
为什么 k8s 上 0.5 核的 pod 这么忙?
0 / 4 / 创建于 2年前 /
 seth-shi 的个人博客
seth-shi 的个人博客
- 我们的技术总监在我写广告合并请求的业务时, 和我说了一句现在的服务是不是都是运行在
0.5核的节点上, 需要注意设置一下参数
- 然后我回去看了一下, 我们的
golang部分服务是运行在k8s上0.5核的pod, 然后跑在多台8核的物理节点上 - 然后程序中可以通过以下命令打印出当前的
GOMAXPROCS, 服务虽然运行在pod上,但打印的是实际的宿主机的核心数
package main
import (
"fmt"
"runtime"
)
func main() {
// runtime.GOMAXPROCS(1) : 设置为 1
fmt.Printf("当前: %d", runtime.GOMAXPROCS(0))
// 8
}
- 先说解决方案, 直接使用github.com/uber-go/automaxprocs这个库获取到实际的核心数, 然后设置
- 修改完之后, 我们的服务负载就下降了很多
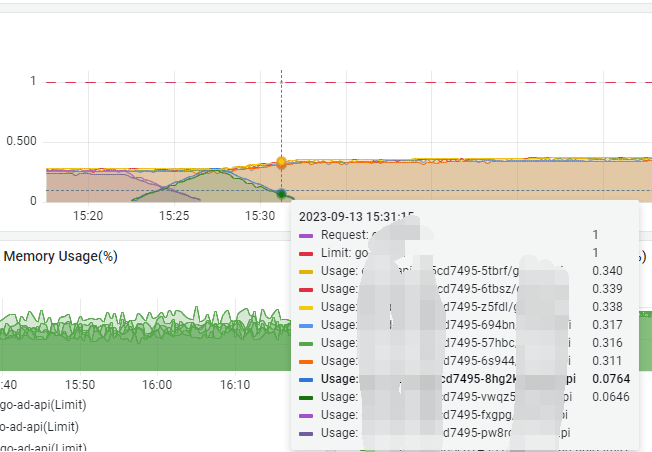
1.png
why
GMP设计思想G代表goroutine协程,M代表machine线程,P代表processor处理器;P包含了运行G所需要的资源,M想要运行goroutine必须先获取P为什么修改
GOMAXPROCS参数可以更高效的运行呢? 简单的来说, 就是本身容器只有0.5核, 但是却设置了GOMAXPROCS=8, 导致会创建出8个P, 每个P由不同的M管理所以当
GOMAXPROCS大于核心数量的时候, 会导致线程不断的切换, 然后cpu有一部分时间被切换占用了(设置为cpu的核心数可以减少切换, 但还是会有切换的场景)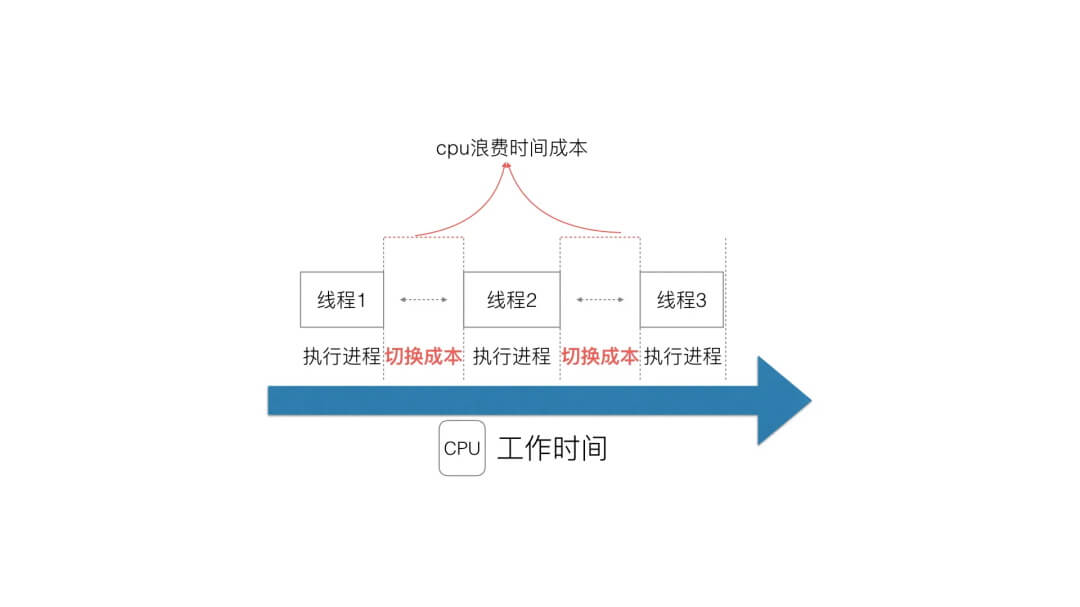
Q 那么设置GOMAXPROCS等于1的时候, 什么时候会出现线程切换? 是不是无法高并发呢?
- 答案是可以的, 虽然同是只能处理
1个任务, 但是cpu实在是太快了. 并且网络io(大部分web服务都是属于网络io)不占用cpu时间
- 根据
G-P-M调度模型,GOMAXPROCS等于1,- 一个
P指为P1运行(假设P1里的本地队列有G0,G1,G2三个goroutine), - 创建新的
M1绑定到P1上
- 一个
- 当
G0里遇到以下场景- 出现系统调用, 文件
io阻塞的时候 - 会把当前的线程
P绑定的M1线程去交给系统调度, - 然后从休眠线程队列/创建新的线程
M2 - 然后绑定到
P1, 继续调度P1后面的G1,G2
- 出现系统调用, 文件
- 当
M1的阻塞调用结束后, 会优先返回P1, 但是P1已经被M2占用, 然后从空闲队列P获取,但是我们只有一个P,也获取失败, 就会把G0放到全局队列中, 等待P1之后获取
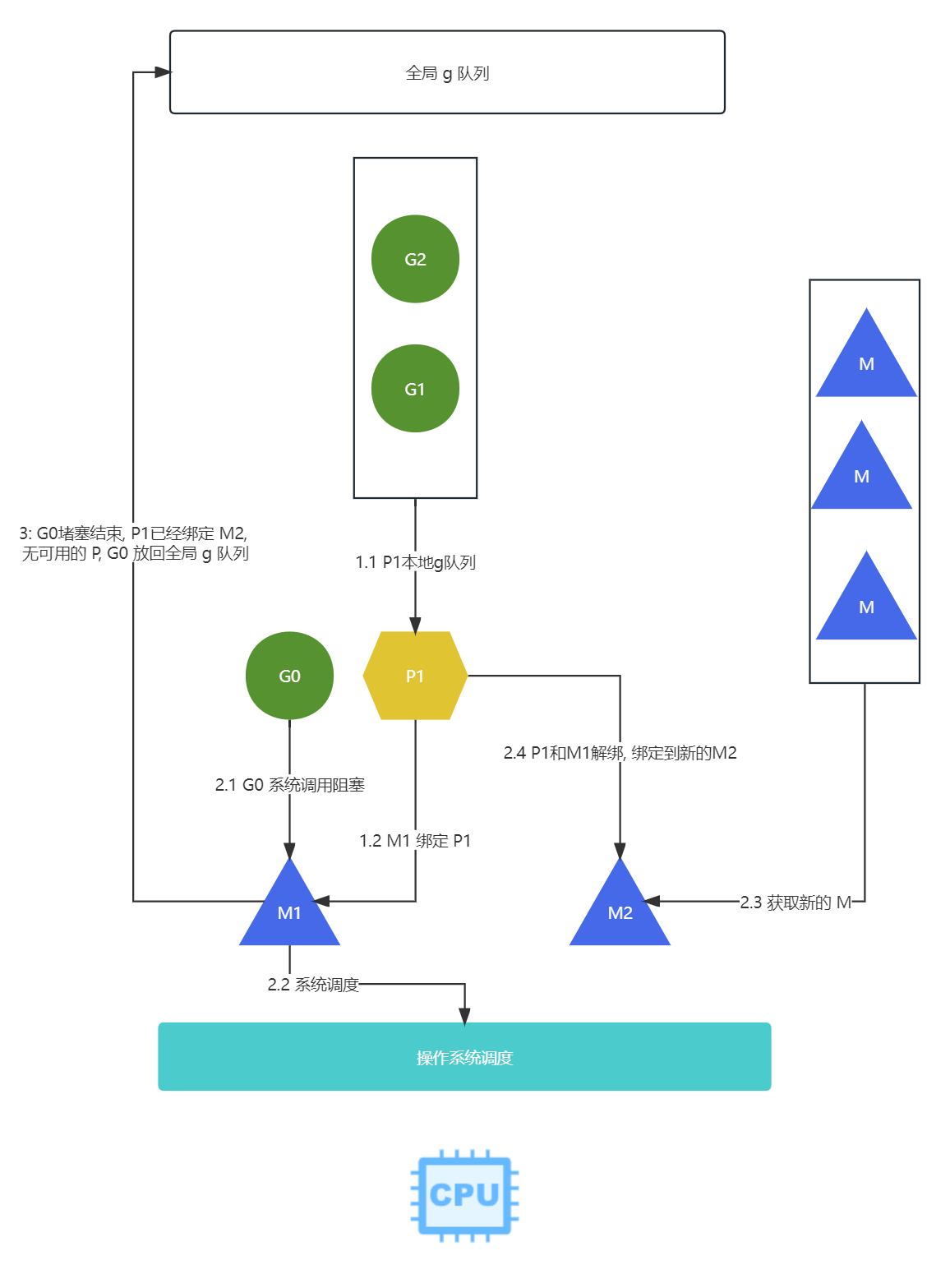
PS
- 网络
io不会造成阻塞, 因为golang在网络请求时,其后台通过kqueue(MacOS),epoll(Linux)或 iocp(Windows来实现IO多路复用 - 所以网络
io密集的服务, 即使核心数量不多,golang也能处理高并发请求
引用
本作品采用《CC 协议》,转载必须注明作者和本文链接








 关于 LearnKu
关于 LearnKu




推荐文章: