
[大数据学习](一)Hadoop生态圈
2 / 0 / 创建于 1年前 /
 程序员的猫 的个人博客
程序员的猫 的个人博客
Hadoop生态圈总览图
Hadoop生态圈](https://cdn.learnku.com/uploads/images/202408/14/23951/d0QD43JjqR.png!large)
-coordination and management(协调与管理) -query(查询) -data piping(数据管道) -core hadoop(核心hadoop) -machine learning(机器学习) -nosql database(nosql数据库)
1.HDFS(分布式文件系统)——核心
源自于Google的GFS论文,发表于2003年10月,HDFS是GFS克隆版。
HDFS是整个hadoop体系的基础,负责数据的存储与管理。HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。它提供了一次写入多次读取的机制,数据以块的形式,同时分布在集群不同物理机器上。
client:切分文件,访问HDFS时,首先与NameNode交互,获取目标文件的位置信息,然后与DataNode交互,读写数据
NameNode:master节点,每个HDFS集群只有一个,管理HDFS的名称空间和数据块映射信息,配置相关副本信息,处理客户端请求。
DataNode:slave节点,存储实际数据,并汇报状态信息给NameNode,默认一个文件会备份3份在不同的DataNode中,实现高可靠性和容错性。
Secondary NameNode:辅助NameNode,实现高可靠性,定期合并fsimage和fsedits,推送给NameNode;紧急情况下辅助和恢复NameNode,但其并非NameNode的热备份。
2.MapReduce(分布式计算框架)——核心
源自于google的MapReduce论文,发表于2004年12月,Hadoop MapReduce是google MapReduce 克隆版。
MapReduce是一种基于磁盘的分布式并行批处理计算模型,用于处理大数据量的计算。它屏蔽了分布式计算框架细节,将计算抽象成map和reduce两部分,其中Map对应数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同的键的所有值进行规约,以得到最终结果。MapReduce非常适合在大量计算机组成的分布式并行环境里进行数据处理。
JobTracker:master节点,只有一个,管理所有作业,任务/作业的监控,错误处理等,将任务分解成一系列任务,并分派给TaskTracker。
TaskTracker:slave节点,运行 Map task和Reduce task;并与JobTracker交互,汇报任务状态。
Map task:解析每条数据记录,传递给用户编写的map()函数并执行,将输出结果写入到本地磁盘(如果为map—only作业,则直接写入HDFS)。
Reduce task:从Map 它深刻地执行结果中,远程读取输入数据,对数据进行排序,将数据分组传递给用户编写的Reduce()函数执行。
3.Yarn(分布式资源管理器)——核心
YARN是下一代MapReduce,即MRv2,是在第一代MapReduce基础上演变而来的,主要是为了解决原始Hadoop扩展性较差,不支持多计算框架而提出的。 Yarn是下一代 Hadoop 计算平台,yarn是一个通用的运行时框架,用户可以编写自己的计算框架,在该运行环境中运行。 用于自己编写的框架作为客户端的一个lib,在运用提交作业时打包即可。该框架为提供了以下几个组件:
- 资源管理:包括应用程序管理和机器资源管理
- 资源双层调度
- 容错性:各个组件均有考虑容错性
- 扩展性:可扩展到上万个节点
4.Spark(分布式计算框架)
Spark是一个Apache项目,它被标榜为“快如闪电的集群计算”。它拥有一个繁荣的开源社区,并且是目前最活跃的Apache项目。最早Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架。是一种基于内存的分布式并行计算框架,不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。Spark提供了一个更快、更通用的数据处理平台。和Hadoop相比,Spark可以让你的程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍
Cluster Manager:在standalone模式中即为Master主节点,控制整个集群,监控worker。在YARN模式中为资源管理器
Worker节点:从节点,负责控制计算节点,启动Executor或者Driver。
Driver: 运行Application 的main()函数
Executor:执行器,是为某个Application运行在worker node上的一个进程
Spark将数据抽象为RDD(弹性分布式数据集),内部提供了大量的库,包括Spark Core、Spark SQL、Spark Streaming、MLlib、GraphX。 开发者可以在同一个应用程序中无缝组合使用这些库。
Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的
Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。
Spark Streaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据,通过短时批处理实现的伪流处理。
MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作
5.Tez(DAG计算模型)
Tez是Apache最新开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分, 即Map被拆分成Input、Processor、Sort、Merge和Output Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等 这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。 目前hive支持mr、tez计算模型,tez能完美二进制mr程序,提升运算性能。
6.Hive(基于Hadoop的数据仓库)
由facebook开源,最初用于解决海量结构化的日志数据统计问题。
Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行。通常用于离线分析。
HQL用于运行存储在Hadoop上的查询语句,Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。
7.Pig(ad-hoc脚本)
由yahoo!开源,设计动机是提供一种基于MapReduce的ad-hoc(计算在query时发生)数据分析工具
Pig定义了一种数据流语言—Pig Latin,它是MapReduce编程的复杂性的抽象,Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。
其编译器将Pig Latin翻译成MapReduce程序序列将脚本转换为MapReduce任务在Hadoop上执行。通常用于进行离线分析。
8.Mahout(数据挖掘算法库)
Mahout起源于2008年,最初是Apache Lucent的子项目,它在极短的时间内取得了长足的发展,现在是Apache的顶级项目。
Mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。
Mahout现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。
除了算法,Mahout还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB 或Cassandra)集成等数据挖掘支持架构。
9.Ambari(安装部署配置管理工具)
Apache Ambari 的作用来说,就是创建、管理、监视 Hadoop 的集群,是为了让 Hadoop 以及相关的大数据软件更容易使用的一个web工具。
10. Oozie(工作流调度器)
Oozie是一个可扩展的工作体系,集成于Hadoop的堆栈,用于协调多个MapReduce作业的执行。它能够管理一个复杂的系统,基于外部事件来执行,外部事件包括数据的定时和数据的出现。
Oozie工作流是放置在控制依赖DAG(有向无环图 Direct Acyclic Graph)中的一组动作(例如,Hadoop的Map/Reduce作业、Pig作业等),其中指定了动作执行的顺序。
Oozie使用hPDL(一种XML流程定义语言)来描述这个图。
11.HBase(分布式列存数据库)
源自Google的Bigtable论文,发表于2006年11月,HBase是Google Bigtable克隆版
HBase是一个建立在HDFS之上,面向列的针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。
HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。
HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
12.Sqoop(数据ETL/同步工具)
Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之前传输数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。
Sqoop利用数据库技术描述数据架构,用于在关系数据库、数据仓库和Hadoop之间转移数据。
13.Flume(日志收集工具)
Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。
它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。
同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。
总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统。当然也可以用于收集其他类型数据
Flume以Agent为最小的独立运行单位,一个Agent就是一个JVM。单个Agent由Source、Sink和Channel三大组件构成
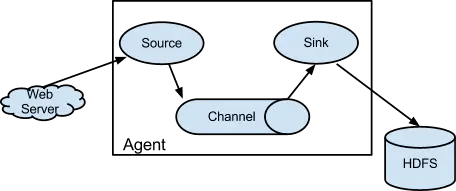
在这里插入图片描述
Source:从客户端收集数据,并传递给Channel。
Channel:缓存区,将Source传输的数据暂时存放。
Sink:从Channel收集数据,并写入到指定地址。
14. Zookeeper(分布式协作服务)
源自Google的Chubby论文,发表于2006年11月,Zookeeper是Chubby克隆版
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
15.HCatalog(数据表和存储管理服务)
HCatalog是Hadoop的表和存储管理工具。它将Hive Metastore的表格数据公开给其他Hadoop应用程序。使得具有不同数据处理工具(Pig,MapReduce)的用户能够轻松在网格读写数据。HCatalog的表抽象为用户提供了Hadoop分布式文件系统(HDFS)中数据的关系视图,并确保用户不必担心数据存储在何处或以何种格式存储——RCFile格式、文本文件、SequenceFiles或ORC文件。
HCatalog像Hive的一个关键组件一样工作,它使用户能够以任何格式和任何结构存储他们的数据。
16.Impala(SQL查询引擎)
impala是cloudera提供的一款高效率的sql查询工具,提供实时的查询效果,官方测试性能比hive快10到100倍,其sql查询比sparkSQL还要更加快速,号称是当前大数据领域最快的查询sql工具,
impala是参照谷歌的新三篇论文(Caffeine–网络搜索引擎、Pregel–分布式图计算、Dremel–交互式分析工具)当中的Dremel实现而来,其中旧三篇论文分别是(BigTable,GFS,MapReduce)分别对应我们即将学的HBase和已经学过的HDFS以及MapReduce。
impala是基于hive并使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点。是CDH平台首选的PB级大数据实时查询分析引擎。
17.Presto(分布式大数据SQL查询引擎)
Presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。
Presto的设计和编写完全是为了解决像Facebook这样规模的商业数据仓库的交互式分析和处理速度的问题。
Presto是一个交互式的查询引擎,我们最关心的就是Presto实现低延时查询的原理,特点如下:
1、完全基于内存的并行计算
2、流水线
3、本地化计算
4、动态编译执行计划
5、小心使用内存和数据结构
6、类BlinkDB的近似查询
7、GC控制
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: