
初识 HTTP(一)
3 / 0 / 创建于 2年前 /
 Configuration 的个人博客
Configuration 的个人博客
什么是HTTP?
HTTP是超文本传输协议(HyperText Transfr Protocol)。
什么是超文本传输协议?它可以拆成三部分:
- 超文本
- 传输
- 协议
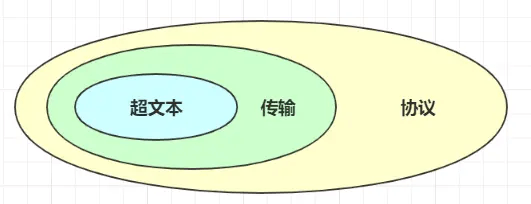
- 协议:
什么是HTTP协议?在生活中,我们也能随处可见【协议】,例如: 刚毕业时会签一个【三方协议】 找房子时会签一个【租房协议】 协议的特点: - 【协】字,代表的意思是必须有`两个以上的参与者`,例如三方协议里的参数者有三个:你,公司,学校,租房协议里的参与者有:你和房东。 - 【议】字,代表的意思是对参与者的一种行为`约定和规范`,例如三方协议里规定试用期,毁约金等,租房协议里规定租期期限,违约如何处理等。HTTP是一个用在计算机世界的`协议`,使用了计算机能够理解的语言确立了一种计算机直接交流的规范`(两个以上的参与者)`,已经相关的各种控制和错误处理方式`(行为约定和规范)`。 - 传输:
结合上述协议传输: 就是把一个东西或者一堆东西从一个地点(A点)搬到另外一个地点(B点)。
HTTP是在计算机世界用来两点之间传输数据的约定和规范。 - 超文本:
超文本传输的东西或者说内容就是`超文本`。 什么超文本? 字符文字,图片,视频,压缩包等,在HTTP眼中这些都算做`文本`,而超文本是文字,图片,视频等的混合体,最关键有超链接,HTML就是最常见的超文本。HTTP是计算机世界专门在两点之间传输超文本数据的约定和规范
HTTP是用于从服务器传输超文本到浏览器的协议,这种说法是正确的吗?
这种说法是不正确的,因为也可以从 服务器 到 服务器,所以使用两点之间会更正确。
HTTP 常用的状态码有哪些?
| 含义 | 状态码 | |
|---|---|---|
| 1xx | 提示信息,表示目前是协议处理的中间状态,还需要后续的操作 | |
| 2xx | 成功,报文已经收到并成功处理 | 200,204,206 |
| 3xx | 重定向,资源位置发生变动,需要客户端程序发送请求 | 301,302,304 |
| 4xx | 客户端错误,请求报文有误,服务器无法处理 | 401,403,404 |
| 5xx | 服务器错误,服务器在处理请求时内部发生了错误 | 500,501,502,503 |
常见的状态码:
- 200: 是最常见的成功状态码,表示一切正常,如果不是HEAD请求,服务器的响应头都会有body数据。
- 204:No Content 也常见的成功状态码,与200基本相同但响应头没有body数据。
- 301:Moved Permanently 表示
永久重定向,请求的资源已经不存在了,需要新的URL再次访问。 - 302:Fount 表示
临时重定向,说明请求的资源还在,但暂时需要另一个URL来访问。 - 400:Bad Request 表示客户端请求的报文有错误。
- 403: Forbidden 表示服务器禁止访问资源(权限不够),并不是客户端的请求错误。
- 404:Not Fount 表示请求的资源在服务器不存在或者未找到。
- 500:Internl Server Error 服务器发生了错误。
- 502:Bad Gateway 通常是服务器作为网关或者代理时返回错误码,表示服务器自身正常,访问后端服务器发生了错误。
HTTP常见字段有哪些?
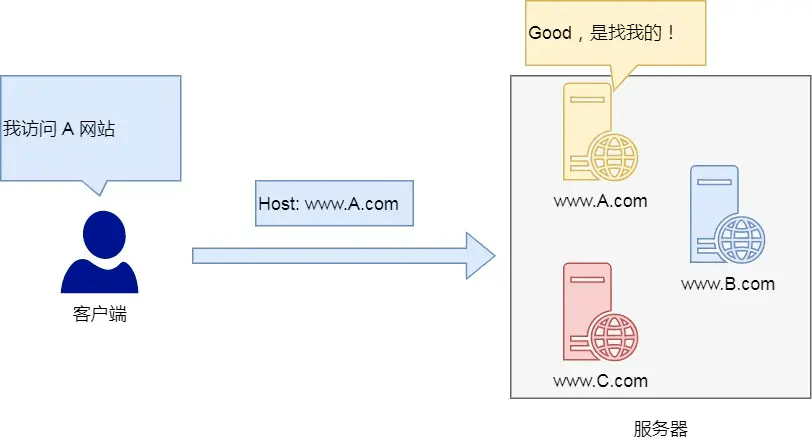
Host字段客户端发送请求时,用来指定服务器域名。 有了Host字段,就可以将请求发往【同一台】服务器上的不同网站
Content-Length字段服务器在返回数据时,会有Content-Length,表明本次回应的数据长度。 Content-Length:1000 表示回应的数据长度为1000字节,后面的字节属于下一个回应,HTTP是基于TCP传输协议进行通信的,而使用了TCP传输协议,就会存在一个粘包的问题,HTTP协议通过设置回车符,换行符作为HTTP header的边界,通过Content-Length字段作为HTTP body的边界,这两个方式都是为了解决 `粘包`的问题。

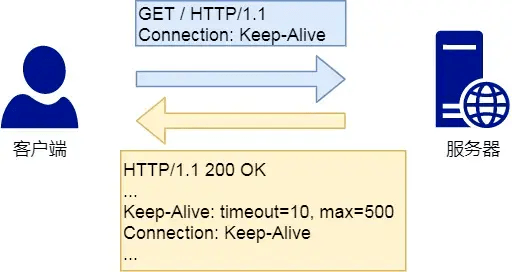
Connection字段Connection 字段最常用客户端要求服务器使用`HTTP长连接`机制,请求复用。 HTTP长连接的特点:只要任意一端没有明确提出断开连接,则保持TCP连接状态。 HTTP/1.1版本的默认连接都是长连接,但是为了兼容老版本的HTTP,需要指定`Connection字段的值为 Keep-Aive`. 开启HTTP Keep-Alive机制后,连接就不会中断,而是保持连接,当客户端发送另一个请求时,它会使用同一个连接,一直持续客户端或者服务端提出断开连接。
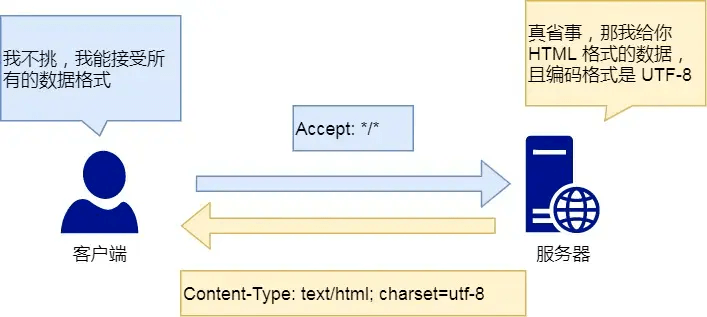
Content-Type字段Content-Type字段用于服务器响应时,告诉客户端本次数据时什么格式。 `Content-Type: text/html;Charset=UTF-8` 表示响应的是网页,并且编码是UTF-8. `Accept`: */* 表示客户端声明自己可以接受如何格式的数据
Content-Encoding字段Content-Encoding 字段说明数据的压缩方法,表示服务器返回的数据使用了压缩格式。 `Content-Encoding: gzip`: 表示服务器返回的数据采用gzip方式压缩,告知客户端需要此方法解压。 `Accept-Enconding: gzip,deflate` 客户端在发送请求时,可以用Accept-Enconding说明自己可以接受哪些压缩方法。
HTTP 常见的请求方式
| 方式 | 含义 |
|---|---|
| GET | 常用于获取数据,查询数据,不对数据进行修改 |
| POST | 创建或者更新数据 |
| PUT | 创建或者更新数据,侧重于创建数据 |
| DELETE | 删除指定资源,它会删除URI给出目标资源的所有当前内容 |
| OPTIONS | 用来描述资源的通信选项,返回服务器针对特定资源所支持的HTTP请求方法,也可以利用向web服务器发生请求 |
| HEAD | 与GET方法相似,但是没有响应体 |
| CONNECT | 用于建立到给定URI的服务器的隧道 |
| trace | 用于沿着目标资源的路径执行消息环回测试 |
GET请求 和 POST请求有什么区别?
根据RFC规范,`GET请求是从服务器获取资源`,并且GET请求参数一般写在URI中,`URL规定只能支持ASCLL,所以GET请求的参数值只允许ASCLL字符,而浏览器会对URL的长度有限制(HTTP协议本身对URL长度做任何规定)。`
`POST请求时根据请求报文body对指定资源做出处理`,POST请求携带的参数一般写在body,body中的数据可以是任意格式,只要客户端与服务器端协商好就可以,而且`浏览器不会对body的大小做限制。`GET 方法和POST 方法都是安全和幂等的吗?
- 安全: 在HTTP协议中,所谓的
安全是指请求方法不会破坏服务器上的资源。 - 幂等: 多次执行相同的操作,结果都是相同的
如果从RFC规范定义的来看: GET方法就是安全幂等的,因为它是只读操作,无论操作多少次,服务器上的数据都是安全的,且每次结果都是相同的。POST因为是新增或者提交数据的操作,会修改服务器上的资源,所以是不安全的,且多次提交数据,就会创建多个资源,所以是不幂等的。
注意上面是根据RFC规范定义的语义来分析的,但是实际过程中,开发者不一定按照RFC规范定义的语义来实现GET和POST方法
- 可以用GET方法实现新增或者删除数据的请求,这样实现的GET方法自然就不是安全和幂等。
- 可以用POST方法实现查询数据的请求,这样实现的POST方法就是安全和幂等的。
GET请求可以携带body吗?
RFC规范并没有规定GET请求不能携带body,理论上,任何请求都可以携带body,URL中的查询参数也不是GET所独有的,POST请求的URL中也可以有参数。Python GET 请求携带body, 使用data
import requests
# 定义请求体数据
data = {
'param1': 'value1',
'param2': 'value2'
}
url = 'xxxxxxxxxxx'
# 发送GET请求
response = requests.get(url, data= data)
# 处理响应
print(response.text)HTTP缓存技术
对于一些重复性的HTTP请求,每次请求得到的数据都一样,就可以把这对请求-响应的数据缓存到本地.
HTTP 缓存有两种实现实现缓存:
- 强制缓存
- 协商缓存
什么是强制缓存?
强制缓存是指浏览器判断缓存有没有过期,如果没有过期就直接使用浏览器的本地缓存,决定是否使用缓存的主动性在于浏览器这边。
如下图,返回的是200状态码,但是标识的是 from disk cache ,就是使用了强制缓存。

强制缓存是利用两个HTTP响应头部字段来实现的,表示资源在客户端缓存的有效期:
- Cache-Control,是一个相对实际。
- Expires,是一个绝对实际。
如果响应头部同时有 Cache-Control和Expire字段的话,Cache-Control的优先级要高于Expires
Cache-control选项更多一点,设置更加精细,所以建议使用Cache-Control来实现强制缓存,流程如下: - 当浏览器第一次访问服务器时,服务器会返回这个资源同时在Respinse头部加上Cache-control 设置过期大小;
- 浏览器再次访问服务器中该资源时,会先通过请求资源的时间与 Cache-Control 中设置的过期时间大小,来计算该资源是否过期,如果没有,则使用该缓存,否则重新请求服务器;
- 服务器再次收到请求后,会再次更新Resonse头部CaChe-Control
什么是协商缓存?
服务器告知客户端是否可以使用缓存的方式被称为协商缓存,协商缓存就是与服务端协商之后,通过协商结果来判断是否使用本地缓存,协商缓存需要配合强制缓存中Cache-Control字段来使用,只有在未命中强制缓存的时候,才能发起带有协商缓存字段的请求。
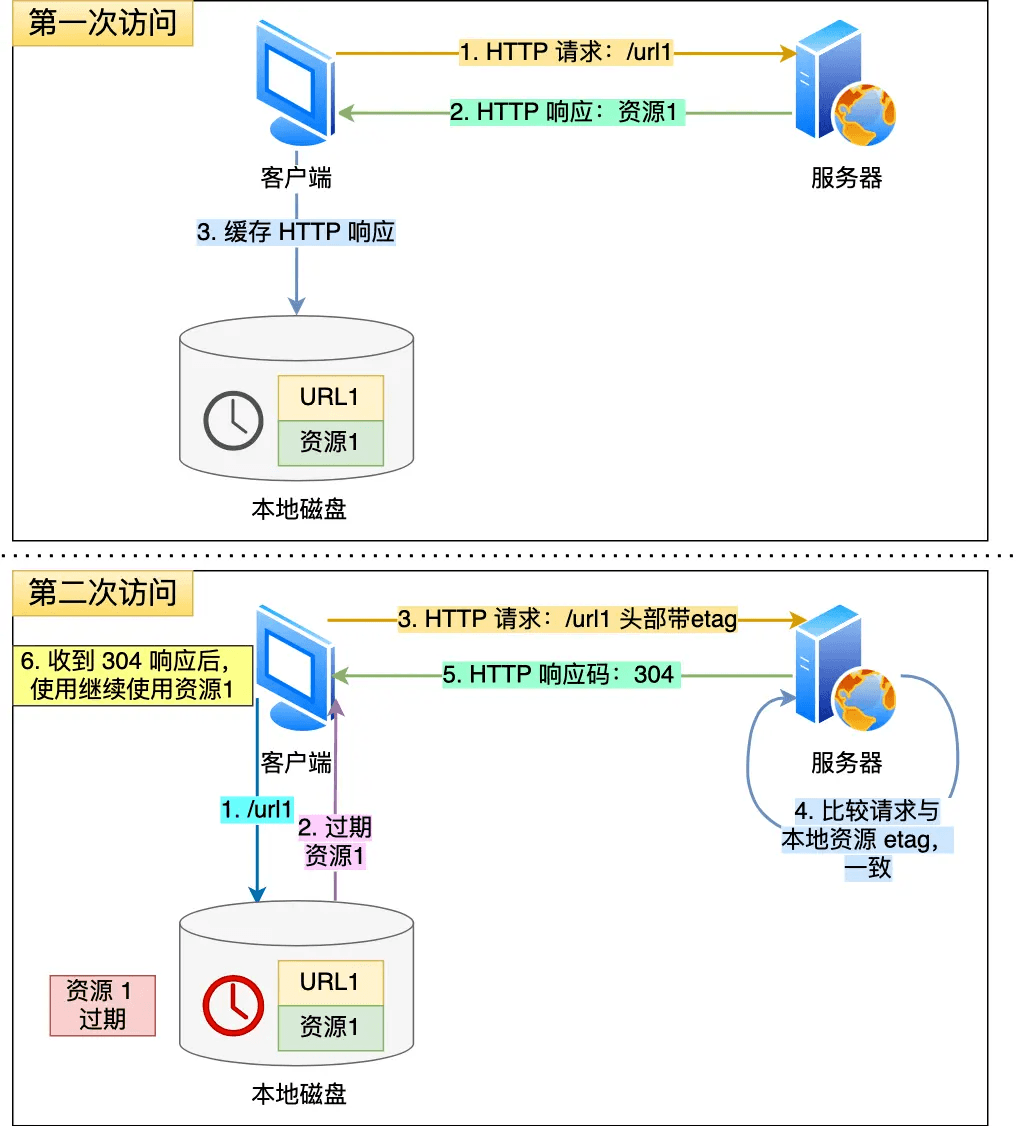
当使用ETag字段实现的协商缓存的过程:
- 当浏览器的第一次请求访问服务器资源时,服务器会在返回这个资源的同时,在Response头部加上ETag唯一标识,这个唯一标识的值是根据当前请求的资源生成的
- 当浏览器再次请求访问服务器中的该资源时,首先会先检查强制缓存是否过去:
如果没有过期,则直接使用本地缓存 如果缓存过期了,会在request头部加上 if-None-Match字段,该字段的值就是ETag唯一标识; - 服务器再次收到请求后,会根据请求的 if-None-Match值与当前请求的资源生成的唯一标识进行比较
如果值相等,则返回304 Not Modified ,不会返回资源 如果不相等,则返回200状态码和返回资源,并在Response头部加上新的ETag唯一标识 - 如果浏览器收到304的请求响应状态码,则会从本地缓存中加载资源,否则更新资源。
HTTP特性
HTTP的优点有哪些?
- 简单
HTTP基本报文格式是 header + body ,头部信息也就是 key-value简单文本的形式,易于理解,降低了学习和使用门槛。 - 灵活和易于扩展
HTTP协议里的各种请求方法,URI、URL,状态码,头字段等每个组成都没有被固定死,都允许开发人员自定义和扩充。 - 应用广泛和跨平台
HTTP的应用范围非常的广泛,从台式机的浏览器到手机上的各种APP,从看新闻,刷贴吧到购物,理财,吃鸡,HTTP的应用遍地开花,同时天然具有跨平台的优越性。
HTTP的缺点有哪些?
- 无状态双刃剑
无状态的好处,因为服务器不会去记录HTTP的状态,所以不需要额外的资源来记录状态信息,这能减轻服务器的负担,能够把更多的CPU和内存用来对外提供服务。 无状态的好处,由于服务器没有记录HTTP的状态,在需要完成关联性的操作会非常麻烦,例如登录->添加购物车->下单->结算->支付,这系列操作都要知道用户的身份才行。但服务器不知道这些请求是有关联的,每次都要问一遍身份信息,对于无状态的问题,解法方案有很多种,其中比较简单的方式用 Cookie 技术。 - 明文传输
HTTP的所有信息都暴露在光天化日下,相当于信息裸奔,在传输的漫长过程中,信息很任意被窃取。 - 不安全
- 通信使用明文(不加密),内容可能会被窃听,比如,账号信息容易泄露,那你号没有了 - 不验证通信方的身份,因此有可能遭遇伪装,比如,访问假的淘宝,拼多多,那你钱没了 - 无法证明报文的完整性,所以有可能已遭篡改,比如,网页上植入垃圾广告,视觉污染,眼没了
HTTP与HTTPS
HTTP 与HTTPS有哪些区别?
- HTTP是超文本传输协议,信息是明文传输的,存在安全风险的问题,HTTPS则解决HTTP不安全的缺陷,在TCP和HTTP网络层之间加了SSL、TLS安全协议,是的报文能够加密传输。
- HTTP连接建立相对简单,TCP三次握手之后便可以进行HTTP报文传输,而HTTPS在TCP三次握手之后,还需要SSL、TLS的握手,才可以进行加密报文传输。
- 两者的默认端口不一样,HTTP的默认端口是80,HTTPS默认端口是443.
- HTTPS协议需要向CA(证书权威机构)申请数字证书,来保证服务器的身份时可信的。
HTTPS解决了HTTP哪些问题?
HTTP由于是明文传输,所以安全上存在三个风险:
- 窃听风险,比如通信链路上可以获取通信内容
- 篡改分析,比如强制植入广告,视觉污染
- 冒充风险,比如冒充淘宝网站

HTTPS在HTTP与TCP层之间加入了SSL、TLS、协议:
- 信息加密:交互信息无法被窃取
- 校验机制:无法篡改通信内容,篡改了就不能正常显示
- 身份证书:证明淘宝是真的淘宝网
HTTPS是如何解决上面的三个风险的?
- 混合加密的方式实现信息的机密性,解决了窃听的风险
- 摘要算法的方式来实现完整性,它能够为数据生成独一无二的指纹,指纹用于校验数据的完整性,解决了篡改的风险
- 将服务器公钥放入到数字证书中,解决了冒充的风险
HTTP 如何优化?
我们可以从三个方面来优化:
- 尽量避免发送请求
- 在需要发送HTTP请求时,考虑如何减少次数
- 减少服务器的响应数据的大小
如何避免发送HTTP请求?
对于一些具有重复性的HTTP请求,比如每次请求的到的数据都一样,我们可以把这对【请求---响应】的数据都缓存在本地,那么下次就直接读取本地的数据,不必在通过网络获取服务器的响应了,这样的话 HTTP/1.1的性能肯定肉眼可见的提升。如何缓存?
客户端会把第一次以及响应的数据保存在本地磁盘上,其中将请求的URL作为KEY,而响应作为value,两者形成映射关系。
这样当后续发起相同的请求时,就可以先在本地磁盘上通过key查到对应的value,也就是响应,如果找到了,就直接从本地读取该响应。读取本地磁盘的速度肯定比网络请求快的多。如何减少HTTP请求次数?
减少HTTP请求次数自然就 提升了HTTP性能:
我们可以考虑对响应资源进行压缩,这样就可以减少响应的数据大小,从而提高网络传输的效率。
压缩的方式一般分为2种,分别是:
- 无损压缩;
- 有损压缩
本作品采用《CC 协议》,转载必须注明作者和本文链接



 关于 LearnKu
关于 LearnKu




推荐文章: