
本地部署最新ChatGLM-6B开源中英双语对话聊天问答小说模型教程
0 / 0 / 创建于 3年前
 112233 的个人博客
112233 的个人博客
项目地址:github.com/THUDM/ChatGLM2-6B
完整教程地址:cj.7aaa.cn/
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。如果您发现我们的开源模型对您的业务有用,我们欢迎您对下一代模型 ChatGLM3 研发的捐赠。
ChatGLM2-6B 开源模型旨在与开源社区一起推动大模型技术发展,恳请开发者和大家遵守开源协议,勿将开源模型和代码及基于开源项目产生的衍生物用于任何可能给国家和社会带来危害的用途以及用于任何未经过安全评估和备案的服务。目前,本项目团队未基于 ChatGLM2-6B 开发任何应用,包括网页端、安卓、苹果 iOS 及 Windows App 等应用。
尽管模型在训练的各个阶段都尽力确保数据的合规性和准确性,但由于 ChatGLM2-6B 模型规模较小,且模型受概率随机性因素影响,无法保证输出内容的准确性,且模型易被误导。本项目不承担开源模型和代码导致的数据安全、舆情风险或发生任何模型被误导、滥用、传播、不当利用而产生的风险和责任。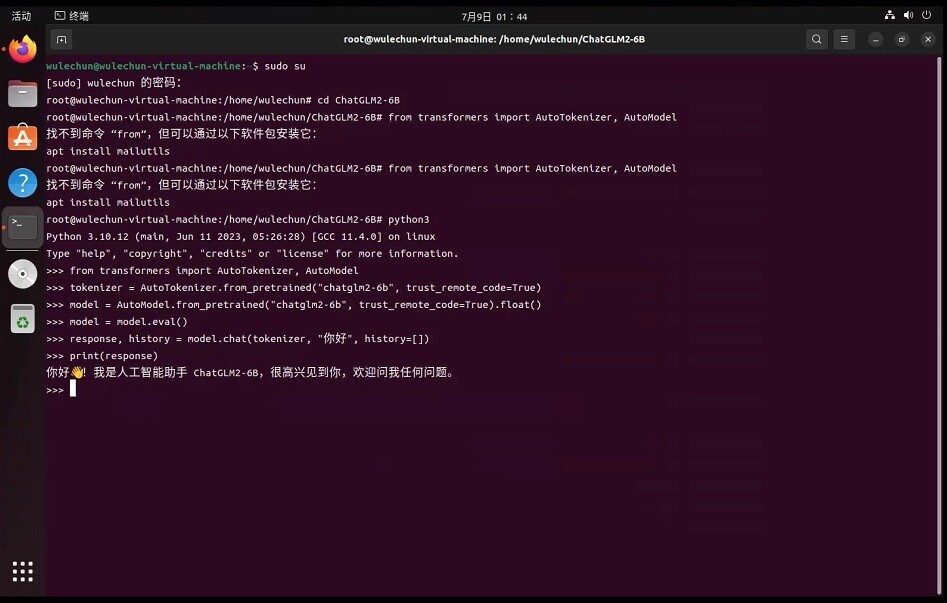
本作品采用《CC 协议》,转载必须注明作者和本文链接




 关于 LearnKu
关于 LearnKu




推荐文章: