
高效办公小技巧——如何批量处理 SQL 文件?
44 / 11 / 创建于 3年前 /
 快乐的皮拉夫 的个人博客
快乐的皮拉夫 的个人博客
背景
我们在日常工作中,经常会遇到一些「洗数据」的场景。
比如,我们有如下格式的源文件:
origin.csv
ID,积分,更新时间
1,1000,2023-07-12 12:00:00
2,2000,2023-07-12 12:00:00
3,3000,2023-07-12 12:00:00
4,4000,2023-07-12 12:00:00
...文件格式为 csv 格式的文件,文件行数在数万行左右。共有三列内容,分别为:ID、积分和更新时间。
现在我们需要根据文件的内容,生成以下格式的 SQL 文件:
target.sql
UPDATE `users` SET `score` = {积分}, `updated_at` = {更新时间} WHERE `id` = {ID} LIMIT 1;
UPDATE `users` SET `score` = {积分}, `updated_at` = {更新时间} WHERE `id` = {ID} LIMIT 1;
UPDATE `users` SET `score` = {积分}, `updated_at` = {更新时间} WHERE `id` = {ID} LIMIT 1;
UPDATE `users` SET `score` = {积分}, `updated_at` = {更新时间} WHERE `id` = {ID} LIMIT 1;
...当你遇到这种场景时,你一般是怎么处理的呢?
接下来,就让我们来看看有哪些常见的处理方法。
以下方法均为笔者用过的一些方法,如果大家有其他更好的方法,欢迎大家在评论区留言讨论~
处理方案
方案一:代码搞定一切
作为天天撸脚本的程序员来说,没有什么问题是几行代码不能搞定的。这里我们先以 Laravel 为例,看看如何实现这个功能。
由于功能比较简单,我们直接上代码:
...
//========== 获取文件路径 ==========
$originFile = storage_path('tmp/origin.csv');
$targetFile = storage_path('tmp/target.sql');
//========== 使用SplFileObject类处理文件 ==========
$splFileObj = new \SplFileObject($originFile, 'r+');
//========== 跳过行首 ==========
$splFileObj->current();
$splFileObj->next();
while (!$splFileObj->eof()) {
//========== 读取行并移动文件指针 ==========
$line = trim($splFileObj->current());
$splFileObj->next();
$lineInfo = explode(',', $line);
//========== 文件行格式判断 ==========
if(!$lineInfo || count($lineInfo) != 3){
Log::error('Invalid line format for origin csv file.', ['line' => $line]);
continue;
}
list($id, $score, $updatedAt) = $lineInfo;
//========== 生成SQL文件 ==========
$sql = "UPDATE `users` SET `score` = {$score}, `updated_at` = '{$updatedAt}' WHERE `id` = {$id} LIMIT 1;" . PHP_EOL;
File::append($targetFile, $sql);
}
...通过运行上述代码,我们就可以将 SQL 生成到 target.sql 文件中,是不是很 Easy 。
方案二:工具 + vim
但是,有时候我们不想这么麻烦地去写脚本,能不能简单一些呢?
我们发现源文件是一个 csv 文件,通过观察目标文件,我们可以发现以下特点:

由于上图中圈出来的部分每一列的内容都是一致的,我们可以把圈出来的部分放到 csv 的新增列中,而未圈出来的部分则是我们原始文件中的列,这样,我们直接在一个新的 csv 文件中生成我们的目标 SQL 。
由于涉及到一些具体的操作,这里我们拆分成几步来演示。
step1:修改日期列格式
这里我们以 WPS 软件为例。当我们用软件打开 origin.csv 文件后,会发现 更新时间 一列的格式被自动转换了,如下:
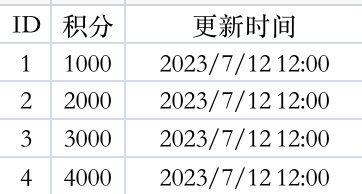
这里我们需要先修改下这一列的单元格格式,选中整列->右键->设置单元格格式,操作如下:
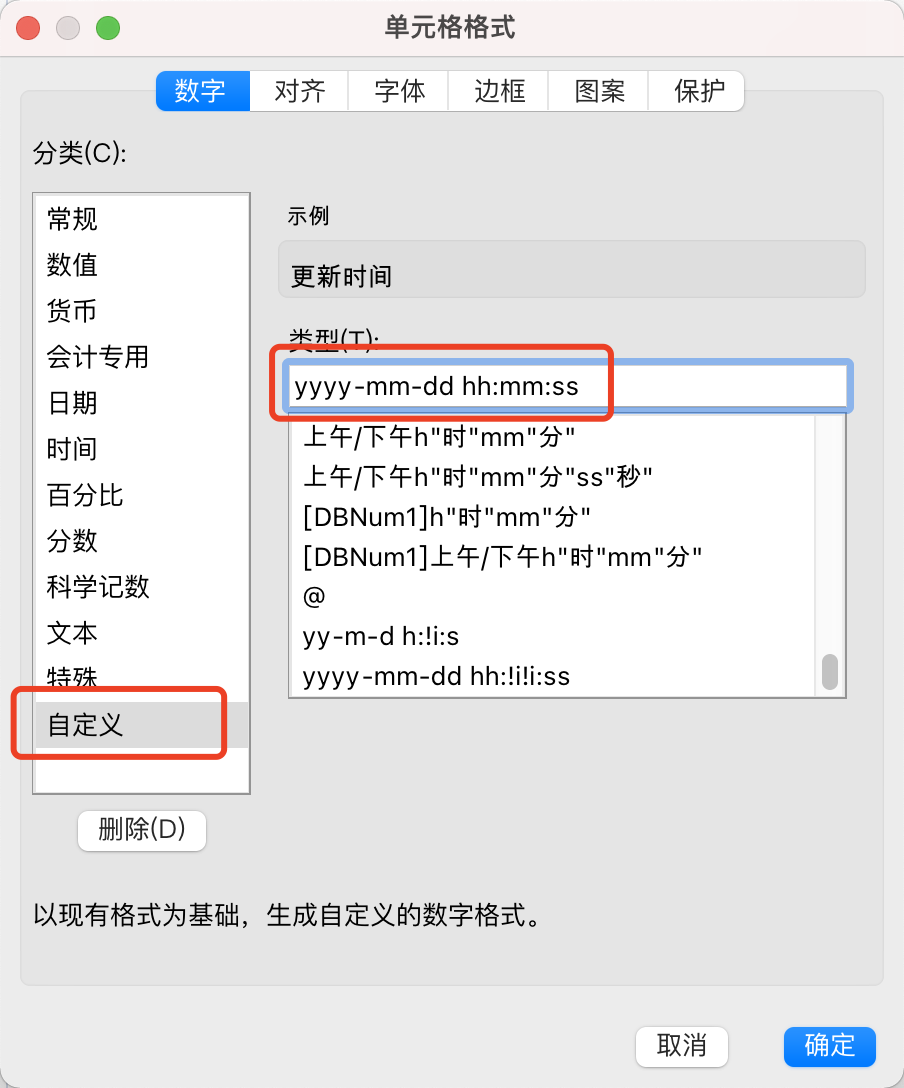
这里,我们把单元格格式设置为 yyyy-mm-dd hh: mm:ss ,确认后就会发现格式显示正常了:

step2:调整列的顺序
接下来,我们需要调整一下原始文件列的顺序,调整后效果如下:
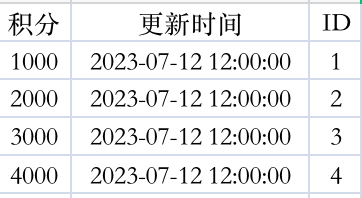
step3:插入新列
根据方案开头的效果图,我们新增数据列,并填充内容,最后再把表头删除。操作以后的效果图如下:
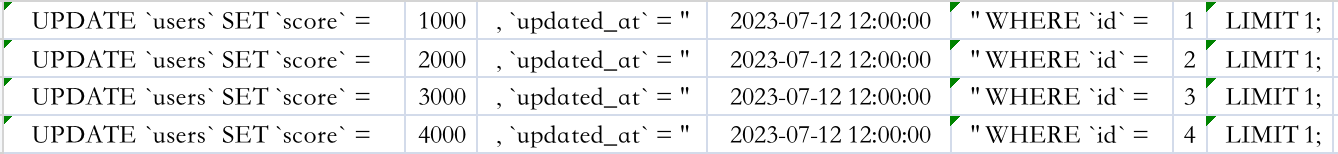
因为 更新时间 一列是字符串,所以我们在外层包裹了双引号。
到这里,看上去已经处理完了。我们将处理完的文件保存为 target.sql 文件,然后打开看看效果:
UPDATE `users` SET `score` = 1000 , `updated_at` = " 2023-07-12 12:00:00 " WHERE `id` = 1 LIMIT 1;
UPDATE `users` SET `score` = 2000 , `updated_at` = " 2023-07-12 12:00:00 " WHERE `id` = 2 LIMIT 1;
UPDATE `users` SET `score` = 3000 , `updated_at` = " 2023-07-12 12:00:00 " WHERE `id` = 3 LIMIT 1;
UPDATE `users` SET `score` = 4000 , `updated_at` = " 2023-07-12 12:00:00 " WHERE `id` = 4 LIMIT 1;这里我们发现,文件中多了一些空白字符,这样的数据格式肯定是不行的,特别是更新时间中的空白字符,可能会产生一些不可预料的后果。
那么应该怎么去掉这些「多余」的空白字符呢?
step4:删除多余空白字符
首先我们需要清楚「空白字符」具体是什么。
我们使用 vim 打开 target.sql 文件,然后命令模式下运行 : set list ,查看空白字符的格式,如下图所示:

通过观察我们发现,空白字符都是 ^I 的格式,这时我们只需要在 vim 的命令模式下执行以下命令将其替换掉就可以了:
:%s/^I//g注意:
^I是通过ctrl + I打出来的,而不是直接输入的,这里需要注意。
操作以后,发现「多余」的空白字符都被删除了,完美~

大功告成。
方案三:awk showtime
可能有些大神「更懒」,连工具都懒得用,那还有没有更简单的方法呢?
既然这样,只能有请上古神器「awk」登场了:
cat origin.csv | awk -F ',' 'NR>1{print "UPDATE `users` SET `score` = " $2 ", `updated_at` = \"" $3 "\" WHERE `id` = " $1 " LIMIT 1;"}'一步到位,就是这么简单粗暴~

总结
以上就是通过三种不同的方式来处批量处理 SQL 文件的内容。
大家在日常工作中是怎么处理类似问题的呢,欢迎在评论区留言讨论。
感谢大家的持续关注~
本作品采用《CC 协议》,转载必须注明作者和本文链接





























 关于 LearnKu
关于 LearnKu




推荐文章: