
透视内存中数据
1 / 0 / 创建于 3年前 /
 悲剧不上演 的个人博客
悲剧不上演 的个人博客
透视内存数据
我们通过实践来看下数据在内存中存储的样子。不必在乎语言。
整数
整数分为正整数和负整数,数字在内存中以补码的形式存储。我们先不去了解什么是补码,我们来看两个示例。
正整数
存储 x = 30 的流程:
- 计算其原码: x 的二进制
0001 1110, 则该值为原码。 - 计算其补码:
0001 1110 - 计算机保存的就是该值
我们已经知道了流程,下来我们需要通过程序来验证下是否存储的该值。
// bin.go
package main
import "fmt"
func main() {
var x uint8 = 30
fmt.Println(&x)
}
下来我们通过 GDB 进行调试确认下。
// 编译 go 程序
$ go build bin.go
// 进入 go 程序
$ gdb bin
// 输出代码内容
(gdb) list
1 package main
2
3 import "fmt"
4
5 func main() {
6 var x uint8 = 30
7 fmt.Println(&x)
8 }
9
// 7 line 打印断点
(gdb) b 7
Breakpoint 1 at 0x47e00a: file /go/bin.go, line 7.
// 运行
(gdb) r
Starting program: /go/./bin
Breakpoint 1, main.main () at /go/bin.go:7
7 fmt.Println(&x)
// 执行下一条执行
(gdb) n
0xc000136000
// 从内存 0xc000136000 开始读取10个单位, 单位为 b (字节), t 表示以二进制展示
(gdb)x/10tb 0xc000136000
0xc000136000: 00011110 00000000 00000000 00000000 00000000 00000000 00000000 00000000
0xc000136008: 00000000 00000000
可以看到在 go 程序中存储为 0001 1110。与我们预期不谋而合。
负整数
存储 y = -30 的流程:
计算机用最高位存放符号,这个 bit 一般叫做符号位。 正数的符号位为 0, 负数的符号位为 1。
计器原码:x 的二进制
1001 1110计算器补码:
1110 0010原码: 1001 1110 反码:1110 0001 1 ------------------------------- 补码:1110 0010计算机存储
我们已经知道了流程,下来我们需要通过程序来验证下是否存储的该值。
package main
import "fmt"
func main() {
var y int16 = -30
fmt.Println(&y)
}
下来我们通过 GDB 进行调试确认下。
// 编译 go 程序
$ go build bin2.go
// 进入 go 程序
$ gdb bin2
// 输出代码内容
(gdb) list
(gdb) list
1 package main
2
3 import "fmt"
4
5 func main() {
6 var y int16 = -30
7 fmt.Println(&y)
8 }
9
10
// 7 line 打印断点
(gdb) b 7
Breakpoint 1 at 0x47e00a: file /go/bin.go, line 7.
// 运行
(gdb) r
Starting program: /go/./bin2
Breakpoint 1, main.main () at /go/bin2.go:7
7 fmt.Println(&x)
// 执行下一条执行
(gdb) n
0xc0000140c0
// 从内存 0xc000136000 开始读取10个单位, 单位为 b (字节), t 表示以二进制展示
(gdb) x/10tb 0xc0000140c0
0xc0000140c0: 11100010 11111111 00000000 00000000 00000000 00000000 00000000 00000000
0xc0000140c8: 00000000 00000000
可以看到 y 存储的 -30 在内存中的存储为 1110 0010, 与我们预期一致。至于后面为啥是 0xff ,我还不知道,有知道的同学可以看看。
字符
关于字符是如何在内存中存储的,这就要引出一个概念:字符集。
字符集
字符集:所谓字符集其实是一套编码规范中的子概念,为了显示字符,国际组织就制定了编码规范,希望使用不同的二进制数来表示代表不同的字符,这样电脑就可以根据二进制数来显示其对应的字符。我们通常就称呼其为XX编码,XX字符集。
白话文:就是将字符映射到二进制数字的规则。如 ACSII 中 M => 0x4E => 78 =>0100 1110。既然知道了二进制,那我们当然知道了内存其实就是存储该二进制数值
单字节
存储单字符就很简单,都是存储的ACSII 表中的对应的值。 如 h = 0110 1000
| 二进制 | 八进制 | 十进制 | 十六进制 | 缩写/字符 | 解释 |
|---|---|---|---|---|---|
| 0110 1000 | 0150 | 104 | 0x68 | h | 小写字母h |
下来我们通过程序来验证下
package main
import "fmt"
func main() {
var z byte = 'h'
fmt.Println(&z)
}// 编译 go 程序
$ go build bin4.go
// 进入 go 程序
$ gdb bin4
// 输出代码内容
(gdb) list
3 import "fmt"
4
5 func main() {
6 var z byte = 'h'
7 fmt.Println(&z)
8 }
10
// 7 line 打印断点
(gdb) b 7
Breakpoint 1 at 0x47e00a: file /go/bin4.go, line 7.
// 运行
(gdb) r
Starting program: /go/./bin4
Breakpoint 1, main.main () at /go/bin4.go:7
7 fmt.Println(&z)
// 执行下一条执行
(gdb) n
0xc0000be000
// 从内存 0xc0000be000 开始读取10个单位, 单位为 b (字节), t 表示以二进制展示
(gdb) x/10bt 0xc0000be000
0xc0000be000: 01101000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
0xc0000be008: 00000000
与预期一致。
单字符
单字符就是无法使用 ACSII 表示的字符,如汉字。因此需要使用 Unicode 来表示。
| 字符 | 编码10进制 | 编码16进制 | Unicode编码10进制 | Unicode编码16进制 |
|---|---|---|---|---|
| 繁 | 15186305 | E7B981 | 32321 | 7E41 |
下来我们通过程序来验证下
package main
import "fmt"
func main() {
var z rune = '繁'
fmt.Println(&z)
}$ go build bin5.go
$ gdb bin5
(gdb) start
Temporary breakpoint 1 at 0x47dfe0: file /go/bin5.go, line 5.
Starting program: /go/bin5
Temporary breakpoint 1, main.main () at /go/bin5.go:5
5 func main() {
(gdb) n
6 var z rune = '繁'
(gdb) n
7 fmt.Println(&z)
(gdb) n
0xc000126000
8 }
(gdb) x/10bx 0xc000126000
0xc000126000: 0x41 0x7e 0x00 0x00 0x00 0x00 0x00 0x00
0xc000126008: 0x00 0x00可以看到内存中存储的是 0x417E,而表中却展示的是 0x7E41。这是由于大小端序导致的。我们稍后在聊聊大小端,可以看到也是基本符合我们预期的。
字符串
字符串就是多个字符的集合,我们可以知道它的开始位置,但是程序怎么知道它的结束位置呢。
C:用\0的方式来表示,不会限制字符串内容,缺点无法直接存储\0,否则会出现异常.
#include <stdio.h> int main() { char string[] = "hello"; printf("%s\n", str); printf("%x\n", &str); //通过字符串名字输出 return 0; }$ gcc -g hello.c -o hello $ gdb hello (gdb) list 1 #include <stdio.h> 2 int main(){ 3 char str[] = "hello"; 4 printf("%s\n", str); //通过字符串名字输出 5 printf("%x\n", &str); //通过字符串名字输出 6 return 0; 7 } 8 (gdb) b 5 Breakpoint 1 at 0x40057e: file hello.c, line 5. (gdb) run Starting program: /go/./hello hello Breakpoint 1, main () at hello.c:5 5 printf("%x\n", &str); //通过字符串名字输出 Missing separate debuginfos, use: debuginfo-install glibc-2.17-260.el7_6.4.x86_64 (gdb) p &str $3 = (char (*)[6]) 0x7fffffffe4a0 (gdb) x/10bx 0x7fffffffe4a0 0x7fffffffe4a0: 0x68 0x65 0x6c 0x6c 0x6f 0x00 0x00 0x00 0x7fffffffe4a8: 0x00 0x00可以看到
0x68= h0x65= e0x6c= l0x6c= l0x6f= o
GO:会添加一个标时len来存储全部字节的长度。不会限制字符串内容。可以看起源码。
// reflect.StringHeader: type StringHeader struct { Data uintptr Len int }
小数
使用浮点格式存储小数。
浮点型
浮点型就是实数的意思。任意一个实数都是表示为:一个整数 乘以 某个基数(计算机中是2)的整数次幂。这种表示方法类似于科学计数法。
在内存中表示:符号位 + 指数位 + 小数位 组成。存储 var x float32 = 19.625 的流程:
将浮点数转换成二进制:如下图计算结果为
10011.101用科学计数法表示二进制浮点数: 如下图结果为
1.0011101 *2^4计算指数偏移后的值:
①:阶码的计算公式:
阶数 + 偏移量。②:偏移量的计算公式:
2^(e-1)-1float 32: 偏移量的计算公式:
2^(8-1)-1 = 127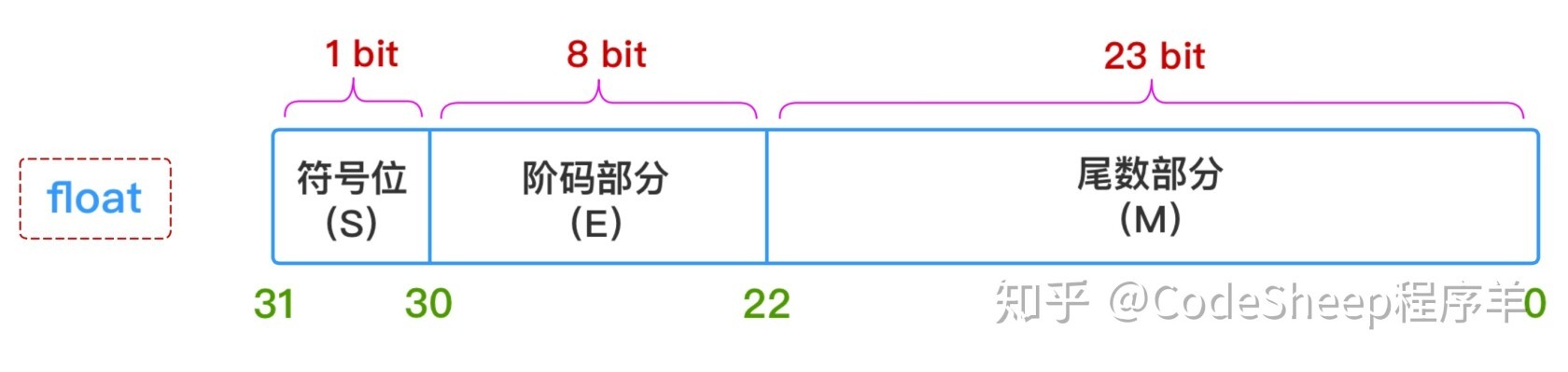
float 64: 偏移量的计算公式:
2^(11-1)-1 = 1023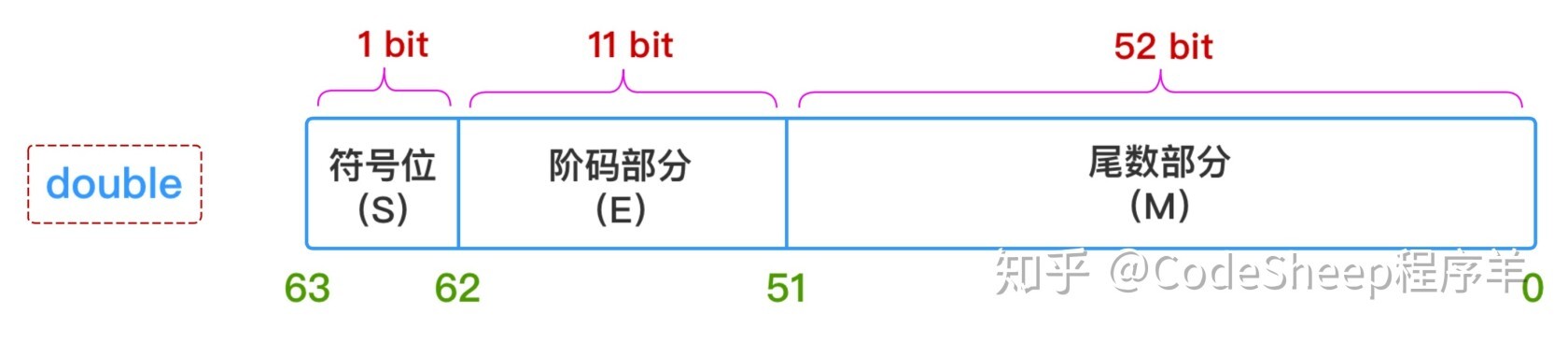
③:如下图阶码值为: 127+4=131= 1000 0011
- 填充到相应的比特位。
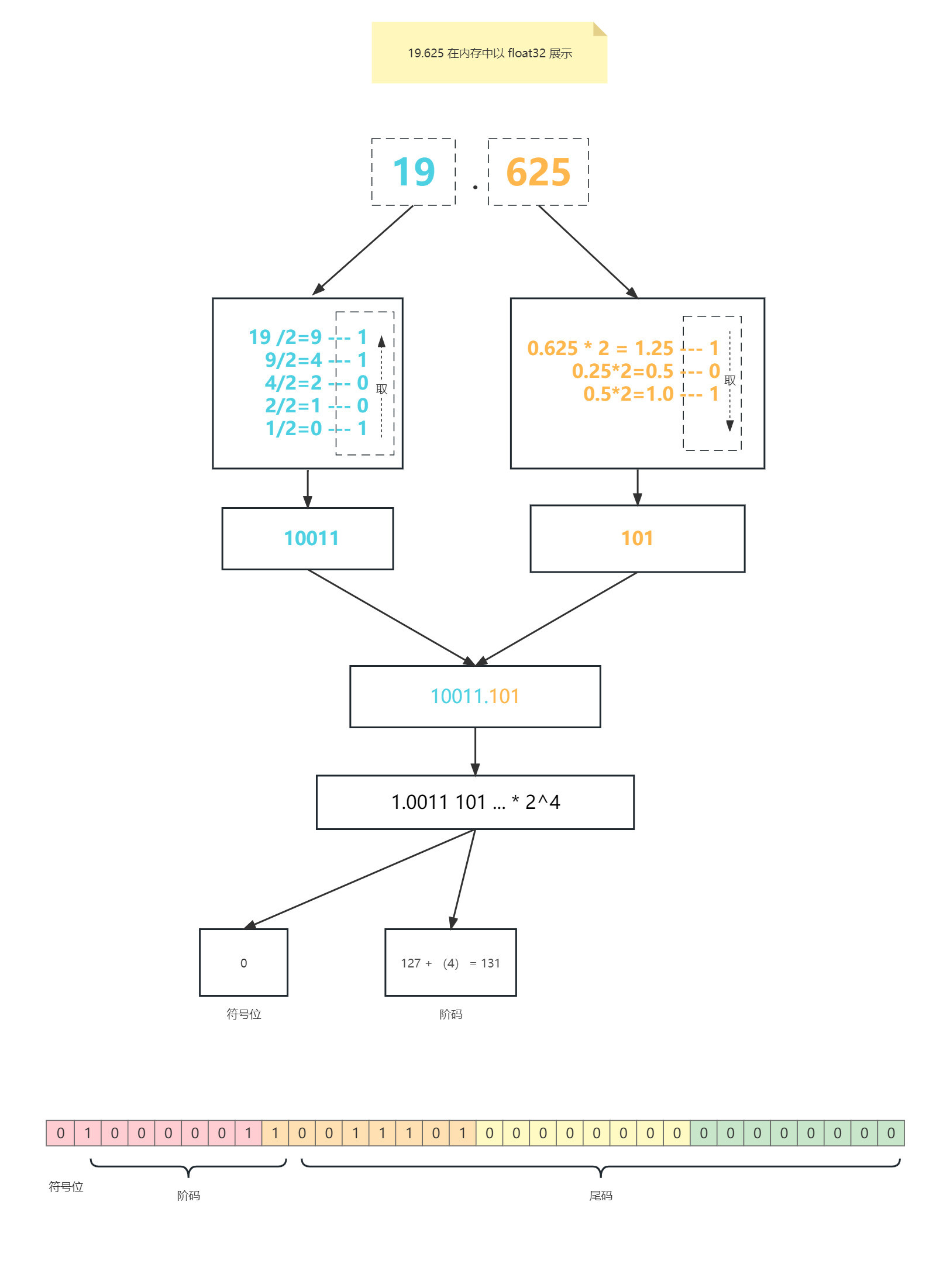
程序校验
package main
import "fmt"
func main() {
var data float32 = 19.625
fmt.Println(&data)
}$ go build bin6.go
$ gdb bin6
(gdb) start
Temporary breakpoint 1 at 0x47dfe0: file /go/bin6.go, line 5.
Starting program: /go/bin6
Temporary breakpoint 1, main.main () at /go/bin6.go:5
5 func main() {
(gdb) n
6 var data float32 = 19.625
(gdb) n
8 fmt.Println(&data)
(gdb) n
0xc000136000
9 }
(gdb) x/10bt 0xc000136000
0xc000136000: 00000000 00000000 10011101 01000001 00000000 00000000 00000000 00000000
0xc000136008: 00000000 00000000可以看到它和我们预期的顺序是相反的,这由是由于字节序的问题。OK,那我们接下来就说说大小端字节序。
字节序
大于一字节的数据在内存中存放的顺序。是在跨平台和,时常要考虑的问题。分为大端序和小端序。
- 大端序:高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。与字节顺序相同。
- 小端序:低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。与字节顺序相反。
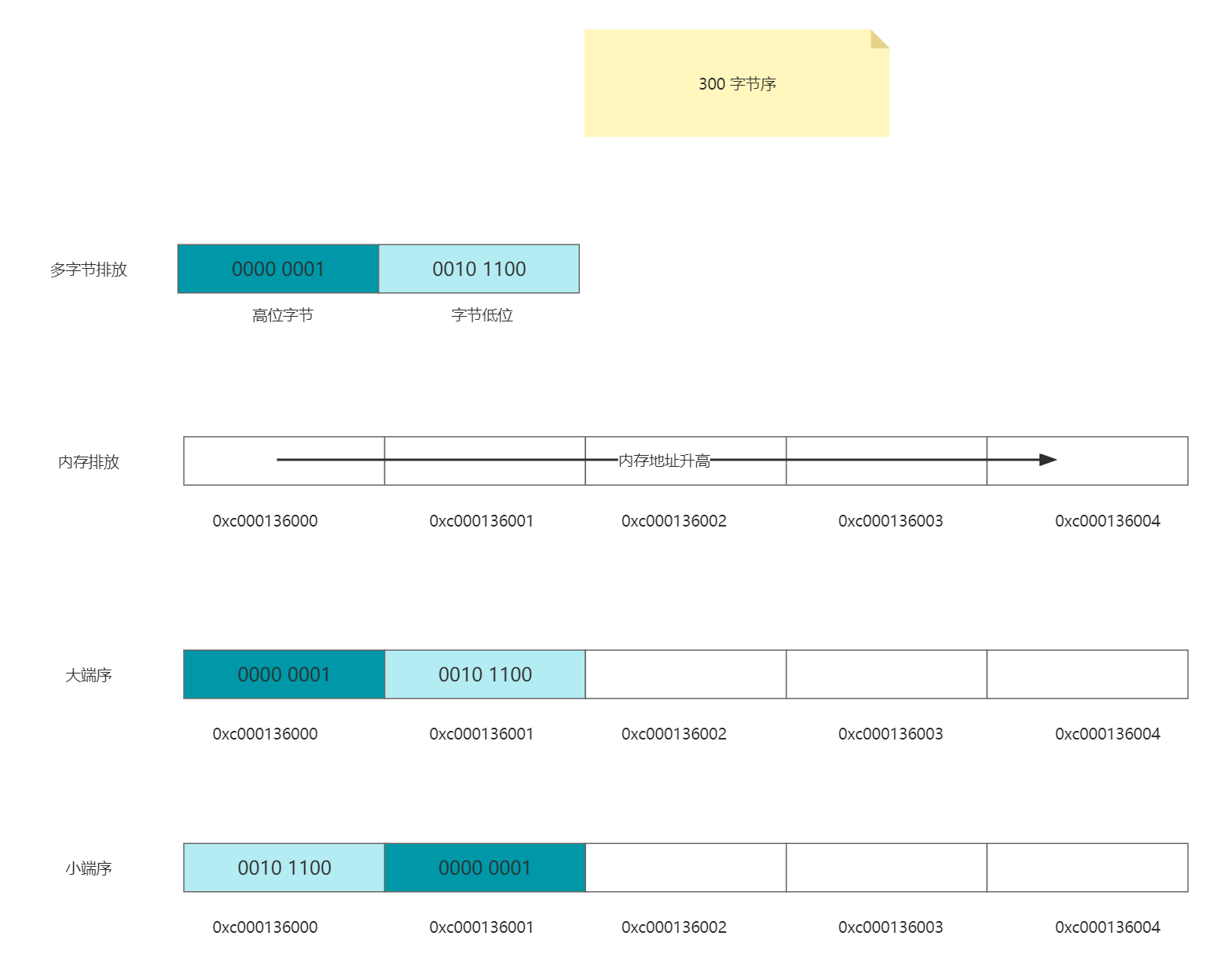
程序验证
查看电脑字节序
$ lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 8 On-line CPU(s) list: 0-7 Thread(s) per core: 2 Core(s) per socket: 4 Socket(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 158 Model name: Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz Stepping: 9 CPU MHz: 3599.998 BogoMIPS: 7199.99 Hypervisor vendor: Microsoft Virtualization type: full L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 8192K Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single pti ssbd ibrs ibpb stibp fsgsbase bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap clflushopt xsaveopt xsavec xgetbv1 xsaves flush_l1d arch_capabilities
go 程序判断
package main import "fmt" func main() { var w int16 = 300 fmt.Println(&w) }$ go build bin8.go $ gdb ./bin8 (gdb) start Temporary breakpoint 1 at 0x47dfe0: file /go/bin8.go, line 5. Starting program: /go/./bin8 Temporary breakpoint 1, main.main () at /go/bin8.go:5 5 func main() { (gdb) n 6 var w int16 = 300 (gdb) n 8 fmt.Println(&w) (gdb) n 0xc0000be000 9 } (gdb) x/10bx 0xc0000be000 0xc0000be000: 0x2c 0x01 0x00 0x00 0x00 0x00 0x00 0x00 0xc0000be008: 0x00 0x00 (gdb) x/10bt 0xc0000be000 0xc0000be000: 00101100 00000001 00000000 00000000 00000000 00000000 00000000 00000000 0xc0000be008: 00000000 00000000 (gdb)符合我们预期是小端序。我们可以回头看看我们上面的两个关于字节序的问题,就会恍然大悟。
我们已经把基本的数据类型在内存中已经查看了。至于补码怎么计算,大家百度即可。附上参考链接
参考链接
本作品采用《CC 协议》,转载必须注明作者和本文链接







 关于 LearnKu
关于 LearnKu




推荐文章: