很多并且叶子节点也在增多,那我们的查询就会变的很慢。这种我们也是可以优化的,就是将每个叶子节点之间的路径存储下来。但是这种方法会增加数据的存储量。那么有什么办法是可以的将我们的整个数存储在关系型数据库中的呢。\
嵌套集模型
在嵌套集模型中,我们可以以一种新的方式看待我们的层次结构,而不是作为节点和线,而是作为嵌套容器尝试以这种方式描绘我们的电子产品类别: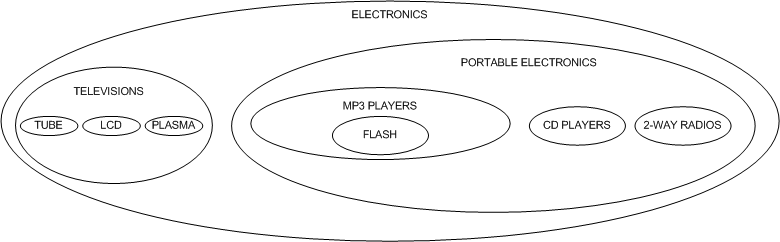
请注意我们的层次结构仍然维持着的的,因为父类别包围了它们的子类别。我们通过使用左右值来表示节点的嵌套,在表中表示这种形式的层次结构:
CREATE TABLE nested_category (
category_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20) NOT NULL,
lft INT NOT NULL,
rgt INT NOT NULL
);
INSERT INTO nested_category VALUES(1,'ELECTRONICS',1,20),(2,'TELEVISIONS',2,9),(3,'TUBE',3,4),
(4,'LCD',5,6),(5,'PLASMA',7,8),(6,'PORTABLE ELECTRONICS',10,19),(7,'MP3 PLAYERS',11,14),(8,'FLASH',12,13),
(9,'CD PLAYERS',15,16),(10,'2 WAY RADIOS',17,18);
SELECT * FROM nested_category ORDER BY category_id;
+-------------+----------------------+-----+-----+
| category_id | name | lft | rgt |
+-------------+----------------------+-----+-----+
| 1 | ELECTRONICS | 1 | 20 |
| 2 | TELEVISIONS | 2 | 9 |
| 3 | TUBE | 3 | 4 |
| 4 | LCD | 5 | 6 |
| 5 | PLASMA | 7 | 8 |
| 6 | PORTABLE ELECTRONICS | 10 | 19 |
| 7 | MP3 PLAYERS | 11 | 14 |
| 8 | FLASH | 12 | 13 |
| 9 | CD PLAYERS | 15 | 16 |
| 10 | 2 WAY RADIOS | 17 | 18 |
+-------------+----------------------+-----+-----+那么我们如何确定左右值呢?我们从外节点最左边开始编号,继续向右:
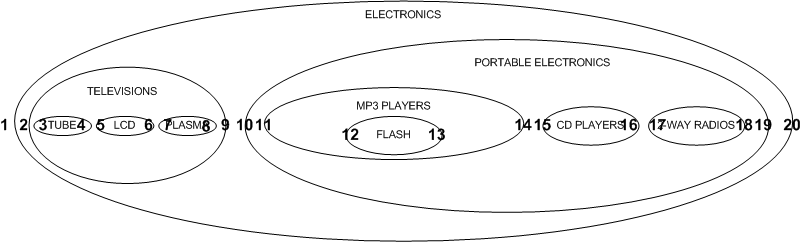
这种设计也可以应用于典型的树:
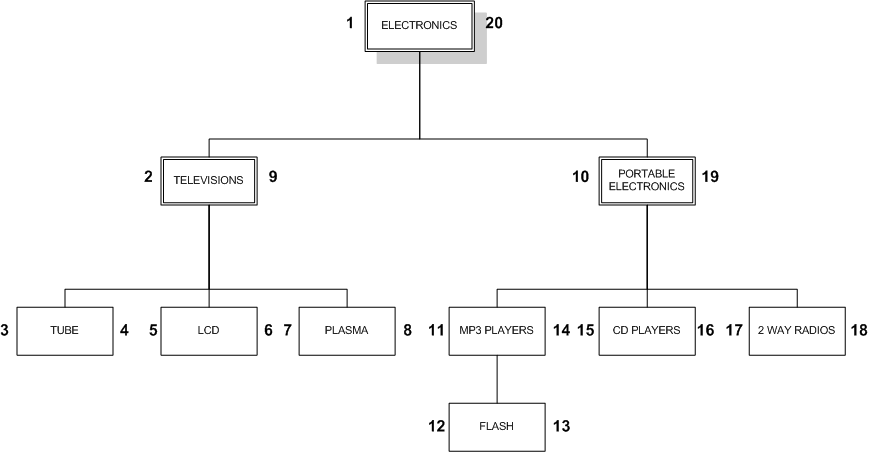
使用树时,我们从左到右,一次一层,在分配右手数字并向右移动之前下降到每个节点的子节点。这种方法称为前序树遍历算法。
检索完整的树
我们可以通过使用自连接来检索完整树,该自连接将父节点与节点连接起来,基于节点的 lft 值将始终出现在其父节点的 lft 和 rgt 值之间:
SELECT node.name
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND parent.name = 'ELECTRONICS'
ORDER BY node.lft;
+----------------------+
| name |
+----------------------+
| ELECTRONICS |
| TELEVISIONS |
| TUBE |
| LCD |
| PLASMA |
| PORTABLE ELECTRONICS |
| MP3 PLAYERS |
| FLASH |
| CD PLAYERS |
| 2 WAY RADIOS |
+----------------------+与我们之前使用邻接列表模型的示例不同,无论树的深度如何,此查询都将起作用。我们不关心 BETWEEN 子句中节点的 rgt 值,因为 rgt 值将始终与 lft 值在同一个父节点内。
参考
mikehillyer.com/articles/managing-h...
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



