
http详解
6 / 0 / 创建于 2年前 /
 lilei12138 的个人博客
lilei12138 的个人博客
当你请求请求一次接口的时候go会开几个协程?
服务端keep-alive?
上传大文件的时候,会不会把大文件全部加载到内存中?
简单http的源码分析,解答疑问。
本文地址hhttps://github.com/luxun9527/go-lib,如果对您有帮助,您的点赞、评论、star都是我更新的动力。
http从tcp中读出数据到执行我们的业务代码的流程
1、go http默认的读缓存是4096,在读取一次之后,进行http各种相关信息的各种解析。
w, err := c.readRequest(ctx)–> readRequest()–>tp.ReadLine()
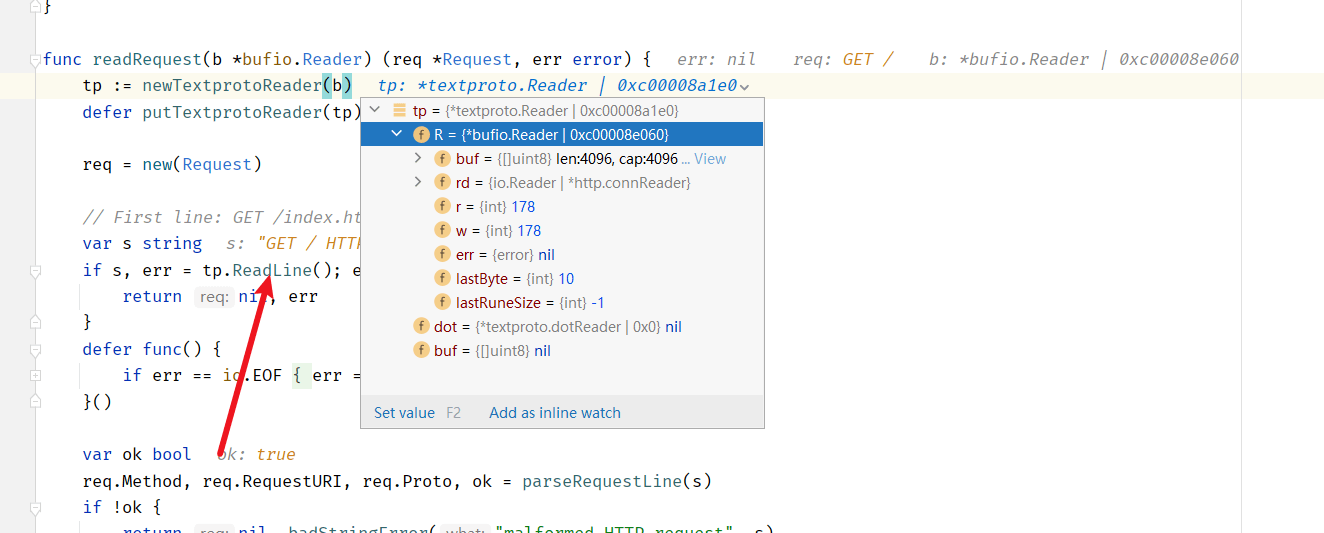
在这一步会从tcp连接中读取4096个字节。进行一系列处理后给request,response赋值

2、执行我们的业务代码
serverHandler{c.server}.ServeHTTP(w, w.req)如果在执行我们的业务代码的时候buf中的4096不足还是会去tcp连接中读取的。
3、在一个tcp连接上一直循环这个过程。
当你请求请求一次接口的时候go会开几个协程?
先说结论:在连接不复用的情况,一次请求会开两个协程。在连接复用的情况下,空闲的连接不会开启backgroupRead协程。只有当有数据解析的时候才会开启这个协程。
go install github.com/link1st/go-stress-testing@latest
mv $GOPATH/bin/go-stress-testing.exe $GOPATH/bin/stress.exe
stress -c 1000 -n 1000 -u http://localhost:8888/func TestHttpGoroutine(t *testing.T) {
go func() {
http.ListenAndServe("0.0.0.0:8899", nil)
}()
if err := http.ListenAndServe(":8888", http.HandlerFunc(func(writer http.ResponseWriter, request *http.Request) {
select {
case <-request.Context().Done():
log.Println("request canceled")
}
})); err != nil {
log.Fatal(err)
}
}pprof 分析 192.168.2.109:8899/debug/pprof/ 可以看到当我们以1000个协程请求一次,对应的服务端会启动2000个协程,一次请求会启动两个协程。
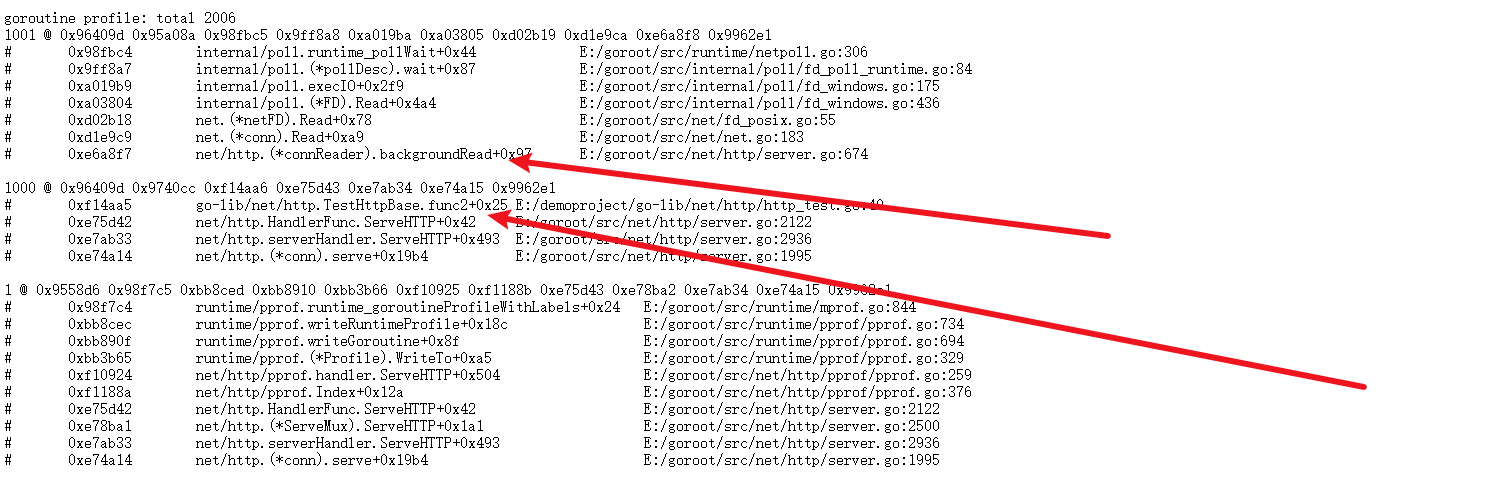
http.ListenAndServe-->server.ListenAndServe()-->srv.Serve(ln)-->rw, err := l.Accept()
-->go c.serve(connCtx)
for {
rw, err := l.Accept()
//拿到一个连接
if err != nil {
if srv.shuttingDown() {
return ErrServerClosed
}
if ne, ok := err.(net.Error); ok && ne.Temporary() {
if tempDelay == 0 {
tempDelay = 5 * time.Millisecond
} else {
tempDelay *= 2
}
if max := 1 * time.Second; tempDelay > max {
tempDelay = max
}
srv.logf("http: Accept error: %v; retrying in %v", err, tempDelay)
time.Sleep(tempDelay)
continue
}
return err
}
connCtx := ctx
if cc := srv.ConnContext; cc != nil {
connCtx = cc(connCtx, rw)
if connCtx == nil {
panic("ConnContext returned nil")
}
}
tempDelay = 0
c := srv.newConn(rw)
c.setState(c.rwc, StateNew, runHooks) // before Serve can return
//开启协程处理
go c.serve(connCtx)
}serve(ctx context.Context)
for {
w, err := c.readRequest(ctx)
if c.r.remain != c.server.initialReadLimitSize() {
// If we read any bytes off the wire, we're active.
c.setState(c.rwc, StateActive, runHooks)
}
//在读取完一次请求所有内容之后,,开启一个协程在后台读取。保证连接,当连接出现问题时候
//及时通知。
if requestBodyRemains(req.Body) {
registerOnHitEOF(req.Body, w.conn.r.startBackgroundRead)
} else {
w.conn.r.startBackgroundRead()
}
serverHandler{c.server}.ServeHTTP(w, w.req)
inFlightResponse = nil
w.cancelCtx()
if c.hijacked() {
return
}
w.finishRequest()
c.rwc.SetWriteDeadline(time.Time{})
if !w.shouldReuseConnection() {
if w.requestBodyLimitHit || w.closedRequestBodyEarly() {
c.closeWriteAndWait()
}
return
}
}func (cr *connReader) startBackgroundRead() {
cr.lock()
defer cr.unlock()
if cr.inRead {
panic("invalid concurrent Body.Read call")
}
if cr.hasByte {
return
}
cr.inRead = true
cr.conn.rwc.SetReadDeadline(time.Time{})
go cr.backgroundRead()
}
func (cr *connReader) backgroundRead() {
n, err := cr.conn.rwc.Read(cr.byteBuf[:])
cr.lock()
if n == 1 {
cr.hasByte = true
// We were past the end of the previous request's body already
// (since we wouldn't be in a background read otherwise), so
// this is a pipelined HTTP request. Prior to Go 1.11 we used to
// send on the CloseNotify channel and cancel the context here,
// but the behavior was documented as only "may", and we only
// did that because that's how CloseNotify accidentally behaved
// in very early Go releases prior to context support. Once we
// added context support, people used a Handler's
// Request.Context() and passed it along. Having that context
// cancel on pipelined HTTP requests caused problems.
// Fortunately, almost nothing uses HTTP/1.x pipelining.
// Unfortunately, apt-get does, or sometimes does.
// New Go 1.11 behavior: don't fire CloseNotify or cancel
// contexts on pipelined requests. Shouldn't affect people, but
// fixes cases like Issue 23921. This does mean that a client
// closing their TCP connection after sending a pipelined
// request won't cancel the context, but we'll catch that on any
// write failure (in checkConnErrorWriter.Write).
// If the server never writes, yes, there are still contrived
// server & client behaviors where this fails to ever cancel the
// context, but that's kinda why HTTP/1.x pipelining died
// anyway.
}
if ne, ok := err.(net.Error); ok && cr.aborted && ne.Timeout() {
//当读取超时的时候走到这里。当serverHandler{c.server}.ServeHTTP(w, w.req)执行完
//正常是这个调用链触发finishRequest()--> abortPendingRead()--> cr.conn.rwc.SetReadDeadline(aLongTimeAgo)
// Ignore this error. It's the expected error from
// another goroutine calling abortPendingRead.
} else if err != nil {
//当出现读取错误的时候走到这里。出现比较多的情况是客户端取消,连接断开。
cr.handleReadError(err)
}
cr.aborted = false
cr.inRead = false
cr.unlock()
cr.cond.Broadcast()
}
// handleReadError is called whenever a Read from the client returns a
// non-nil error.
//
// The provided non-nil err is almost always io.EOF or a "use of
// closed network connection". In any case, the error is not
// particularly interesting, except perhaps for debugging during
// development. Any error means the connection is dead and we should
// down its context.
//
// It may be called from multiple goroutines.
func (cr *connReader) handleReadError(_ error) {
//调用cancel通知结束。监听http的cancelCtx的协程会收到通知。
cr.conn.cancelCtx()
cr.closeNotify()
}
服务端keep-alive
go 服务端是默认开启http keep-alive的。http.Server{}.SetKeepAlivesEnabled()可以通过这个设置禁用
for {
w, err := c.readRequest(ctx)
if c.r.remain != c.server.initialReadLimitSize() {
// If we read any bytes off the wire, we're active.
c.setState(c.rwc, StateActive, runHooks)
}
//可以开启这个才会一直在这个tcp连接中读取
if !w.conn.server.doKeepAlives() {
// We're in shutdown mode. We might've replied
// to the user without "Connection: close" and
// they might think they can send another
// request, but such is life with HTTP/1.1.
return
}
}上传大文件的时候,会不会把大文件全部加载到内存中?
先说答案:不会,但是会创几个32MB的buf也是会占用一点内存。
源码分析调用链
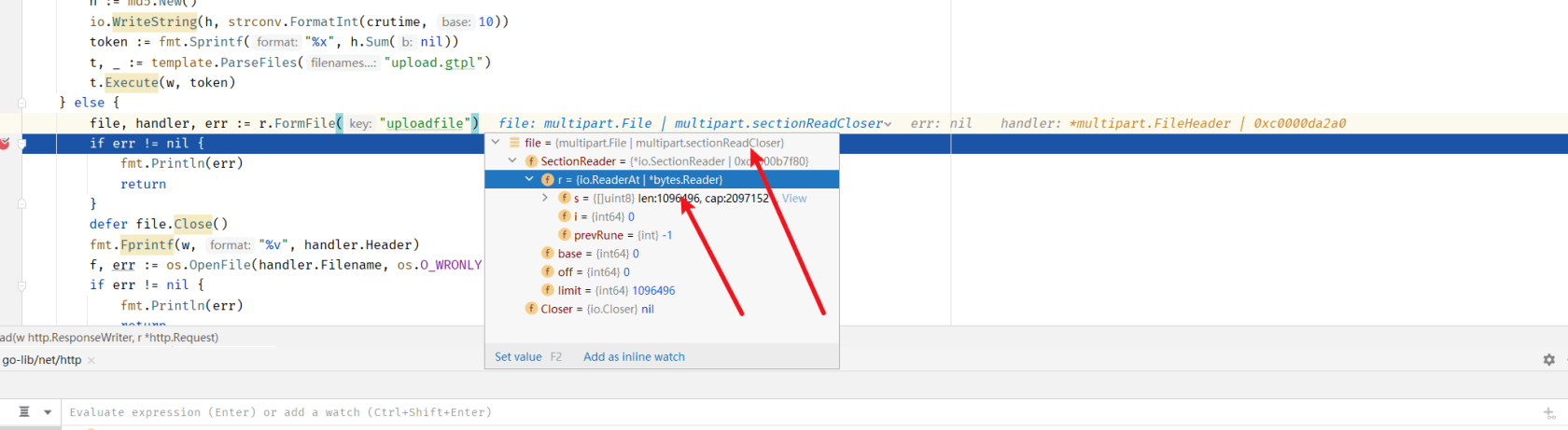
r.FormFile(“uploadfile”)
err := r.ParseMultipartForm(defaultMaxMemory)
f, err := mr.ReadForm(maxMemory)
readForm(maxMemory int64)
p, err := r.nextPart(false, maxMemoryBytes, maxHeaders)
package http
import (
"crypto/md5"
"fmt"
"html/template"
"io"
"net/http"
_ "net/http/pprof"
"os"
"strconv"
"testing"
"time"
)
func TestUpload(t *testing.T) {
go func() {
http.ListenAndServe("0.0.0.0:8899", nil)
}()
http.HandleFunc("/upload", upload)
http.ListenAndServe(":8888", nil)
}
// 处理 /upload 逻辑
func upload(w http.ResponseWriter, r *http.Request) {
fmt.Println("method:", r.Method) // 获取请求的方法
if r.Method == "GET" {
crutime := time.Now().Unix()
h := md5.New()
io.WriteString(h, strconv.FormatInt(crutime, 10))
token := fmt.Sprintf("%x", h.Sum(nil))
t, _ := template.ParseFiles("upload.gtpl")
t.Execute(w, token)
} else {
file, handler, err := r.FormFile("uploadfile")
if err != nil {
fmt.Println(err)
return
}
defer file.Close()
fmt.Fprintf(w, "%v", handler.Header)
f, err := os.OpenFile(handler.Filename, os.O_WRONLY|os.O_CREATE|os.O_TRUNC, 0666)
if err != nil {
fmt.Println(err)
return
}
defer f.Close()
io.Copy(f, file)
}
}//将p可以理解为tcp连接中拷贝32MB到内存b中
n, err := io.CopyN(&b, p, maxFileMemoryBytes+1)
if err != nil && err != io.EOF {
return nil, err
}
//如果文件大于32MB会创建一个临时文件来保存
if n > maxFileMemoryBytes {
if file == nil {
file, err = os.CreateTemp(r.tempDir, "multipart-")
if err != nil {
return nil, err
}
}
numDiskFiles++
if _, err := file.Write(b.Bytes()); err != nil {
return nil, err
}
if copyBuf == nil {
copyBuf = make([]byte, 32*1024) // same buffer size as io.Copy uses
}
// os.File.ReadFrom will allocate its own copy buffer if we let io.Copy use it.
type writerOnly struct{ io.Writer }
//拷贝文件从tcp连接中拷贝数据到临时文件中,使用32MB的缓冲区。
remainingSize, err := io.CopyBuffer(writerOnly{file}, p, copyBuf)
if err != nil {
return nil, err
}
fh.tmpfile = file.Name()
fh.Size = int64(b.Len()) + remainingSize
fh.tmpoff = fileOff
fileOff += fh.Size
if !combineFiles {
if err := file.Close(); err != nil {
return nil, err
}
file = nil
}
} else {
fh.content = b.Bytes()
fh.Size = int64(len(fh.content))
maxFileMemoryBytes -= n
maxMemoryBytes -= n
}文件大于32MB

文件小于32MB
使用go的官方库作为http客户端,一次http请求会创几个协程
先说结论:在不使用连接池的情况,一次请求会创建两个协程。
使用pprof分析。每次请求都会创建两个协程。
package pool
import (
"go.uber.org/atomic"
"io/ioutil"
"log"
"net/http"
_ "net/http/pprof"
"sync"
"testing"
"time"
)
// var _httpCli = &http.Client{
// //Timeout: time.Duration(15) * time.Second,
//
// //Transport: &http.Transport{
// // MaxIdleConns: 10, //最大空闲
// // MaxIdleConnsPerHost: 5, //每个host最多保持多少个空闲连接, 如果连接数超过MaxIdleConnsPerHost 则会关闭多余的连接。
// // MaxConnsPerHost: 5, //MaxConnPerHost 10 决定了每个host最大的连接数,包括正在使用的,正在建立连接的,空闲的,决定了最大并发请求。超过则会阻塞
// // IdleConnTimeout: 1000 * time.Second, //空闲的连接超时时间,当超过这个时间则会关闭空闲的连接
// //},
// //5个goroutine 并发请求,会有两个并发,其他三个阻塞,
// }
var _httpCli = http.DefaultClient
func get(url string) {
resp, err := _httpCli.Get(url)
if err != nil {
// do nothing
return
}
defer resp.Body.Close()
_, err = ioutil.ReadAll(resp.Body)
if err != nil {
// do nothing
return
}
}
func TestLong(t *testing.T) {
go func() {
http.ListenAndServe("0.0.0.0:9999", nil)
}()
go func() {
for {
for i := 0; i < 50; i++ {
go get("http://127.0.0.1:9090")
}
time.Sleep(time.Second * 3)
}
}()
select {}
}
func TestInitServer(t *testing.T) {
//https://www.cnblogs.com/paulwhw/p/15972645.html
//https://www.jianshu.com/p/43bb39d1d221
go func() {
http.ListenAndServe("0.0.0.0:8899", nil)
}()
var (
lock sync.RWMutex
m = make(map[string]int, 10)
receivedCount atomic.Int32
)
go func() {
for {
time.Sleep(time.Second * 3)
lock.Lock()
log.Printf("client size %v request count %v", len(m), receivedCount.Load())
lock.Unlock()
}
}()
log.Printf("server start %v", 9090)
if err := http.ListenAndServe(":9090", http.HandlerFunc(func(writer http.ResponseWriter, request *http.Request) {
writer.Write([]byte("helloworld"))
receivedCount.Inc()
lock.Lock()
value, ok := m[request.RemoteAddr]
if !ok {
m[request.RemoteAddr] = 1
} else {
value++
m[request.RemoteAddr] = value
}
lock.Unlock()
select {}
})); err != nil {
log.Printf("server start error %v", err)
}
}
3150 @ 0xc137fd 0xc0992a 0xc3ec45 0xc98ea8 0xc99f9a 0xc9bde5 0xe9a1b9 0xeaff4a 0x1011c9f 0xd26e30 0xd27238 0x1012e7e 0xc44e61
# 0xc3ec44 internal/poll.runtime_pollWait+0x44 E:/goroot/src/runtime/netpoll.go:306
# 0xc98ea7 internal/poll.(*pollDesc).wait+0x87 E:/goroot/src/internal/poll/fd_poll_runtime.go:84
# 0xc99f99 internal/poll.execIO+0x2f9 E:/goroot/src/internal/poll/fd_windows.go:175
# 0xc9bde4 internal/poll.(*FD).Read+0x4a4 E:/goroot/src/internal/poll/fd_windows.go:436
# 0xe9a1b8 net.(*netFD).Read+0x78 E:/goroot/src/net/fd_posix.go:55
# 0xeaff49 net.(*conn).Read+0xa9 E:/goroot/src/net/net.go:183
# 0x1011c9e net/http.(*persistConn).Read+0x1de E:/goroot/src/net/http/transport.go:1943
# 0xd26e2f bufio.(*Reader).fill+0x26f E:/goroot/src/bufio/bufio.go:106
# 0xd27237 bufio.(*Reader).Peek+0x177 E:/goroot/src/bufio/bufio.go:144
# 0x1012e7d net/http.(*persistConn).readLoop+0x27d E:/goroot/src/net/http/transport.go:2107
3150 @ 0xc137fd 0xc2428a 0x1015b0e 0xc44e61
# 0x1015b0d net/http.(*persistConn).writeLoop+0x16d E:/goroot/src/net/http/transport.go:2410
这个是本来的协程非新建的,上面两个是新建的。
3150 @ 0xc137fd 0xc2428a 0x1016d2c 0x1005e5e 0xfe0d8f 0xf82744 0xf81f05 0xf85f4c 0xf84d4f 0xf84658 0x104eda7 0xc44e61
# 0x1016d2b net/http.(*persistConn).roundTrip+0xa6b E:/goroot/src/net/http/transport.go:2638
# 0x1005e5d net/http.(*Transport).roundTrip+0xe1d E:/goroot/src/net/http/transport.go:603
# 0xfe0d8e net/http.(*Transport).RoundTrip+0x4e E:/goroot/src/net/http/roundtrip.go:17
# 0xf82743 net/http.send+0x4c3 E:/goroot/src/net/http/client.go:252
# 0xf81f04 net/http.(*Client).send+0x164 E:/goroot/src/net/http/client.go:176
# 0xf85f4b net/http.(*Client).do+0x116b E:/goroot/src/net/http/client.go:716
# 0xf84d4e net/http.(*Client).Do+0x4e E:/goroot/src/net/http/client.go:582
# 0xf84657 net/http.(*Client).Get+0x137 E:/goroot/src/net/http/client.go:480
# 0x104eda6 go-lib/net/httpclient/pool.get+0x66 E:/demoproject/go-lib/net/httpclient/pool/pool_test.go:29通过pprof的调用链分析,一次请求会创建2个协程。
具体的代码。
client.go
func (c *Client) do(req *Request)
if resp, didTimeout, err = c.send(req, deadline); err != nil {}
resp, err = rt.RoundTrip(req)
transport.go
pconn, err := t.getConn(treq, cm)
t.queueForDial(w)
go t.dialConnFor(w)
func (t *Transport) dialConn(ctx context.Context, cm connectMethod)
go pconn.readLoop()
go pconn.writeLoop()
http 客户端连接池
var _httpCli = &http.Client{
Timeout: time.Duration(15) * time.Second,
Transport: &http.Transport{
MaxIdleConns: 10, //整个连接池,最多能保持多少空闲连接。
MaxIdleConnsPerHost: 5, //每个host最多保持多少个空闲连接, 如果连接数超过MaxIdleConnsPerHost 则会关闭多余的连接。
MaxConnsPerHost: 5, //MaxConnPerHost 10 决定了每个host最大的连接数,包括正在使用的,正在建立连接的,空闲的,决定了最大并发请求。超过则会阻塞
IdleConnTimeout: 1000 * time.Second, //空闲的连接超时时间,当超过这个时间则会关闭空闲的连接
},
}
245 @ 0x537fd 0x6428a 0x44ba70 0x445c71 0x420d8f 0x3c2744 0x3c1f05 0x3c5f4c 0x3c4d4f 0x3c4658 0x48eda7 0x84e61
# 0x44ba6f net/http.(*Transport).getConn+0x7cf E:/goroot/src/net/http/transport.go:1382
# 0x445c70 net/http.(*Transport).roundTrip+0xc30 E:/goroot/src/net/http/transport.go:590
# 0x420d8e net/http.(*Transport).RoundTrip+0x4e E:/goroot/src/net/http/roundtrip.go:17
# 0x3c2743 net/http.send+0x4c3 E:/goroot/src/net/http/client.go:252
# 0x3c1f04 net/http.(*Client).send+0x164 E:/goroot/src/net/http/client.go:176
# 0x3c5f4b net/http.(*Client).do+0x116b E:/goroot/src/net/http/client.go:716
# 0x3c4d4e net/http.(*Client).Do+0x4e E:/goroot/src/net/http/client.go:582
# 0x3c4657 net/http.(*Client).Get+0x137 E:/goroot/src/net/http/client.go:480
# 0x48eda6 go-lib/net/httpclient/pool.get+0x66 E:/demoproject/go-lib/net/httpclient/pool/pool_test.go:29
5 @ 0x537fd 0x4992a 0x7ec45 0xd8ea8 0xd9f9a 0xdbde5 0x2da1b9 0x2eff4a 0x451c9f 0x166e30 0x167238 0x452e7e 0x84e61
# 0x7ec44 internal/poll.runtime_pollWait+0x44 E:/goroot/src/runtime/netpoll.go:306
# 0xd8ea7 internal/poll.(*pollDesc).wait+0x87 E:/goroot/src/internal/poll/fd_poll_runtime.go:84
# 0xd9f99 internal/poll.execIO+0x2f9 E:/goroot/src/internal/poll/fd_windows.go:175
# 0xdbde4 internal/poll.(*FD).Read+0x4a4 E:/goroot/src/internal/poll/fd_windows.go:436
# 0x2da1b8 net.(*netFD).Read+0x78 E:/goroot/src/net/fd_posix.go:55
# 0x2eff49 net.(*conn).Read+0xa9 E:/goroot/src/net/net.go:183
# 0x451c9e net/http.(*persistConn).Read+0x1de E:/goroot/src/net/http/transport.go:1943
# 0x166e2f bufio.(*Reader).fill+0x26f E:/goroot/src/bufio/bufio.go:106
# 0x167237 bufio.(*Reader).Peek+0x177 E:/goroot/src/bufio/bufio.go:144
# 0x452e7d net/http.(*persistConn).readLoop+0x27d E:/goroot/src/net/http/transport.go:2107
5 @ 0x537fd 0x6428a 0x455b0e 0x84e61
# 0x455b0d net/http.(*persistConn).writeLoop+0x16d E:/goroot/src/net/http/transport.go:2410当我们设置http的连接池参数后,协程的数量只会和连接池设置的参数一样。defer resp.Body.Close(),此外要注意,一定要读取response,不然也不能复用http客户端。
本作品采用《CC 协议》,转载必须注明作者和本文链接








 关于 LearnKu
关于 LearnKu




推荐文章: