
为什么计算机科学只有图灵机和lambda演算两种世界观,而量子力学却存在三种世界图景
2 / 0 / 创建于 2年前 /
 canonical 的个人博客
canonical 的个人博客
计算机科学存在两种基本的世界观:图灵机和Lambda演算,它们指出了到达图灵完备的两条技术路线。但是量子力学中却存在着三种世界图景:薛定谔图景,海森堡图景和狄拉克图景。为什么计算机科学有两种基本世界观,但是量子力学却存在三种世界图景?它们之间是否存在什么对应关系?
先说结论,计算机科学中实现图灵完备的基本技术路线也可以被看作是有三条,它们和量子力学的世界图景存在如下对应关系:
- 图灵机 <=> 薛定谔图景
- Lambda演算 <=> 海森堡图景
- 可逆计算 <=> 狄拉克图景
以下是具体的分析。首先,量子力学中最基本的世界图景同样是两个,狄拉克图景是前两种图景自然衍生的结果
- 薛定谔图景中算子固定,态函数演化
- 海森堡图景中态函数固定,而算子演化
- 狄拉克图景(相互作用图景)中态函数和算符都不固定,它们都随时间演化
在狄拉克图景中,我们将系统的Hamiltion量拆分为已知的部分和待研究的微小扰动
H = H_0 + H_1
然后研究系统如何偏离已知模型进行演化,即我们所关心的是差量描述的演化情况。在相互作用图景下,态函数和算符都随时间演化。
i\hbar \frac d {dt} |\psi_I(t)\rangle = H_1|\psi_I(t)\rangle \
i\hbar \frac d {dt} |A_I(t)\rangle = [A_I(t), H_0]
根据这三种图景都可以得到完全一致的物理测量结果
\langle \psi_S(t)|A_S|\psi_S(t)\rangle = \langle \psi_H|A_H(t)|\psi_H\rangle
= \langle \psi_I(t)|A_I(t)|\psi_I(t)\rangle
有趣的是,相互作用图景是物理学家在实际工作中使用最多的图景。事实上,数学物理中存在一个专门的分支:微扰论(Perturbation Theroy),它系统化的研究在已知模型的基础上添加微小的扰动量,新的模型如何演化的问题。而理论物理中绝大多数有价值的计算都是在微扰论的框架下进行。
如果把量子力学和计算机理论做个对比,我们会发现量子力学中的世界图景和计算机理论的世界观之间存在一个有趣的对应关系。
- 图灵机是一种结构固化的机器,它具有可枚举的有限的状态集合,只能执行有限的几条操作指令,但是可以从无限长的纸带上读取和保存数据。例如我们日常使用的电脑,它在出厂的时候硬件功能就已经确定了,但是通过安装不同的软件,传入不同的数据文件,最终它可以自动产生任意复杂的目标输出。图灵机的计算过程在形式上可以写成
目标输出 = 固定的机器 (无限复杂的输入)
- 与图灵机相反的是,lambda演算的核心概念是函数,一个函数就是一台小型的计算机器,函数的复合仍然是函数,也就是说可以通过机器和机器的递归组合来产生更加复杂的机器。lambda演算的计算能力与图灵机等价,这意味着如果允许我们不断创建更加复杂的机器,即使输入一个常数0,我们也可以得到任意复杂的目标输出。
目标输出 = 无限复杂的机器(固定的输入)
计算机科学中的两个基本理论在形式上都可以被表达为 Y = F(X)这样一种抽象的形式。如果仿照狄拉克图景的导出过程,我们认识到在真实的物理世界中,人类的认知总是有限的,所有的量都需要区分已知的部分和未知的部分,因此我们需要进行如下分解:
\begin{aligned}
Y &= F(X) \
&= (F_0 + F_1) (X_0+X_1)\
&= F_0(X_0) + \Delta
\end{aligned}
重新整理一下符号,我们就得到了一个适应范围更加广泛的计算模式
Y = F(X) \oplus \Delta
除了函数运算F(X)之外,这里出现了一个新的结构运算符⊕,它表示两个元素之间的合成运算,并不是普通数值意义上的加法,同时引出了一个新的概念:差量△。△的特异之处在于,它必然包含某种负元素,F(X)与△合并在一起之后的结果并不一定是“增加”了输出,而完全可能是“减少”。
在物理学中,差量△存在的必然性以及△包含逆元这一事实完全是不言而喻的,因为物理学的建模必须要考虑到两个基本事实:
- 世界是“测不准”的,噪声永远存在
- 模型的复杂度要和问题内在的复杂度相匹配,它捕获的是问题内核中稳定不变的趋势及规律。
例如,对以下的数据
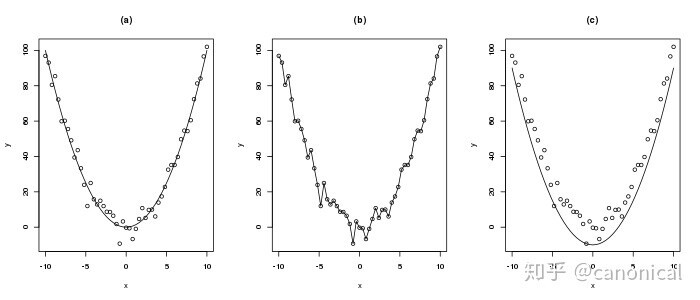
我们所建立的模型只能是类似图(a)中的简单曲线,图(b)中的模型试图精确拟合每一个数据点在数学上称之为过拟合,它难以描述新的数据,而图(c)中限制差量只能为正值则会极大的限制模型的描述精度。
可逆计算理论
可逆计算理论提出了一个新的软件构造公式,将以上的计算模式落实为实现图灵完备的一条具体的技术路线。
App = Delta x-extends Generator<DSL>- App : 所需要构建的目标应用程序
- DSL: 领域特定语言(Domain Specific Language),针对特定业务领域定制的业务逻辑描述语言,也是所谓领域模型的文本表示形式
- Generator : 根据领域模型提供的信息,反复应用生成规则可以推导产生大量的衍生代码。实现方式包括独立的代码生成工具,以及基于元编程(Metaprogramming)的编译期模板展开
- Delta : 根据已知模型推导生成的逻辑与目标应用程序逻辑之间的差异被识别出来,并收集在一起,构成独立的差量描述
- x-extends: 差量描述与模型生成部分通过类似面向切面编程(Aspect Oriented Programming)的技术结合在一起,这其中涉及到对模型生成部分的增加、修改、替换、删除等一系列操作
DSL是对关键性领域信息的一种高密度的表达,它直接指导Generator生成代码,这一点类似于图灵计算通过输入数据驱动机器执行内置指令。而如果把Generator看作是文本符号的替换生成,则它的执行和复合规则完全就是lambda演算的翻版。差量合并在某种意义上是一种很新奇的操作,因为它要求我们具有一种细致入微、无所不达的变化收集能力,能够把散布系统各处的同阶小量分离出来并合并在一起,这样差量才具有独立存在的意义和价值。同时,系统中必须明确建立逆元和逆运算的概念,在这样的概念体系下差量作为“存在”与“不存在”的混合体才可能得到表达。
图灵机能够实现图灵完备的根本原因在于图灵机可以被看作是一种虚拟机,它可以模拟所有其他的自动计算机器,而如果我们不断提升虚拟机的抽象层次,就会得到可以直接”运行”所谓领域特定语言(DSL)的虚拟机,但是因为DSL关注的重点是特定领域概念,它必然无法以最便利的方式表达所有通用计算逻辑(否则它就成为了通用语言),必然会导致某种信息溢出,成为所谓的Delta项。
图灵机和lambda演算建立了通用计算机的概念基础,在理论上解决了计算的可行性问题,即为什么可以存在一种通用的机器执行机械化的动作,使用有限资源来完成所有我们能够想见的计算。在通用计算机已经普及的今天,我们所面临的最大的实际问题是如何有效的进行计算的问题。计算效率的提高依赖于我们发现计算中的“捷径”,而这依赖于我们对问题本质的洞察,而洞察的产生与问题的表述形式息息相关。表象(representation)变换本身甚至就是解决问题的一种方式,因为变换后的问题表象有可能使得解决方案变得清晰可见。可逆计算借助于领域模型和差量描述,提供了一种新的、系统化的表象变换方式,使我们的注意力得以聚焦在待解决的新问题上。
关于表象变换的作用,参见 解耦的方法远不止依赖注入
基于可逆计算的基本公式,我们可以很自然的得到如下推广的软件构造方法
\begin{aligned}
App &= Biz \oplus G1(DSL1) \oplus G2(DSL2) + …\
& \equiv (Biz, DSL1, DSL2, …)
\end{aligned}
如果把Generator(也可以是Translator或者Transformer)看作是已知的背景知识,在符号层面隐去它们的存在(类似于物理学中引入泊松括号),我们可以将App看作是一组DSL所构成的特性向量。也就是说,在第一代、第二代、第三代程序语言的发展过程中,不断的提升抽象层次,但它们仍然都是通用程序语言,但是发展到第四代程序语言,我们很可能得到的不是另一种通用程序语言,而是大量领域特定语言所构成的DSL森林,通过它们我们可以形成对原有程序结构的一种新的表示和认知。
Nop平台
如果把DSL的构造和Delta差量的合并算法标准化,就可以由程序自动完成x-extends运算,从而形成一种新的软件框架技术。Nop平台是基于可逆计算理论实现的新一代的低代码平台,它可以看作是可逆计算理论的一个参考实现。作为演示,它内置了一条差量化的软件生产管线

根据Excel数据模型,Nop平台会自动生成前后端全套代码,包括后端的存储实体、GraphQL服务以及前台页面等。具体来说,从后端到前端的逻辑推理链条可以分解为四个主要模型:
XORM:面向存储层的领域模型
XMeta:针对GraphQL接口层的领域模型,可以直接生成GraphQL的类型定义
XView:在业务层面理解的前端逻辑,采用表单、表格、按钮等少量UI元素,与前端框架无关
XPage:具体使用某种前端框架的页面模型
整个生成过程可以用如下公式表达
$$
\begin{aligned}
XORM &= Generator\langle XExcel \rangle + \Delta XORM \
XMeta &= Generator\langle XORM \rangle + \Delta XMeta \
GraphQL &= Builder\langle XMeta\rangle + BizModel\
XView &= Generator\langle XMeta\rangle + \Delta XView \
XPage &= Generator\langle XView\rangle + \Delta XPage\
\end{aligned}
$$
推理关系的各个步骤都是可选环节:我们可以从任意步骤直接开始,也可以完全舍弃此前步骤所推理得到的所有信息。例如我们可以手动增加xview模型,并不需要它一定具有特定的xmeta支持,也可以直接新建page.yaml文件,按照AMIS组件规范编写JSON代码,AMIS框架的能力完全不会受到推理管线的限制。
在日常开发中,我们经常可以发现一些逻辑结构之间存在相似性和某种不精确的衍生关系,例如后端数据模型与前端页面之间密切的关联,对于最简单的情况,我们可以根据数据模型直接推导得到它对应的增删改查页面,或者反向根据表单字段信息推导得到数据库存储结构。但是,这种不精确的衍生关系很难被现有的技术手段所捕获和利用,如果强行约定一些关联规则,则只能应用于非常受限的特定场景,而且还会导致与其他技术手段的不兼容性,难以复用已有的工具技术,也难以适应需求从简单到复杂的动态演化。
Nop平台基于可逆计算理论为实现这种面向动态相似性的复用提供了标准的技术路线:
借助于嵌入式元编程和代码生成,任意结构A和C之间都可以建立一条推理管线
将推理管线分解为多个步骤 : A => B => C
进一步将推理管线差量化:A =>
_B=> B =>_C=> C每一个环节都允许暂存和透传本步骤不需要使用的扩展信息
基于可逆计算理论设计的低代码平台NopPlatform已开源:
- gitee: canonical-entropy/nop-entropy
- github: entropy-cloud/nop-entropy
- 开发示例:docs/tutorial/tutorial.md
- 可逆计算原理和Nop平台介绍及答疑_哔哩哔哩_bilibili
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: