
Go 语言中的结构体内存对齐你了解吗?
8 / 1 / 创建于 2年前 /
 江湖十年 的个人博客
江湖十年 的个人博客
这是一篇填坑文章,我在《Go 中空结构体惯用法,我帮你总结全了!》一文中提到了 Go 中空结构体对内存对齐的影响,并承诺近期会写一篇关于 Go 结构体内存对齐的文章。本文就来详述一下在 Go 中什么是结构体内存对齐,以及内存对齐规则是什么。
结构体内存布局
首先我来演示下结构体字段顺序的不同,对结构体占用内存大小的影响,以此来引出什么是结构体内存布局。
示例代码如下:
package main
import (
"fmt"
"unsafe"
)
type T1 struct {
a int8
b string
c bool
}
type T2 struct {
b string
a int8
c bool
}
func main() {
fmt.Printf("T1 size: %d\n", unsafe.Sizeof(T1{}))
fmt.Printf("T2 size: %d\n", unsafe.Sizeof(T2{}))
}
这里定义了两个结构体 T1、T2,它们包含了相同的字段,分别是 a int8、b string、c bool,不过顺序却不相同。
我们可以分析下这两个结构体所占内存空间大小:
首先是字段
a,它的类型为int8,这里的8代表8bit,所以它占所用内存大小为1字节(bytes)。接着是字段
b,它的类型为string,占用内存大小为16字节。
实际上,在运行时字符串是以 reflect.StringHeader 形式存在的,其定义如下:
// StringHeader is the runtime representation of a string.
// It cannot be used safely or portably and its representation may
// change in a later release.
// Moreover, the Data field is not sufficient to guarantee the data
// it references will not be garbage collected, so programs must keep
// a separate, correctly typed pointer to the underlying data.
//
// Deprecated: Use unsafe.String or unsafe.StringData instead.
type StringHeader struct {
Data uintptr
Len int
}
StringHeader 代表的是字符串在程序运行时的真实结构,它包含两个字段,在 64 位机器上,uintptr 和 int 都占用 8 字节,所以 string 类型占用内存大小为 16 字节。
NOTE: 本文示例代码基于 Go 1.22.0,通过
StringHeader的注释可以发现,其已经被标记为弃用,不过这并不影响本文讲解,以后更推荐使用unsafe.String或unsafe.StringData。
如果你感兴趣,可以在 go-review 427095 中看到关于这一变更的 review 记录。
NOTE: 这里所说的占用内存大小,是指字段本身
类型实例所占内存大小,而非字段的值所占内存大小,所以string内存大小是固定的,不随其包含内容长度变化。
- 最后是字段
c,它的类型为bool,占用内存大小为1字节。
现在我们知道了结构体所有字段分别占用的内存大小空间,那么就可以很容易计算出结构体 T1 或 T2 所占用内存大小空间为:1 + 16 + 1 = 18 字节。
真实情况是这样吗?
Go 为我们提供了 unsafe.Sizeof 方法可以计算出一个数据类型实例所占用内存大小的字节数。我们执行示例代码来看一下输出结果:
$ go run main.go
T1 size: 32
T2 size: 24
这个结果有点出乎意料,不仅占用内存大小不等于我们分析的 18 字节,并且 T1 和 T2 两个结构体各自占用的内存大小也不相同。
实际结果与我们计算的结果存在差异,而导致这个差异的原因跟结构体内存布局有关。
我们分别来看下 T1 和 T2 的内存是如何布局的。
T1 结构体内存布局如下:

其中字段 a 占用 1 个字节,假设其内存地址为 0,接下来的第 1~7 内存地址并不包含数据,称为 padding(填充)(稍后会讲解)。
字段 b 内存地址从 8 开始,到 23 结束,占用 16 个字节。
字段 c 内存地址为 24,占用 1 个字节,第 25~31 内存地址同样为 padding。
所以 T1 结构体共计占用 1 + 7 + 16 + 1 + 7 = 32 个字节的内存地址。
T2 结构体内存布局如下:
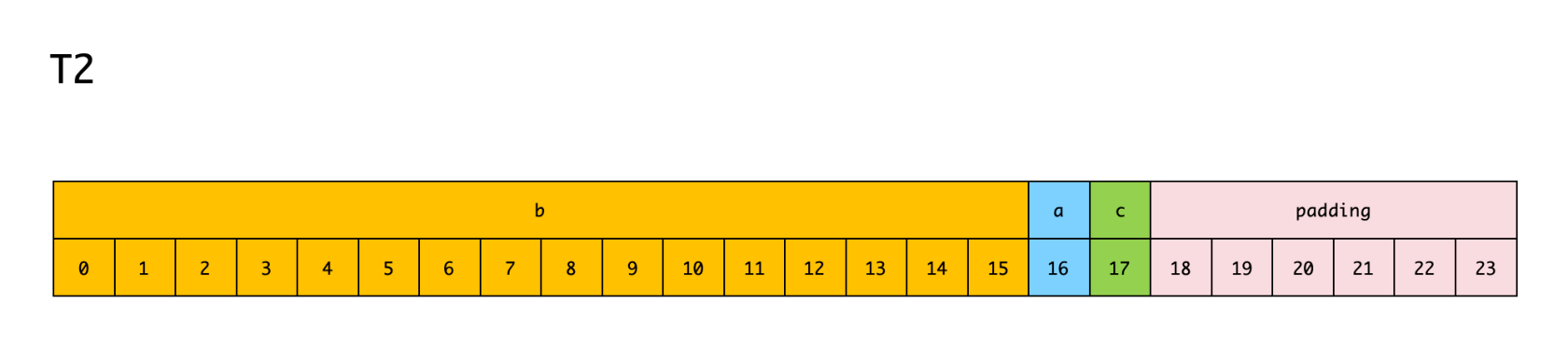
对于 T2 结构体内存布局,我就不挨个字段分析了,一目了然。
T2 结构体共计占用 16 + 1 + 1 + 6 = 24 个字节的内存地址。
影响结构体内存布局的,正是内存对齐。
结构体内存对齐
在 Go 语言中,不同数据类型,都会根据其类型大小具有特定的对齐要求。对于结构体而言,为了满足对齐要求,Go 编译器可能会在结构体字段之间插入额外的空间来进行填充,这个空间就是 padding。
所以在结构体 T1 内存布局中,尽管字段 a 仅占用 1 个字节,但字段 b 的内存地址却并没有紧挨着字段 a,而是在中间插入了 7 个地址空间,作为 padding 进行填充。以此来保证内存地址对齐。
那为什么需要内存对齐呢?
内存对齐实际上是为了适应 CPU 对结构体数据进行快速访问。
这里需要介绍一个概念 字长(word size),是指计算机 CPU 一次(一个访问周期)处理的数据位数(目前通常为 32 位或 64 位)。数据总线大小、指令大小、地址大小通常都是字长的倍数。
我们常说的 32 位芯片,它的字长就是 32 位,即 4 字节。64 位芯片,字长自然就是 64 位,即 8 字节。
至于 CPU 为什么按照 字长 访问,有多种因素考虑,比如,数据处理效率,硬件和总线设计等因素。
假设 T1' 结构体没有内存对齐,那么它的内存布局长这样:
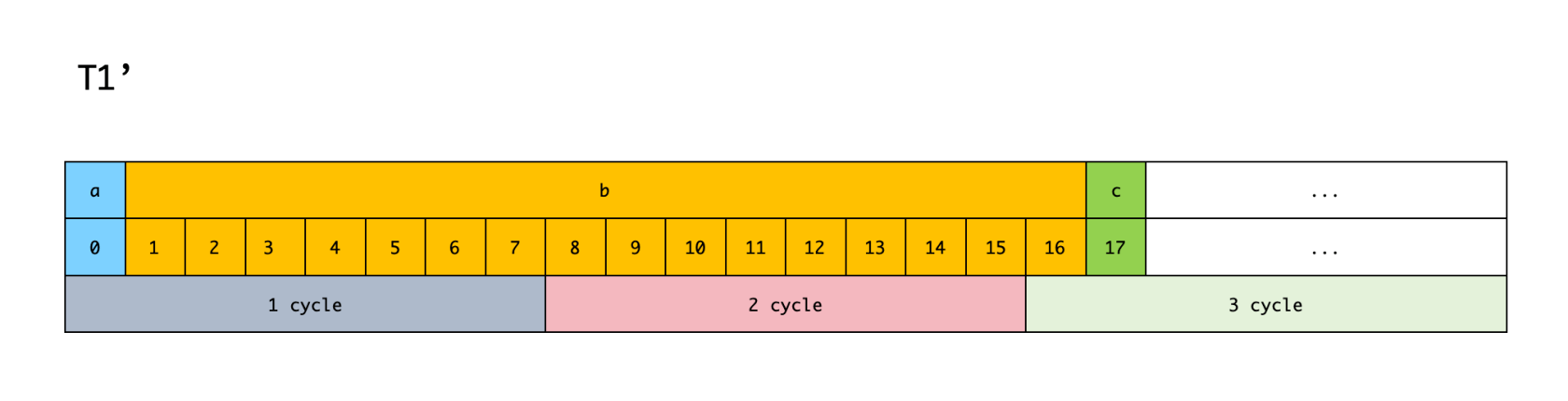
可以看到,这是一个非常紧凑的内存布局,没有 padding 存在,所以 T1' 所占用内存大小为 1 + 16 + 1 = 18 字节。
如果我们想读取 T1' 的 b 字段内容,在 64 位机器上,需要 3 个 CPU 访问周期。
因为 CPU 读取数据的内存地址并不是随意的,而是以 0、8、16 这种按字长的倍数读取。所以在第一个访问周期,CPU 读取内存地址 0~7 的数据,得到字段 b 的前 7 个字节;第二个访问周期,CPU 读取内存地址 8~15 的数据,得到字段 b 的 8~15 个字节;第三个访问周期,CPU 读取内存地址 16~23 的数据,得到字段 b 的最后 1 个字节。
我们再来回顾下已经进行内存对齐的 T1 结构体内存布局:

如果我们想读取 T1 的 b 字段内容,在 64 位机器上,则只需要 2 个 CPU 访问周期。
因为字段 b 的起始地址为 8,刚好是字长的倍数,所以 CPU 可以直接跳转到这里进行读取数据。第一个访问周期,CPU 读取内存地址 8~15 的数据,得到字段 b 的前 8 个字节;第二个访问周期,CPU 读取内存地址 16~23 的数据,得到字段 b 的后 8 个字节。
对比发现,内存对齐虽然会浪费 padding 部分的内存,但是可以加快 CPU 访问速度。
现在我们知道了 Go 中结构体内存对齐的存在,以及为什么需要进行内存对齐。
接下来看一看 Go 中结构体内存对齐的规则是什么?
内存对齐规则
Go 中内存对齐是有一定规则可循的,Go 官方对内存对齐规则做了以下保证:
对于任意类型(
any)的变量x:unsafe.Alignof(x)至少为1。对于结构体类型(
struct)的变量x: 假设f表示为x中的每个字段,则unsafe.Alignof(x)是所有unsafe.Alignof(x.f)中的最大值,但至少为1。对于数组类型(
array)的变量x:unsafe.Alignof(x)与数组元素类型变量的对齐方式相同。
此外:如果一个结构体或数组类型不包含任何占用内存大小大于零的字段(或元素),那么它的大小为零。两个不同的零大小变量可能在内存中具有相同的地址。
Go 在 unsafe 包中为我们提供了 3 个函数,分别可以获取一个类型实例(包括 int、bool 这种基础数据类型以及 struct 结构体等)的类型长度、对齐系数以及字段偏移量。
函数签名如下:
// Sizeof takes an expression x of any type and returns the size in bytes
// of a hypothetical variable v as if v was declared via var v = x.
// The size does not include any memory possibly referenced by x.
// For instance, if x is a slice, Sizeof returns the size of the slice
// descriptor, not the size of the memory referenced by the slice.
// For a struct, the size includes any padding introduced by field alignment.
// The return value of Sizeof is a Go constant if the type of the argument x
// does not have variable size.
// (A type has variable size if it is a type parameter or if it is an array
// or struct type with elements of variable size).
func Sizeof(x ArbitraryType) uintptr
// Offsetof returns the offset within the struct of the field represented by x,
// which must be of the form structValue.field. In other words, it returns the
// number of bytes between the start of the struct and the start of the field.
// The return value of Offsetof is a Go constant if the type of the argument x
// does not have variable size.
// (See the description of [Sizeof] for a definition of variable sized types.)
func Offsetof(x ArbitraryType) uintptr
// Alignof takes an expression x of any type and returns the required alignment
// of a hypothetical variable v as if v was declared via var v = x.
// It is the largest value m such that the address of v is always zero mod m.
// It is the same as the value returned by reflect.TypeOf(x).Align().
// As a special case, if a variable s is of struct type and f is a field
// within that struct, then Alignof(s.f) will return the required alignment
// of a field of that type within a struct. This case is the same as the
// value returned by reflect.TypeOf(s.f).FieldAlign().
// The return value of Alignof is a Go constant if the type of the argument
// does not have variable size.
// (See the description of [Sizeof] for a definition of variable sized types.)
func Alignof(x ArbitraryType) uintptr
Sizeof用来计算类型实例长度,前文已经使用过了。Offsetof用来计算结构体字段偏移量。Alignof用来计算类型实例对齐系数(有人也叫对齐宽度)。
NOTE: 注意
Offsetof只接收结构体变量,切记不要传非结构体,编译时没事,但是运行时会报错。比如传递基础类型int8会报错,执行示例fmt.Println(unsafe.Offsetof(int8(1)))程序将会panic,得到invalid argument: int8(1) is not a selector expression错误信息。
我们使用 Alignof 来看下几种常见的类型实例对齐系数是多少:
fmt.Printf("int8 align: %d\n", unsafe.Alignof(int8(1)))
fmt.Printf("bool align: %d\n", unsafe.Alignof(true))
fmt.Printf("string align: %d\n", unsafe.Alignof("Hello World"))
fmt.Printf("T1 align: %d\n", unsafe.Alignof(T1{}))
fmt.Printf("T2 align: %d\n", unsafe.Alignof(T1{}))
fmt.Printf("empty struct align: %d\n", unsafe.Alignof(struct{}{}))
fmt.Printf("int align: %d\n", unsafe.Alignof(int(3)))
fmt.Printf("int array align: %d\n", unsafe.Alignof([3]int{1, 2, 3}))
执行示例代码,输出结果如下:
$ go run main.go
int8 align: 1
bool align: 1
string align: 8
T1 align: 8
T2 align: 8
empty struct align: 1
int align: 8
int array align: 8
对于基础数据类型 int8、bool 对齐系数都是 1,它们的类型实例也确实仅占用 1 个字节。
string 类型对齐系数是 8,而非类型实例所占用的字节数 16。这是因为在 64 位机器中,编译器存在最大对齐系数,等于字长大小,即为 8,那么可想而知 32 位机器中最大对齐系数为 4。
T1 和 T2 都是结构体类型,而结构体是复合类型,考虑内存对齐系数时要考虑每一个字段。结构体对齐系数等于其成员字段中的最大对齐系数,即为 string 类型的 b 字段对齐系数,并且在 64 位机器中同样不会超过 8。
空结构体虽然不占用内存空间,但根据 Go 的内存对齐保证 对于任意类型的变量 x: unsafe.Alignof(x) 至少为 1,所以空结构体的内存对齐系数为 1。
int 类型对齐系数是 8,与类型实例占用字节数相同。而由 int 组成的 array 类型,其内存对齐系数等于成员类型 int 的对齐系数 8。
这些看似复杂的规则记不住也没有关系,所有类型都可以通过 unsafe.Alignof(x) 计算出其对齐系数。
更进一步,我们可以使用 Sizeof、Offsetof、Alignof 这 3 个函数对 T1 和 T2 结构体字段属性进行计算,分别获取各个字段的类型实例长度、字段偏移量和字段对齐系数:
t1 := T1{}
fmt.Println("# T1")
fmt.Printf("T1.a: size=%d, offset=%v, align=%d\n", unsafe.Sizeof(t1.a), unsafe.Offsetof(t1.a), unsafe.Alignof(t1.a))
fmt.Printf("T1.b: size=%d, offset=%v, align=%d\n", unsafe.Sizeof(t1.b), unsafe.Offsetof(t1.b), unsafe.Alignof(t1.b))
fmt.Printf("T1.c: size=%d, offset=%v, align=%d\n", unsafe.Sizeof(t1.c), unsafe.Offsetof(t1.c), unsafe.Alignof(t1.c))
t2 := T2{}
fmt.Println("# T2")
fmt.Printf("T2.b: size=%d, offset=%v, align=%d\n", unsafe.Sizeof(t2.b), unsafe.Offsetof(t2.b), unsafe.Alignof(t2.b))
fmt.Printf("T2.a: size=%d, offset=%v, align=%d\n", unsafe.Sizeof(t2.a), unsafe.Offsetof(t2.a), unsafe.Alignof(t2.a))
fmt.Printf("T2.c: size=%d, offset=%v, align=%d\n", unsafe.Sizeof(t2.c), unsafe.Offsetof(t2.c), unsafe.Alignof(t2.c))
执行示例代码,输出结果如下:
$ go run main.go
# T1
T1.a: size=1, offset=0, align=1
T1.b: size=16, offset=8, align=8
T1.c: size=1, offset=24, align=1
# T2
T2.b: size=16, offset=0, align=8
T2.a: size=1, offset=16, align=1
T2.c: size=1, offset=17, align=1
我们根据这个结果,再来重新分析下结构体 T1 和 T2 的内存布局。
首先来看 T1 结构体:

字段 a 占用的内存大小为 1 字节,因为是结构体的第一个字段,所以内存地址偏移量为 0,内存对齐系数为 1。
既然字段 a 的内存对齐系数是 1,那为什么后面要存在 7 个内存地址的 padding 呢?
因为字段 b 的内存对齐系数是 8,为了减少 CPU 访问 b 的周期,填充 7 个内存地址的 padding 后,CPU 能够根据字段 b 的内存地址偏移量 8,快速定位到字段 b 的内存起始位置,然后仅需 2 个访问周期,就能完整读取字段 b 的内容。
字段 c 仅占用 1 个字节内存,对齐系数也为 1,并且是 T1 的最后一个字段,可以根据内存地址偏移量 24 直接读取其值,为什么在其后面也会存在 padding 呢?
是因为对于结构体的内存对齐,还有一条规则:结构体最终所分配的内存大小是其所有字段中最大齐系数的整数倍。
所以,为了满足上面这条规则,字段 c 后面仍然需要存在 padding 填充。
最终 T1 占用的内存空间大小为 32 字节。
再来看下 T2 结构体:
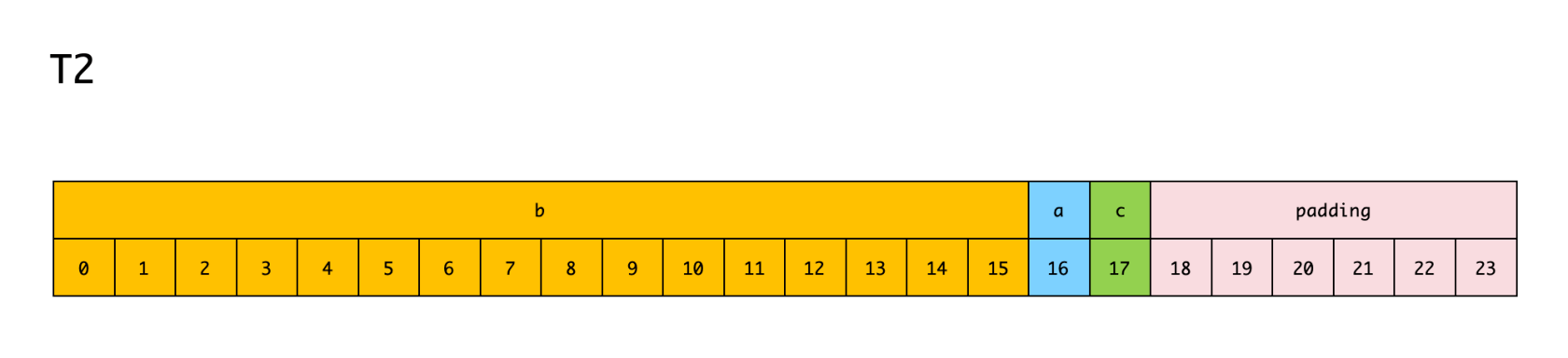
字段 b 作为结构体的第一个字段,占用内存大小为 16 字节,内存地址偏移量为 0,内存对齐系数为 8。
由于字段 b 的所有属性都满足对齐规则,所以不存在 padding。
字段 a 可以紧挨着字段 b,其占用内存大小为 1 字节,内存地址偏移量为 16,内存对齐系数为 1。
因为字段 c 的内存占用大小、内存对齐系数,都为 1,所以字段 a 和 c 加在一起,其总内存占用大小才等于 2,小于 8,那么为了减少 CPU 访问周期,就可以把二者放在同一个 8 字节区域,这样 CPU 访问一次就可以同时读取到两个变量。并且后面再填充 6 个内存地址的 padding,T2 就能满足结构体最终所分配的内存大小是最大齐系数的整数倍。
所以最终 T2 占用的内存空间大小为 24 字节。
经过以上分析可以发现,其实所谓的结构体内存对齐,就是在结构体字段长度小于对齐系数时,考虑使用 字段对齐系数 - 字段类型实例大小 得到 padding 的内存地址数量,进行填充,最终尽量让结构体的所有字段偏移量都落在对齐系数的整数倍内存地址上,以此来减少 CPU 访问周期,这正是典型的以空间换时间的思想。
对于 Sizeof、Offsetof、Alignof 这 3 个函数,其实 Go 还提供了反射版本:
for _, T := range []any{T1{}, T2{}} {
typ := reflect.TypeOf(T)
fmt.Printf("%s size: %d\n", typ.Name(), typ.Size())
n := typ.NumField()
for i := 0; i < n; i++ {
field := typ.Field(i)
fmt.Printf("%s.%s: size=%d, offset=%v, align=%d\n",
typ.Name(),
field.Name,
field.Type.Size(),
field.Offset,
field.Type.Align(),
)
}
}
执行示例代码,输出结果如下:
$ go run main.go
T1 size: 32
T1.a: size=1, offset=0, align=1
T1.b: size=16, offset=8, align=8
T1.c: size=1, offset=24, align=1
T2 size: 24
T2.b: size=16, offset=0, align=8
T2.a: size=1, offset=16, align=1
T2.c: size=1, offset=17, align=1
另外,对于字段偏移量,其实有一个“奇技淫巧”:我们可以通过字段偏移,直接修改结构体字段的值。
比如修改 T1{}.b 的值:
t1 := T1{}
fmt.Printf("T1: %+v\n", t1)
b := (*string)(unsafe.Pointer(uintptr(unsafe.Pointer(&t1)) + unsafe.Offsetof(t1.b)))
*b = "江湖十年"
fmt.Printf("T1: %+v\n", t1)
unsafe.Pointer(&t1) 可以获取类型实例 t1 指针地址,而 t1 的内存地址即为第一个字段 a 的内存地址。
将其转换为 uintptr 类型后,可以进行运算,比如 +(加号)运算符操作,t1 内存地址 + 字段b 的内存地址偏移量,就得到了字段 b 的内存地址。
通过 *b = "江湖十年" 可以直接为字段 b 进行赋值。
执行示例代码,输出结果如下:
$ go run main.go
T1: {a:0 b: c:false}
T1: {a:0 b:江湖十年 c:false}
这一点知道就好,尽量不要使用,内存级别的操作还是比较危险的。
内存对齐对性能的影响
前文分析中,我们说内存对齐能够加快 CPU 访问速度,现在来写一个基准测试验证一下:
package main
import "testing"
func Benchmark_T1_Align(b *testing.B) {
b.ReportAllocs() // 开启内存统计
b.ResetTimer() // 重置计时器
for i := 0; i < b.N; i++ {
_ = make([]T1, b.N)
}
}
func Benchmark_T2_Align(b *testing.B) {
b.ReportAllocs() // 开启内存统计
b.ResetTimer() // 重置计时器
for i := 0; i < b.N; i++ {
_ = make([]T2, b.N)
}
}
这里对 T1 和 T2 两个结构体都进行了基准测试,执行 10000 次看看结果:
$ go test -bench=. -count=1 -benchtime=10000x
goos: darwin
goarch: arm64
pkg: github.com/jianghushinian/blog-go-example/struct/memory-layouts/benchmark
Benchmark_T1_Align-8 10000 13097 ns/op 327681 B/op 1 allocs/op
Benchmark_T2_Align-8 10000 10858 ns/op 245761 B/op 1 allocs/op
PASS
ok github.com/jianghushinian/blog-go-example/struct/memory-layouts/benchmark 0.349s
两个基准测试各自执行 10000 次,T1 每次执行需要花费 13097 纳秒,每次操作分配了 327681 字节的内存,每次操作分配内存的次数为 1。T2 每次执行需要花费 10858 纳秒,每次操作分配了 245761 字节的内存,每次操作分配内存的次数为 1。
根据测试结果,看来 T2 内存布局更加合理。
这是因为 T2 仅占用 24 个字节内存,而 T1 需要占用 32 个字节内存。并且 T1 中 a、c 字段后面都存在 padding,T2 仅在字段 c 后面存在 padding。
结构体字段类型含空结构体情况
终于到了这一部分讲解,这也是我在《Go 中空结构体惯用法,我帮你总结全了!》一文中挖下的坑。
我们定义 3 个结构体如下:
type T3 struct {
a int8
b string
c struct{}
}
type T4 struct {
a int8
c struct{}
b string
}
type T5 struct {
c struct{}
a int8
b string
}
T3、T4、T5 都包含了一个空结构体字段 struct{},分别打印其占用内存大小:
fmt.Printf("T3 size: %d\n", unsafe.Sizeof(T3{}))
fmt.Printf("T4 size: %d\n", unsafe.Sizeof(T4{}))
fmt.Printf("T5 size: %d\n", unsafe.Sizeof(T5{}))
执行示例代码,输出结果如下:
$ go run main.go
T3 size: 32
T4 size: 24
T5 size: 24
可以发现,T3 比 T4 和 T5 多占用了 8 字节内存空间。
由此我们也可以得出结论,当结构体字段含有空结构体时,为了节省内存空间,最好不要将空结构体字段放在末尾,而 T5 是推荐写法。
我们来分析下 T3 结构体为什么会多占用 8 字节内存空间,T3 结构体内存布局如下:

虽然空结构体字段 c 不占用内存空间,但 Go 还是为结构体 T3 在字段 c 后面进行了 padding 填充。
我们也可以获取 T3 各个字段的类型实例长度、字段偏移量和字段对齐系数:
t3 := T3{}
fmt.Println("# T3")
fmt.Printf("T3.a: size=%d, offset=%v, align=%d\n", unsafe.Sizeof(t3.a), unsafe.Offsetof(t3.a), unsafe.Alignof(t3.a))
fmt.Printf("T3.b: size=%d, offset=%v, align=%d\n", unsafe.Sizeof(t3.b), unsafe.Offsetof(t3.b), unsafe.Alignof(t3.b))
fmt.Printf("T3.c: size=%d, offset=%v, align=%d\n", unsafe.Sizeof(t3.c), unsafe.Offsetof(t3.c), unsafe.Alignof(t3.c))
执行示例代码,输出结果如下:
$ go run main.go
# T3
T3.a: size=1, offset=0, align=1
T3.b: size=16, offset=8, align=8
T3.c: size=0, offset=24, align=1
可以发现,字段 c 占用内存大小为 0 字节,但是内存对齐系数为 1。
不过内存对齐系数并不是影响存在 padding 的原因。
关于为什么只有空结构体字段在末尾时才存在内存填充,我在 Go FAQ 101 的 Why does the final field of a zero-sized type in a struct contribute to the size of the struct sometimes? 中找到了解释:
In the current standard Go runtime implementation, as long as a memory block is referenced by at least one active pointer, that memory block will not be viewed as garbage and will not be collected.
All the fields of an addressable struct value can be taken addresses. If the size of the final field in a non-zero-sized struct value is zero, then taking the address of the final field in the struct value will return an address which is beyond the allocated memory block for the struct value. The returned address may point to another allocated memory block which closely follows the one allocated for the non-zero-sized struct value. As long as the returned address is stored in an active pointer value, the other allocated memory block will not get garbage collected, which may cause memory leaking.
To avoid these kinds of memory leak problems, the standard Go compiler will ensure that taking the address of the final field in a non-zero-sized struct will never return an address which is beyond the allocated memory block for the struct. The standard Go compiler implements this by padding some bytes after the final zero-sized field when needed.
If the types of all fields in a struct type are zero-sized (so the struct is also a zero-sized type), then there is no need to pad bytes in the struct, for the standard Go compiler treats zero-sized memory blocks specially.
这段内容可以概述为:
当空结构体做为外层结构体最后一个字段时,如果有指针指向这个空结构体字段,这个指针将得到一个超出为该结构值分配的内存块的地址,返回的地址可能指向紧随该非零大小结构体值分配的另一个内存块。只要返回的地址被指针引用,其分配的内存块就不会被垃圾回收,这可能会导致内存泄漏。
Go 编译器通过在需要时,在最后一个零大小字段后填充一些字节来实现避免这类内存泄漏问题。
如果结构体类型中所有字段的类型都是零大小(因此结构体也是零大小类型),则无需在结构体中填充字节,因为Go 编译器特殊处理零大小内存块。
我认为之所以空结构体字段如此特殊,这和空结构体实现也有关。前文在讲解 内存对齐规则 时有提到「如果一个结构体或数组类型不包含任何占用内存大小大于零的字段(或元素),那么它的大小为零。两个不同的零大小变量可能在内存中具有相同的地址」。
另外,Go 官方仓库中 issues 9401 也有讨论这个问题。如果你足够耐心的话,其实有很多 issues 都有提到这个问题,若你想进一步了解更多细节,可以去翻翻历史 issues。
原子操作
我在查阅资料的过程中,发现 atomic 库的文档底部记录了一个 Bug:
On 386, the 64-bit functions use instructions unavailable before the Pentium MMX.
On non-Linux ARM, the 64-bit functions use instructions unavailable before the ARMv6k core.
On ARM, 386, and 32-bit MIPS, it is the caller’s responsibility to arrange for 64-bit alignment of 64-bit words accessed atomically via the primitive atomic functions (types Int64 and Uint64 are automatically aligned). The first word in an allocated struct, array, or slice; in a global variable; or in a local variable (because the subject of all atomic operations will escape to the heap) can be relied upon to be 64-bit aligned.
这里是说:开发者在 32-bit 平台调用 atomic 进行 64 位原子操作时,有责任确保被操作的对象 8 字节对齐。
什么意思?我给你举个例子,你就明白了。
示例程序如下:
package main
import "sync/atomic"
type S1 struct {
a int32
b int64
}
func main() {
s1 := S1{}
atomic.AddInt64(&s1.b, 1)
}
定义结构体 S1,其字段 a 为 int32 类型,字段 b 为 int64 类型。
使用 atomic.AddInt64(&s1.b, 1) 对 S1 类型实例对象 s1 的 b 属性进行原子加 1 操作。
在我的 64 位机器上编译并执行示例程序:
$ go build main.go
$ ./main
没有任何输出,这刚好符合 Linux/Unix 系统设计哲学:没有消息就是最好的消息。
现在,我们模拟在 Linux 386 机器上执行该示例程序,看看效果如何。
首先交叉编译示例程序:
$ GOOS=linux GOARCH=386 go build main.go
如果直接在我的 Mac 系统上执行编译后的程序,则得到如下输出:
$ ./main
zsh: exec format error: ./main
这并不是程序本身报错,而是因为跨平台问题,我们编译的 Linux 386 平台程序无法直接在 Mac 系统中运行。
不过我们可以使用 Docker 来绕过这个问题,先使用如下命令启动一个 CentOS 的容器环境:
$ docker run -it --rm centos:7
[root@13f606392c43 /]#
然后在新的终端中,将刚刚编译好的 Linux 386 二进制程序复制到容器内部:
$ docker cp ./main 13f606392c43:/root/main
Successfully copied 1.31MB to 13f606392c43:/root/main
最后在容器中执行示例程序:
[root@13f606392c43 /]# cd /root/
[root@13f606392c43 ~]# ls
anaconda-ks.cfg main
[root@13f606392c43 ~]# ./main
panic: unaligned 64-bit atomic operation
goroutine 1 [running]:
runtime/internal/atomic.panicUnaligned()
/Users/jianghushinian/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.22.0.darwin-arm64/src/runtime/internal/atomic/unaligned.go:8 +0x2d
runtime/internal/atomic.Xadd64(0x84a8004, 0x1)
/Users/jianghushinian/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.22.0.darwin-arm64/src/runtime/internal/atomic/atomic_386.s:125 +0x11
main.main()
/blog-go-example/struct/memory-layouts/atomic-bugs/main.go:12 +0x42
[root@13f606392c43 ~]#
程序会 panic 并退出,得到 panic: unaligned 64-bit atomic operation 错误信息。
这其实是因为结构体 S1 在 32 位平台上是 4 字节对齐,而在 64 位平台上是 8 字节对齐。
所以要解决这个问题,我们应该想办法让结构体在 32 位平台上也能实现 8 字节对齐的效果。
现在,我们重新定义一个结构体 S2:
package main
import "sync/atomic"
type S2 struct {
a int32
pad uint32 // ensure 8-byte alignment of val on 386
b int64
}
func main() {
s2 := S2{}
atomic.AddInt64(&s2.b, 1) // 手动对齐以后不会报错
}
这次在结构体字段 a、b 中间加入一个 uint32 类型的 pad 字段作为内存填充,即手动实现 8 字节对齐。
这样,当 atomic.AddInt64(&s2.b, 1) 访问字段 b 时,其实已经是 8 字节对齐了。因为字段 a 和字段 b 的大小加在一起刚好等于 8 字节。字段 b 的偏移量无论在 64 位平台还是 32 位平台都是相等的,为 8 的倍数。
再次将其编译成 Linux 386 二进制程序并复制到容器内部执行:
[root@13f606392c43 ~]# ./main
[root@13f606392c43 ~]#
程序不再 panic 了。
这就印证了「开发者在 32-bit 平台调用 atomic 进行 64 位原子操作时,有责任确保被操作的对象 8 字节对齐」。
我在 issues 36606 中还见到了有人提议添加 //go:packed 指令来解决这类问题,感兴趣的读者可以点击进去查看。
NOTE: 这里也再次验证了 issues 中存在大量关于 Go 结构体内存对齐的讨论,如果你感兴趣可以多去看看,你会发现非常多有意思的讨论。
false sharing
关于 false sharing(伪共享)的概念,由于篇幅所限,我在这里就不过多介绍了,我专门写了一篇文章《以 Go 语言为例解释什么是伪共享以及如何解决》 来讲解。
我们可以通过手动对齐的方式来避免 false sharing,Go 中的 sync.Pool 包就使用了这种方式:
// golang.org/toolchain@v0.0.1-go1.22.0.darwin-arm64/src/sync/pool.go
type poolLocal struct {
poolLocalInternal
// Prevents false sharing on widespread platforms with
// 128 mod (cache line size) = 0 .
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
根据代码注释可知,poolLocal 结构体字段 pad 的设计,就是为了防止出现 false sharing。这里直接使用了魔法数字 128,应该是为了兼容更多平台。
其实 Go 为我们提供了 cpu.CacheLinePad 变量,可以解决不同平台缓存行大小不一致的问题。
如下示例代码,我们可以使用 cpu.CacheLinePad 进行手动内存对齐:
package main
import "golang.org/x/sys/cpu"
var S struct {
a string
_ cpu.CacheLinePad
}
这样就能够兼容不同平台。
cpu.CacheLinePad 变量定义如下:
// golang.org/x/sys@v0.22.0/cpu/cpu.go
// CacheLinePad is used to pad structs to avoid false sharing.
type CacheLinePad struct{ _ [cacheLineSize]byte }
它其实是一个结构体,其内部又嵌入了一个 [cacheLineSize]byte 数组,cacheLineSize 的值所占用内存宽度,跟平台有关。在我的 64 位 Mac 机器上其值为 128:
// golang.org/x/sys@v0.22.0/cpu/cpu_arm64.go
// cacheLineSize is used to prevent false sharing of cache lines.
// We choose 128 because Apple Silicon, a.k.a. M1, has 128-byte cache line size.
// It doesn't cost much and is much more future-proof.
const cacheLineSize = 128
hot path
hot path 直译过来是 热路径,其实就是指频繁访问的指令。
我们知道,结构体的第一个字段内存地址偏移量为 0,所以访问结构体指针,其实就相当于访问结构体第一个字段。而访问第二个字段,就需要先计算第二个字段的内存地址偏移量,然后才能获取第二个字段的内存地址。
所以为了提升性能,对于频繁操作的结构体字段,建议放在第一个字段的位置,将其作为 hot path。
比如 Go 中的 sync.Once 就是这么做的:
type Once struct {
// done indicates whether the action has been performed.
// It is first in the struct because it is used in the hot path.
// The hot path is inlined at every call site.
// Placing done first allows more compact instructions on some architectures (amd64/386),
// and fewer instructions (to calculate offset) on other architectures.
done atomic.Uint32
m Mutex
}
根据注释可以发现,done 字段之所以被放在第一个字段位置,就是为了满足 hot path。
对比前文在讲解 内存对齐规则 时介绍的修改 T1{}.b 的值所用的“奇技淫巧”「通过字段偏移,直接修改结构体字段的值」,操作结构体第一个字段要更加简单。
工具
围绕 Go 结构体内存对齐,其实有很多工具可以利用,在这里仅演示几个我尝试使用过的,供你选择。
检查结构体内存占用是否存在可优化空间
每次写完一个结构体,肉眼查看其占用内存是否还存在可优化空间,这是一件非常困难的事情。因为生产实践中,很多结构体不会像 T1、T2 这样定义的如此简单。
好在 golangci-lint 中的 govet linter 支持静态分析出每一个结构体内存占用是否存在可优化空间。
我们可以创建如下测试程序目录结构:
$ tree -a tool
tool
└── golangci-lint
├── .golangci.yaml
└── main.go
在 .gilangci.yaml 文件中写下如下内容:
linters:
disable-all: true
enable:
- govet
linters-settings:
govet:
disable-all: true
enable:
- fieldalignment
简单介绍下这个配置内容:为了避免其他干扰,在 linters 配置项中首先关闭了所有 linter,然后仅开启 govet 这一个 linter。在 linters-settings 配置项中,关闭 govet 所有其他功能,仅开启 fieldalignment 功能,顾名思义,这是用来进行结构体字段对齐检查的。
在 main.go 中编写测试代码:
package main
type T1 struct {
a int8
b string
c bool
}
type T2 struct {
b string
a int8
c bool
}
安装 golangci-lint:
# 安装
$ go install github.com/golangci/golangci-lint/cmd/golangci-lint@latest
# 查看版本
$ golangci-lint version
golangci-lint has version v1.59.1 built with go1.22.0 from (unknown, modified: ?, mod sum: "h1:CRRLu1JbhK5avLABFJ/OHVSQ0Ie5c4ulsOId1h3TTks=") on (unknown)
使用 golangci-lint 检查结构体内存占用是否存在可优化空间:
$ golangci-lint run tool/golangci-lint/main.go
tool/golangci-lint/main.go:3:9: fieldalignment: struct of size 32 could be 24 (govet)
type T1 struct {
^
执行结果告诉我们,结构体 T1 内存占用可以从 32 下降到 24 字节。
自动更正结构体字段位置
现在我们知道了结构体 T1 存在可优化空间,但是一个一个字段去分析还是太麻烦了。
Go 官方出品了一个工具 fieldalignment,可以帮我们自动更正结构体字段位置,以此来节约结构体内存占用。
我们可以创建如下测试程序目录结构:
tree -a tool
tool
└── fieldalignment
└── main.go
在 main.go 中编写测试代码:
package main
type T1 struct {
a int8
b string
c bool
}
type T2 struct {
b string
a int8
c bool
}
安装 fieldalignment:
# 安装
$ go install golang.org/x/tools/go/analysis/passes/fieldalignment/cmd/fieldalignment@latest
# 查看版本
$ fieldalignment -V=full
/Users/jianghushinian/go/bin/fieldalignment version devel comments-go-here buildID=8258fcc5bcd2826c8fe959360b8d8c293c965c23f8452bc1a434af5f0061a361
使用 fieldalignment 检查结构体内存占用是否存在可优化空间:
$ fieldalignment tool/fieldalignment/main.go
/blog-go-example/struct/memory-layouts/tool/fieldalignment/main.go:3:9: struct of size 32 could be 24
这里同样能够检查出结构体 T1 内存占用可以从 32 下降到 24 字节。
如果我们加上 -fix 标志,则可以直接自动更正结构体字段位置:
$ fieldalignment -fix tool/fieldalignment/main.go
/blog-go-example/struct/memory-layouts/tool/fieldalignment/main.go:3:9: struct of size 32 could be 24
现在 main.go 内容如下:
package main
type T1 struct {
b string
a int8
c bool
}
type T2 struct {
b string
a int8
c bool
}
T1 结构体字段位置已经被 fieldalignment 工具自动重排了。
此外,还有一个 betteralign 工具同样可以实现此目的,用法也非常简单。由于篇幅所限,我就不进行演示了,你可以自行学习使用。
可视化结构体内存布局
最后再介绍一个非常好用的工具 structlayout,它可以让我们以可视化的方式分析查看结构体内存布局。
我们可以创建如下测试程序目录结构:
$ tree -a tool
tool
└── structlayout
└── main.go
main.go 中代码没变,还是 T1 和 T2 的定义,我就不贴代码了。
安装 structlayout:
# 安装
$ go install honnef.co/go/tools/cmd/structlayout
# 查看版本
$ structlayout -version
structlayout 2020.2.3 (v0.1.3)
使用 structlayout 将 T1 结构体的所有字段信息以 JSON 格式进行输出:
$ structlayout -json tool/structlayout/main.go T1 | jq .
[
{
"name": "T1.a",
"type": "int8",
"start": 0,
"end": 1,
"size": 1,
"align": 1,
"is_padding": false
},
{
"name": "",
"type": "",
"start": 1,
"end": 8,
"size": 7,
"align": 0,
"is_padding": true
},
{
"name": "T1.b",
"type": "string",
"start": 8,
"end": 24,
"size": 16,
"align": 8,
"is_padding": false
},
{
"name": "T1.c",
"type": "bool",
"start": 24,
"end": 25,
"size": 1,
"align": 1,
"is_padding": false
},
{
"name": "",
"type": "",
"start": 25,
"end": 32,
"size": 7,
"align": 0,
"is_padding": true
}
]
NOTE:
jq命令用来美化 JSON 输出内容格式,不是必须的。
可以发现 structlayout 输出内容信息非常详细,包含了结构体中每个字段所占内存大小、对齐系数等,并且每一个 padding 也都单独列了出来。
现在我们再来安装一个插件 structlayout-svg:
$ go install github.com/ajstarks/svgo/structlayout-svg
可以使用 structlayout-svg 将 structlayout 输出结果保存为 SVG 格式的图片:
$ structlayout -json tool/structlayout/main.go T1 | structlayout-svg -t main.T1 > tool/structlayout/t1-struct.svg
现在输出路径下 t1-struct.svg 图片已经存在:
$ tree -a tool
tool
└── structlayout
├── main.go
└── t1-struct.svg
打开图片:
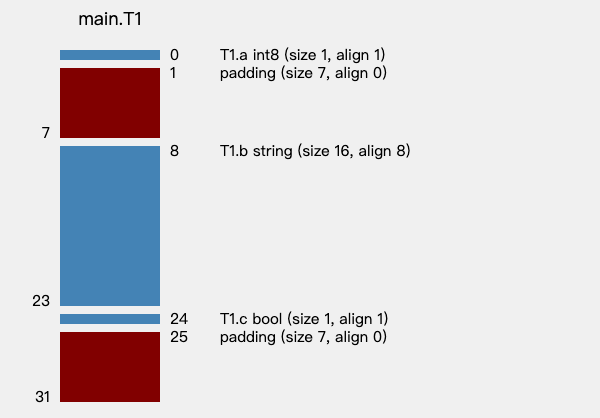
一张非常清晰的结构体内存布局图就展现在我们面前了,可以说非常直观。
我们再也不用手动画结构体内存布局图了(P.S. 为了更好的展示效果,T1、T2 结构体的内存布局图我真的画了好几个版本 -_-!)。
不过,我在使用 structlayout 的过程中发现了一个小 bug,structlayout 生成的内存布局图中空结构体 struct{} 占用内存大小为 1 字节,如下是生成的 T3 结构体内存布局图:
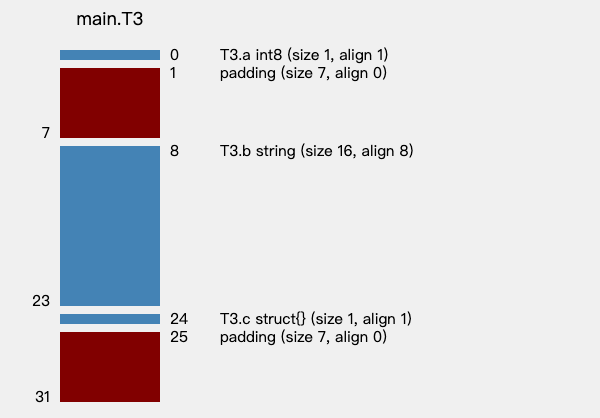
理论上来说空结构体的 size 值应该为 0 才对,这一点也可以使用 Sizeof 函数来验证。不过这一点注意下就好,structlayout 仍然很好用。
在此给大家布置一个小作业,对于 T4、T5 结构体我没有画内存布局图,你可以自行用 structlayout 工具分析下 T4、T5 结构体的内存布局。
可读性很重要
最后,我想站在自己的角度出发,来说说我们在日常开发中,是否需要关注 Go 中的结构体内存对齐。
我的理解是,99% 的开发者根本不需要关心!
没错,即使我花了这么长的篇幅来介绍 Go 语言中的结构体内存对齐,但我仍然认为我们几乎不需要关注它。
如下两个结构体是我从工作代码中定义的结构体中抽离出来的:
type TaskResource1 struct {
CPU uint8 `json:"cpu"`
GPU uint8 `json:"gpu"`
GPUType string `json:"gpuType"`
Memory uint16 `json:"memory"`
Storage uint64 `json:"storage"`
}
type TaskResource2 struct {
GPUType string `json:"gpuType"`
Storage uint64 `json:"storage"`
Memory uint16 `json:"memory"`
CPU uint8 `json:"cpu"`
GPU uint8 `json:"gpu"`
}
两个结构体包含一样的字段,只是顺序不同。
现在,我告诉你 TaskResource2 结构体更省内存,你会这样定义它吗?
我相信绝大多数人都会使用 TaskResource1 结构体的定义。
因为可读性更重要。
TaskResource1 结构体类型实例占用内存大小为 40,TaskResource2 结构体类型实例占用内存大小为 32,相差 8 个字节。
假如我们有 1000 个这样的结构体,可以省下多少内存?
答案是 1000 * 8 bytes = 7.8125 KB,换算成 MB 就是不到 0.008 MB。
相比于现在服务器的机器配置,这点内存优化能够产生多大收益呢?
所以,尽管正常定义你的结构体字段,不必花心思关注在内存对齐上。等你真正需要它的时候,再回过头来分析代码也不迟。
总结
本文为大家讲解了 Go 中结构体内存对齐的相关知识。
首先介绍了 Go 中结构体的内存布局,接着讲解了 Go 中内存对齐现象和规则,以及 Go 官方的内存对齐保证。
Go 在 unsafe 包中为我们提供了 3 个方法 Sizeof、Alignof 和 Offsetof,分别可以获取类型实例的类型长度、对齐系数、字段偏移量。
你应该能体会到,内存对齐实际上是在以空间换时间,提高程序执行效率。
我们还着重介绍了空结构体对结构体内存对齐的影响,Go FAQ 101 中给出了解释。
开发者在 32-bit 平台调用 atomic 进行 64 位原子操作时,有责任确保被操作的对象 8 字节对齐。
有了结构体内存对齐的知识,我们可以手动解决 false sharing 问题,以及使用 hot path 来提高程序执行效率。
我还为你介绍并演示了 golangci-lint、fieldalignment、structlayout 这 3 个工具的使用,助你玩转 Go 结构体内存对齐。
虽然我们可以通过调整结构体字段顺序,来优化内存占用。但是,绝大多数情况下可读性更重要,我们节省下的那点内存还是太少了,有些得不偿失。我们也不必过早的关注性能提升。
现在我们可以总结出:由于内存对齐的存在,结构体大小一定 >= 结构体各字段所占内存之和。
还有一个小技巧要告诉你,其实除了可以使用工具检测来优化结构体内存占用,其实我们只需要将结构体字段从大到小依次排列,就能够做到将结构体占用内存降到最低。
本文我并没有一条条的把所有内存对齐规则都罗列出来,整理一个清单给你,我是通过反复分析 T1 和 T2 结构体的内存布局来讲解。因为这个东西就不是死记硬背的,不过我还是希望你能自己去整理出来所有的内存对齐规则。因为在整理的过程中你会发现,其实这个清单并不重要,重要的是分析过程,最终你会做到无招胜有招。
本文示例源码我都放在了 GitHub 中,欢迎点击查看。
希望此文能对你有所启发。
P.S.
本文话题其实是 Go 语言中的一个高频面试题,我就曾经在面试的过程中被问到过这个问题。但现实是 99% 的程序员绝对用不到这个特性,也无需关注它,所以这种问题我愿称其为“八股文”。
延伸阅读
The Go Memory Model: go.dev/ref/mem
atomic Documentation: pkg.go.dev/sync/atomic#pkg-note-BU...
The Go Programming Language Specification Size and alignment guarantees: go.dev/ref/spec#Size_and_alignment...
Package atomic Bugs: golang.google.cn/pkg/sync/atomic/#...
Go Wiki: cgo Struct Alignment Issues: go.dev/wiki/cgo
Go 101 Memory Layouts: go101.org/article/memory-layout.ht...
Go 101 Why does the final field of a zero-sized type in a struct contribute to the size of the struct sometimes?: go101.org/article/unofficial-faq.h...
Go and memory layout: syslog.ravelin.com/go-and-memory-l...
Source file src/go/types/sizes.go: go.dev/src/go/types/sizes.go
Purpose of memory alignment: stackoverflow.com/questions/381244...
Sizeof struct in Go: stackoverflow.com/questions/211375...
What does it mean by word size in computer?: stackoverflow.com/questions/198211...
Word Size and Data Types: litux.nl/mirror/kerneldevelopment/...
Lock-free Data Structures. Basics: Atomicity and Atomic Primitives: kukuruku.co/hub/cpp/lock-free-data...
False sharing: en.wikipedia.org/wiki/False_sharin...
False Sharing: docs.kernel.org/kernel-hacking/fal...
What’s false sharing and how to solve it (using Golang as example): medium.com/@genchilu/whats-false-s...
go-review 427095: go-review.googlesource.com/c/go/+/...
Go issues 9401: github.com/golang/go/issues/9401
Go issues 36606: github.com/golang/go/issues/36606
Go 中空结构体惯用法,我帮你总结全了!: jianghushinian.cn/2024/06/02/i-hav...
以 Go 语言为例解释什么是伪共享以及如何解决: jianghushinian.cn/2024/07/04/what%...
本文 GitHub 示例代码:github.com/jianghushinian/blog-go-...
联系我
公众号:Go编程世界
微信:jianghushinian
本作品采用《CC 协议》,转载必须注明作者和本文链接







 关于 LearnKu
关于 LearnKu




推荐文章: