
golang 结合 cobra 使用 chatgpt qdrant 实现 ai知识库 cli
2 / 4 / 创建于 2年前
 websong 的个人博客
websong 的个人博客
golang 结合 cobra 使用 chatgpt qdrant 实现 ai知识库 cli
流程
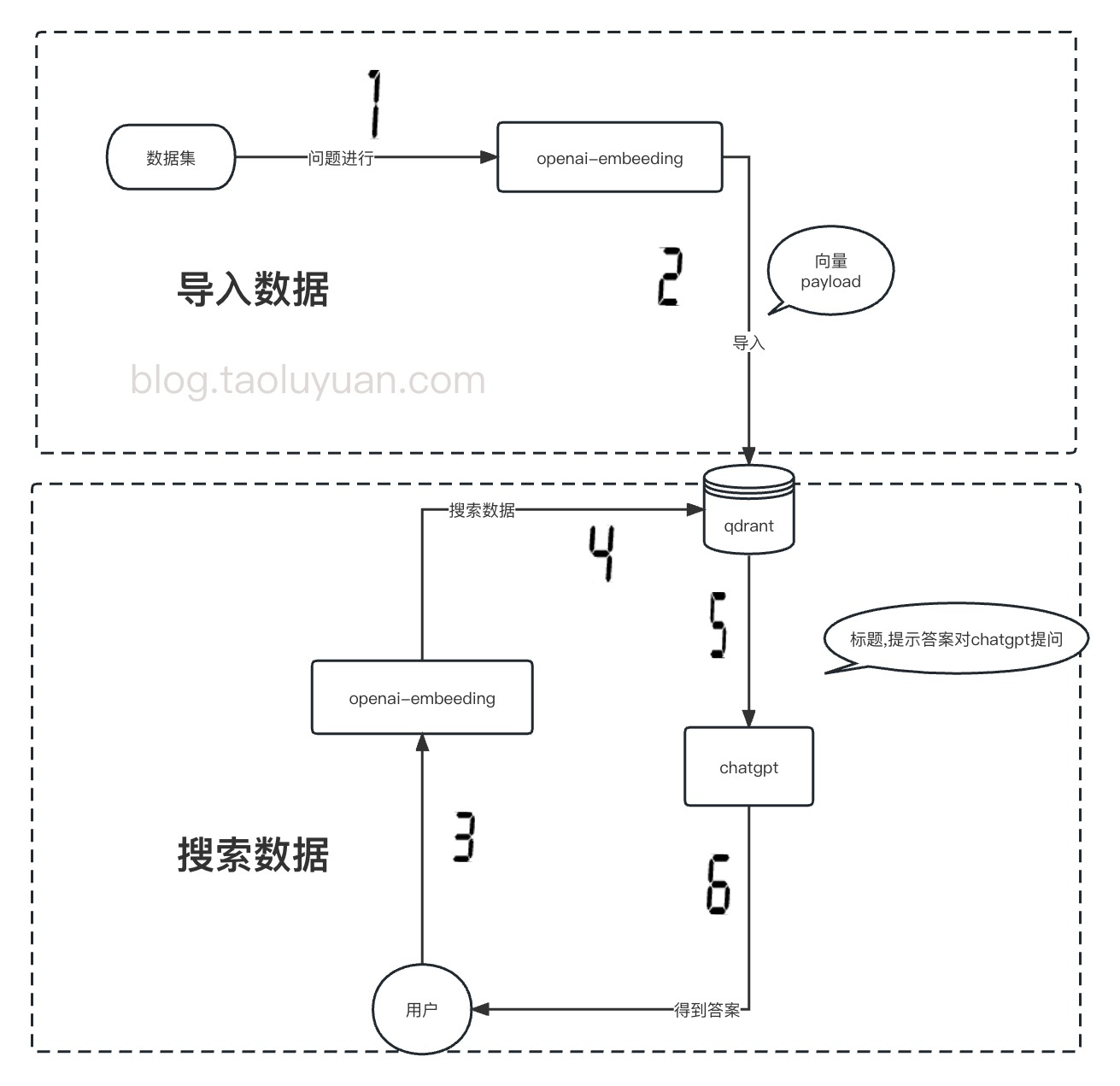
- 将数据集 通过 openai embedding 得到向量+组装payload,存入 qdrant
- 用户进行问题搜索,通过 openai embedding 得到向量,从 qdrant 中搜索相似度大于0.8的数据
- 从 qdrant 中取出数据得到参考答案
- 将问题标题+参考答案,组装成promot 向gpt进行提问,得到偏向于 已有知识库设定的扩展知识回答
kabi 知识库的导入和搜索
仓库地址:https://github.com/webws/embedding-knowledge-base
kabi 是使用 golang 基于 openai chatgpt embedding + qdrant 实现知识库的导入和问答
❯ kabi -h
a local knowledge base, based on chatgpt and qdrant
usage:
kbai [flags]
kbai [command]
available commands:
completion generate the autocompletion script for the specified shell
help help about any command
import import data to vector database
search ask the knowledge base example: kbai ask --msg 'first, the chicken or the egg'
flags:
--apikey string openai apikey:default from env apikey
--collection string qdrant collection name default: kubernetes (default "kubernetes")
-h, --help help for kbai
--proxy string http client proxy default:socks5://127.0.0.1:1080 (default "socks5://127.0.0.1:1080")
--qdrant string qdrant address default: 127.0.0.1:6334 (default "127.0.0.1:6334")
--vectorsize uint qdrant vector size default: 1536 (default 1536)
use "kbai [command] --help" for more information about a command.启动向量数据库
qdrant 是一个开源的向量搜索引擎,支持多种向量距离计算方式
docker 运行 qdrant
docker run --rm -p 6334:6334 qdrant/qdrantkbai库导入数据到知识库
clone 源码运行(后续提供二进制文件)
git clone https://github.com/webws/embedding-knowledge-base.git
cd ./embedding-knowledge-base这里使用的测试数据是k8s相关的知识库,真实数据需自己准备
1.设置 openai apikey
export apikey=xxx2.导入知识库(源码运行)
go run ./ import --datafile ./example/data.jsondata.json 数据格式如下,为 真实数据需自己准备
[
{
"questions": "这是问题",
"answers": "这是答案"
},
]说明:
默认的 代理 是 "socks5://127.0.0.1:1080" 自定义 可使用 --proxy 指定kbai 搜索数据
搜索问题(源码执行)
go run ./ search --msg "网关是什么"回答
the answer to the knowledge base:
在kubernetes中,网关通常指的是ingress(入 口)资源对象。ingress是一种kubernetes api对象,用于配置和管理集群中的http和https流量入口。它充当了从集群外部访问集群内部服务的入口点
results of chatgpt answers with reference answers:
,同时提供负载均衡、ssl/tls终止和基于域名的路由等功能。ingress资源对象定义了一组规则,这些规则指定了通过特定http路径或主机名将请求路由到后端服务的方式。可以使用不同的ingress控制器实现这些规则,如nginx、traefik等。这样就可以在集群中创建多个ingress资源对象来管理不同的流量入口。
only chatgpt answers:
网关是一种网络设备,用于连接两个或多个不同类型的网络,以便实现数据以不同协议进行传递和转换。网关起到了连接不同网络之间的桥梁作用,将两个或多个网络互相连接起来,并负责数据的路由和转发。网关可以是硬件设备,如路由器,也可以是软件程序,如互联网网关。网关通常用于连接本地网络与互联网,使得局域网中的计算机能够访问互联网上的资源。除了连接不同网络的功能,网关还可以实现安全性、负载均衡、数据过滤等功能。- 第一个是知识库的回答(the answer to the knowledge base):
- 第二个 是结合知识库 chatgpt 的回答(results of chatgpt answers with reference answers)
- 第三个 仅chatgpt 回答
可以看出 直接问chatgpt,得到的答案可能跟k8s无关,结合k8s本地知识库,可以让回答偏向 数据集设定的主题
如果直接搜索 与知识库无关或违规问题,将搜索不到任务数据
go run ./ search --msg "苹果不洗能吃吗"
rearch term violation or exceeding categorykabi golang 实现 ai知识库导入原理
导入
- 接入 qdrant 和 openai cleint
- 解释原始知识库数据 为 q(问) a(答)
- 将 问题 经过 openai embedding 得到向量+答案存入 qdrant
以下是 kbai go 导入逻辑代码
qdrantclient := qdrant.newqdrantclient(configflags.qdrant, configflags.collection, configflags.vectorsize)
defer qdrantclient.close()
aiclient, err := ai.newaiclient(configflags.proxy, configflags.apikey)
if err != nil {
return err
}
if err = qdrantclient.createcollection(configflags.collection, configflags.vectorsize); err != nil {
return err
}
qas, err := converttoqas(datafile)
if err != nil {
return err
}
points := []*pb.pointstruct{}
logger.infow("import", "data", qas)
qpslenth := len(qas)
for i, qa := range qas {
embedding, err := aiclient.simplegetvec(qa.questions)
if err != nil {
logger.errorw("simplegetvec", "err", err, "question", qa.questions, "index", i, "total", qpslenth)
return err
}
point := buildpoint(qa.questions, qa.answers, embedding)
points = append(points, point)
}搜索
- 问题搜索,通过 openai embedding 得到向量
- 根据向量 从 qdrant 中搜索相似度大于0.8的数据
- 根据 qdrant 里的知识库答案(参考答案) + 从 chatgpt 提问 得到扩展知识
以下是 kbai go 搜索代码逻辑
qdrantclient := qdrant.newqdrantclient(configflags.qdrant, configflags.collection, configflags.vectorsize)
defer qdrantclient.close()
aiclient, err := ai.newaiclient(configflags.proxy, configflags.apikey)
if err != nil {
return err
}
vector, err := aiclient.simplegetvec(msg)
if err != nil {
return err
}
points, err := qdrantclient.search(vector)
if err != nil {
logger.errorw("qdrant search fail", "err", err)
return err
}
if len(points) == 0 {
fmt.println("rearch term violation or exceeding category")
return nil
// return errors.new("rearch term violation or exceeding category")
}
// score less than 0.8, rearch term violation or exceeding category
if points[0].score < 0.8 {
fmt.println("rearch term violation or exceeding category")
return nil
// return errors.new("rearch term violation or exceeding category")
}
本作品采用《CC 协议》,转载必须注明作者和本文链接








 关于 LearnKu
关于 LearnKu




推荐文章: