
mysql in 子查询无法使用索引全表扫描 慎用in
34 / 0 / 创建于 2年前 /
 MissYou-Coding 的个人博客
MissYou-Coding 的个人博客
mysql in 子查询无法使用索引全表扫描 慎用in
背景
最近慢sql 性能优化 发现一个调用频率高的sql 使用 in 子查询,导致外层全表扫描的问题?
为什么会产生这样的问题?特别强调在优化的使用发现 使用in 和优化后的效果差距 300倍,可见全表扫描的效果可多厉害。 mysql 版本 5.6
下面案例推荐使用sql2
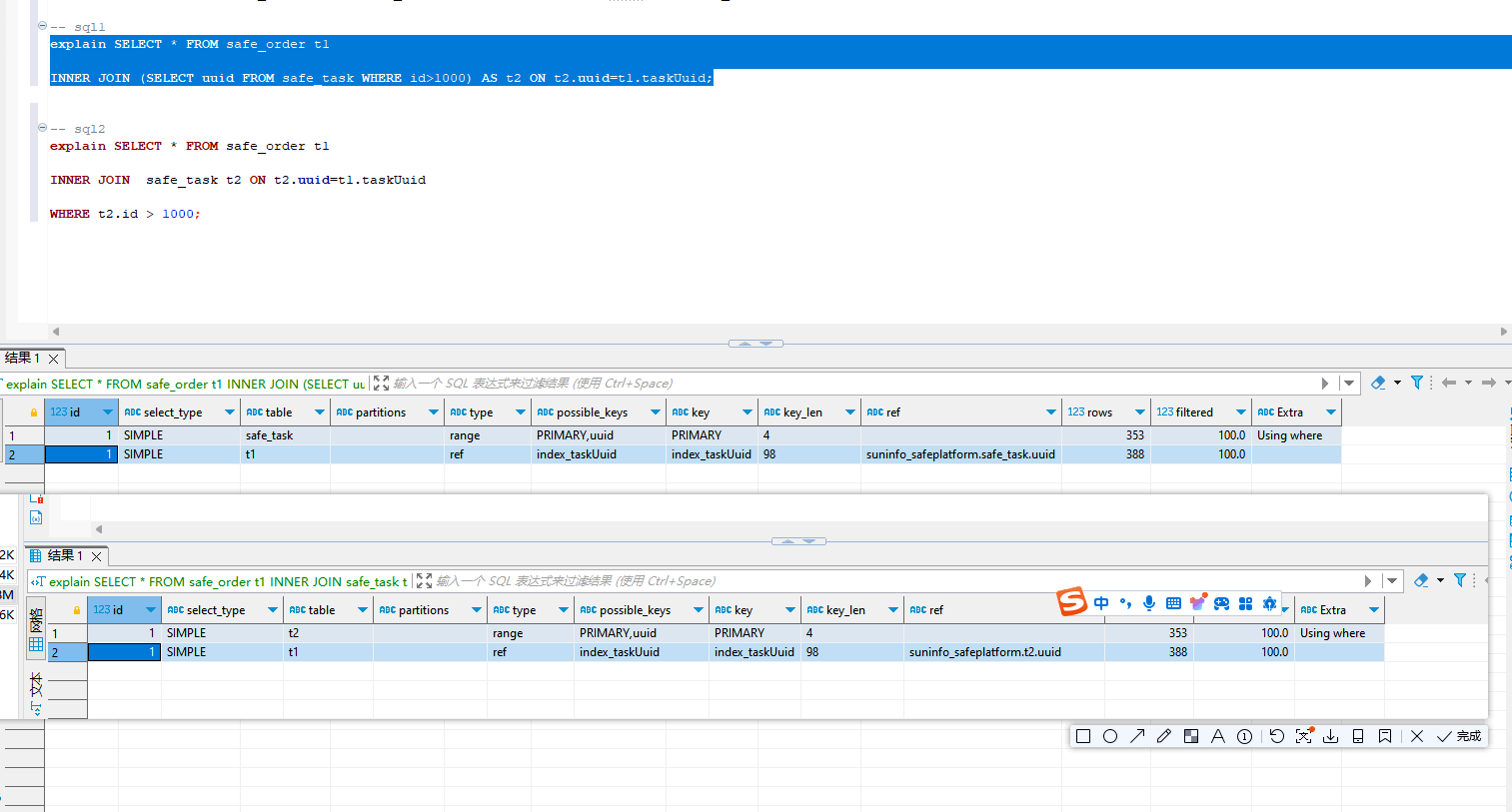
根据您提供的查询执行计划结果,可以看出两个SQL查询语句的执行计划非常相似。在这种情况下,选择哪个SQL查询语句通常取决于可读性和维护性。
对比两个SQL查询语句的执行计划:
第一个查询语句执行计划:
- 优化器选择了使用范围扫描(range)来处理子查询中的过滤条件,然后将其与另一个表进行JOIN操作。
- 查询中使用了WHERE子句进行条件过滤,利用了索引。
- 执行计划显示处理两个表的过程中都使用了索引,执行效率较高。
第二个查询语句执行计划:
- 直接执行表JOIN操作,然后在连接结果上应用WHERE子句进行条件过滤。
- 查询中使用了WHERE子句进行条件过滤,同样利用了索引。
- 执行计划显示处理两个表的过程中都使用了索引,执行效率较高。
建议选择:
根据执行计划的结果,两个SQL查询语句的执行效率相似,并且执行计划均显示使用了索引。因此,在这种情况下,可以选择更易读、更易维护的第二个查询语句:
SELECT * FROM safe_order t1
INNER JOIN safe_task t2 ON t2.uuid=t1.taskUuid
WHERE t2.id > 1000;该查询语句结构清晰,直观地表达了表之间的关系和筛选条件,易于理解和维护。同时,执行计划显示效率较高,符合性能要求。
综上所述,建议选择第二个SQL查询语句作为您的查询语句。希望这能帮助您做出最佳选择,如果您有任何其他问题或需要进一步帮助,请随时告诉我!
详情展开说:
搜集了一下资料发现 www.cnblogs.com/wy123/archive/2017... 这篇 文章特别像我们的场景,子查询中 查询一个条件,然后非常慢使用不上索引
实践
创建表
create table test_table2
(
id int auto_increment
primary key,
pay_id int null,
pay_time datetime null,
other_col varchar(100) null
);
create index test_table2_pay_id_index
on test_table2 (pay_id);
执行计划
explain extended select * from test_table2
where pay_id in(
select pay_id from test_table2
where pay_id > 800
group by pay_id
having count(pay_id) > 2
);
从执行计划可以看出 先执行子查询(SUBQUERY), 然后扫描了全表的数据。
[
{
“id”: 1,
“select_type”: “PRIMARY”,
“table”: “test_table2”,
“partitions”: null,
“type”: “ALL”,
“possible_keys”: null,
“key”: null,
“key_len”: null,
“ref”: null,
“rows”: 1010,
“filtered”: 100,
“Extra”: “Using where”
},
{
“id”: 2,
“select_type”: “SUBQUERY”,
“table”: “test_table2”,
“partitions”: null,
“type”: “range”,
“possible_keys”: “test_table2_pay_id_index”,
“key”: “test_table2_pay_id_index”,
“key_len”: “5”,
“ref”: null,
“rows”: 200,
“filtered”: 100,
“Extra”: “Using where; Using index”
}
]
即使强制指定索引也没有用
explain extended select * from test_table2 force index(test_table2_pay_id_index)
where pay_id in(
select pay_id from test_table2
where pay_id > 800
group by pay_id
having count(pay_id) > 2
);
为什么?
如果直接使用这种查询 (pay_id) in 常量
效率杠杠的,使用了索引 pay_id
explain select * from test_table2 where pay_id in(800,900)
为什么没有命中索引?
子查询的结果是未知的,不能作为外层的索引判断 。【高版本mysql优化器应该会优化成连接查询】
以上就是利用,在SQL 查询语言执行流程中,优化器执行计划生成已经索引选择阶段,子查询的结果无法提供任何的判断依据,因此不能作为外层判断索引的依据,由此导致外层直接全表扫描了。具体可以参考一下 Mysql的查询流程。
MySql查询语句执行流程
如何改进
接改为连接查询非常快
explain extended
select * from test_table2 as t1
inner join (
select pay_id from test_table2
where pay_id > 800
group by pay_id
having count(pay_id) > 2
)as tmp on tmp.pay_id =t1.pay_id;
总结
对于子查询慎用 in,常量情况下可以使用 in 涉及多表操作 in 最好使用 连接查询,性能差异可能几百倍。
原文链接:blog.csdn.net/u012881904/article/d...
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: