
全文检索技术lucene的demo
0 / 0 / 创建于 3年前 /
 meimengxing 的个人博客
meimengxing 的个人博客
lucene是一个基于Java的全文检索库,使用lucene能够创建全文索引和搜索,当数据量比较大的时候,比起传统的顺序搜索,索引搜索速度提升会非常明显。很多搜索引擎例如Elasticsearch 和 solor 都是以lucene为核心的。
全文检索
全文检索指的是,提前对文章或者文档中的每一个词建立索引,索引中包含该词在文章中出现的位置和次数,当用户查询时,根据事先建立好的索引进行查找,并返回查询结果。
这种建立索引,在通过搜索索引返回数据的方式就叫全文检索。
优点:
- 查询准确高。
- 查询速度快,不会随着数据量的增大而变得越来越慢。
缺点:
- 索引会占据磁盘存储空间
应用场景:
- 大量数据检索(贴吧,论坛,淘宝,京东)
- 搜索引擎 (google、baidu)
Lucene
Lucene是Apache旗下的一个开源全文检索引擎库,提供了完整了查询引擎和索引引擎。使用lucene可以在系统中实现全文检索功能,或者以此为基础构建一个全文检索引擎。
Lucene不是现成的搜索引擎产品,但确可以用来制作搜索引擎产品。
Lucene实现全文检索的流程
假如要为数据库中的数据库建立全文检索,大致的步骤如下:先获取到数据库中的数据库,对这批数据创建索引,索引存储在索引库中。当用户查询时,对索引库的索引进行查找,从而找到相对应的数据。
重点在于创建索引的这部分。创建索引时需要将数据构建为Lucene中的 文档对象,并对文档对象进行分析,最后创建索引
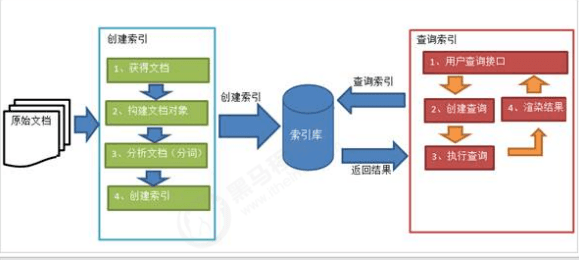
代码步骤如下:
1.创建索引:
- 获取数据
- 创建Document文档对象()
- 创建分词器
- 创建Directory对象,声明索引库存储位置
- 创建IndexWriterConfig配置信息类
- 创建IndexWriter写入对象
- 把Document写入到索引库中(底层自动创建索引)
- 关闭写入流
POJO类省略–
Dao层省略–
pom.xml 中引入依赖:
<!--lucene核心-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>7.7.2</version>
</dependency>
<!--lucene分词器-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>7.7.2</version>
</dependency>
<!--lucene查询解析-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>7.7.2</version>
</dependency>
<!--中文分词器-->
<dependency>
<groupId>org.wltea.ik-analyzer</groupId>
<artifactId>ik-analyzer</artifactId>
<version>8.1.0</version>
</dependency>测试类
创建索引:
/*###
创建索引:
* 获取数据
* 创建Document文档对象()
* 创建分词器
* 创建Directory对象,声明索引库存储位置
* 创建IndexWriterConfig配置信息类
* 创建IndexWriter写入对象
* 把Document写入到索引库中(底层自动创建索引)
*/
//创建全部索引
@Test
public void createIndex() throws IOException {
//获取原始数据
List<YxStoreProduct> skuList = yxStoreProductRepository.findAll();
//创建分词器
Analyzer analyzerIK = new IKAnalyzer();
//创建文档对象集合
List<Document> documents =new ArrayList<>();
for (YxStoreProduct sku : skuList) {
Document document = new Document();
document.add(new StringField("id",sku.getId().toString(), Field.Store.YES));
document.add(new TextField("store_name",sku.getStoreName(), Field.Store.YES));
document.add(new TextField("storeInfo",sku.getStoreInfo(), Field.Store.YES));
document.add(new TextField("price",sku.getPrice().toString(), Field.Store.YES));
documents.add(document);
}
Directory directory = FSDirectory.open(Paths.get("D:\\lucene\\indexDir"));
Directory directory2 = FSDirectory.open(Paths.get(msgIndex));
//创建IndexWriterConfig对象,写入索引需要的配置
IndexWriterConfig config = new IndexWriterConfig(analyzerIK);
//创建IndexWriter写入对象
IndexWriter indexWriter = new IndexWriter(directory2,config);
indexWriter.addDocuments(documents);
indexWriter.close();
}搜索索引:
@Test
public void searchIndex() throws Exception {
//创建分词器
Analyzer analyzerIK = new IKAnalyzer();
//创建Directory流对象,声明索引库位置
Directory directory = FSDirectory.open(Paths.get("D:\\yshop\\msgindex"));
//创建搜索解析器 第一个参数是指定默认搜索的field
QueryParser queryParser = new QueryParser("store_name",analyzerIK);
//创建搜索对象
Query query = queryParser.parse("商品");
//创建索引读取对象
IndexReader reader = DirectoryReader.open(directory);
//创建索引搜索对象
IndexSearcher searcher = new IndexSearcher(reader);
//使用索引搜索对象执行搜索
TopDocs topDocs =searcher.search(query,10);
System.out.println("查询到的数据总条数是:"+topDocs.totalHits);
//获取查询结果集
ScoreDoc[] docs = topDocs.scoreDocs;
//解析结果集:
for(ScoreDoc scoreDoc:docs){
//拿到文档id
int docID = scoreDoc.doc;
Document doc =searcher.doc(docID);
System.out.println("=============================");
System.out.println("docID:"+docID);
System.out.println("id:"+doc.get("id"));
System.out.println("store_name:"+doc.get("store_name"));
System.out.println("storeInfo:"+doc.get("storeInfo"));
System.out.println("price:"+doc.get("price"));
}
reader.close();
}结果展示: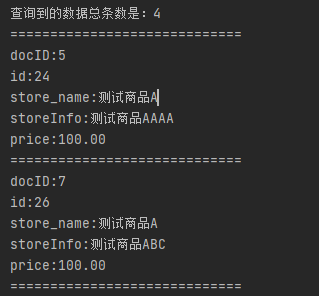
本作品采用《CC 协议》,转载必须注明作者和本文链接



 关于 LearnKu
关于 LearnKu



