
Elasticsearch学习总结
17 / 0 / 创建于 3年前
 iceymoss 的个人博客
iceymoss 的个人博客
[toc]
什么是Elasticsearch
在了解Elasticsearch之前我们需要了解:
1. mysql搜索面临的问题
- 性能低下
- 没有相关性排名 - 刚需
- 无法全文搜索
- 搜索不准确 - 没有分词
2. 什么是全文搜索
我们生活中的数据总体分为两种:结构化数据和非结构化数据。
- 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
- 非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等。
非结构化数据又一种叫法叫全文数据。
按照数据的分类,搜索也分为两种:
- 对结构化数据的搜索:如对数据库的搜索,用SQL语句。再如对元数据的搜索,如利用windows搜索对文件名,类型,修改时间进行搜索等。
- 对非结构化数据的搜索:如利用windows的搜索也可以搜索文件内容,Linux下的grep命令,再如用Google和百度可以搜索大量内容数据。
对非结构化数据也即对全文数据的搜索主要有两种方法:
一种是顺序扫描法(Serial Scanning):\所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。如利用windows的搜索也可以搜索文件内容,只是相当的慢。假如有一个80G硬盘,如果想在上面找到一个内容包含某字符串的文件,可能需要几个小时的时间。Linux下的grep命令也是这一种方式。这是一种比较原始的方法,但对于小数据量的文件,这种方法还是最直接,最方便的。但是对于大量的文件,这种方法的速度就很慢。
另一种是*全文检索(Full-text Search)*:即先建立索引,再对索引进行搜索。索引是从非结构化数据中提取出之后重新组织的信息。
3.什么是elasticsearch
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene™ 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
ES特点
- 可以作为一个大型的分布式集群(数百台服务器)技术,处理PB级数据,服务大公司,可以运行在单机上,服务小公司。
- ES不是什么新技术,主要是将全文检索、数据分析以及分布式技术合并在一起,才形成了独一无二的ES.lucene(全文检索)、商用的数据分析软件、分布式数据库 (mycat)
- 对用户而言,是开箱即用,非常简单,作为中小型的应用,直接3分钟部署ES,就可以作为生产环境的系统使用,数据量不大,操作不是很复杂。
- 数据库的功能面对很多领域是不够用的(事务,还有各种联机事务的操作):特殊的功能,比如全文检索、同义词处理、相关度排名、复杂数据分析、海量数据近实时处理;ES作为传统数据库的一个补充,提供了数据库所不能提供的很多功能。
es使用场景
- 维基百科
- The Guardian、新闻
- Stack Overflow
- Github
- 电商网站、检索商品
- 日志数据分析、logstash采集日志、ES进行复杂的数据分析(ELK)
- 商品价格监控网站、用户设定价格阈值
- BI系统、商业智能、ES执行数据分析和挖掘
ES的安装(docker安装)
在此之前需要保证您的计算机已经安装了docker
需要说明我们这里需要使用docker安装es和用于操作es的工具kibana
1. 关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
systemctl status firewalld.service2. 安装es
这里我们安装 es7.10.1
#新建es的config配置文件夹 注意:这里/data/elasticsearch/config位置在可随意
mkdir -p /data/elasticsearch/config
#新建es的data目录 注意:这个文件夹使用来存放es中我们要存储和使用的真实数据
mkdir -p /data/elasticsearch/data
#新建es的plugins目录
mkdir -p /data/elasticsearch/plugins
#给目录设置权限
chmod 777 -R /data/elasticsearch
#写入配置到elasticsearch.yml中, 下面的 > 表示覆盖的方式写入, >>表示追加的方式写入,但是要确保http.host: 0.0.0.0不能被写入多次
echo "http.host: 0.0.0.0" >> /data/elasticsearch/config/elasticsearch.yml
#安装es 注意: -e ES_JAVA_OPTS="-Xms128m -Xmx256m"可根据自己设备存储来配置大小
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms128m -Xmx256m" \
-v /data/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /data/elasticsearch/data:/usr/share/elasticsearch/data \
-v /data/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.10.13.安装kibana
注意:kibana的版本需要和es的版本一致
docker run -d --name kibana -e ELASTICSEARCH_HOSTS="http://192.168.0.104:9200" -p 5601:5601 kibana:7.10.1安装完成后可以使用
docker ps查看两个容器是否启动成功
在浏览器中访问:localhost:9200/ 返回:
{
name: "a44962f20eeb",
cluster_name: "elasticsearch",
cluster_uuid: "QTexyRC2QN27xs-FgrsKZg",
version: {
number: "7.10.1",
build_flavor: "default",
build_type: "docker",
build_hash: "1c34507e66d7db1211f66f3513706fdf548736aa",
build_date: "2020-12-05T01:00:33.671820Z",
build_snapshot: false,
lucene_version: "8.7.0",
minimum_wire_compatibility_version: "6.8.0",
minimum_index_compatibility_version: "6.0.0-beta1"
},
tagline: "You Know, for Search"
}es安装成功
访问:http://localhost::5601就可以使用kibana
接下来我们就使用kibana对es进行操作
查询:
GET _cat/indices kibana操作es
下面我们来做一个对比
| mysql | es |
|---|---|
| database | |
| table | index(7.x开始type为固定值_doc) |
| row | document |
| column | field |
| schema | mapping |
| sql | DSL(Descriptor Structure Laguage) |
查看索引
GET _cat/indices //查看所有索引
GET /account //查看index下的的基本信息插入数据:
1.put方法写入
以put方法写入,需要指定id,该id不存在则创建,存在则更新
PUT account/_doc/1
{
"name":"ice_moss",
"age":18,
"company":[
{
"name":"alibaba1"
},
{
"name":"alibaba2"
}
]
}同一个请求发送多次,下面的信息会产生变化
"_version" : 11,
"result" : "updated", #这里第一次是created,后续都是updated
"_seq_no" : 10, #版本号关于 _version和_seq_no的区别和作用请参考官方文档
2. 发送post不带id新建数据
POST user/_doc/
{
"name":"bobby"
}
POST user/_doc/2
{
"name":"bobby"
}如果post带id就和put一样的操作了, put是不允许不带id的
3.post + _create
没有就创建,有就报错
POST user/_create/1
{
"name":"bobby"
}查询数据
GET user/_doc/1
#返回
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1",
"_version" : 5,
"_seq_no" : 5,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "ice_moss"
}
}只返回source的值
GET user/_source/1
#返回
{
"name" : "ice_moss"
}搜索数据
官方文档
Elasticsearch有两种查询方式
1. URI带有查询条件(轻量查询)
查询能力有限,不是所有的查询都可以使用此方式
2. 请求体中带有查询条件(复杂查询)
查询条件以JSON格式表现,作为查询请求的请求体,适合复杂的查询 通过url查询数据
请求参数位于_search端点之后,参数之间使用&分割,例如:
GET /_search?pretty&q=title:azure&explain=true&from=1&size=10&sort=title:asc&fields:user,title,content搜索API的最基础的形式是没有指定任何查询的空搜索,它简单地返回集群中所有索引下的所有文档。
所有索引下符合条件的数据
- 通过request body查询数据
GET account/_search
{
"query": {
"match_all": {}
}
}GET _search?q=ice_moss
#返回所有索引下符合条件的数据
{
"took" : 29,
"timed_out" : false,
"_shards" : {
"total" : 9,
"successful" : 9,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 0.18232156,
"hits" : [
{
"_index" : "account",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.18232156,
"_source" : {
"name" : "ice_moss",
"age" : 18,
"company" : [
{
"name" : "alibaba1"
},
{
"name" : "alibaba2"
}
]
}
},
{
"_index" : "account",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.18232156,
"_source" : {
"name" : "ice_moss",
"age" : 18,
"company" : [
{
"name" : "alibaba1"
},
{
"name" : "alibaba2"
}
]
}
},
{
"_index" : "user",
"_type" : "_doc",
"_id" : "7qHZfoMBIFNOh3Zq_5d5",
"_score" : 0.18232156,
"_source" : {
"name" : "ice_moss",
"age" : 18,
"company" : [
{
"name" : "Tencent",
"address" : "beijing"
},
{
"name" : "Alibaba",
"address" : "hangzhou"
}
]
}
},
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.18232156,
"_source" : {
"name" : "ice_moss"
}
}
]
}
}- 指定索引下查询
GET user/_search?q=ice_moss
#返回
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.18232156,
"hits" : [
{
"_index" : "user",
"_type" : "_doc",
"_id" : "7qHZfoMBIFNOh3Zq_5d5",
"_score" : 0.18232156,
"_source" : {
"name" : "ice_moss",
"age" : 18,
"company" : [
{
"name" : "Tencent",
"address" : "beijing"
},
{
"name" : "Alibaba",
"address" : "hangzhou"
}
]
}
},
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.18232156,
"_source" : {
"name" : "ice_moss"
}
}
]
}
}新增数据
1.给已有的数据新增字段
POST users/_doc/1
{
"age":18
}此时会发现,已有的数据的name字段没有了,只有age字段
此时我们需要使用
POST user/_update/1
{
"doc": {
"age":18
}
}2. 删除数据和索引
DELETE users/_doc/1
DELETE users
4. 批量插入
批量插入数据 各个语句不相互影响,具有独立性
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }实例:
POST _bulk
{ "index" : { "_index" : "user", "_id" : "1" } }
{ "name" : "ice_moss1", "age":19 }
{ "index" : { "_index" : "user", "_id" : "2" } }
{ "name" : "ice_moss1", "age":19 }
{ "delete" : { "_index" : "user", "_id" : "2" } }批量获取(mget)
GET /_mget
{
"docs": [
{
"_index": "my-index-000001",
"_id": "1"
},
{
"_index": "my-index-000001",
"_id": "2"
}
]
}实例:
#_mget批量查询
GET /_mget
{
"docs": [
{
"_index": "user",
"_id": "1"
},
{
"_index": "account",
"_id": "1"
}
]
}全文查询 - 分词
1. match查询(匹配查询)
match:模糊匹配,需要指定字段名,但是输入会进行分词,比如”hello world”会进行拆分为hello和world,然后匹配,如果字段中包含hello或者world,或者都包含的结果都会被查询出来,也就是说match是一个部分匹配的模糊查询。查询条件相对来说比较宽松。
GET user/_search
{
"query": {
"match": {
"address": "street"
}
}
}2. match_phrase查询 短语查询
官方文档match_phase:会对输入做分词,但是需要结果中也包含所有的分词,而且顺序要求一样。以”hello world”为例,要求结果中必须包含hello和world,而且还要求他们是连着的,顺序也是固定的,hello that word不满足,world hello也不满足条件。
GET user/_search
{
"query": {
"match_phrase": {
"address": "Madison street"
}
}
}3. multi_match查询
官方文档multi_match查询提供了一个简便的方法用来对多个字段执行相同的查询,即对指定的多个字段进行match查询
POST resume/_doc/12
{
"title": "后端工程师",
"desc": "多年go语言开发经验, 熟悉go的基本语法, 熟悉常用的go语言库",
"want_learn":"python语言"
}
POST resume/_doc/13
{
"title": "go工程师",
"desc": "多年开发经验",
"want_learn":"java语言"
}
POST resume/_doc/14
{
"title": "后端工程师",
"desc": "多年开发经验",
"want_learn":"rust语言"
}
GET resume/_search
{
"query": {
"multi_match": {
"query": "go",
"fields": ["title", "desc"]
}
}
}
#返回
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.2576276,
"hits" : [
{
"_index" : "resume",
"_type" : "_doc",
"_id" : "12",
"_score" : 1.2576276,
"_source" : {
"title" : "后端工程师",
"desc" : "多年go语言开发经验, 熟悉go的基本语法, 熟悉常用的go语言库",
"want_learn" : "python语言"
}
},
{
"_index" : "resume",
"_type" : "_doc",
"_id" : "13",
"_score" : 1.0417082,
"_source" : {
"title" : "go工程师",
"desc" : "多年开发经验",
"want_learn" : "java语言"
}
}
]
}
}4.query_string查询
官方文档query_string:和match类似,但是match需要指定字段名,query_string是在所有字段中搜索,范围更广泛。
GET user/_search
{
"query": {
"query_string": {
"default_field": "address",
"query": "Madison AND street"
}
}
} 又或者:
GET user/_search
{
"query": {
"query_string": {
"default_field": "address",
"query": "Madison OR street"
}
}
}match_all查询所有数据
GET user/_search
{
"query": {
"match_all": {}
}
}term 级别查询
1. term查询(精确查找)
term: 这种查询和match在有些时候是等价的,比如我们查询单个的词hello,那么会和match查询结果一样,但是如果查询”hello world”,结果就相差很大,因为这个输入不会进行分词,就是说查询的时候,是查询字段分词结果中是否有”hello world”的字样,而不是查询字段中包含”hello world”的字样,elasticsearch会对字段内容进行分词,“hello world”会被分成hello和world,不存在”hello world”,因此这里的查询结果会为空。这也是term查询和match的区别。
GET user/_search
{
"query": {
"term": {
"address": "madison street"
}
}
}2. range查询 - 范围查询
GET user/_search
{
"query":{
"range": {
"age": {
"gte": 20,
"lte": 30
}
}
}
}3. exists查询
查询指定字段
GET user/_search
{
"query": {
"exists": {
"field": "school"
}
}
}
代码块123456784. fuzzy模糊查询
这种查询我们在使用百度或者其他搜索引擎时经常用到,例如:搜索”golang”但是打成了”golan”,这样也会拿到我们要的结果
GET user/_search
{
"query": {
"match": {
"address": {
"query": "Midison streat",
"fuzziness": 1
}
}
}
}复合查询
官方文档
Elasticsearch bool查询对应Lucene BooleanQuery, 格式如下
{
"query":{
"bool":{
"must":[
],
"should":[
],
"must_not":[
],
"filter":[
],
}
}
}must: 必须匹配,查询上下文,加分
should: 应该匹配,查询上下文,加分
must_not: 必须不匹配,过滤上下文,过滤
filter: 必须匹配,过滤上下文,过滤bool查询采用了一种匹配越多越好的方法,因此每个匹配的must或should子句的分数将被加在一起,以提供每个文档的最终得分
实例:
GET user/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"state":"tn"
}
},
{
"range": {
"age": {
"gte": 20,
"lte": 30
}
}
}
],
"must_not": [
{
"term": {
"gender":"f"
}
}
],
"should": [
{
"match": {
"firstname" : "Vera"
}
}
],
"filter": [
{
"range": {
"age": {
"gte": 25,
"lte": 30
}
}
}
]
}
}
}
#返回
{
"took" : 10,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 4.6700764,
"hits" : [
{
"_index" : "user",
"_type" : "_doc",
"_id" : "343",
"_score" : 4.6700764,
"_source" : {
"account_number" : 343,
"balance" : 37684,
"firstname" : "Robbie",
"lastname" : "Logan",
"age" : 29,
"gender" : "M",
"address" : "488 Linden Boulevard",
"employer" : "Hydrocom",
"email" : "robbielogan@hydrocom.com",
"city" : "Stockdale",
"state" : "TN"
}
},
{
"_index" : "user",
"_type" : "_doc",
"_id" : "283",
"_score" : 4.6700764,
"_source" : {
"account_number" : 283,
"balance" : 24070,
"firstname" : "Fuentes",
"lastname" : "Foley",
"age" : 30,
"gender" : "M",
"address" : "729 Walker Court",
"employer" : "Knowlysis",
"email" : "fuentesfoley@knowlysis.com",
"city" : "Tryon",
"state" : "TN"
}
},
{
"_index" : "user",
"_type" : "_doc",
"_id" : "923",
"_score" : 4.6700764,
"_source" : {
"account_number" : 923,
"balance" : 48466,
"firstname" : "Mueller",
"lastname" : "Mckee",
"age" : 26,
"gender" : "M",
"address" : "298 Ruby Street",
"employer" : "Luxuria",
"email" : "muellermckee@luxuria.com",
"city" : "Coleville",
"state" : "TN"
}
}
]
}
}什么是 Mapping?
在一篇文章带你搞定 ElasticSearch 术语中,我们讲到了 Mapping 类似于数据库中的表结构定义 schema,它有以下几个作用:
定义索引中的字段的名称定义字段的数据类型,比如字符串、数字、布尔字段,倒排索引的相关配置,比如设置某个字段为不被索引、记录 position 等在 ES 早期版本,一个索引下是可以有多个 Type ,从 7.0 开始,一个索引只有一个 Type,也可以说一个 Type 有一个 Mapping 定义。
在了解了什么是 Mapping 之后,接下来对 Mapping 的设置做下介绍:
Mapping 设置
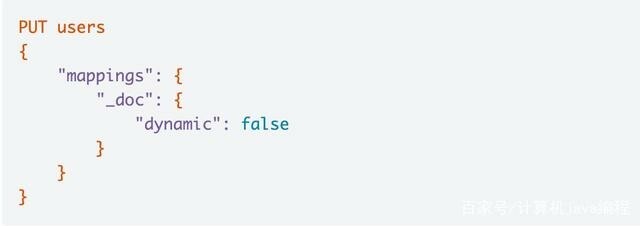
在创建一个索引的时候,可以对 dynamic 进行设置,可以设成 false、true 或者 strict。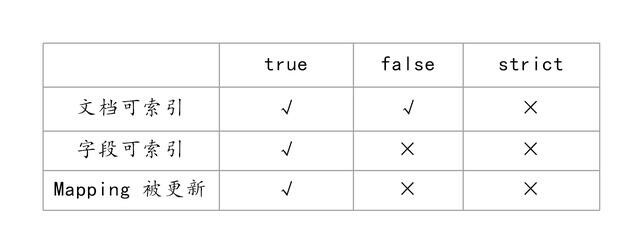
比如一个新的文档,这个文档包含一个字段,当 Dynamic 设置为 true 时,这个文档可以被索引进 ES,这个字段也可以被索引,也就是这个字段可以被搜索,Mapping 也同时被更新;当 dynamic 被设置为 false 时候,存在新增字段的数据写入,该数据可以被索引,但是新增字段被丢弃;当设置成 strict 模式时候,数据写入直接出错。
另外还有 index 参数,用来控制当前字段是否被索引,默认为 true,如果设为 false,则该字段不可被搜索。
参数 index_options 用于控制倒排索引记录的内容,有如下 4 种配置:
doc:只记录 doc id
freqs:记录 doc id 和 term frequencies
positions:记录 doc id、term frequencies 和 term position
offsets:记录 doc id、term frequencies、term position 和 character offects
另外,text 类型默认配置为 positions,其他类型默认为 doc,记录内容越多,占用存储空间越大。
null_value 主要是当字段遇到 null 值时的处理策略,默认为 NULL,即空值,此时 ES 会默认忽略该值,可以通过设定该值设定字段的默认值,另外只有 KeyWord 类型支持设定 null_value。
copy_to 作用是将该字段的值复制到目标字段,实现类似 _all 的作用,它不会出现在 _source 中,只用来搜索。
除了上述介绍的参数,还有许多参数,大家感兴趣的可以在官方文档中进行查看。
在学习了 Mapping 的设置之后,让我们来看下字段的数据类型有哪些吧!
字段数据类型
ES 字段类型类似于 MySQL 中的字段类型,ES 字段类型主要有:核心类型、复杂类型、地理类型以及特殊类型,具体的数据类型如下图所示: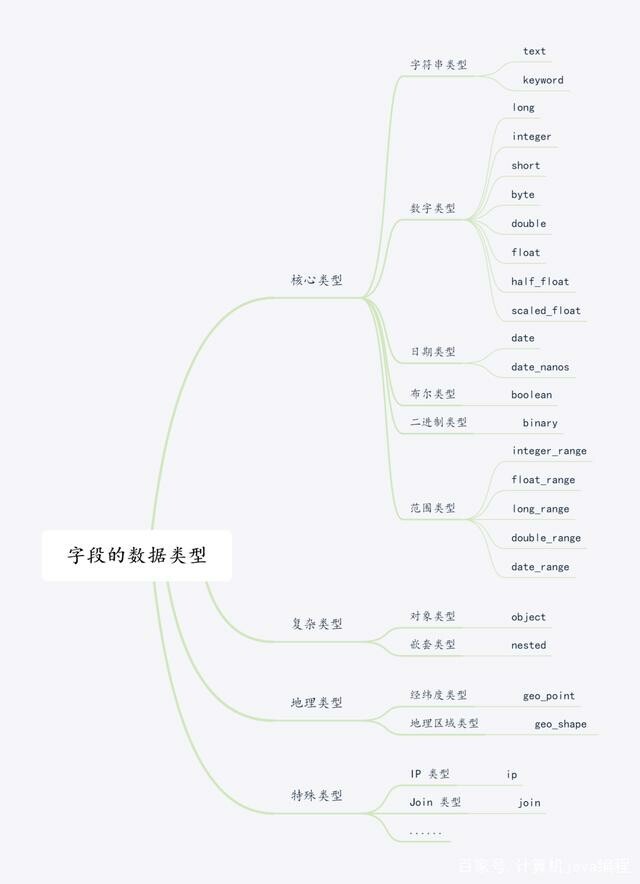
核心类型
从图中可以看出核心类型可以划分为字符串类型、数字类型、日期类型、布尔类型、基于 BASE64 的二进制类型、范围类型。
字符串类型
其中,在 ES 7.x 有两种字符串类型:text 和 keyword,在 ES 5.x 之后 string 类型已经不再支持了。
text 类型适用于需要被全文检索的字段,例如新闻正文、邮件内容等比较长的文字,text 类型会被 Lucene 分词器(Analyzer)处理为一个个词项,并使用 Lucene 倒排索引存储,text 字段不能被用于排序,如果需要使用该类型的字段只需要在定义映射时指定 JSON 中对应字段的 type 为 text。
keyword 适合简短、结构化字符串,例如主机名、姓名、商品名称等,可以用于过滤、排序、聚合检索,也可以用于精确查询。
数字类型
数字类型分为 long、integer、short、byte、double、float、half_float、scaled_float。
数字类型的字段在满足需求的前提下应当尽量选择范围较小的数据类型,字段长度越短,搜索效率越高,对于浮点数,可以优先考虑使用 scaled_float 类型,该类型可以通过缩放因子来精确浮点数,例如 12.34 可以转换为 1234 来存储。
日期类型
在 ES 中日期可以为以下形式:
格式化的日期字符串,例如 2020-03-17 00:00、2020/03/17
时间戳(和 1970-01-01 00:00:00 UTC 的差值),单位毫秒或者秒即使是格式化的日期字符串,ES 底层依然采用的是时间戳的形式存储。
布尔类型
JSON 文档中同样存在布尔类型,不过 JSON 字符串类型也可以被 ES 转换为布尔类型存储,前提是字符串的取值为 true 或者 false,布尔类型常用于检索中的过滤条件。
二进制类型
二进制类型 binary 接受 BASE64 编码的字符串,默认 store 属性为 false,并且不可以被搜索。
范围类型
范围类型可以用来表达一个数据的区间,可以分为5种:
integer_range、float_range、long_range、double_range 以及 date_range。
复杂类型
复合类型主要有对象类型(object)和嵌套类型(nested):
对象类型
JSON 字符串允许嵌套对象,一个文档可以嵌套多个、多层对象。可以通过对象类型来存储二级文档,不过由于 Lucene 并没有内部对象的概念,ES 会将原 JSON 文档扁平化,例如文档:
实际上 ES 会将其转换为以下格式,并通过 Lucene 存储,即使 name 是 object 类型:
嵌套类型
嵌套类型可以看成是一个特殊的对象类型,可以让对象数组独立检索,例如文档:
username 字段是一个 JSON 数组,并且每个数组对象都是一个 JSON 对象。如果将 username 设置为对象类型,那么 ES 会将其转换为:
可以看出转换后的 JSON 文档中 first 和 last 的关联丢失了,如果尝试搜索 first 为 wu,last 为 xy 的文档,那么成功会检索出上述文档,但是 wu 和 xy 在原 JSON 文档中并不属于同一个 JSON 对象,应当是不匹配的,即检索不出任何结果。
嵌套类型就是为了解决这种问题的,嵌套类型将数组中的每个 JSON 对象作为独立的隐藏文档来存储,每个嵌套的对象都能够独立地被搜索,所以上述案例中虽然表面上只有 1 个文档,但实际上是存储了 4 个文档。
地理数据
地理类型字段分为两种:经纬度类型和地理区域类型:
经纬度类型
经纬度类型字段(geo_point)可以存储经纬度相关信息,通过地理类型的字段,可以用来实现诸如查找在指定地理区域内相关的文档、根据距离排序、根据地理位置修改评分规则等需求。
地理区域类型
经纬度类型可以表达一个点,而 geo_shape 类型可以表达一块地理区域,区域的形状可以是任意多边形,也可以是点、线、面、多点、多线、多面等几何类型。
特殊类型
特殊类型包括 IP 类型、过滤器类型、Join 类型、别名类型等,在这里简单介绍下 IP 类型和 Join 类型,其他特殊类型可以查看官方文档。
IP 类型
IP 类型的字段可以用来存储 IPv4 或者 IPv6 地址,如果需要存储 IP 类型的字段,需要手动定义映射:
Join 类型
Join 类型是 ES 6.x 引入的类型,以取代淘汰的 _parent 元字段,用来实现文档的一对一、一对多的关系,主要用来做父子查询。
Join 类型的 Mapping 如下:
其中,my_join_field 为 Join 类型字段的名称;relations 指定关系:question 是 answer 的父类。
例如定义一个 ID 为 1 的父文档: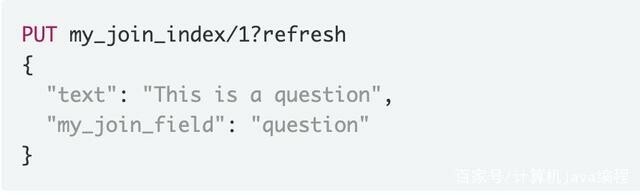
接下来定义一个子文档,该文档指定了父文档 ID 为 1:
再了解完字段数据类型后,再让我们看下什么是 Dynamic Mapping?
什么是 Dynamic Mapping?
Dynamic Mapping 机制使我们不需要手动定义 Mapping,ES 会自动根据文档信息来判断字段合适的类型,但是有时候也会推算的不对,比如地理位置信息有可能会判断为 Text,当类型如果设置不对时,会导致一些功能无法正常工作,比如 Range 查询。
类型自动识别
ES 类型的自动识别是基于 JSON 的格式,如果输入的是 JSON 是字符串且格式为日期格式,ES 会自动设置成 Date 类型;当输入的字符串是数字的时候,ES 默认会当成字符串来处理,可以通过设置来转换成合适的类型;如果输入的是 Text 字段的时候,ES 会自动增加 keyword 子字段,还有一些自动识别如下图所示: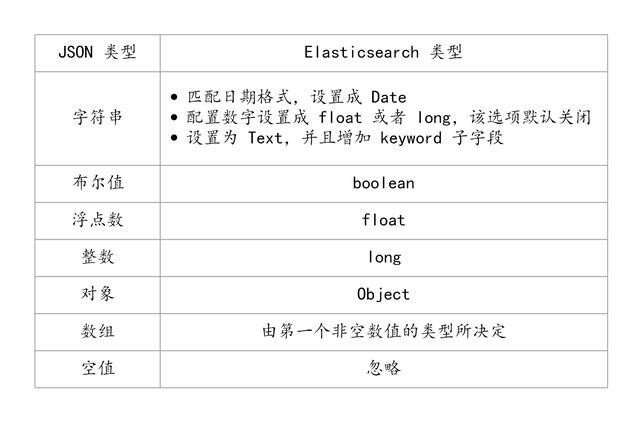
下面我们通过一个例子是看看是怎么类型自动识别的,输入如下请求,创建索引: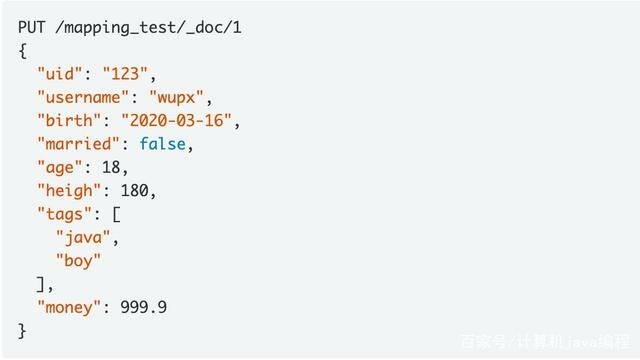
然后使用 GET /mapping_test/_mapping 查看,结果如下图所示: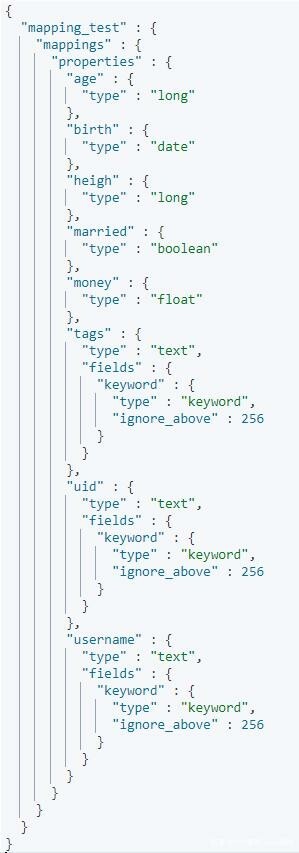
可以从结果中看出,ES 会根据文档信息自动推算出合适的类型。
哦豁,万一我想修改 Mapping 的字段类型,能否更改呢?让我们分以下两种情况来探究下:
修改 Mapping 字段类型?
如果是新增加的字段,根据 Dynamic 的设置分为以下三种状况:
当 Dynamic 设置为 true 时,一旦有新增字段的文档写入,Mapping 也同时被更新。
当 Dynamic 设置为 false 时,索引的 Mapping 是不会被更新的,新增字段的数据无法被索引,也就是无法被搜索,但是信息会出现在 _source 中。
当 Dynamic 设置为 strict 时,文档写入会失败。
另外一种是字段已经存在,这种情况下,ES 是不允许修改字段的类型的,因为 ES 是根据 Lucene 实现的倒排索引,一旦生成后就不允许修改,如果希望改变字段类型,必须使用 Reindex API 重建索引。
不能修改的原因是如果修改了字段的数据类型,会导致已被索引的无法被搜索,但是如果是增加新的字段,就不会有这样的影响。
Elasticsearch 中文本分析Analysis是把全文本转换成一系列的单词(term/token)的过程,也叫分词。文本分析是使用分析器 Analyzer 来实现的,Elasticsearch内置了分析器,用户也可以按照自己的需求自定义分析器。
为了提高搜索准确性,除了在数据写入时转换词条,匹配 Query 语句时候也需要用相同的分析器对查询语句进行分析。
Analyzer 的组成
Analyzer 由三部分组成:Character Filters、Tokenizer、Token Filters
Character Filters
Character Filters字符过滤器接收原始文本text的字符流,可以对原始文本增加、删除字段或者对字符做转换。一个Analyzer 分析器可以有 0-n 个按顺序执行的字符过滤器。
**
Tokenizer
Tokenizer 分词器接收Character Filters输出的字符流,将字符流分解成的那个的单词,并且输出单词流。例如空格分词器会将文本按照空格分解,将 “Quick brown fox!” 转换成 [Quick, brown, fox!]。分词器也负责记录每个单词的顺序和该单词在原始文本中的起始和结束偏移 offsets 。
一个Analyzer 分析器有且只有 1个分词器。
Token Filters
Token Filter单词过滤器接收分词器 Tokenizer 输出的单词流,可以对单词流中的单词做添加、移除或者转换操作,例如 lowercase token filter会将单词全部转换成小写,stop token filter会移除 the、and 这种通用单词, synonym token filter会往单词流中添加单词的同义词。<br /> Token filters不允许改变单词在原文档的位置以及起始、结束偏移量。
一个Analyzer 分析器可以有 0-n 个按顺序执行的单词过滤器。
**
**
Elasticsearch内置的分词器
Standard Analyzer - 默认分词器,按词切分,小写处理
Simple Analyzer - 按照非字母切分(符号被过滤),小写处理
Stop Analyzer - 小写处理,停用词过滤(the ,a,is)
Whitespace Analyzer - 按照空格切分,不转小写
Keyword Analyzer - 不分词,直接将输入当做输出
Patter Analyzer - 正则表达式,默认 \W+
Language - 提供了 30 多种常见语言的分词器
例子:The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone.
Standard Analyzer
- 默认分词器
- 按词分类
- 小写处理
#standard
GET _analyze
{
"analyzer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[the,2,quick,brown,foxes,a,jumped,over,the,lazy,dog’s,bone]
Simple Analyzer
- 按照非字母切分,非字母则会被去除
- 小写处理
#simpe
GET _analyze
{
"analyzer": "simple",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[the,quick,brown,foxes,jumped,over,the,lazy,dog,s,bone]
Stop Analyzer
- 小写处理
- 停用词过滤(the,a, is)
GET _analyze
{
"analyzer": "stop",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[quick,brown,foxes,jumped,over,lazy,dog,s,bone]
Whitespace Analyzer
- 按空格切分
#stop
GET _analyze
{
"analyzer": "whitespace",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[The,2,QUICK,Brown-Foxes,jumped,over,the,lazy,dog’s,bone.]
Keyword Analyzer
- 不分词,当成一整个 term 输出
#keyword
GET _analyze
{
"analyzer": "keyword",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone.]
Patter Analyzer
- 通过正则表达式进行分词
- 默认是 \W+(非字母进行分隔)
GET _analyze
{
"analyzer": "pattern",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[the,2,quick,brown,foxes,jumped,over,the,lazy,dog,s,bone]
Language Analyzer
支持语言:arabic, armenian, basque, bengali, bulgarian, catalan, czech, dutch, english, finnish, french, galician, german, hindi, hungarian, indonesian, irish, italian, latvian, lithuanian, norwegian, portuguese, romanian, russian, sorani, spanish, swedish, turkish.
#english
GET _analyze
{
"analyzer": "english",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
代码块123456输出:
[2,quick,brown,fox,jump,over,the,lazy,dog,bone]
中文分词要比英文分词难,英文都以空格分隔,中文理解通常需要上下文理解才能有正确的理解,比如 [苹果,不大好吃]和
[苹果,不大,好吃],这两句意思就不一样。
常用的插件分词器
IK Analyzer - 对中文分词友好,支持远程词典热更新,有ik_smart 、ik_max_word 两种分析器
pinyin Analyzer - 可以对中文进行拼音分析,搜索时使用拼音即可搜索出来对应中文
ICU Analyzer - 提供了 Unicode 的支持,更好的支持亚洲语言
hanLP Analyzer - 基于NLP的中文分析器
注:博客大部分内容来自慕课网Bobby老师
本作品采用《CC 协议》,转载必须注明作者和本文链接














 关于 LearnKu
关于 LearnKu



