
学习swoole之前,你需要知道的几件事
51 / 13 / 创建于 3年前
 cl_echo 的个人博客
cl_echo 的个人博客
学习swoole需要的前置知识
学习一项新的技术,最重要的就why、what、how。
这门技术是什么,为什么用它,要怎么用它。这篇文档的作用就是为了解释what与why。
php-fpm与swoole的异同
常驻内存
一个请求通过nginx转发到php来运行,中间是通过php-fpm来沟通连接的,通过一种叫cgi的协议来通信。
在php-fpm还未出现之前,php一般都是通过php-cgi这个php官方组件来与web server进行通信的,它的特点是每次运行都需要重新加载一次php.ini中的配置,并且每有一个请求都会重新启动一个进程来执行,执行完毕后再销毁掉。
这种方式每次都会重新解析php.ini、重新载入全部扩展,并重新初始化全部数据结构,这无疑是对cpu性能的浪费行为,于是就出现了fast cgi。
fast cgi的应用体现便是php-fpm。通过一个master进程管理多个worker进程的方式,在主进程启动时便将php.ini中的配置等信息载入内存,worker进程创建时会继承master进程的数据,并且worker进程处理完一个请求后不会销毁,而是继续等待下一个请求。所以只需要一次加载,php.ini与扩展和初始化数据这部分的性能便被节省出来了。虽然php.ini的配置初始化被节省掉了,但是我们平时使用的laravel等php开发框架中同样有冗长的ioc容器初始化,依赖创建的过程,这个问题php-fpm就无能为力了。
那么说完了php-fpm,这些和swoole又有什么关系呢?相同点就在于,swoole也是常驻内存的,也是一个master管理多个worker进程,所以也节省掉了多次载入php.ini等配置的消耗。
并且,由于swoole本身就是一个PHP扩展,它的启动是在php脚本内开始的,因此可以看做是php开发框架的一部分,那么php框架初始化的那一系列重复初始化便同样被节省掉了。这便是swoole高性能的原因。
swoole在宣传上写的是为了解决传统php-fpm模式并发慢的问题而诞生的,那么就带来一个问题:
php-fpm模式为什么慢?
php-fpm模式是以多进程方式来运行的,一个master进程创建并管理多个work进程。master进程只负责接收请求和返回响应,剩下的运行工作交给work进程来执行。
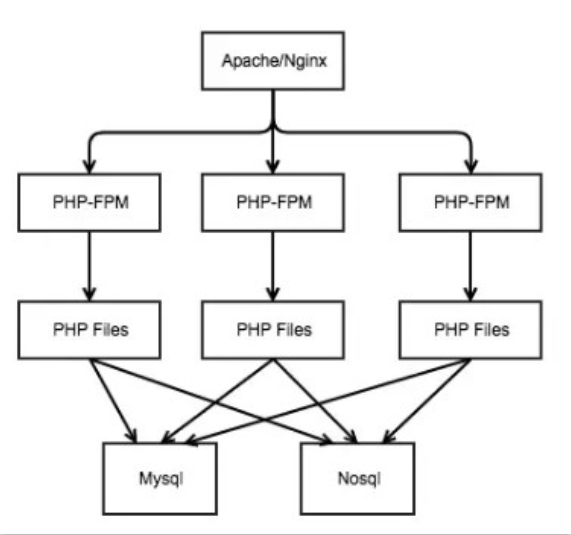
也就是说每一个请求都对应一个work进程,同一时刻,服务器上有多少work进程,这台服务器就可以处理多少的并发。
这么一看是不是觉得php-fpm的并发能力特别差?假设不考虑服务器配置问题,默认的400个进程数同时就只能支持400的并发。
实际情况肯定没有这么差,假设很多的脚本只需要0.001秒就处理完成了,如果所有的请求都可以快速处理的话,那么我们可以说1秒钟的并发数就等于400*1000=40万的并发。
这么一看是不是觉得php-fpm的性能也没这么差了?
但是,如果你的业务数据量很大,mysql的查询效率不高,每次请求都需要花费1秒钟的时间才能返回响应的话呢?
那么每秒钟的并发数就从40W又下降回400了。
而swoole,就是为了解决这个问题所开发出来的一个php扩展,它使得每个worker进程不会因为1秒钟的io阻塞而白白让cpu浪费1秒钟的性能。
swoole的运行方式
按照刚刚的那个例子来解释的话,swoole的处理方式就是在一个worker进程开始进行mysql io查询的时候就将这个请求任务暂时挂起,立马开始执行下一个请求,然后等到第一个请求中的mysql io数据返回之后,再切换回第一个请求中继续执行代码返回响应。这样一来,对于cpu来说,它一直在执行代码,没有因为请求中mysql的1秒io耗时处于空闲状态。
那么,既然那1秒的io耗时没有对cpu产生影响,那么对于服务器来说,每一秒钟的并发数和之前一样仍然是40W,只不过由于每个请求还是有1秒的耗时,所以单个请求的响应时间依然是1秒钟,但是对于cpu来说,它每秒处理的请求数量并没有减少,因为对于cpu来说一个请求的io耗时是1秒,1000个请求的总耗时依旧是1秒。
同步与异步
什么是同步
我们平时编写的php代码就是同步代码。php解释器一行一行的编译运行我们的代码,碰到数据库查询,或者第三方接口调用,或者系统磁盘读写。这些不归php当前进程管辖的部分都是io操作,它们可能是磁盘io,可能是网络io。而同步的代码一旦碰到这些io操作,它们就会停下来等待,等待mysql返回查询结果,等待第三方接口返回响应,等待linxu文件系统返回磁盘读取结果。在等待的过程中,cpu的性能就被浪费掉了。
什么是异步
异步代码就是说代码在运行到一个需要等待的io操作时,不在原地傻等,而是继续向下执行其他代码,等到io操作有返回结果通知的时候再回过头来执行处理逻辑。
一个简单的例子就是js中的Ajax,下面这个例子当中,js把Ajax请求发送出去就开始执行下一行代码了,所以是先alert 2,然后等到Ajax响应返回再执行回调函数alert1。
$.ajax({
url:"http://www.test.com/get_data",
success: function (result) {
alert(1);
}
});
alert(2);对于生活中的例子来说,异步就是一个人同时使用洗衣机洗衣服与使用电饭煲做饭,假设洗衣机洗一次衣服要40分钟,电饭煲煮饭也需要40分钟,那么这两件事都完成需要多长时间呢?
是的,也是40分钟(最多多出一些把衣服和米分别放进机器的可以忽略不计的时间),因为人把衣服放进洗衣机就可以去做其他事了,不会守在洗衣机旁傻等,可以去开电饭煲了。而洗衣机洗好衣服以后,会有滴滴声提示人衣服已经洗好了。
回到一开始那个swoole并发数的例子,那些需要1秒钟来查询mysql数据的请求,它们的那1秒io操作也没有让cpu进行傻等,所以对于cpu来说,io操作已经无法影响它的并发数了,因为它始终在工作,并没有浪费等待时间。
解析一下,如果使用异步的方式,那么会有两个比较关键的点:
- 发起io操作,添加回调函数
- 等任务完成后执行回调函数
异步编程完全没有浪费cpu一点性能,那如果所有的io耗时操作都用异步操作会怎么样呢?
了解node.js的朋友可能经常听见一个词回调地狱。
前端开发中很少会有人在Ajax中嵌套Ajax,但是如果你想通过异步的方式来提升代码的性能,那么不可避免的,只要你的程序中有多个io操作,那它们就会向下面这段代码一样变成层层嵌套,很快这段代码就变得不可维护了,甚至是修改的时候都会让人十分头疼。
login(user => {
getStatus(status => {
getOrder(order => {
getPayment(payment => {
getRecommendAdvertisements(ads => {
setTimeout(() => {
alert(ads)
}, 1000)
})
})
})
})
})
而swoole的出现,就是为了解决同步代码浪费性能的问题,让同步执行的代码变为异步执行,同时使用协程降低异步回调编程时的心智负担。
cpu上下文切换
现在的电脑,一边写代码,一边查文档,一边听音乐都是很常见的,因为cpu 的核心数很多可以同时做好几件事。但是你在一开始学习for循环的时候一定听老师说过,当年的单核cpu写循环一定要小心,因为一旦出现死循环了,那么整台电脑都会卡死只能重启了。
cpu在执行代码的时候是同步的,所以理论上来讲同一时刻只能做一件事,哪怕不进行死循环,按理说之前的老电脑也没办法做到同时写代码与查文档以及听音乐这些事才对,并且就算是现在的四核八核cpu,那我也是可以同时开十几个网页,同时播放视频的。
让单核cpu同时运行多任务的魔法就是上下文切换了,主要的原理就是cpu在同时进行玩游戏与播放音乐时,先运行一会游戏,然后马上切到音乐程序上运行一会,不断地在这些应用之间来回切换运行,因为cpu的计算速度是远超人脑反应时间的,所以在人类眼中,这些应用就像是在同时运行一样。
那到底什么是上下文呢?就是程序运行中所需要的数据,包括存储在内存中的,以及cpu多级寄存器中的这些数据。在线程与进程切换的时候,需要把这些数据保存起来,等到它们恢复运行的时候再把数据读取回进程来运行。
本文主要是介绍swoole的,swoole的重点在于异步与协程,为什么要提到上下文切换呢?因为不论是多进程、多线程还是协程,它们本质上都需要用到上下文切换来实现的。
多进程模式,是由系统来决定每个进程的运行分片时长。而多线程由于它们一定有一个父级进程,所以每个线程的运行分片时长则是由进程来决定的。这也是为什么多线程语言的教程里都会提到不是线程开的越多越好的原因,多线程会有线程争抢和系统调度的开销。同时,由于cpu同一段时间内运算速度的总量是固定的,所以线程只需要尽量把cpu空闲的算力占满就好,开过多的线程反而会因为增加系统线程调度开销造成业务部分线程性能的下降。
那么协程与多线程多进程又有什么不同呢?通过实例来对比:
- php-cgi便是多进程的一种体现,每个请求对应一个cgi进程,带来的缺点是进程频繁创建销毁的开销以及每次都需要加载php.ini配置的性能浪费。
- php-fpm多进程模式的改良,通过master/worker的模式,让多进程少了重新加载配置与频繁创建销毁进程的开销。
- 假设php有多线程,省略多次php.ini的加载,省略多次开发框架初始化,相应的带来线程调度开销,多线程抢占式模型需要注意数据访问的线程安全,需要给数据加锁,并带来锁争抢与死锁问题。
- 协程,省略多次php.ini加载,省略多次开发框架初始化,由于协程是用户态的线程,所以由代码来控制什么时候进行切换,没有线程调度开销。并且swoole以同步的方式编写异步代码,协程的切换由底层调度器自行切换,开发者无需关注线程锁与死锁问题。
swoole的协程切换是基于io来调度的,也就是说它只会在遇到io操作的时候才会进行切换,通过节省io等待时间来提高服务器性能,因此swoole的协程是无法进行并发计算的。不过遇到需要并行计算的场景,swoole也提供了多进程的运行方式,如果需要多进程协同操作同一个数据,就需要加进程锁了。
事件循环–异步是如何实现的
现在我们已经知道多进程,多线程,协程都是异步的编程方式了,那么异步是怎么实现的呢?
这是一个大问题,先从最基础的看起,基础异步编程就是异步回调模式,也就是在执行任务的同时传入一个回调函数,等到任务执行完毕,回调函数自然而然的就开始运行了。类似js的Ajax一样,发起一个Ajax请求的时候便是发起了异步任务,同时在$.ajax方法的第三个参数传入一个匿名函数,等到后端返回响应以后再继续执行回调函数中的代码。
那么就出现了一个问题,是谁来通知当前进程异步任务已经完成了的呢?
做过im通信朋友都知道,两个客户端的对话除了发送消息,最难实现的还是接收消息,因为需要服务端主动做推送。如果不使用WebSocket的话,要实现服务端推送就只能使用长连接+轮询的方式了。接收消息的那一方客户端需要每隔一段时间就请求一次服务器,看看有没有消息发送给自己。对于异步回调来说,它的实现方式也是有异曲同工之处。
处理异步回调的部分叫做事件循环,可以理解为每个进程有一个死循环,不断的查看当前有没有待执行的任务、已经执行完需要通知的回调。当我们进行异步任务调用的时候,就是向这个循环中投递了一个任务与对应的回调。当任务完成的时候,循环便把任务从监听数组中去除,并执行回调。
下面来看一个简单的事件循环的例子。
可以看到,EventLoop类中维护了一个event数组,用来存储需所有需要监听的事件。在调用addEventHandler方法时,则需要将事件的类型、参数,以及回调函数一同传入。
当调用run方法时,这个循环就被开启了,可以看到run方法中是一个while死循环,用来不断的检测是否有已完成的任务。而while循环内层的foreach则是为了查看所有事件中是否有已完成的单个任务。
而processTimers与processIOEvents方法则代表了swoole中典型的两种事件,io事件与定时器。由于linux系统中万物皆文件的特性,很多看似是网络io的功能,其实都要用到文件系统来实现,所以processIOEvents方法需要传入fp文件指针以及read与write两种读写事件。例如假设我们投递的是读取事件,那么就调用fread函数来读取文件,并把读取到的数据传递给回调函数来执行。这就是一个事件循环的回调过程了。
<?php
class EventLoop
{
private $event_handlers = [];
public function addEventHandler($event_type, $handler)
{
$this->event_handlers[$event_type][] = $handler;
}
public function run()
{
while (true) {
foreach ($this->event_handlers as $event_type => $handlers) {
switch ($event_type) {
case 'timer':
$this->processTimers($handlers);
break;
case 'io':
$this->processIOEvents($handlers);
break;
// 可以根据需求添加更多事件类型
}
}
}
}
private function processTimers($handlers)
{
$now = time();
foreach ($handlers as $timer) {
if ($now >= $timer['time']) {
$timer['callback']();
if ($timer['interval']) {
$timer['time'] = $now + $timer['interval'];
} else {
unset($this->event_handlers['timer'][array_search($timer, $handlers)]);
}
}
}
}
private function processIOEvents($handlers)
{
foreach ($handlers as $io_event) {
$fp = $io_event['fp'];
$callback = $io_event['callback'];
$events = $io_event['events'];
$read = in_array('read', $events);
$write = in_array('write', $events);
if ($read) {
$read_data = fread($fp, 8192);
if ($read_data) {
$callback($read_data);
} else {
unset($this->event_handlers['io'][array_search($io_event, $handlers)]);
fclose($fp);
}
}
if ($write) {
$callback();
unset($this->event_handlers['io'][array_search($io_event, $handlers)]);
fclose($fp);
}
}
}
}
// 使用示例
$loop = new EventLoop();
// 添加定时器
$loop->addEventHandler('timer', [
'time' => time() + 5,
'interval' => 0,
'callback' => function () {
echo "5 seconds have passed\n";
},
]);
// 添加 IO 事件
$fp = fopen(__FILE__, 'r');
$loop->addEventHandler('io', [
'fp' => $fp,
'events' => ['read', 'write'],
'callback' => function ($read_data = null) {
if ($read_data) {
echo "read data: $read_data";
} else {
echo "io event has occurred\n";
}
},
]);
// 启动事件循环
$loop->run();
在理解了时间循环以后,那么事件循环与swoole与多进程、多线程、协程之间有什么关系呢?
没错,无论是多进程、多线程还是协程,它们底层都依赖事件循环来实现异步,例如进程与线程之间切换的时候如何通知对应的进程与线程?依赖系统级事件循环。例如协程之间多个协程的切换要如何通知对应的协程?也是依赖事件循环。不过swoole为了降低上下文切换带来的消耗,没有依赖系统级事件循环而是自己实现了一套,swoole的协程上下文切换都是内存读取,避免了cpu寄存器、堆栈以及系统内核态与用户态之间的切换,因此切换开销极小。
总结
说了这么多概念,那么swoole到底是什么呢?它融合了php-fpm的结构模式,优化了单进程的性能浪费,弱化了多线程的调度开销,屏蔽了异步回调的复杂逻辑,是一个常驻内存的高性能web扩展。
做一个不严谨的类比,你也可以认为swoole是一个语言层面实现的php-fpm,毕竟swoole也支持完全的多进程模式,这种模式下与php-fpm的运行方式大同小异。不过由于在语言层面便常驻内存了,所以带来的福利便是在启动php脚本的开发框架时,只需要一次载入便保存在内存中了,避免了php-fpm每个请求都重新初始化框架的性能浪费。那么同样的由于服务常驻内存了,所以哪怕是在开发过程中,代码相关的改动都需要重启一下swoole服务。
而swoole的架构,对应下面这张图,便是master、manager、worker的结构,在swoole服务启动时,master进程便fork出manager进程来对worker进程进行创建和管理,master进程自己则通过reactor线程来接受与分发请求,master进程接收到的请求通过reactor线程直接发送到worker进程中,而worker进程负责对请求进行具体的处理。如果开启了协程模式,并且代码也是以协程的方式运行,则一个worker可能会一段时间内(例如1s)处理多个请求。因为每个请求遇到io等待时,worker便切换协程直接开始处理下一个请求了,直到io任务返回结果,worker再切换回上一个请求将响应返回给master进程。
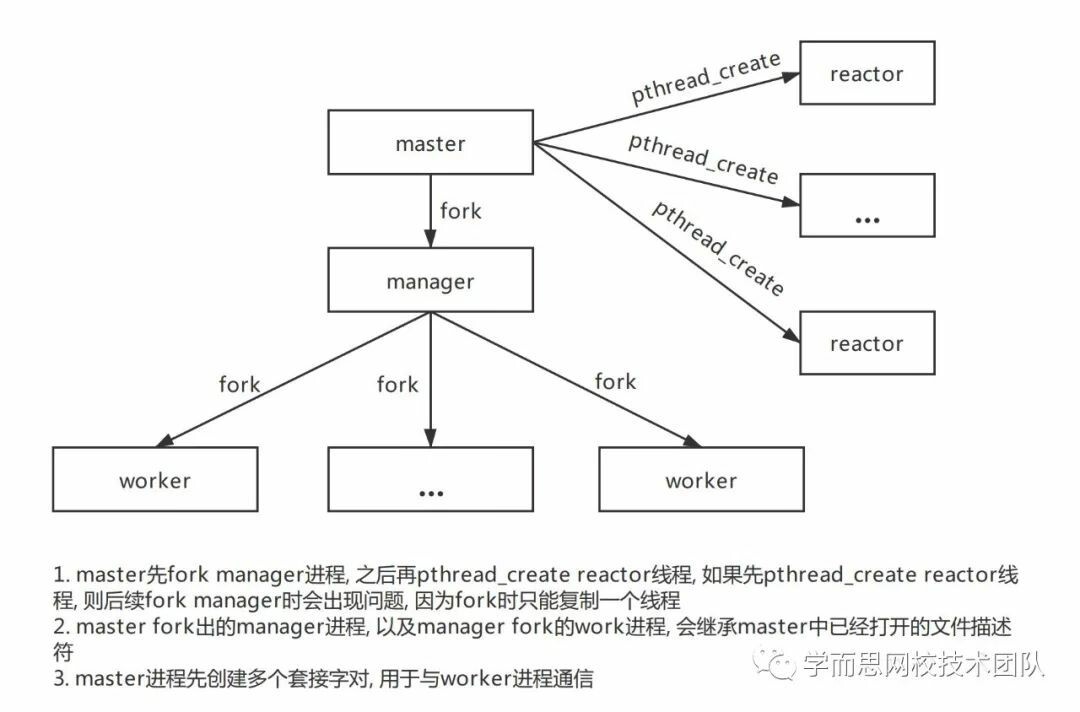
swoole对性能的提升带来的代价是编程思维的转变,因为常驻内存了,所以编写业务代码时,对内存变量的使用就需要更加小心,避免造成内存泄露。因为基于异步编程,所以要理解异步的思想,避免写出同步阻塞的代码。
本作品采用《CC 协议》,转载必须注明作者和本文链接


































 关于 LearnKu
关于 LearnKu




推荐文章: