
LotusDB 设计与实现—3 内存 memtable
0 / 1 / 创建于 4年前
 roseduan 的个人博客
roseduan 的个人博客
LotusDB 是一个全新的 KV 存储引擎,Github 地址:github.com/flower-corp/lotusdb,希望大家多多支持呀,点个 star 或者参与进来!
顾名思义,memtable 是内存中维护的组件,在 LSM Tree 存储模型中,memtable 相当于一块内存 buffer,数据写入到 WAL 后,然后在 memtable 中更新。memtable 的数据积累到一定的阈值之后,批量 Flush 到磁盘,这样做的目的是延迟写磁盘,并且将随机的 IO 写入转换为批量的顺序 IO,这也是 LSM 存储模型的核心思路。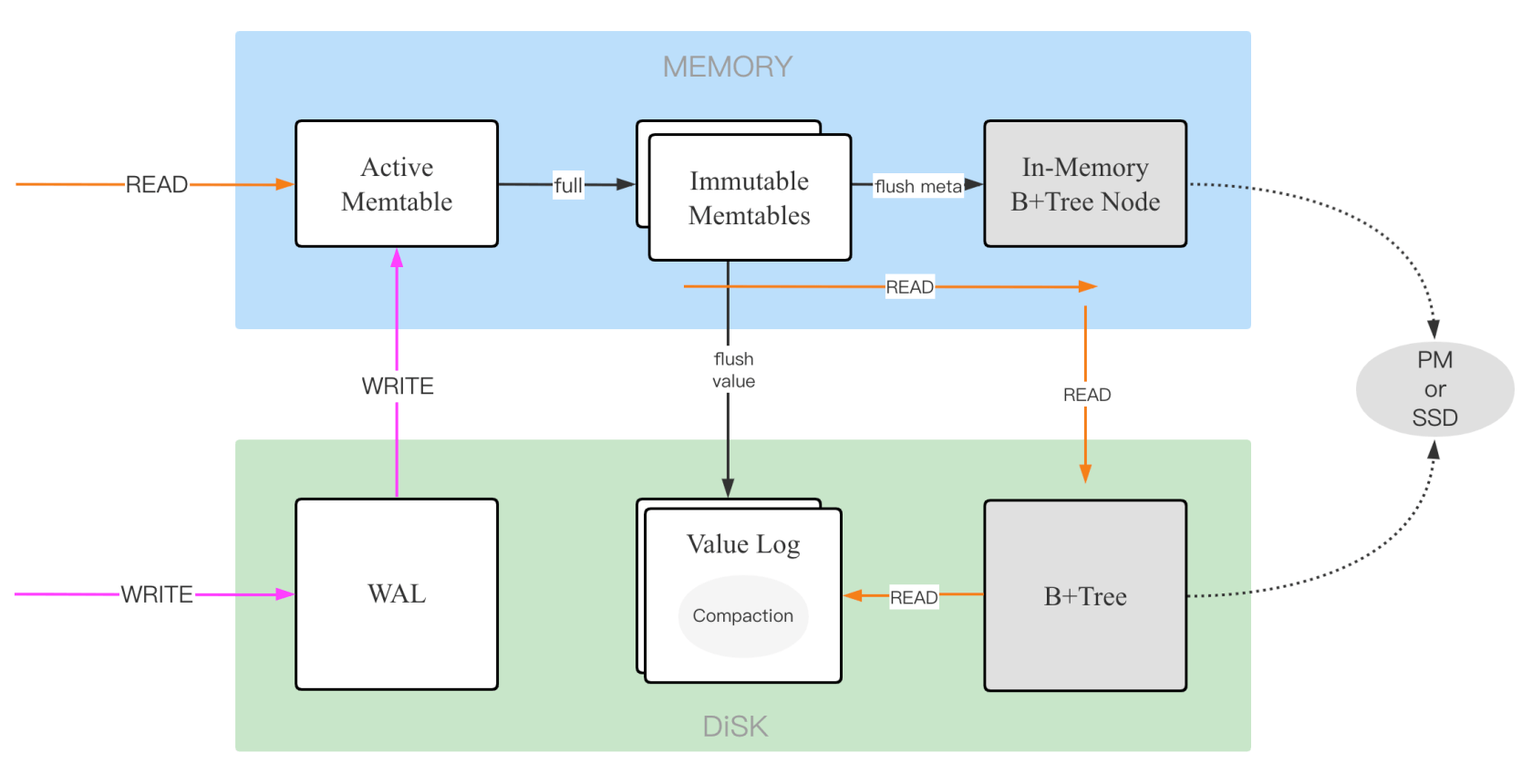
内存中的 memtable 一般会有多个,一个 memtable 写满之后,会转为不可变的 memtable,不可变的 memtable 不能接收新的写入,并且等待被后台线程 Flush 持久化到磁盘。
LotusDB 的一个 Column Family 结构体中,维护了最新的 memtable,记为 activeMem,以及不可变的 memtable 数组,即 immuMems。
Column Family 这个命名借鉴于 rocksdb,表示一个 key/value 的命名空间,可以理解为表的概念。
从 Column Family 的结构体定义中可以查看:
// ColumnFamily is a namespace of keys and values.
// Each key/value pair in LotusDB is associated with exactly one Column Family.
// If no Column Family is specified, key-value pair is associated with Column Family "cf_default".
// Column Families provide a way to logically partition the database.
type ColumnFamily struct {
// Active memtable for writing.
activeMem *memtable
// Immutable memtables, waiting to be flushed to disk.
immuMems []*memtable
// Value Log(Put value into value log according to options ValueThreshold).
vlog *valueLog
// Store keys and meta info.
indexer index.Indexer
// When the active memtable is full, send it to the flushChn, see listenAndFlush.
flushChn chan *memtable
flushLock sync.RWMutex // guarantee flush and compaction exclusive.
// ...
}当有数据写入时,需要判断当前 memtable 是否已满,如果已满,则将 memtable 存放到 immuMems 这个 slice 里面,然后将 memtable 通过 channel 发送,由 channel 的另一端进行 flush 工作。发送到 channel 之后,需要创建一个新的 memtable 做为 activeMem。
大致的逻辑如下代码:
func (cf *ColumnFamily) waitWritesMemSpace(size uint32) error {
// check whether memtable is full
if !cf.activeMem.isFull(size) {
return nil
}
timer := time.NewTimer(cf.opts.MemSpaceWaitTimeout)
defer timer.Stop()
select {
case cf.flushChn <- cf.activeMem:
cf.immuMems = append(cf.immuMems, cf.activeMem)
// open a new active memtable.
// ...
if table, err := openMemtable(memOpts); err != nil {
return err
} else {
cf.activeMem = table
}
case <-timer.C:
return ErrWaitMemSpaceTimeout
}
return nil
}如果当前 memtable 容量和数量都达到了最大值, 不可变的 memtable 还来不及 flush,这时候新的写入需要阻塞等待,等待的超时时间可以配置,默认是 100ms。
但实际上,这种情况发生的概率较低,只有在 memtable 阈值小、数量少,并且有大量写入的情况下才有可能发生,如果在写入的过程中遇到了类似 wait memtable space timeout 的错误,建议调大 memtable 的阈值,或者增加超时时间的配置。
需要注意在 memtable 中,如果是删除数据,那么实际上也是添加记录,并不会真正去执行删除,只是添加的记录加上了一个特殊的标记,一般称为墓碑值。
具体在 LotusDB 里面,添加记录操作的是 LogEntry 这个结构体,所以在里面加上了一个 Type 字段,标识这个 LogEntry 数据的类型,然后再添加到 memtable 中:
// put new writes to memtable.
func (mt *memtable) put(key []byte, value []byte, deleted bool, opts WriteOptions) error {
entry := &logfile.LogEntry{
Key: key,
Value: value,
}
if opts.ExpiredAt > 0 {
entry.ExpiredAt = opts.ExpiredAt
}
if deleted {
entry.Type = logfile.TypeDelete
}
// ....
}在 channel 的另一端(listenAndFlush 方法中),启动了一个 goroutine 进行监听,如果有新的 memtable 数据进来,则会开始 flush 操作。LotusDB 的 memtable 的具体数据结构采用的是跳表,所以就取出对应的跳表的迭代器,从头开始遍历跳表中的数据。
这里需要注意判断,如果 memtable 中的 key 被标记为删除或已过期的话,也需要记录一下,否则,则说明是有效的 key/value 数据,那么便会将数据追加写到 value log 中,获取到对应数据的索引信息,即文件 id 和位置偏移 offset。
for iter.SeekToFirst(); iter.Valid(); iter.Next() {
key := iter.Key()
node := &index.IndexerNode{Key: key}
mv := decodeMemValue(iter.Value())
// delete invalid keys from indexer.
if mv.typ == byte(logfile.TypeDelete) || (mv.expiredAt != 0 && mv.expiredAt <= time.Now().Unix()) {
deletedKeys = append(deletedKeys, key)
} else {
// wiret data into value log.
valuePos, esize, err := cf.vlog.Write(&logfile.LogEntry{
Key: key,
Value: mv.value,
ExpiredAt: mv.expiredAt,
})
if err != nil {
return err
}
node.Meta = &index.IndexerMeta{
Fid: valuePos.Fid,
Offset: valuePos.Offset,
EntrySize: esize,
}
nodes = append(nodes, node)
}
}遍历完 memtable 中的数据之后,再调用索引提供的方法,针对无效的数据进行批量删除,针对有效的数据进行批量添加,完成之后需要调用 Sync 方法持久化写入的内容,保证数据的一致性。
func (cf *ColumnFamily) flushUpdateIndex(nodes []*index.IndexerNode, keys [][]byte) error {
cf.flushLock.Lock()
defer cf.flushLock.Unlock()
// must put and delete in batch.
writeOpts := index.WriteOptions{SendDiscard: true}
if _, err := cf.indexer.PutBatch(nodes, writeOpts); err != nil {
return err
}
if len(keys) > 0 {
if err := cf.indexer.DeleteBatch(keys, writeOpts); err != nil {
return err
}
}
// must fsync before delete wal.
if err := cf.indexer.Sync(); err != nil {
return err
}
return nil
}Flush 完成之后,便会将 immuMems 这个数组中的 memtable 删除掉,给后续新的 memtable 空出位置。
memtable 相关的配置项:
ColumnFamilyOptions:
MemtableSize:一个 memtable 所占内存空间的阈值,默认 64MB
MemtableNums:最多可存在的 memtable 的数量,默认 5
MemSpaceWaitTimeout:等待 memtable 空闲空间的超时,默认 100ms
LotusDB Github 地址:github.com/flower-corp/lotusdb
本作品采用《CC 协议》,转载必须注明作者和本文链接







 关于 LearnKu
关于 LearnKu




推荐文章: